| protobuf序列化和反序列化原理 | 您所在的位置:网站首页 › 序列化和反序列化原理解析题及答案大全图片 › protobuf序列化和反序列化原理 |
protobuf序列化和反序列化原理
|
实现原理
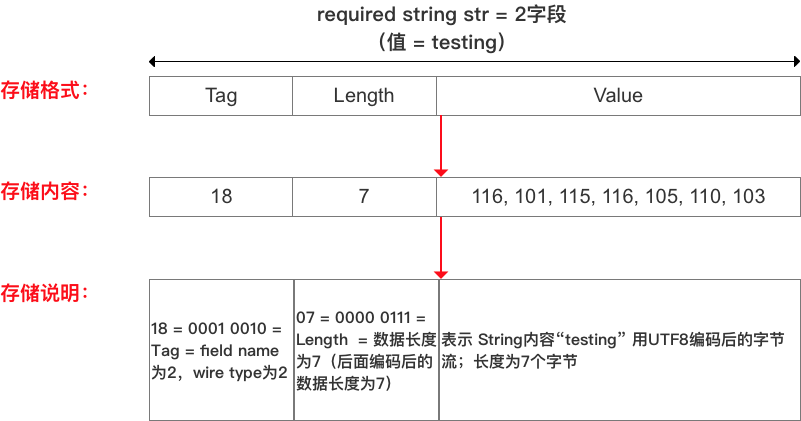
序列化是如何实现的? message sku_feature { int64 sku_id = 1; int32 cid1 = 2; float price = 3; int32 cid2 = 4; int32 cid3 = 5; } Tag - Length - Value(标识 - 长度 - 字段值) 编码存储方式 以 标识 - 长度 - 字段值 表示每个字段,所有字段拼接成一个 字节流,从而 实现 编码存储 的功能 示意图
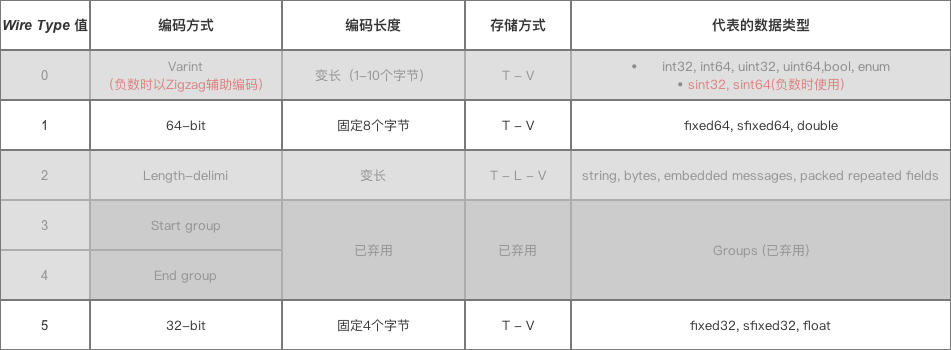
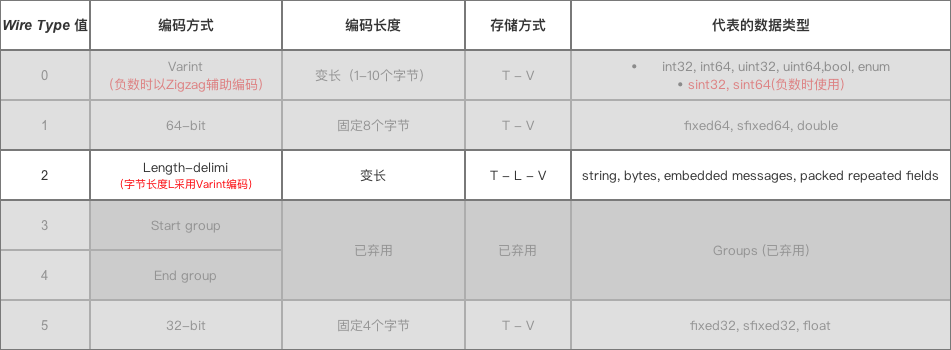
uint32 : field_number *target = static_cast(value | 0x80); value >>= 7; ++target; } *target = static_cast(value); return target + 1; } 解码 bool CodedInputStream::ReadVarint64Slow(uint64* value) { // Slow path: This read might cross the end of the buffer, so we // need to check and refresh the buffer if and when it does. uint64 result = 0; int count = 0; uint32 b; do { if (count == kMaxVarintBytes) { *value = 0; return false; } while (buffer_ == buffer_end_) { if (!Refresh()) { *value = 0; return false; } } b = *buffer_; result |= static_cast(b & 0x7F) // Note: Using unsigned types prevent undefined behavior return static_cast((n >> 1) ^ (~(n & 1) + 1)); } 总结 : Protocol Buffer 通过Varint和Zigzag编码后大大减少了字段值占用字节数。 2 Wire Type = 1& 5时的编码&数据存储方式
