| 一起学Hadoop | 您所在的位置:网站首页 › 怎么用idea写python › 一起学Hadoop |
一起学Hadoop
|
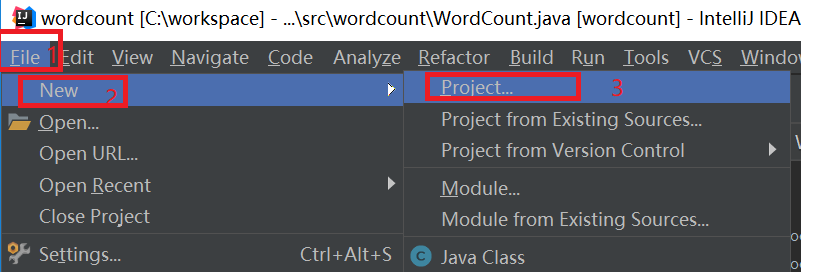
上一篇我们学习了MapReduce的原理,今天我们使用代码来加深对MapReduce原理的理解。 wordcount是Hadoop入门的经典例子,我们也不能免俗,也使用这个例子作为学习Hadoop的第一个程序。本文将介绍使用java和python编写第一个MapReduce程序。 本文使用Idea2018开发工具开发第一个Hadoop程序。使用的编程语言是Java。 打开idea,新建一个工程,如下图所示:
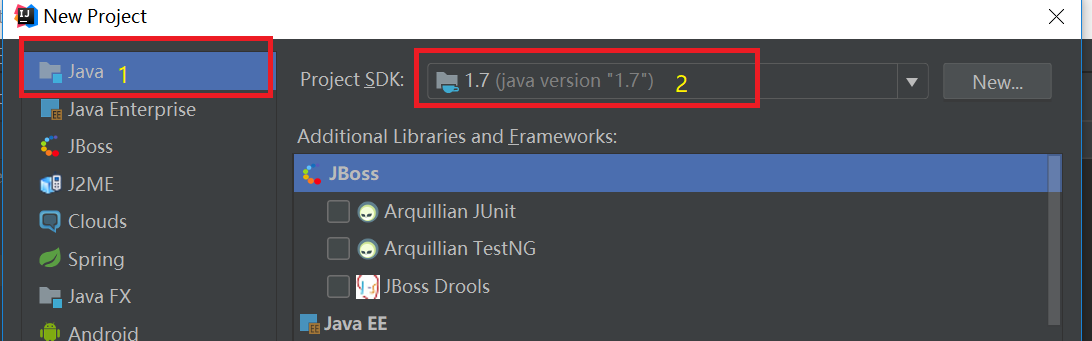
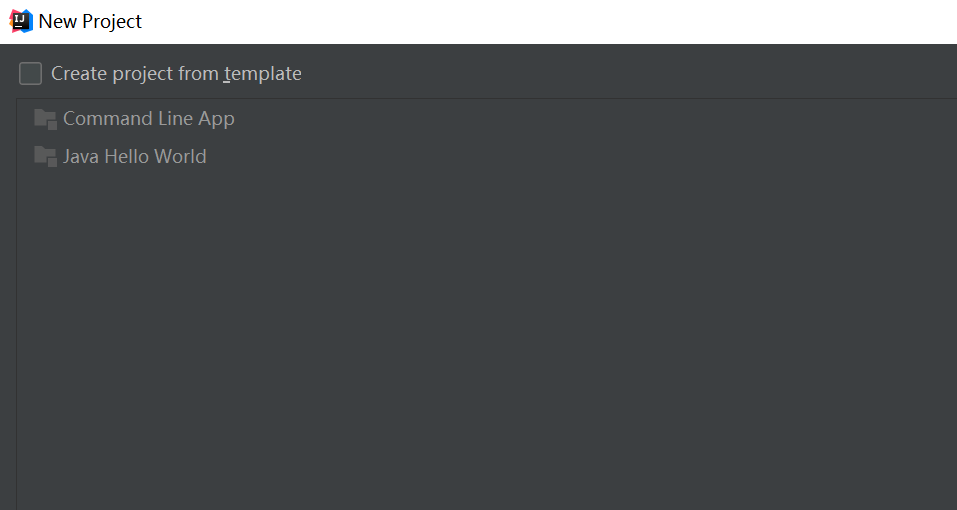
在弹出新建工程的界面选择Java,接着选择SDK,一般默认即可,点击“Next”按钮,如下图: 在弹出的选择创建项目的模板页面,不做任何操作,直接点击“Next”按钮。
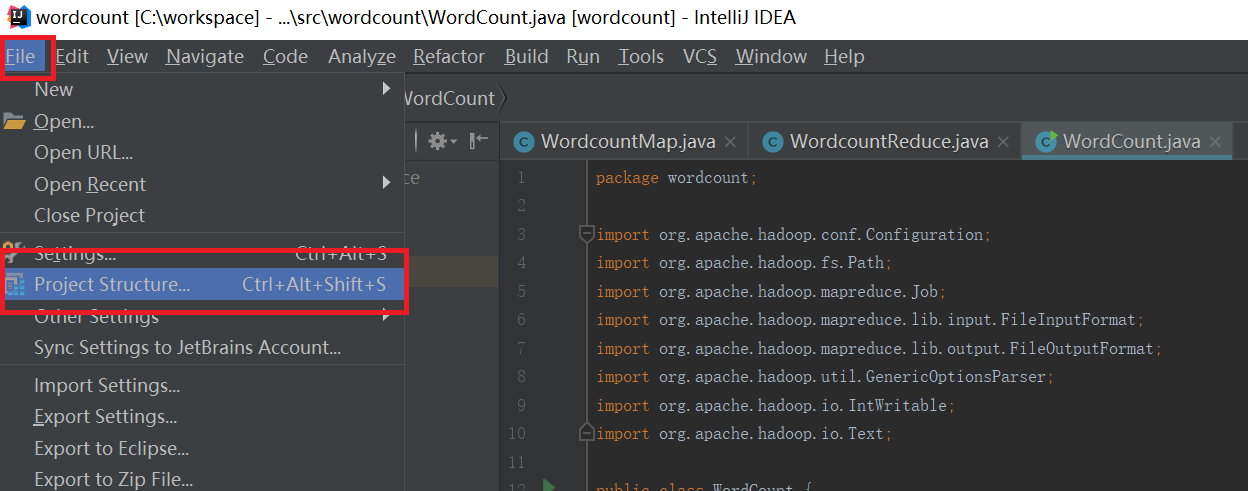
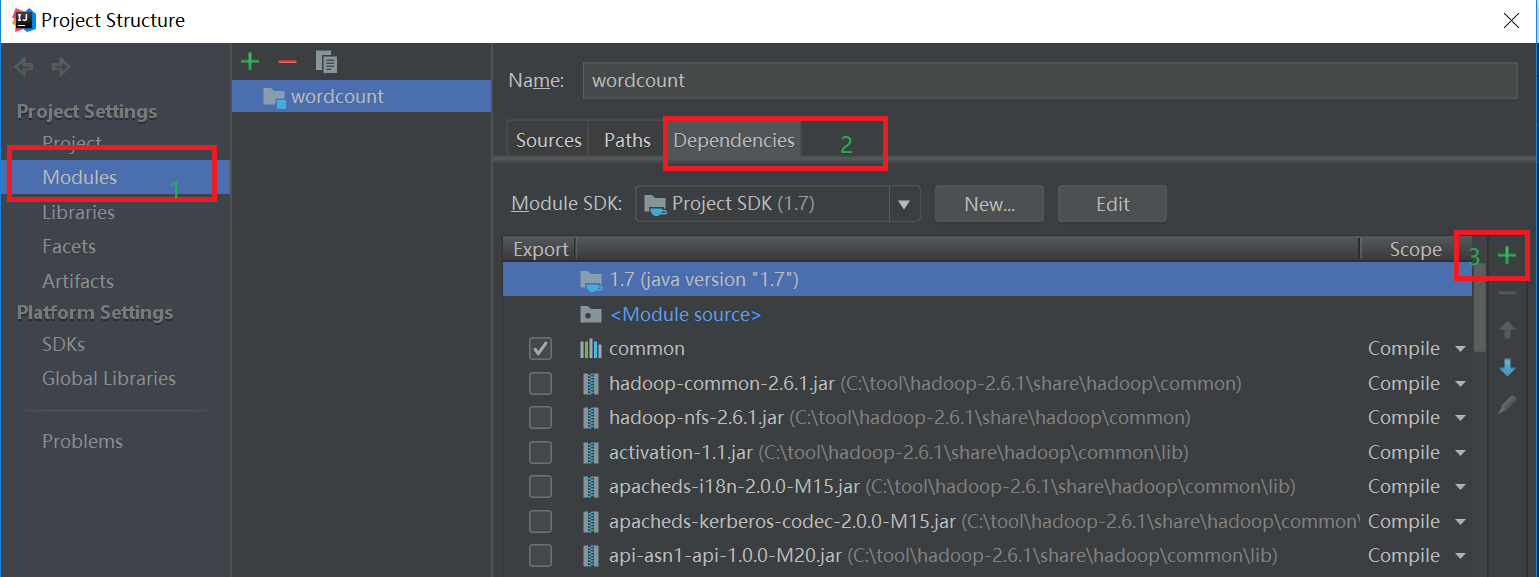
输入项目名称,点击Finish,就完成了创建新项目的工作,我们的项目名称为:WordCount。如下图所示: 添加依赖jar包,和Eclipse一样,要给项目添加相关依赖包,否则会出错。 点击Idea的File菜单,然后点击“Project Structure”菜单,如下图所示: 依次点击Modules和Dependencies,然后选择“+”的符号,如下图所示:
选择hadoop的包,我用得是hadoop2.6.1。把下面的依赖包都加入到工程中,否则会出现某个类找不到的错误。 (1)”/usr/local/hadoop/share/hadoop/common”目录下的hadoop-common-2.6.1.jar和haoop-nfs-2.6.1.jar; (2)/usr/local/hadoop/share/hadoop/common/lib”目录下的所有JAR包; (3)“/usr/local/hadoop/share/hadoop/hdfs”目录下的haoop-hdfs-2.6.1.jar和haoop-hdfs-nfs-2.7.1.jar; (4)“/usr/local/hadoop/share/hadoop/hdfs/lib”目录下的所有JAR包。
工程已经创建好,我们开始编写Map类、Reduce类和运行MapReduce的入口类: JAVA编写MarReduce代码 Map类如下: 1 import org.apache.hadoop.io.IntWritable; 2 3 import org.apache.hadoop.io.LongWritable; 4 5 import org.apache.hadoop.io.Text; 6 7 import org.apache.hadoop.mapreduce.Mapper; 8 9 import java.io.IOException; 10 11 12 public class WordcountMap extends Mapper { 13 public void map(LongWritable key,Text value,Context context)throws IOException,InterruptedException{ 14 15 String line = value.toString();//读取一行数据 16 17 String str[] = line.split("");//因为英文字母是以“ ”为间隔的,因此使用“ ”分隔符将一行数据切成多个单词并存在数组中 18 19 for(String s :str){//循环迭代字符串,将一个单词变成形式,及 20 context.write(new Text(s),new IntWritable(1)); 21 } 22 } 23 }
