| python+selenium实现的谷歌爬虫(超详细) | 您所在的位置:网站首页 › 怎么在谷歌上搜网站 › python+selenium实现的谷歌爬虫(超详细) |
python+selenium实现的谷歌爬虫(超详细)
|
python+selenium实现的谷歌爬虫
接到一个需求,需要从谷歌图库中爬取图片。于是按照之前的爬取国内网站的图片的方法,进入谷歌图库的图片页面,打开谷歌开发者工具,选中network面板,然后翻页,以此找到返回图片地址的json数组的请求url,结果硬是找不到。在这里不得不说,国外的网站安全性比国内还是要高,国内的什么百度图库、搜狗图库、一些图片收费网站按照上面的方法轻松爬取。 既然此路不通,那就换一种方法,在此选择了使用selenium自动化测试工具来配合python完成爬虫。 1、seleniumSelenium 是一款强大的基于浏览器的开源自动化测试工具,最初由 Jason Huggins 于 2004 年在 ThoughtWorks 发起,它提供了一套简单易用的 API,模拟浏览器的各种操作,方便各种 Web 应用的自动化测试。 Selenium 的初衷是打造一款优秀的自动化测试工具,但是慢慢的人们就发现,Selenium 的自动化用来做爬虫正合适。我们知道,传统的爬虫通过直接模拟 HTTP 请求来爬取站点信息,由于这种方式和浏览器访问差异比较明显,很多站点都采取了一些反爬的手段,而 Selenium 是通过模拟浏览器来爬取信息,其行为和用户几乎一样,反爬策略也很难区分出请求到底是来自 Selenium 还是真实用户。而且通过 Selenium 来做爬虫,不用去分析每个请求的具体参数,比起传统的爬虫开发起来更容易。Selenium 爬虫唯一的不足是慢,如果你对爬虫的速度没有要求,那使用 Selenium 是个非常不错的选择。Selenium 提供了多种语言的支持(Java、.NET、Python、Ruby 等)。 selenium安装参照下面地址的博客,网上关于这个很多。 https://blog.csdn.net/sinat_35100573/article/details/80272040 2、 爬虫实现思路selenium就是用来模拟浏览器操作的,在这里我们首先首先打开浏览器进入谷歌首页:https://www.google.com.hk/,然后找到搜索输入框,通过selenium的API得到输入框对象 input=browser.find_elements_by_xpath("//input[@class=‘gLFyf gsfi’]")[0]
