| 【pandas数据清洗与处理】项目7 | 您所在的位置:网站首页 › 影视作品评分标准 › 【pandas数据清洗与处理】项目7 |
【pandas数据清洗与处理】项目7
|
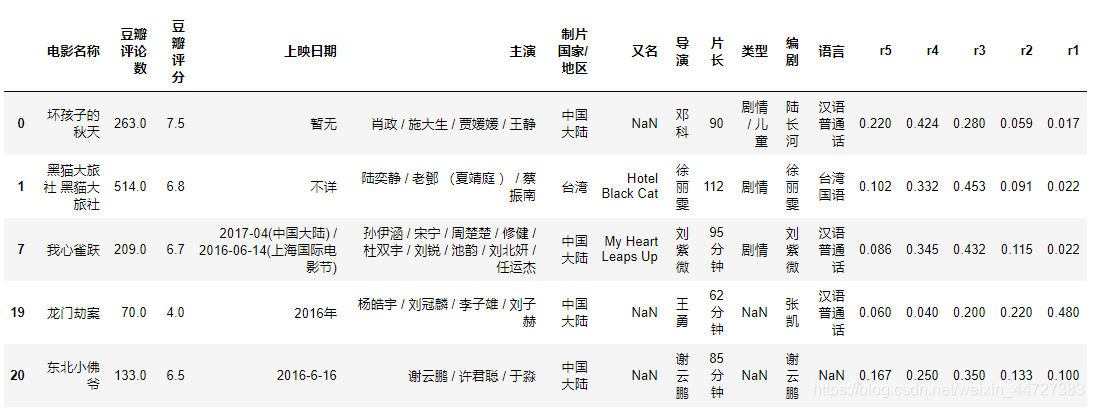
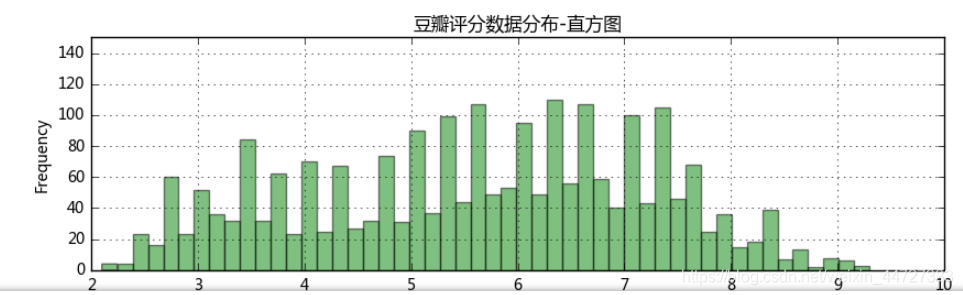
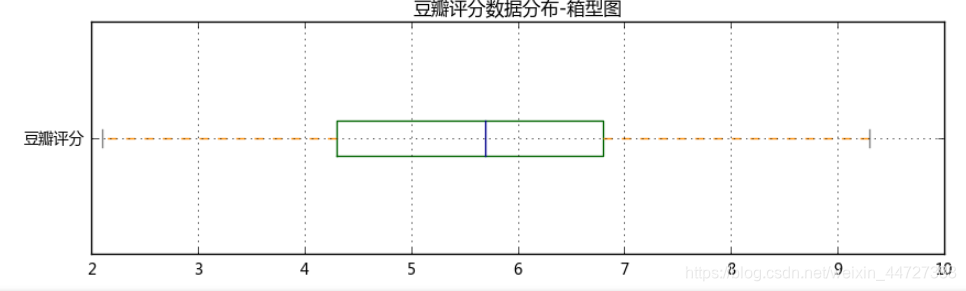
1、读取数据,以“豆瓣评分”为标准,看看电影评分分布,及烂片情况 要求: ① 读取数据“moviedata.xlsx” ② 查看“豆瓣评分”数据分布,绘制直方图、箱型图 ③ 判断“豆瓣评”数据是否符合正态分布 ④ 如果符合正态分布,这里以上四分位数(该样本中所有数值由小到大排列后第25%的数字)评分为“烂片标准” ⑤ 筛选出烂片数据,并做排名,找到TOP20 提示: ① 读取数据之后去除缺失值 ② 这里可以用ks检验来判断数据是否符合正态分布 import numpy as np import pandas as pd import matplotlib.pyplot as plt % matplotlib inline import warnings warnings.filterwarnings('ignore') # 不发出警告 from bokeh.io import output_notebook output_notebook() # 导入notebook绘图模块 from bokeh.plotting import figure,show from bokeh.models import ColumnDataSource,HoverTool # 导入图表绘制、图标展示模块 # 导入ColumnDataSource模块 # 查看数据,数据清洗 df = pd.read_excel('moviedata.xlsx') df = df[df['豆瓣评分'] > 0] print('初步清洗后数据量为%i条' % len(df)) # 读取数据 # 删除“豆瓣评分”小于等于0的值 df.head() #查看数据
count 2306.000000 mean 5.604250 std 1.595514 min 2.100000 25% 4.300000 50% 5.700000 75% 6.800000 max 9.300000 Name: 豆瓣评分, dtype: float64
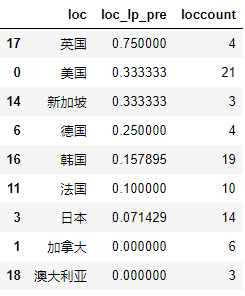
KstestResult(statistic=0.061493870089715519, pvalue=5.0506841597908192e-08) # 筛选出烂片数据,并做排名,找到TOP20 data_lp = df[df['豆瓣评分']} datai = data[data['制片国家/地区'].str.contains(loci)] # 筛选数据 lp_pre_i = len(datai[datai['豆瓣评分']=3] # 筛选合作电影大于等于3部以上的国家 loc_lp_top20 = df_loc_lp.sort_values(by = 'loc_lp_pre',ascending = False).iloc[:20] loc_lp_top20 # 筛选出烂片比例TOP的制片地 # 结论 # 综合来看,居然和欧美合作更可能产生烂片
4、卡司数量是否和烂片有关? 要求: ① 计算每部电影的主演人数 ② 按照主演人数分类,并统计烂片率 ** 分类:‘1-2人’,‘3-4人’,‘5-6人’,‘7-9人’,‘10以上’ ③ 查看烂片比例最高的演员TOP20 提示: ① 通过“主演”字段内做分列来计算主演人数 ② 需要分别统计不同主演人数的电影数量及烂片数量,再计算烂片比例 ③ 这里可以按照明星再查看一下他们的烂片率,比如:吴亦凡、杨幂、黄晓明、甄子丹、刘亦菲、范冰冰… # 计算每部电影的主演人数,并统计烂片率 # 分类:'1-2人','3-4人','5-6人','7-9人','10以上' df['主演人数'] = df['主演'].str.split('/').str.len() # 计算主演人数 df_leadrole1 = df[['主演人数','豆瓣评分']].groupby('主演人数').count() df_leadrole2 = df[['主演人数','豆瓣评分']][df['豆瓣评分']} lp_pre_i = len(datai[datai['豆瓣评分'] |
【本文地址】
公司简介
联系我们