| Ubuntu下使用darknet | 您所在的位置:网站首页 › 废钢数据集 › Ubuntu下使用darknet |
Ubuntu下使用darknet
|
目录 1.拍摄数据集 2.标注数据集 3.训练自己的数据集 make问题1: 原因1: 方法1: 注意: 注意: 训练命令行为: 训练问题记录: 问题1: 训练过程图为: 训练结束示意图为: 4.测试训练所得的权重 结论: 5.最后附上学习自己训练时参考的链接 1.拍摄数据集注意事项: 1.拍摄时,不用追求太清晰,640x480即可。 2.最好多角度、多距离拍摄,可以提高最后的检测效果。 3.每个类别拍摄400-500张即可。 订书机的拍摄示范如下:
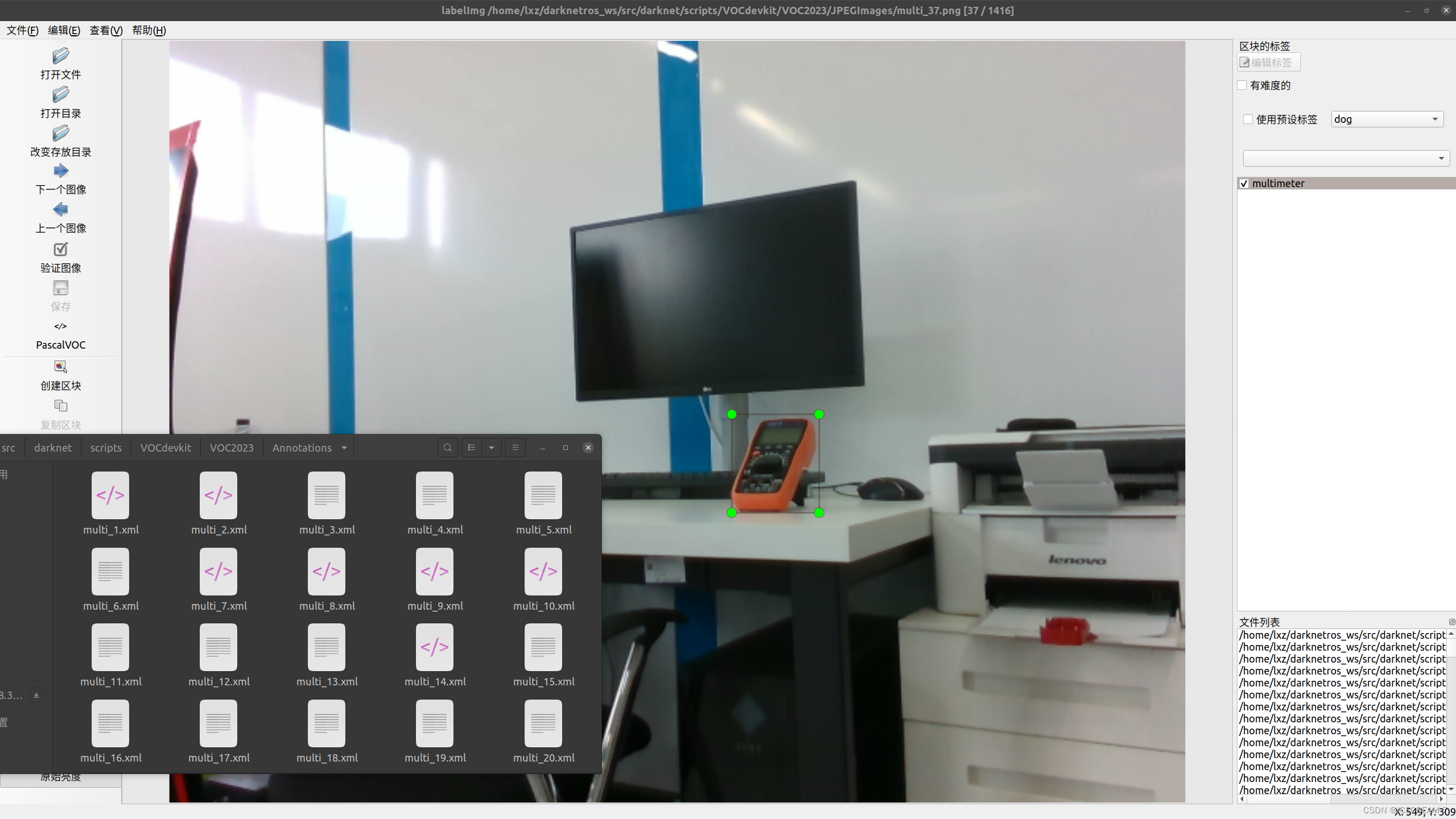
使用最常用的labelimg进行标注,格式为VOC格式,生成的标签为xml文件。 注意事项: 1.图片名称唯一,不可重复。 2.首先运行save_path.py(需要copy一下)保存所有训练集的名称,后执行voc_label.py代码。(应该需要稍微修改一下代码,尽量看懂一下,更方便修改) 3.yolo输入的标签为txt文件,因此需要执行voc_label.py代码,将xml文件转换为txt文件,该代码为包自带的。 数据集标注示范如下:
如果该包是catkin_make编译的,是不能直接执行训练命令的,需要make一下。路径为****_ws/src/darknet,执行make命令。 make问题1:报错如下:
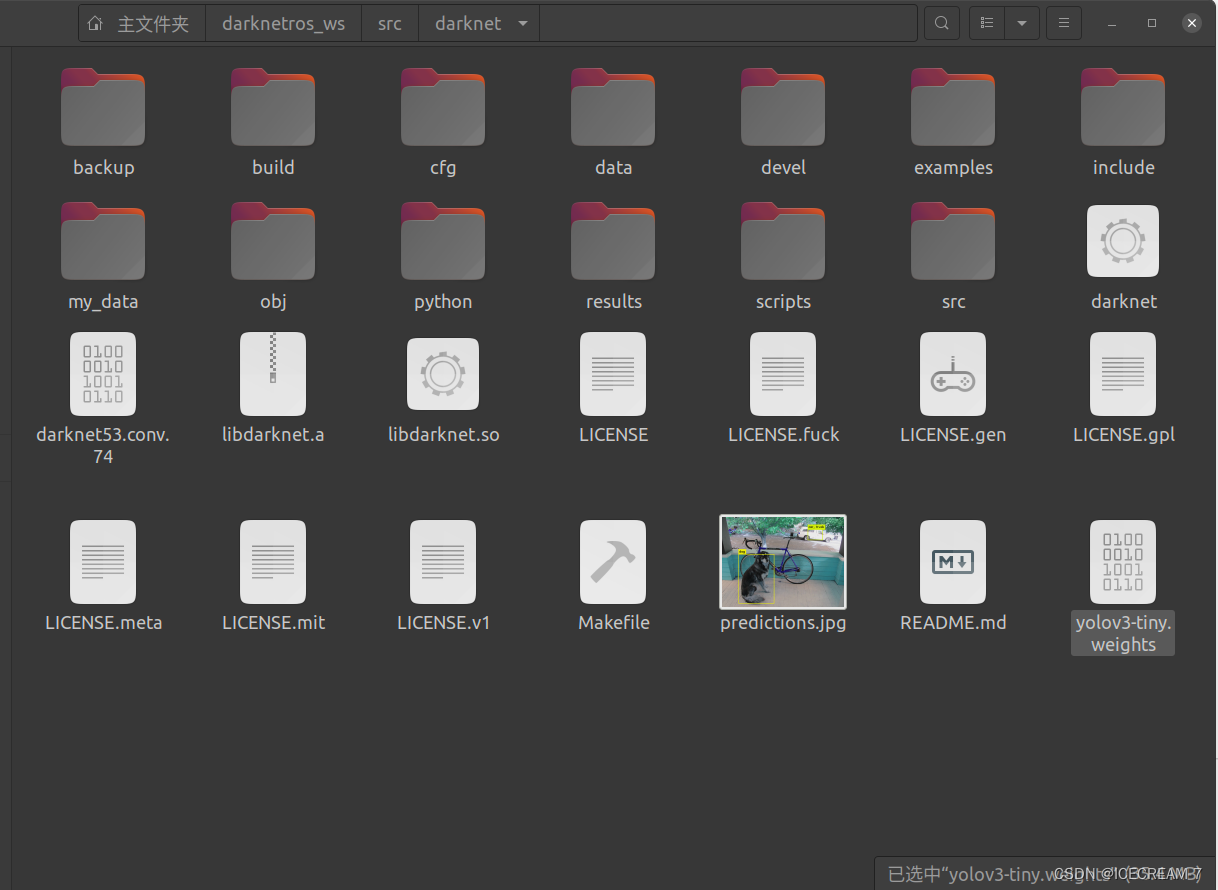
darknet较为老旧,其中包含的cuda相关的代码只写到7.0版本,需要修改。(建议直接将convolutional_layer.c文件中的代码全部替换) 方法1:该文件全部代码如下: #include "convolutional_layer.h" #include "utils.h" #include "batchnorm_layer.h" #include "im2col.h" #include "col2im.h" #include "blas.h" #include "gemm.h" #include #include #define PRINT_CUDNN_ALGO 0 #define MEMORY_LIMIT 2000000000 #ifdef AI2 #include "xnor_layer.h" #endif void swap_binary(convolutional_layer *l) { float *swap = l->weights; l->weights = l->binary_weights; l->binary_weights = swap; #ifdef GPU swap = l->weights_gpu; l->weights_gpu = l->binary_weights_gpu; l->binary_weights_gpu = swap; #endif } void binarize_weights(float *weights, int n, int size, float *binary) { int i, f; for(f = 0; f < n; ++f){ float mean = 0; for(i = 0; i < size; ++i){ mean += fabs(weights[f*size + i]); } mean = mean / size; for(i = 0; i < size; ++i){ binary[f*size + i] = (weights[f*size + i] > 0) ? mean : -mean; } } } void binarize_cpu(float *input, int n, float *binary) { int i; for(i = 0; i < n; ++i){ binary[i] = (input[i] > 0) ? 1 : -1; } } void binarize_input(float *input, int n, int size, float *binary) { int i, s; for(s = 0; s < size; ++s){ float mean = 0; for(i = 0; i < n; ++i){ mean += fabs(input[i*size + s]); } mean = mean / n; for(i = 0; i < n; ++i){ binary[i*size + s] = (input[i*size + s] > 0) ? mean : -mean; } } } int convolutional_out_height(convolutional_layer l) { return (l.h + 2*l.pad - l.size) / l.stride + 1; } int convolutional_out_width(convolutional_layer l) { return (l.w + 2*l.pad - l.size) / l.stride + 1; } image get_convolutional_image(convolutional_layer l) { return float_to_image(l.out_w,l.out_h,l.out_c,l.output); } image get_convolutional_delta(convolutional_layer l) { return float_to_image(l.out_w,l.out_h,l.out_c,l.delta); } static size_t get_workspace_size(layer l){ #ifdef CUDNN if(gpu_index >= 0){ size_t most = 0; size_t s = 