Reudce类: 1 import org.apache.hadoop.io.IntWritable; 2 import org.apache.hadoop.mapreduce.Reducer; 3 import org.apache.hadoop.io.Text; 4 import java.io.IOException; 5 6 public class WordcountReduce extends Reducer { 7 public void reduce(Text key, Iterable values,Context context)throws IOException,InterruptedException{ 8 int count = 0; 9 for(IntWritable value: values) { 10 count++; 11 } 12 context.write(key,new IntWritable(count)); 13 } 14 }
入口类 : 1 import org.apache.hadoop.conf.Configuration; 2 import org.apache.hadoop.fs.Path; 3 import org.apache.hadoop.mapreduce.Job; 4 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 5 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 6 import org.apache.hadoop.util.GenericOptionsParser; 7 import org.apache.hadoop.io.IntWritable; 8 import org.apache.hadoop.io.Text; 9 10 public class WordCount { 11 12 public static void main(String[] args)throws Exception{ 13 Configuration conf = new Configuration(); 14 //获取运行时输入的参数,一般是通过shell脚本文件传进来。 15 String [] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs(); 16 if(otherArgs.length < 2){ 17 System.err.println("必须输入读取文件路径和输出路径"); 18 System.exit(2); 19 } 20 Job job = new Job(); 21 job.setJarByClass(WordCount.class); 22 job.setJobName("wordcount app"); 23 24 //设置读取文件的路径,都是从HDFS中读取。读取文件路径从脚本文件中传进来 25 FileInputFormat.addInputPath(job,new Path(args[0])); 26 //设置mapreduce程序的输出路径,MapReduce的结果都是输入到文件中 27 FileOutputFormat.setOutputPath(job,new Path(args[1])); 28 29 //设置实现了map函数的类 30 job.setMapperClass(WordcountMap.class); 31 //设置实现了reduce函数的类 32 job.setReducerClass(WordcountReduce.class); 33 34 //设置reduce函数的key值 35 job.setOutputKeyClass(Text.class); 36 //设置reduce函数的value值 37 job.setOutputValueClass(IntWritable.class); 38 System.exit(job.waitForCompletion(true) ? 0 :1); 39 } 40 }
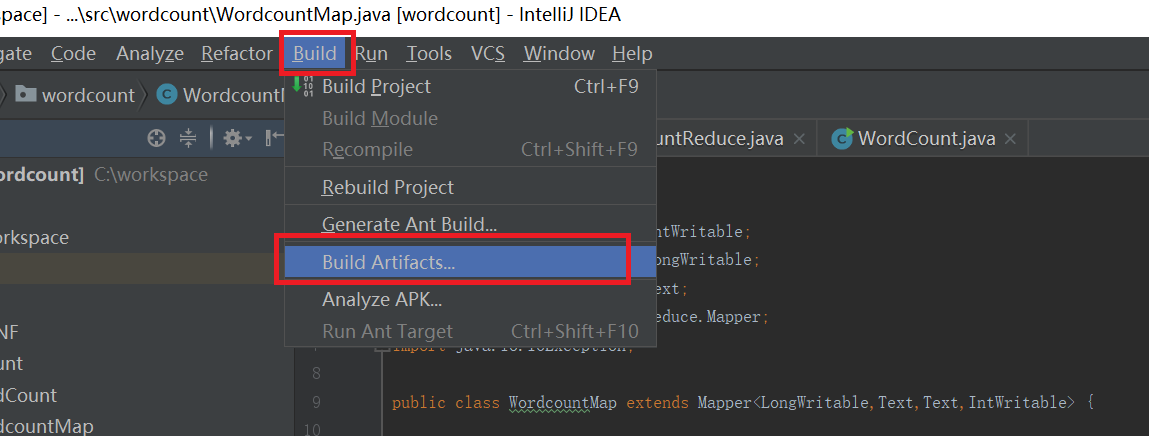
代码写好之后,开始jar包,按照下图打包。点击“File”,然后点击“Project Structure”,弹出如下的界面,
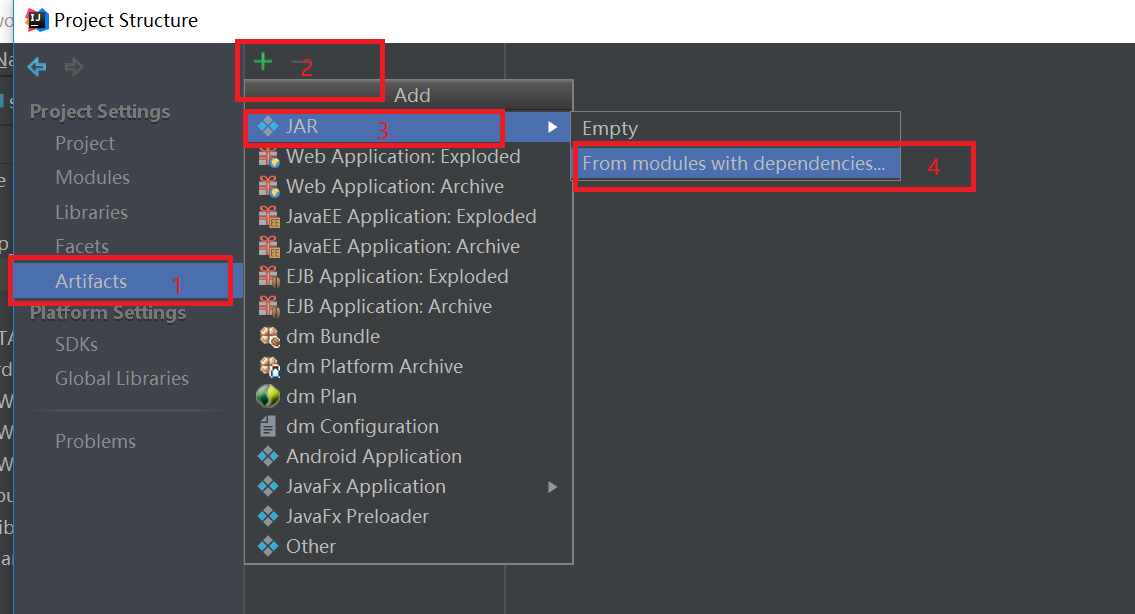