input.send_keys(“路飞”) input.send_keys(Keys.ENTER) #按下enter键
a = browser.find_element_by_xpath("//div[@id=‘hdtb-msb-vis’]/div[2]/a") a.click() 进入到页面之后,我们就可以拿到页面的html源码,找到图片的url地址,然后利用xpath或者bs4、正则等提取图片的的url js = “q=document.documentElement.scrollTop=1903” # 将页面滚动条往下拖 browser.execute_script(js) 总结 : 利用selenium实现的爬虫逻辑上非常简单,代码的具体实现多在网上找找资料也没什么难度。 3、完整代码博主码子不易,阅读完了,点个赞呗! from selenium import webdriver from selenium.webdriver.chrome.options import Options import time from selenium.webdriver.common.keys import Keys import lxml from lxml import etree import os import urllib.request import json import uuid def get_image_urls(keyword,path): #创建一个参数对象,用来控制chrome以无界面模式打开 ch_op = Options() #设置谷歌浏览器的页面无可视化 ch_op.add_argument('--headless') ch_op.add_argument('--disable-gpu') ch_op.add_argument('blink-settings=imagesEnabled=false') # 不加载图片, 提升速度 url = "https://www.google.com.hk/" browser = webdriver.Chrome(chrome_options=ch_op) browser.get(url) time.sleep(2) input=browser.find_elements_by_xpath("//input[@class='gLFyf