0; cudnnGetConvolutionForwardWorkspaceSize(cudnn_handle(), l.srcTensorDesc, l.weightDesc, l.convDesc, l.dstTensorDesc, l.fw_algo, &s); if (s > most) most = s; cudnnGetConvolutionBackwardFilterWorkspaceSize(cudnn_handle(), l.srcTensorDesc, l.ddstTensorDesc, l.convDesc, l.dweightDesc, l.bf_algo, &s); if (s > most) most = s; cudnnGetConvolutionBackwardDataWorkspaceSize(cudnn_handle(), l.weightDesc, l.ddstTensorDesc, l.convDesc, l.dsrcTensorDesc, l.bd_algo, &s); if (s > most) most = s; return most; } #endif return (size_t)l.out_h*l.out_w*l.size*l.size*l.c/l.groups*sizeof(float); } #ifdef GPU #ifdef CUDNN void cudnn_convolutional_setup(layer *l) { cudnnSetTensor4dDescriptor(l->dsrcTensorDesc, CUDNN_TENSOR_NCHW, CUDNN_DATA_FLOAT, l->batch, l->c, l->h, l->w); cudnnSetTensor4dDescriptor(l->ddstTensorDesc, CUDNN_TENSOR_NCHW, CUDNN_DATA_FLOAT, l->batch, l->out_c, l->out_h, l->out_w); cudnnSetTensor4dDescriptor(l->srcTensorDesc, CUDNN_TENSOR_NCHW, CUDNN_DATA_FLOAT, l->batch, l->c, l->h, l->w); cudnnSetTensor4dDescriptor(l->dstTensorDesc, CUDNN_TENSOR_NCHW, CUDNN_DATA_FLOAT, l->batch, l->out_c, l->out_h, l->out_w); cudnnSetTensor4dDescriptor(l->normTensorDesc, CUDNN_TENSOR_NCHW, CUDNN_DATA_FLOAT, 1, l->out_c, 1, 1); cudnnSetFilter4dDescriptor(l->dweightDesc, CUDNN_DATA_FLOAT, CUDNN_TENSOR_NCHW, l->n, l->c/l->groups, l->size, l->size); cudnnSetFilter4dDescriptor(l->weightDesc, CUDNN_DATA_FLOAT, CUDNN_TENSOR_NCHW, l->n, l->c/l->groups, l->size, l->size); #if CUDNN_MAJOR >= 6 cudnnSetConvolution2dDescriptor(l->convDesc, l->pad, l->pad, l->stride, l->stride, 1, 1, CUDNN_CROSS_CORRELATION, CUDNN_DATA_FLOAT); #else cudnnSetConvolution2dDescriptor(l->convDesc, l->pad, l->pad, l->stride, l->stride, 1, 1, CUDNN_CROSS_CORRELATION); #endif #if CUDNN_MAJOR >= 7 cudnnSetConvolutionGroupCount(l->convDesc, l->groups); #else if(l->groups > 1){ error("CUDNN < 7 doesn't support groups, please upgrade!"); } #endif #if CUDNN_MAJOR >= 8 int returnedAlgoCount; cudnnConvolutionFwdAlgoPerf_t fw_results[2 * CUDNN_CONVOLUTION_FWD_ALGO_COUNT]; cudnnConvolutionBwdDataAlgoPerf_t bd_results[2 * CUDNN_CONVOLUTION_BWD_DATA_ALGO_COUNT]; cudnnConvolutionBwdFilterAlgoPerf_t bf_results[2 * CUDNN_CONVOLUTION_BWD_FILTER_ALGO_COUNT]; cudnnFindConvolutionForwardAlgorithm(cudnn_handle(), l->srcTensorDesc, l->weightDesc, l->convDesc, l->dstTensorDesc, CUDNN_CONVOLUTION_FWD_ALGO_COUNT, &returnedAlgoCount, fw_results); for(int algoIndex = 0; algoIndex < returnedAlgoCount; ++algoIndex){ #if PRINT_CUDNN_ALGO > 0 printf("^^^^ %s for Algo %d: %f time requiring %llu