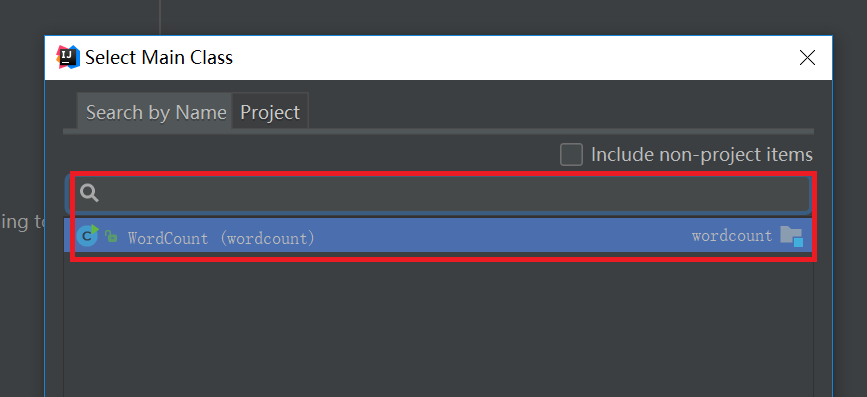
依次点击"Artifacts" -> "+" -> "JAR" -> "From modules with dependencies",然后弹出一个选择入口类的界面,选择刚刚写好的WordCount类,如下图: 按照上面设置好之后,就开始打jar包,如下图:
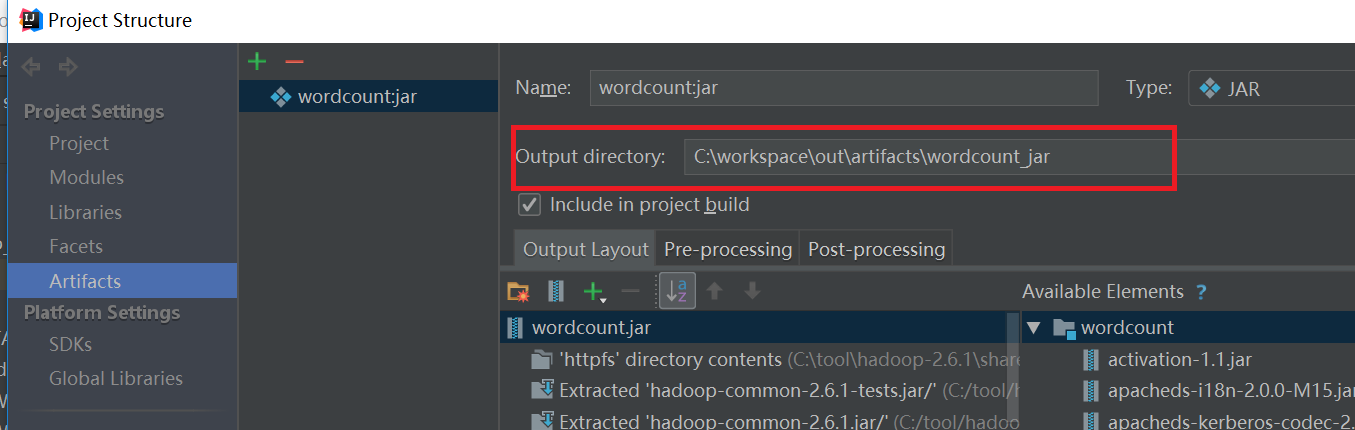
点击上图的“Build”之后就会生成一个jar包。jar的位置看下图,依次点击File->Project Structure->Artifacts就会看到如下的界面:
将打好包的wordcount.jar文件上传到装有hadoop集群的机器中,然后创建shell文件,shell文件内容如下,/usr/local/src/hadoop-2.6.1是hadoop集群中hadoop的安装位置, 1 /usr/local/src/hadoop-2.6.1/bin/hadoop jar wordcount.jar \ #执行jar文件的命令以及jar文件名, 2 3 hdfs://hadoop-master:8020/data/english.txt \ #输入路径 4 5 hdfs://hadoop-master:8020/wordcount_output #输出路径
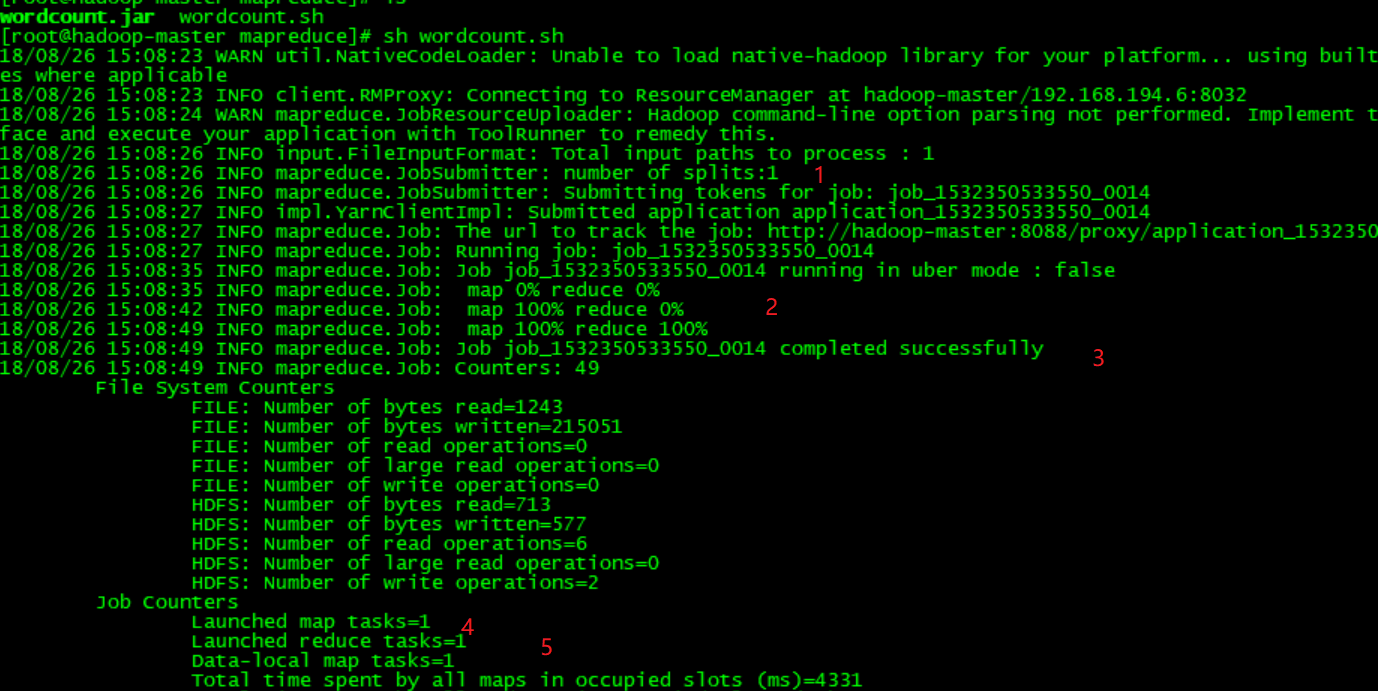
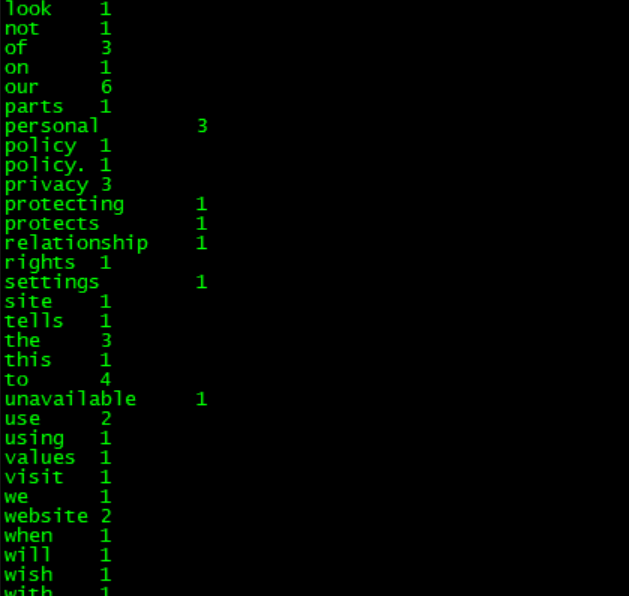
执行shell文件之后,会看到如下的信息, 上图中数字1表示输入分片split的数量,数字2表示map和reduce的进度,数字3表示mapreduce执行成功,数字4表示启动多少个map任务,数字5表示启动多少个reduce任务。 自行成功后在hadoop集群中的hdfs文件系统中会看到一个wordcount_output的文件夹。