gsfi']")[0] input.send_keys(keyword) input.send_keys(Keys.ENTER) #按下enter键 time.sleep(2) # browser.save_screenshot('4.png') #截图 # a=browser.find_elements_by_link_text("图片") # hdtb-msb-vis hdtb-mitem hdtb-imb a = browser.find_element_by_xpath("//div[@id='hdtb-msb-vis']/div[2]/a") a.click() # 因为WebDriver驱动中没有提供对滚动条相应的方法,所以需要借助JS中的方法来控制滚动条 # 再通过WebDriver中的execute_script()执行JS代码 js = "q=document.documentElement.scrollTop=1903" # 将页面滚动条拖到底部 browser.execute_script(js) time.sleep(5) response = browser.page_source response = lxml.etree.HTML(response) image_urls = response.xpath("//div[@jscontroller='Q7Rsec']/div[@class='rg_meta notranslate']/text()") print(len(image_urls)) for m in image_urls: try: image_url = str2json(m) print(image_url) download_pic(image_url,str(uuid.uuid1()),path) except Exception as e: print(e) continue # browser.quit() def download_pic(url,name,path): ''' 下载图片 :param url: 图片url :param name: 图片名字 :param path: 图片存储路径 ''' if not os.path.exists(path): os.makedirs(path) res=urllib.request.urlopen(url,timeout=5).read() with open(path+name+'.jpg','wb') as file: file.write(res) file.close() def