memory\n", cudnnGetErrorString(fw_results[algoIndex].status), fw_results[algoIndex].algo, fw_results[algoIndex].time, (unsigned long long)fw_results[algoIndex].memory); #endif if( fw_results[algoIndex].memory < MEMORY_LIMIT ){ l->fw_algo = fw_results[algoIndex].algo; break; } } cudnnFindConvolutionBackwardDataAlgorithm(cudnn_handle(), l->weightDesc, l->ddstTensorDesc, l->convDesc, l->dsrcTensorDesc, CUDNN_CONVOLUTION_BWD_DATA_ALGO_COUNT, &returnedAlgoCount, bd_results); for(int algoIndex = 0; algoIndex < returnedAlgoCount; ++algoIndex){ #if PRINT_CUDNN_ALGO > 0 printf("^^^^ %s for Algo %d: %f time requiring %llu memory\n", cudnnGetErrorString(bd_results[algoIndex].status), bd_results[algoIndex].algo, bd_results[algoIndex].time, (unsigned long long)bd_results[algoIndex].memory); #endif if( bd_results[algoIndex].memory < MEMORY_LIMIT ){ l->bd_algo = bd_results[algoIndex].algo; break; } } cudnnFindConvolutionBackwardFilterAlgorithm(cudnn_handle(), l->srcTensorDesc, l->ddstTensorDesc, l->convDesc, l->dweightDesc, CUDNN_CONVOLUTION_BWD_FILTER_ALGO_COUNT, &returnedAlgoCount, bf_results); for(int algoIndex = 0; algoIndex < returnedAlgoCount; ++algoIndex){ #if PRINT_CUDNN_ALGO > 0 printf("^^^^ %s for Algo %d: %f time requiring %llu memory\n", cudnnGetErrorString(bf_results[algoIndex].status), bf_results[algoIndex].algo, bf_results[algoIndex].time, (unsigned long long)bf_results[algoIndex].memory); #endif if( bf_results[algoIndex].memory < MEMORY_LIMIT ){ l->bf_algo = bf_results[algoIndex].algo; break; } } #else cudnnGetConvolutionForwardAlgorithm(cudnn_handle(), l->srcTensorDesc, l->weightDesc, l->convDesc, l->dstTensorDesc, CUDNN_CONVOLUTION_FWD_SPECIFY_WORKSPACE_LIMIT, 2000000000, &l->fw_algo); cudnnGetConvolutionBackwardDataAlgorithm(cudnn_handle(), l->weightDesc, l->ddstTensorDesc, l->convDesc, l->dsrcTensorDesc, CUDNN_CONVOLUTION_BWD_DATA_SPECIFY_WORKSPACE_LIMIT, 2000000000, &l->bd_algo); cudnnGetConvolutionBackwardFilterAlgorithm(cudnn_handle(), l->srcTensorDesc, l->ddstTensorDesc, l->convDesc, l->dweightDesc, CUDNN_CONVOLUTION_BWD_FILTER_SPECIFY_WORKSPACE_LIMIT, 2000000000, &l->bf_algo); #endif } #endif #endif convolutional_layer make_convolutional_layer(int batch, int h, int w, int c, int n, int groups, int size, int stride, int padding, ACTIVATION activation, int batch_normalize, int binary, int xnor, int adam) { int i; convolutional_layer l = {0}; l.type = CONVOLUTIONAL; l.groups = groups; l.h = h; l.w = w; l.c = c; l.n = n; l.binary = binary; l.xnor = xnor; l.batch = batch; l.stride = stride; l.size = size; l.pad = padding; l.batch_normalize = batch_normalize; l.weights = calloc(c/groups*n*size*size, sizeof(float)); l.weight_updates = calloc(c/groups*n*size*size, sizeof(float)); l.biases = calloc(n, sizeof(float)); l.bias_updates = calloc(n, sizeof(float)); l.nweights = c/groups*n*size*size; l.nbiases = n; // float scale = 1./sqrt(size*size*c); float scale = sqrt(2./(size*size*c/l.groups)); //printf("convscale %f\n", scale); //scale = .02; //for(i = 0; i < c*n*size*size; ++i) l.weights[i] = scale*rand_uniform(-1, 1); for(i = 0; i < l.nweights; ++i) l.weights[i] = scale*rand_normal(); int out_w = convolutional_out_width(l); int out_h = convolutional_out_height(l); l.out_h = out_h; l.out_w = out_w; l.out_c = n; l.outputs = l.out_h * l.out_w * l.out_c; l.inputs = l.w * l.h * l.c; l.output = calloc(l.batch*l.outputs, sizeof(float)); l.delta = calloc(l.batch*l.outputs, sizeof(float)); l.forward = forward_convolutional_layer; l.backward = backward_convolutional_layer; l.update = update_convolutional_layer; if(binary){ l.binary_weights = calloc(l.nweights, sizeof(float)); l.cweights = calloc(l.nweights, sizeof(char)); l.scales = calloc(n, sizeof(float)); } if(xnor){ l.binary_weights = calloc(l.nweights, sizeof(float)); l.binary_input = calloc(l.inputs*l.batch, sizeof(float)); } if(batch_normalize){ l.scales = calloc(n, sizeof(float)); l.scale_updates = calloc(n, sizeof(float)); for(i = 0; i < n; ++i){ l.scales[i] = 1; } l.mean = calloc(n, sizeof(float)); l.variance = calloc(n, sizeof(float)); l.mean_delta = calloc(n, sizeof(float)); l.variance_delta = calloc(n, sizeof(float)); l.rolling_mean = calloc(n, sizeof(float)); l.rolling_variance = calloc(n, sizeof(float)); l.x = calloc(l.batch*l.outputs, sizeof(float)); l.x_norm = calloc(l.batch*l.outputs, sizeof(float)); } if(adam){ l.m = calloc(l.nweights, sizeof(float)); l.v = calloc(l.nweights, sizeof(float)); l.bias_m = calloc(n, sizeof(float)); l.scale_m = calloc(n, sizeof(float)); l.bias_v = calloc(n, sizeof(float)); l.scale_v = calloc(n, sizeof(float)); } #ifdef GPU l.forward_gpu = forward_convolutional_layer_gpu; l.backward_gpu = backward_convolutional_layer_gpu; l.update_gpu = update_convolutional_layer_gpu; if(gpu_index >= 0){ if (adam) { l.m_gpu = cuda_make_array(l.m, l.nweights); l.v_gpu = cuda_make_array(l.v, l.nweights); l.bias_m_gpu = cuda_make_array(l.bias_m, n); l.bias_v_gpu = cuda_make_array(l.bias_v, n); l.scale_m_gpu = cuda_make_array(l.scale_m, n); l.scale_v_gpu = cuda_make_array(l.scale_v, n); } l.weights_gpu = cuda_make_array(l.weights, l.nweights); l.weight_updates_gpu = cuda_make_array(l.weight_updates, l.nweights); l.biases_gpu = cuda_make_array(l.biases, n); l.bias_updates_gpu = cuda_make_array(l.bias_updates, n); l.delta_gpu = cuda_make_array(l.delta, l.batch*out_h*out_w*n); l.output_gpu = cuda_make_array(l.output, l.batch*out_h*out_w*n); if(binary){ l.binary_weights_gpu = cuda_make_array(l.weights, l.nweights); } if(xnor){ l.binary_weights_gpu = cuda_make_array(l.weights, l.nweights); l.binary_input_gpu = cuda_make_array(0, l.inputs*l.batch); } if(batch_normalize){ l.mean_gpu = cuda_make_array(l.mean, n); l.variance_gpu = cuda_make_array(l.variance, n); l.rolling_mean_gpu = cuda_make_array(l.mean, n); l.rolling_variance_gpu = cuda_make_array(l.variance, n); l.mean_delta_gpu = cuda_make_array(l.mean, n); l.variance_delta_gpu = cuda_make_array(l.variance, n); l.scales_gpu = cuda_make_array(l.scales, n); l.scale_updates_gpu = cuda_make_array(l.scale_updates, n); l.x_gpu = cuda_make_array(l.output, l.batch*out_h*out_w*n); l.x_norm_gpu = cuda_make_array(l.output, l.batch*out_h*out_w*n); } #ifdef CUDNN cudnnCreateTensorDescriptor(&l.normTensorDesc); cudnnCreateTensorDescriptor(&l.srcTensorDesc); cudnnCreateTensorDescriptor(&l.dstTensorDesc); cudnnCreateFilterDescriptor(&l.weightDesc); cudnnCreateTensorDescriptor(&l.dsrcTensorDesc); cudnnCreateTensorDescriptor(&l.ddstTensorDesc); cudnnCreateFilterDescriptor(&l.dweightDesc); cudnnCreateConvolutionDescriptor(&l.convDesc); cudnn_convolutional_setup(&l); #endif } #endif l.workspace_size = get_workspace_size(l); l.activation = activation; fprintf(stderr, "conv %5d %2d x%2d /%2d %4d x%4d x%4d -> %4d x%4d x%4d %5.3f BFLOPs\n", n, size, size, stride, w, h, c, l.out_w, l.out_h, l.out_c, (2.0 * l.n * l.size*l.size*l.c/l.groups * l.out_h*l.out_w)/1000000000.); return l; } void denormalize_convolutional_layer(convolutional_layer l) { int i, j; for(i = 0; i < l.n; ++i){ float scale = l.scales[i]/sqrt(l.rolling_variance[i] + .00001); for(j = 0; j < l.c/l.groups*l.size*l.size; ++j){ l.weights[i*l.c/l.groups*l.size*l.size + j] *= scale; } l.biases[i] -= l.rolling_mean[i] * scale; l.scales[i] = 1; l.rolling_mean[i] = 0; l.rolling_variance[i] = 1; } } /* void test_convolutional_layer() { convolutional_layer l = make_convolutional_layer(1, 5, 5, 3, 2, 5, 2, 1, LEAKY, 1, 0, 0, 0); l.batch_normalize = 1; float data[] = {1,1,1,1,1, 1,1,1,1,1, 1,1,1,1,1, 1,1,1,1,1, 1,1,1,1,1, 2,2,2,2,2, 2,2,2,2,2, 2,2,2,2,2, 2,2,2,2,2, 2,2,2,2,2, 3,3,3,3,3, 3,3,3,3,3, 3,3,3,3,3, 3,3,3,3,3, 3,3,3,3,3}; //net.input = data; //forward_convolutional_layer(l); } */ void resize_convolutional_layer(convolutional_layer *l, int w, int h) { l->w = w; l->h = h; int out_w = convolutional_out_width(*l); int out_h = convolutional_out_height(*l); l->out_w = out_w; l->out_h = out_h; l->outputs = l->out_h * l->out_w * l->out_c; l->inputs = l->w * l->h * l->c; l->output = realloc(l->output, l->batch*l->outputs*sizeof(float)); l->delta = realloc(l->delta, l->batch*l->outputs*sizeof(float)); if(l->batch_normalize){ l->x = realloc(l->x, l->batch*l->outputs*sizeof(float)); l->x_norm = realloc(l->x_norm, l->batch*l->outputs*sizeof(float)); } #ifdef GPU cuda_free(l->delta_gpu); cuda_free(l->output_gpu); l->delta_gpu = cuda_make_array(l->delta, l->batch*l->outputs); l->output_gpu = cuda_make_array(l->output, l->batch*l->outputs); if(l->batch_normalize){ cuda_free(l->x_gpu); cuda_free(l->x_norm_gpu); l->x_gpu = cuda_make_array(l->output, l->batch*l->outputs); l->x_norm_gpu = cuda_make_array(l->output, l->batch*l->outputs); } #ifdef CUDNN cudnn_convolutional_setup(l); #endif #endif l->workspace_size = get_workspace_size(*l); } void add_bias(float *output, float *biases, int batch, int n, int size) { int i,j,b; for(b = 0; b < batch; ++b){ for(i = 0; i < n; ++i){ for(j = 0; j < size; ++j){ output[(b*n + i)*size + j] += biases[i]; } } } } void scale_bias(float *output, float *scales, int batch, int n, int size) { int i,j,b; for(b = 0; b < batch; ++b){ for(i = 0; i < n; ++i){ for(j = 0; j < size; ++j){ output[(b*n + i)*size + j] *= scales[i]; } } } } void backward_bias(float *bias_updates, float *delta, int batch, int n, int size) { int i,b; for(b = 0; b < batch; ++b){ for(i = 0; i < n; ++i){ bias_updates[i] += sum_array(delta+size*(i+b*n), size); } } } void forward_convolutional_layer(convolutional_layer l, network net) { int i, j; fill_cpu(l.outputs*l.batch, 0, l.output, 1); if(l.xnor){ binarize_weights(l.weights, l.n, l.c/l.groups*l.size*l.size, l.binary_weights); swap_binary(&l); binarize_cpu(net.input, l.c*l.h*l.w*l.batch, l.binary_input); net.input = l.binary_input; } int m = l.n/l.groups; int k = l.size*l.size*l.c/l.groups; int n = l.out_w*l.out_h; for(i = 0; i < l.batch; ++i){ for(j = 0; j < l.groups; ++j){ float *a = l.weights + j*l.nweights/l.groups; float *b = net.workspace; float *c = l.output + (i*l.groups + j)*n*m; float *im = net.input + (i*l.groups + j)*l.c/l.groups*l.h*l.w; if (l.size == 1) { b = im; } else { im2col_cpu(im, l.c/l.groups, l.h, l.w, l.size, l.stride, l.pad, b); } gemm(0,0,m,n,k,1,a,k,b,n,1,c,n); } } if(l.batch_normalize){ forward_batchnorm_layer(l, net); } else { add_bias(l.output, l.biases, l.batch, l.n, l.out_h*l.out_w); } activate_array(l.output, l.outputs*l.batch, l.activation); if(l.binary || l.xnor) swap_binary(&l); } void