使用“hadoop fs -ls /”命令查看: 在wordcount_output文件夹中有两个文件,分别是_SUCCESS和part-r-00000,part-r-00000记录着mapreduce的执行结果,使用hadoop fs -cat /wordcount_output/part-r-00000查看part-r-00000的内容: 可以每个英文单词出现的次数。 至此,借助idea 2018工具开发第一个使用java语言编写的mapreduce程序已经成功执行。下面介绍使用python语言编写的第一个mapreduce程序,相对于java,python编写mapreduce会简单很多,因为hadoop提供streaming,streaming是使用Unix标准流作为Hadoop和应用程序之间的接口,所以可以使用任何语言通过标准输入输出来写MapReduce程序。 Python编写MapReduce程序 看代码: 实现了map函数的python程序,命名为map.py: 1 #!/usr/local/bin/python 2 3 import sys #导入sys包 4 5 for line in sys.stdin: #从标准输入中读取数据 6 ss = line.strip().split(' ')#读取每一行数据,strip()函数过滤掉空格换行的字符,split(' ')分隔出每个额单词并存放在数组ss中 7 8 for s in ss: #读取数组ss中的每个单词 9 if s.strip() != "": 10 print "%s\t%s" % (s, 1)#构造以单词为key,1为value的键值对,并写入到标准输出中。
实现了reduce函数的python程序,命名为reduce.py: 1 import sys 2 cur_word = None 3 sum = 0 4 for line in sys.stdin: 5 ss = line.strip().split('\t')#从标准输入中读取数据。 6 if len(ss) != 2: 7 continue 8 word,cnt = ss 9 if cur_word == None: 10 cur_word = word 11 #因为从map流转到reduce的数据时按照key排好序的,cur_word记录的是上一个单词,word记 #录的是当前读取的单词,如果两个单词一致,则将sum+1,否则将word和sum值组成一个键值对,##写入到标准输出,同时sum赋值为0,并且将word赋值给cur_word变量。 