| python爬虫 | 您所在的位置:网站首页 › 怎么在百度上图片搜索 › python爬虫 |
python爬虫
|
参考:python 爬取动态网页(百度图片) 说明:在上面这位博主的贴子的基础上做了一些改进,解决了有些URL无法访问导致的请求超时异常抛出致使程序退出的问题。话不多说,直接上代码。 import re import os from urllib import parse from urllib import request # 网页地址 正则表达式 url = ('https://image.baidu.com/search/acjson?' 'tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&' 'queryWord={word}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&' 'word={word}&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=&fr=&' 'pn={pn}&rn=30&gsm=5a&1516945650575=') pattern = '"thumbURL":"(.+?\.jpg)"' # 输入需要下载数量和关键字 返回获取所有搜索页面url def geturls(num,word): word = parse.quote(word) urls = [] pn = (num//30+1)*30 for i in range(30,pn+1,30): urls.append(url.format(word = word,pn = i)) return urls # 输入需要下载数量和搜索页面urls 返回所有图片urls def getimgs(num,urls): imgs = [] reg = re.compile(pattern) for url in urls: page = request.urlopen(url) code = page.read() code = code.decode('utf-8') imgs.extend(reg.findall(code)) #print(code) return imgs if __name__ == '__main__': # 搜索关键字 下载数量 存放路径 word = '苹果' num = 100 path = r'D:\360MoveData\Users\lenovo\Desktop\img' # 判断图片保存路径是否存在,不存在就创建 if not os.path.exists(path): os.mkdir(path) print('路径不存在,但已新建') #进入百度图片搜索网页,搜索关键字,获取num整除30页图片搜索页面的地址列表 urls = geturls(num,word)#百度搜索页面地址 #打开urls列表中的url,用正则表达式搜索以.jpg结尾的图片源地址url,保存到imgs列表中,imgs中的url是30的倍数 imgs = getimgs(num,urls)#图片地址 i = 0#下载序号 j = 0#请求超时数量 for img in imgs: i +=1 try: request.urlretrieve(img,path +'/'+ '%s.jpg' %(i-j))#将图片下载到指定目录 except OSError as err:#下载超时处理 print('下载第%s图片时请求超时,已跳过该图片' % (i-j)) j +=1 else: print('成功下载第'+str(i-j)+'张图片') if (i-j)>=num:#判断是不是下载量达到指定数量 print('下载图片完毕,成功下载%d张照片,跳过%d张照片'%((i-j),j)) break程序运行截图。 |
 打开目标文件夹,查看下载的图片。
打开目标文件夹,查看下载的图片。 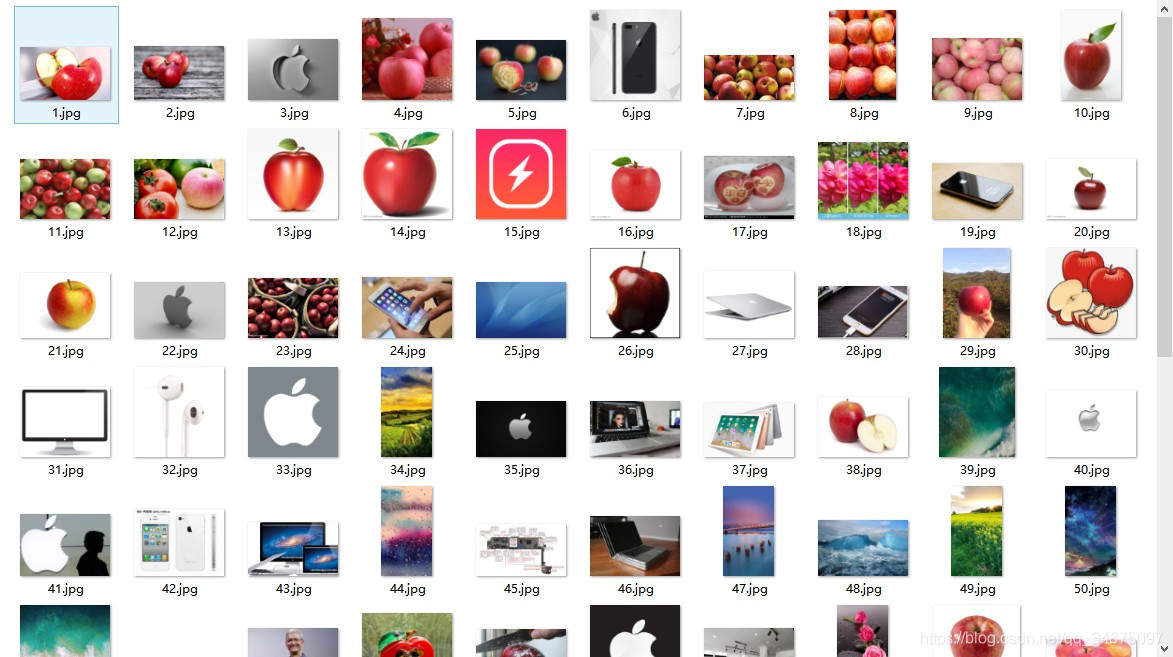 用关键字“苹果”进行搜索,搜出了好多苹果手机的图片。。。后面用关键字“水果苹果”进行爬取,就好很多了。
用关键字“苹果”进行搜索,搜出了好多苹果手机的图片。。。后面用关键字“水果苹果”进行爬取,就好很多了。【本文地址】
公司简介
联系我们