str2json(strs): ''' 字符串转换为json,并得到json对象值 :param strs: 字符串 :return: 图片url ''' strjson = json.loads(strs) image_url = strjson.get('ou') return image_url if __name__ == '__main__': keywords = ['路飞','娜美','索隆'] path = 'd:\\谷歌爬虫' for keyword in keywords: try: temp = path +"\\"+keyword+"\\" if not os.path.exists(temp): os.makedirs(temp) get_image_urls(keyword,temp) except Exception as e: print(str(e)) print(keyword+"——下载出错") continue |
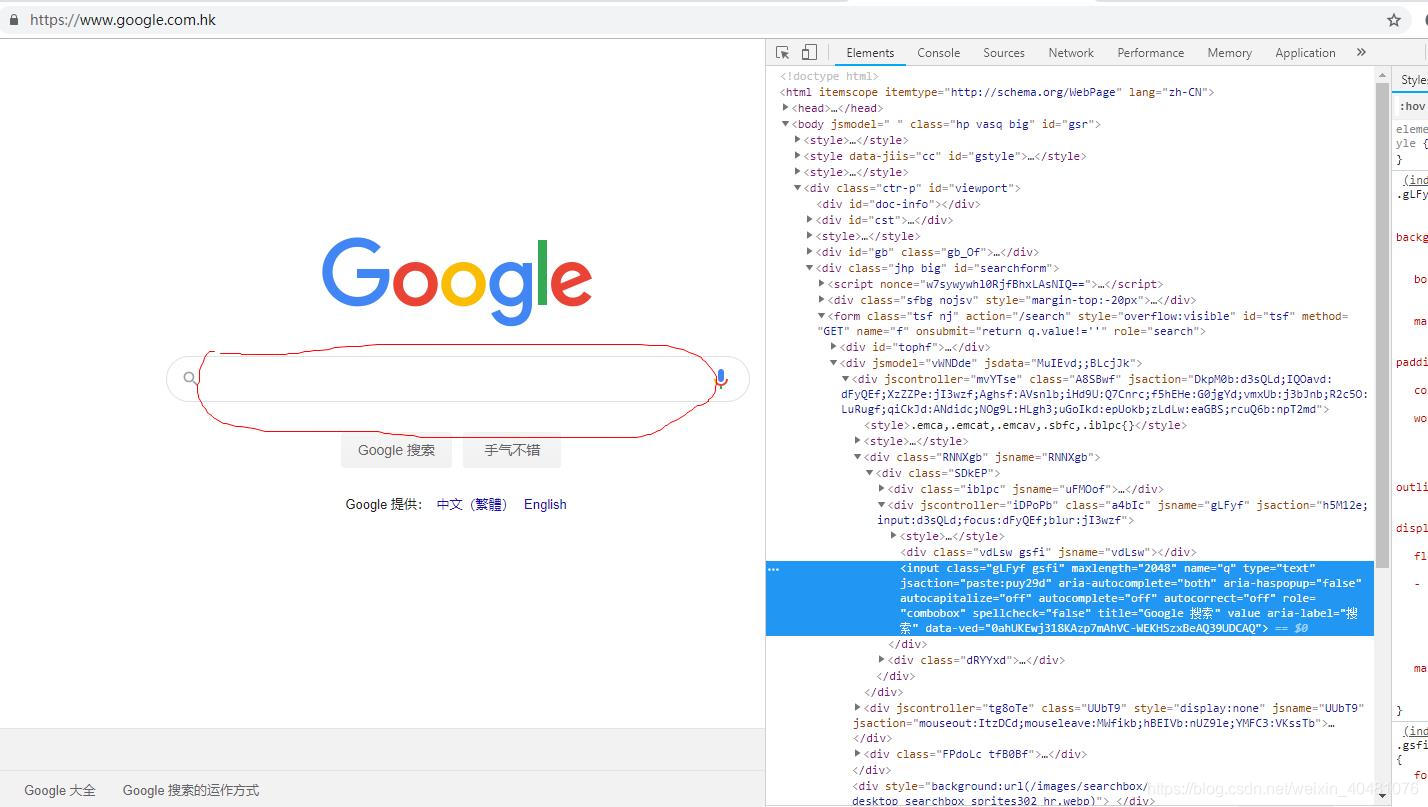 接下来在输入框中写入关键字,按下enter键即会搜索
接下来在输入框中写入关键字,按下enter键即会搜索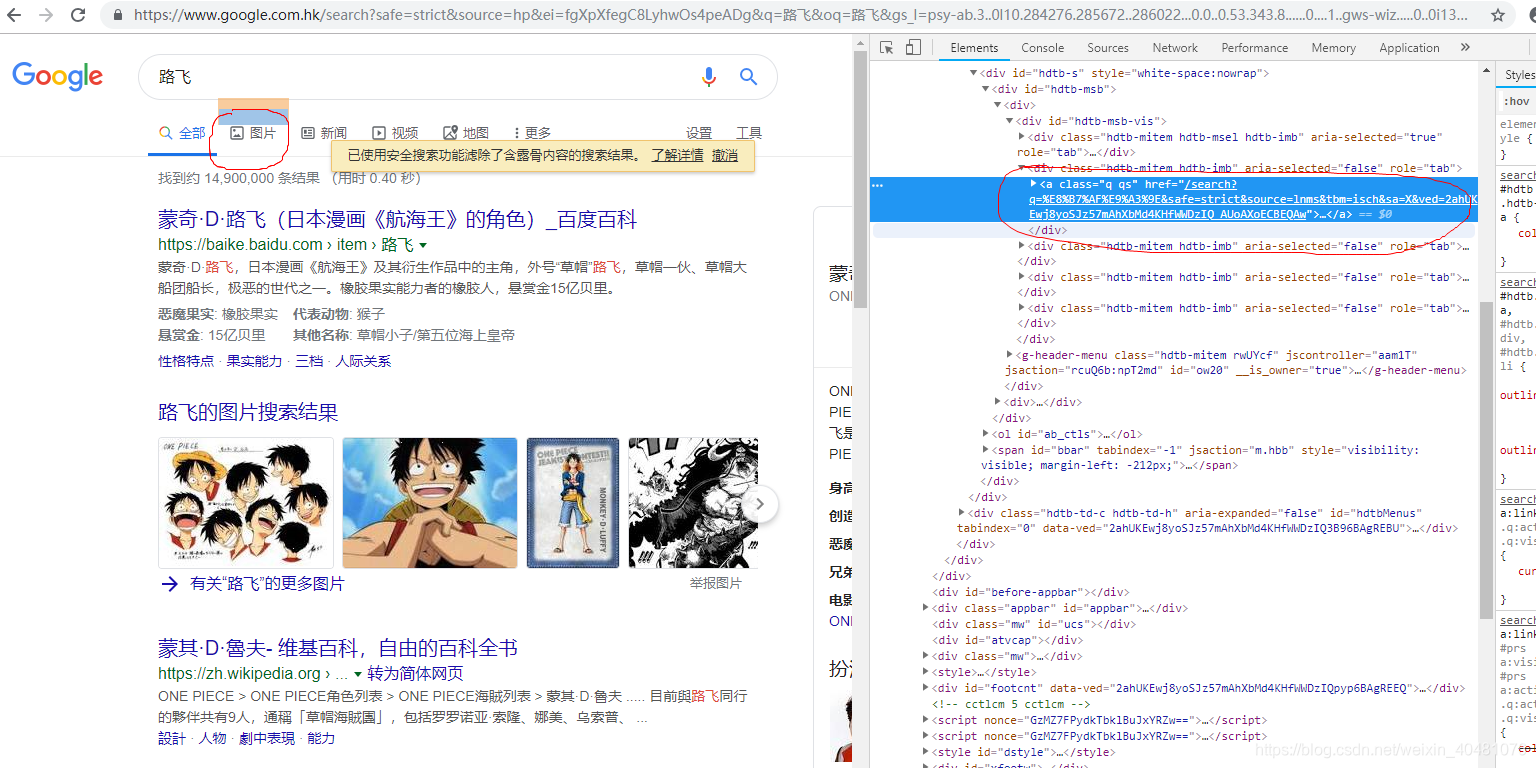 进入到上面这个页面,在点击“图片”这个超链接就进入到了谷歌图库页面
进入到上面这个页面,在点击“图片”这个超链接就进入到了谷歌图库页面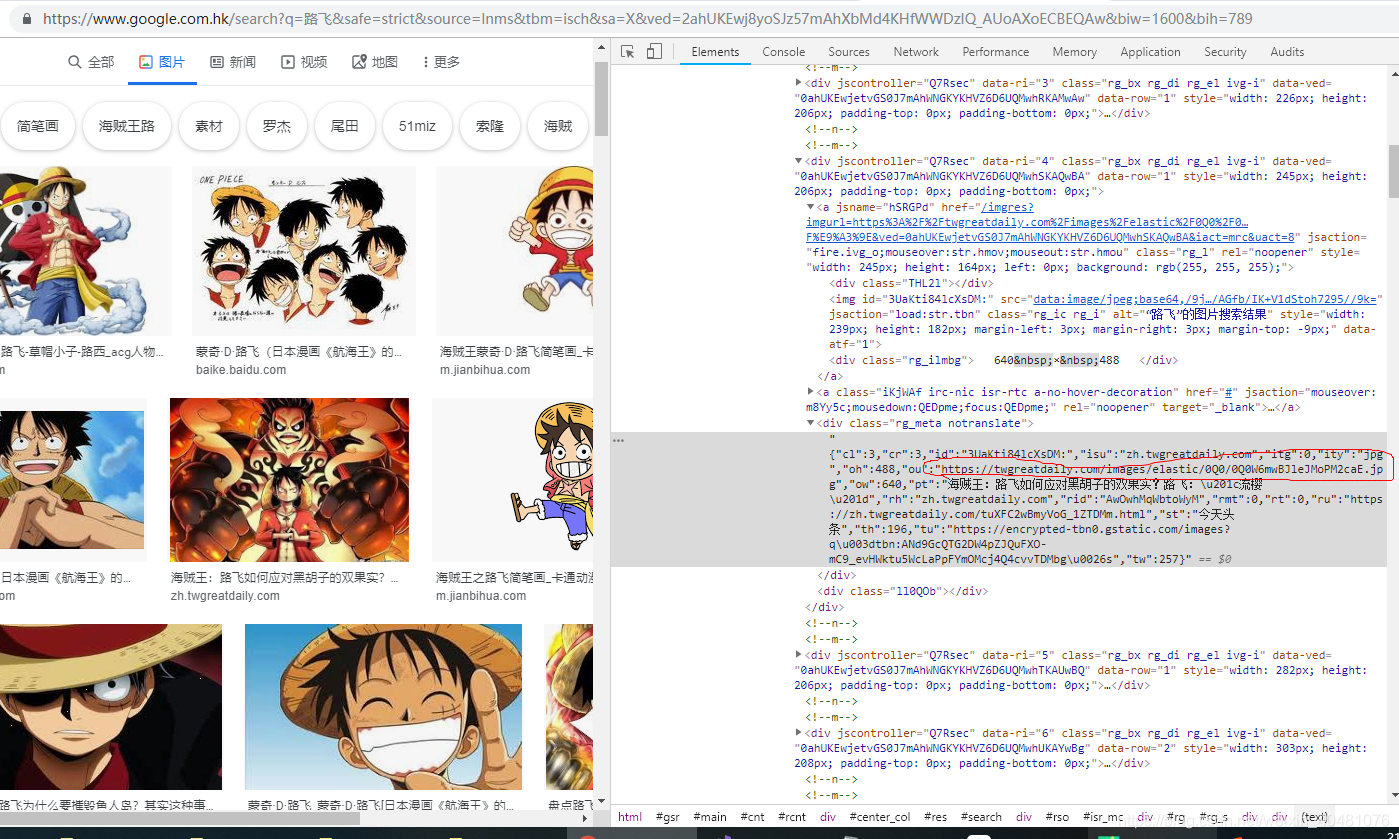 但是,这样操作之后发现我们在这个页面提取到的url数量只有三十多个,这是为什么呢?因为谷歌图库的图片是动态加载的,我们这个才是第一页,那我们该怎样才能获取到更多的数据呢?此页面的翻页是滑动页面右侧的滚动条进行翻页的,但是selenium的WebDriver驱动中没有提供对滚动条相应的方法,所以需要借助JS中的方法来控制滚动条,再通过WebDriver中的execute_script()执行JS代码。
但是,这样操作之后发现我们在这个页面提取到的url数量只有三十多个,这是为什么呢?因为谷歌图库的图片是动态加载的,我们这个才是第一页,那我们该怎样才能获取到更多的数据呢?此页面的翻页是滑动页面右侧的滚动条进行翻页的,但是selenium的WebDriver驱动中没有提供对滚动条相应的方法,所以需要借助JS中的方法来控制滚动条,再通过WebDriver中的execute_script()执行JS代码。【本文地址】