backward_convolutional_layer(convolutional_layer l, network net) { int i, j; int m = l.n/l.groups; int n = l.size*l.size*l.c/l.groups; int k = l.out_w*l.out_h; gradient_array(l.output, l.outputs*l.batch, l.activation, l.delta); if(l.batch_normalize){ backward_batchnorm_layer(l, net); } else { backward_bias(l.bias_updates, l.delta, l.batch, l.n, k); } for(i = 0; i < l.batch; ++i){ for(j = 0; j < l.groups; ++j){ float *a = l.delta + (i*l.groups + j)*m*k; float *b = net.workspace; float *c = l.weight_updates + j*l.nweights/l.groups; float *im = net.input + (i*l.groups + j)*l.c/l.groups*l.h*l.w; float *imd = net.delta + (i*l.groups + j)*l.c/l.groups*l.h*l.w; if(l.size == 1){ b = im; } else { im2col_cpu(im, l.c/l.groups, l.h, l.w, l.size, l.stride, l.pad, b); } gemm(0,1,m,n,k,1,a,k,b,k,1,c,n); if (net.delta) { a = l.weights + j*l.nweights/l.groups; b = l.delta + (i*l.groups + j)*m*k; c = net.workspace; if (l.size == 1) { c = imd; } gemm(1,0,n,k,m,1,a,n,b,k,0,c,k); if (l.size != 1) { col2im_cpu(net.workspace, l.c/l.groups, l.h, l.w, l.size, l.stride, l.pad, imd); } } } } } void update_convolutional_layer(convolutional_layer l, update_args a) { float learning_rate = a.learning_rate*l.learning_rate_scale; float momentum = a.momentum; float decay = a.decay; int batch = a.batch; axpy_cpu(l.n, learning_rate/batch, l.bias_updates, 1, l.biases, 1); scal_cpu(l.n, momentum, l.bias_updates, 1); if(l.scales){ axpy_cpu(l.n, learning_rate/batch, l.scale_updates, 1, l.scales, 1); scal_cpu(l.n, momentum, l.scale_updates, 1); } axpy_cpu(l.nweights, -decay*batch, l.weights, 1, l.weight_updates, 1); axpy_cpu(l.nweights, learning_rate/batch, l.weight_updates, 1, l.weights, 1); scal_cpu(l.nweights, momentum, l.weight_updates, 1); } image get_convolutional_weight(convolutional_layer l, int i) { int h = l.size; int w = l.size; int c = l.c/l.groups; return float_to_image(w,h,c,l.weights+i*h*w*c); } void rgbgr_weights(convolutional_layer l) { int i; for(i = 0; i < l.n; ++i){ image im = get_convolutional_weight(l, i); if (im.c == 3) { rgbgr_image(im); } } } void rescale_weights(convolutional_layer l, float scale, float trans) { int i; for(i = 0; i < l.n; ++i){ image im = get_convolutional_weight(l, i); if (im.c == 3) { scale_image(im, scale); float sum = sum_array(im.data, im.w*im.h*im.c); l.biases[i] += sum*trans; } } } image *get_weights(convolutional_layer l) { image *weights = calloc(l.n, sizeof(image)); int i; for(i = 0; i < l.n; ++i){ weights[i] = copy_image(get_convolutional_weight(l, i)); normalize_image(weights[i]); /* char buff[256]; sprintf(buff, "filter%d", i); save_image(weights[i], buff); */ } //error("hey"); return weights; } image *visualize_convolutional_layer(convolutional_layer l, char *window, image *prev_weights) { image *single_weights = get_weights(l); show_images(single_weights, l.n, window); image delta = get_convolutional_image(l); image dc = collapse_image_layers(delta, 1); char buff[256]; sprintf(buff, "%s: Output", window); //show_image(dc, buff); //save_image(dc, buff); free_image(dc); return single_weights; }之后便可make通过。 使用如下命令测试(路径仍为darknet下): ./darknet detect cfg/yolov3-tiny.cfg yolov3-tiny.weights data/dog.jpg注意:该命令需要weights文件,需要将yolov3-tiny.weights放到darknet路径下,文件放置如下图。
./darknet命令测试结果如下图:
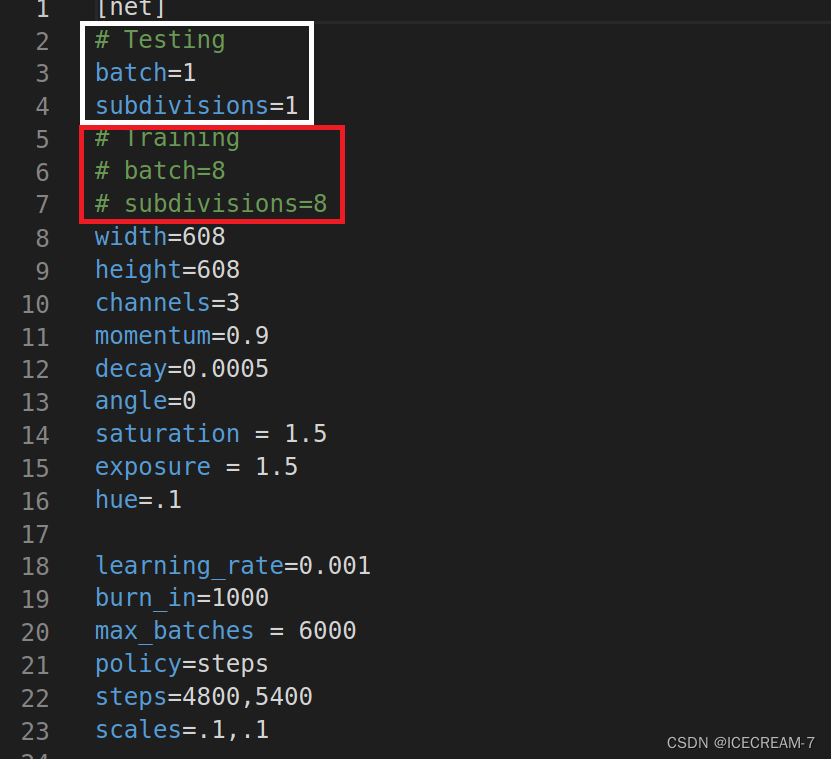
证明./darknet命令行能够正常使用,后面开始训练。 注意:1.需要下载v3的预训练权重。 2.修改cfg文件的参数。 3.data文件和cfg文件最好重新建一个,防止出问题。 cfg文件的参数修改大致相同,这里给出本人的主要参数,如下图。
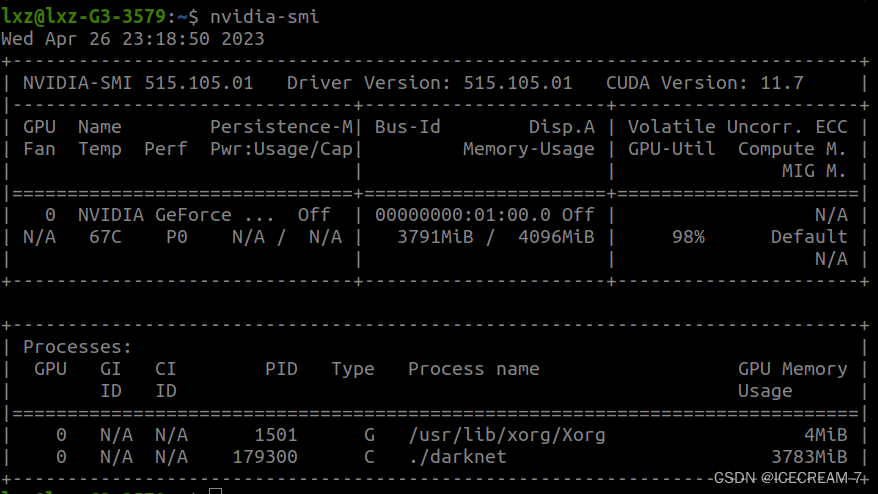
1.训练时把红色框中的注释打开,训练完成后测试时打开白色框中的参数,只打开batch和subdivision即可。 2.max_batches参数根据总类别修改,为类别数x2000,大致如此。 3.steps参数为max_batches的80%和90%。 4.参数合适的修改尤为重要,会导致最终的效果以及训练的正常与否。 训练命令行为: ./darknet detector train cfg/my_data.data cfg/my_yolov3_1.cfg darknet53.conv.74其中darknet53.conv.74为预先下载的预训练权重。 训练问题记录: 问题1:本人电脑为1050显卡,4GB显存,使用v3网络训练,在batch和subdivision参数设置为64和16情况下,出现了爆显存的情况,导致训练中断。steps参数当时也忘记修改,也导致了训练失败。 该参数下显存占用情况如下:
满显存运行,本以为可以安然无事,但大约1个小时后显存满了,训练中断。 中断后再次执行该命令,就会出现段错误(核心转储)的错误,最后不断尝试,通过重新建了一个cfg文件,调用新的cfg文件继续训练。此时的cfg文件参数batch和subdivision已被改为8和8,steps参数也进行了相应修改。 使用此参数训练时的显卡占用为:
之后一切正常,使用命令可以看到 nvidia-smi虽然GPU-Util已经显示99%,但是显存只占用了2GB,因此稳定性较好,最终训练成功。 训练过程图为:
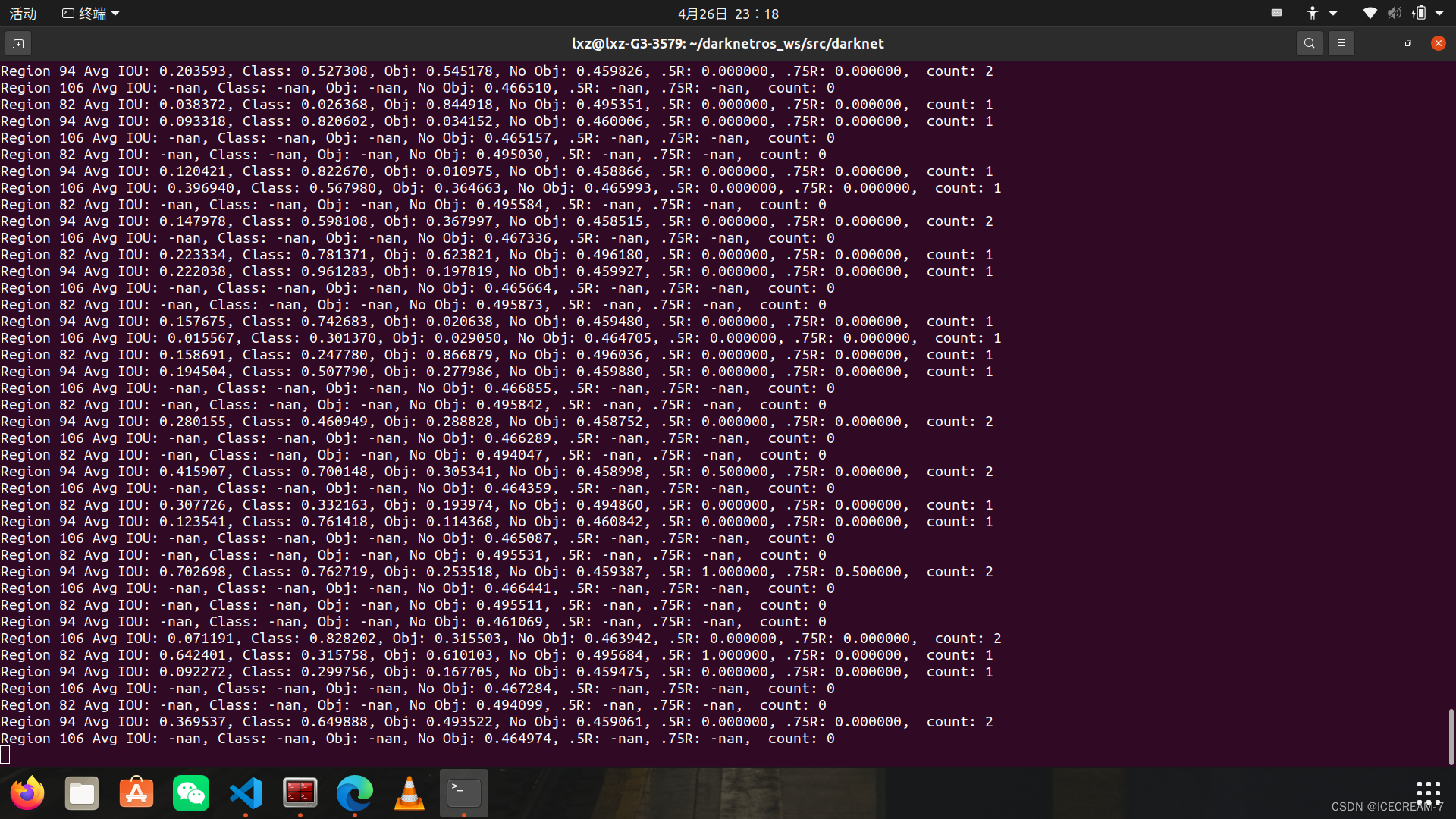
会保存一个含有final标签的最终权重。 4.测试训练所得的权重其中的太过细节的操作,参考链接中都有,在此不在介绍。 使用darknet的yolov3不能识别卷尺:
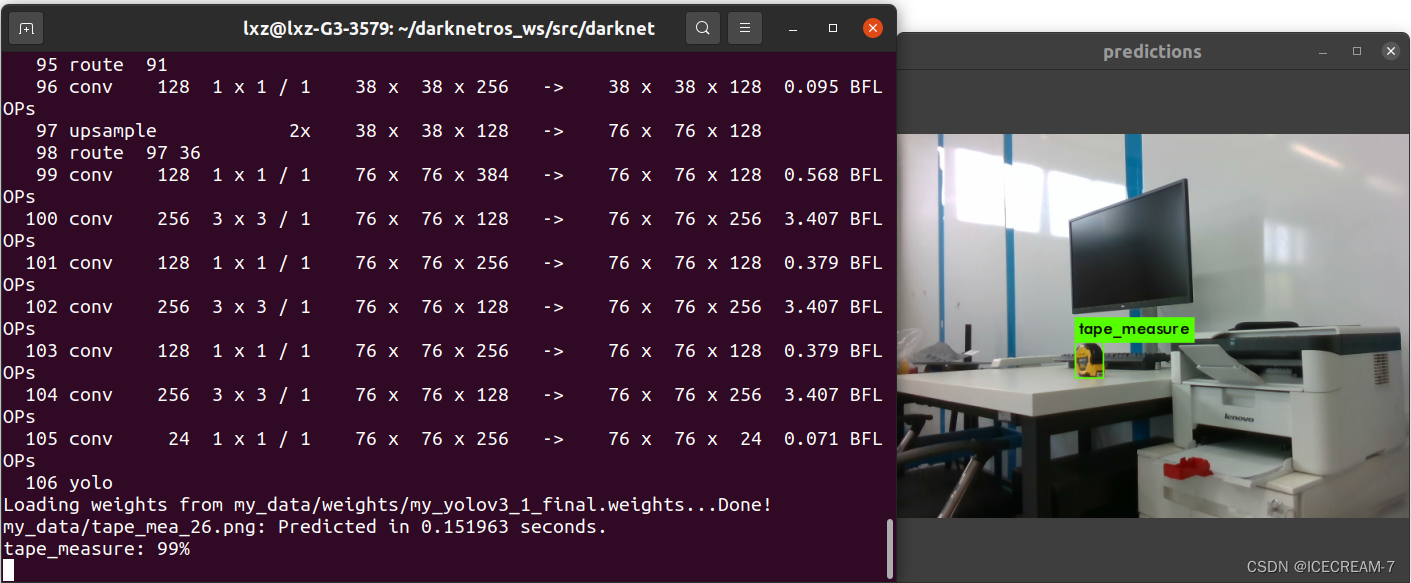
调用训练所得权重测试train所用图片:
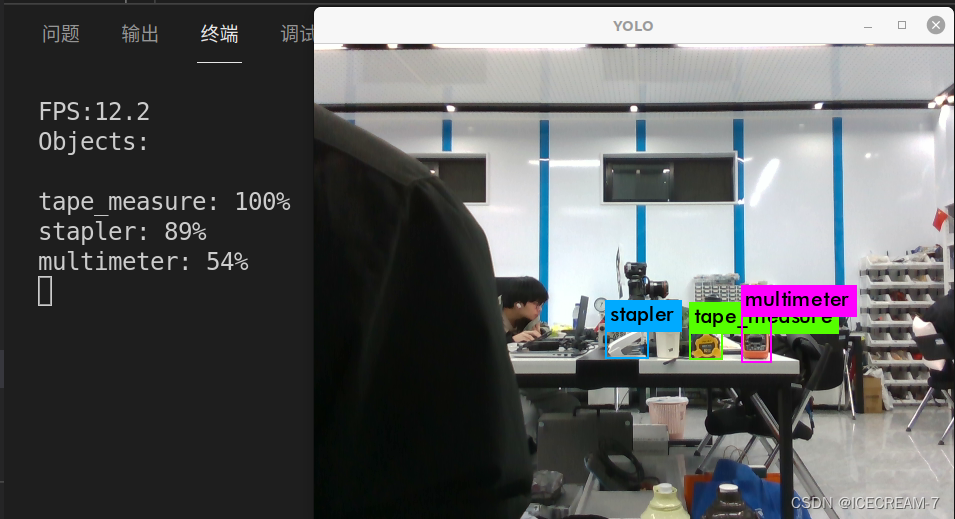
调用训练所得权重测试图片: 测试图片采用realsense-D435相机实时获取,拍摄也是该相机。 正面物体检测效果如下图:
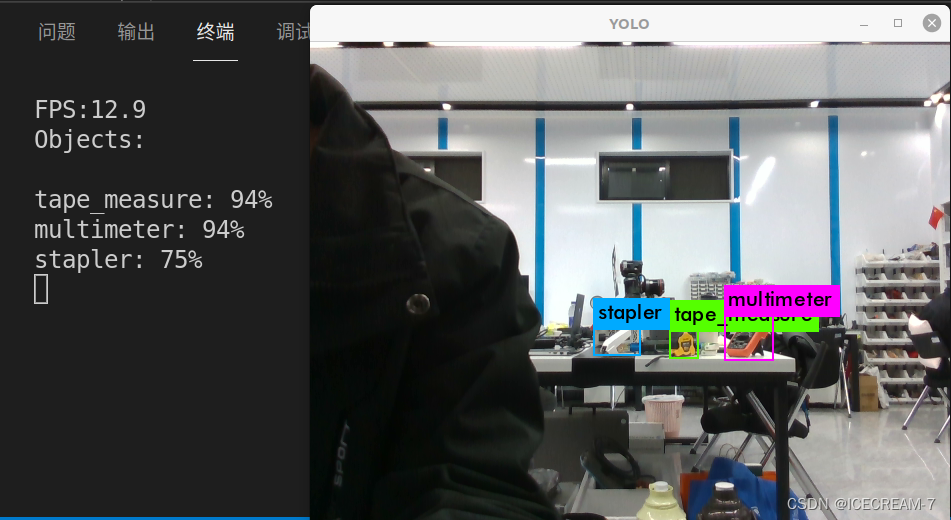
稍微侧面物体检测效果如下图:
1.拍摄数据集的相机和最终使用的相机最好是同一台,这样可以避免一些问题。 2.拍摄数据集时多个角度的拍摄,可以提高检测的效果。 3.训练需要调用显卡算力,因此请根据自己的显卡性能合理选择参数,才能保证训练的正常运行。 5.最后附上学习自己训练时参考的链接(1条消息) 在ROS中实现darknet_ros(YOLO V3)检测以及训练自己的数据集_矩池云训练yolo_马文茂的博客-CSDN博客 yolov3.cfg参数解读 - 玩转机器学习 - 博客园 (cnblogs.com) (1条消息) Darknet——yolo3训练自己的数据集+在ros环境下实现目标检测实战教程(三)——应用在ROS上_ros中如何在yolo中加入深度信息_平山村小明的博客-CSDN博客 (1条消息) Darknet——yolo3训练自己的数据集+在ros环境下实现目标检测实战教程(二)——训练自己的权重文件_yolov3修改detect文件的权重文件_平山村小明的博客-CSDN博客 darknet-yolov3训练自己的数据集,并测试训练结果_pd很不专业的博客-CSDN博客 darknet-yolov3训练自己的数据集(超详细) - AnswerThe - 博客园 (cnblogs.com) (1条消息) Darknet概述_深夜虫鸣的博客-CSDN博客 【教程】标注工具Labelimg的安装与使用 - 知乎 (zhihu.com) 小白教程:Ubuntu下使用Darknet/YOLOV3训练自己的数据集_Royal Pearl.的博客-CSDN博客 【目标检测实战】Darknet—yolov3模型训练(VOC数据集) - 知乎 (zhihu.com) |






【本文地址】