12 if cur_word != word: 13 print '\t'.join([cur_word,str(sum)]) 14 cur_word = word 15 sum = 0 16 sum += int(cnt) 17 print '\t'.join([cur_word,str(sum)])
map和reduce程序已经编写完毕,下面编写shell脚本文件: 1 HADOOP_CMD="/usr/local/src/hadoop-2.6.1/bin/hadoop" 2 STREAM_JAR_PATH="/usr/local/src/hadoop-2.6.1/share/hadoop/tools/lib/hadoop-streaming-2.6.1.jar " 3 4 INPUT_FILE_PATH_1="/data/english.txt"#输入路径 5 OUTPUT_PATH="/wordcount_output"#输出路径 6 $HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH#每次执行时都删除输出路径,否则会出错 7 8 $HADOOP_CMD jar $STREAM_JAR_PATH \ 9 -input $INPUT_FILE_PATH_1 \#指定输入路径 10 -output $OUTPUT_PATH \#指定输出路径 11 -mapper "python map.py" \#指定要执行的map程序 12 -reducer "python reduce.py" \#指定要执行reduce程序 13 -file ./map.py \#指定map程序所在的位置 14 -file ./reduce.py#指定reduce程序所在的位置到此Java和Python编写第一个MapReduce程序已经完成。 |



【本文地址】