固定用4/8个字节表示 inline uint64 WireFormatLite::EncodeDouble(double value) { union {double f; uint64 i;}; f = value; return i; } inline double WireFormatLite::DecodeDouble(uint64 value) { union {double f; uint64 i;}; i = value; return f; } 3 Wire Type = 2时的 编码 & 数据存储方式
讲解三种数据类型: String类型嵌套消息类型(Message)通过packed修饰的 repeat 字段(即packed repeated fields)3.1 String类型 字段值(即V) 采用UTF-8编码
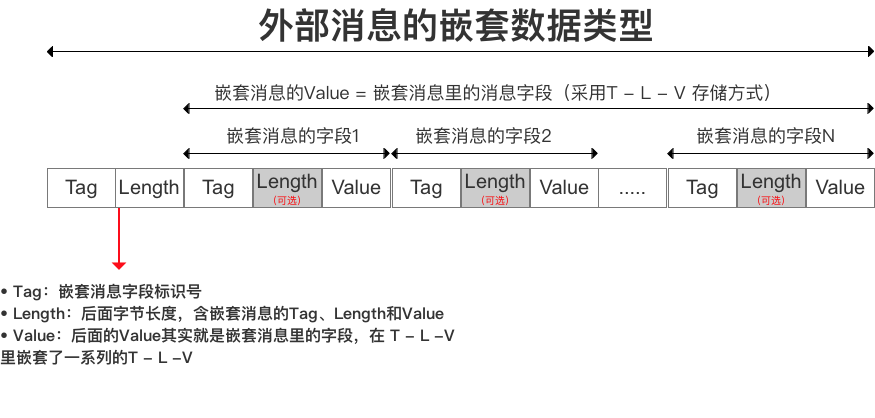
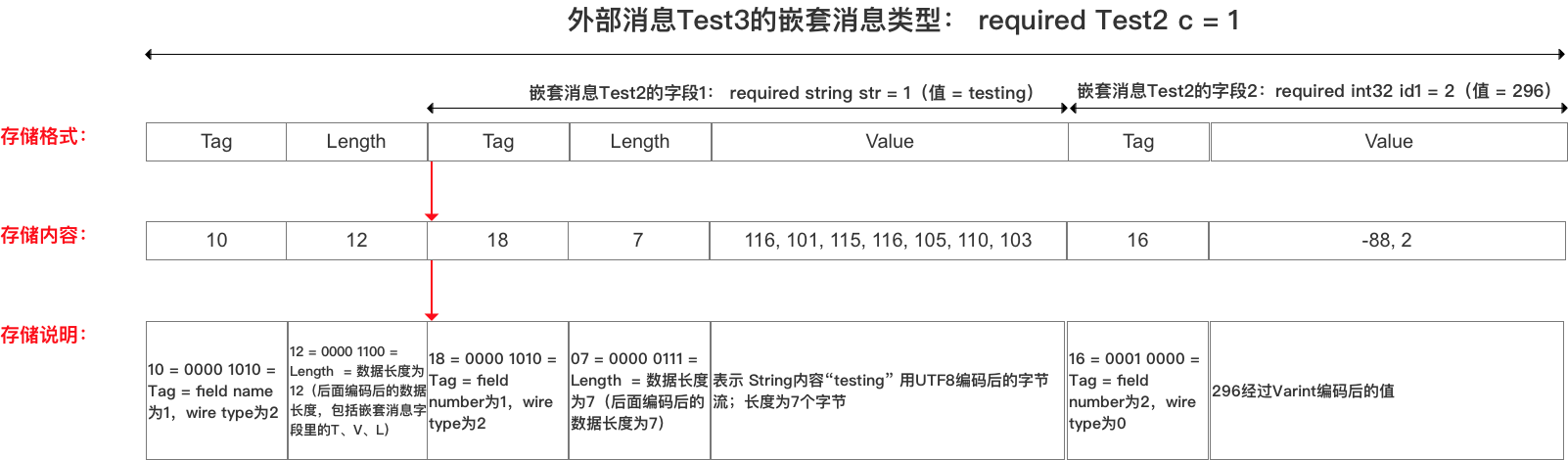
3.2 嵌套消息类型(Message) 存储方式:T - L - V内部消息编码的T - L -V组成外部消息的v
3.3 通过packed修饰的 repeat 字段 repeated 修饰的字段有两种表达方式: message Test { repeated int32 Car = 4 ; // 表达方式1:不带packed=true repeated int32 Car = 4 [packed=true]; // 表达方式2:带packed=true // proto 2.1 开始可使用 } // 在代码中给`repeated int32 Car`附上3个字段值:3、270、86942 Test.setCar(3); Test.setCar(270); Test.setCar(86942); 背景:,即数据类型 & 标识号都相同
通过采用带packed=true 的 repeated 字段存储方式,从而更好地压缩序列化后的数据长度。 特别注意 packed修饰只用于基本类型的repeated字段用在其他字段,编译 .proto 文件时会报错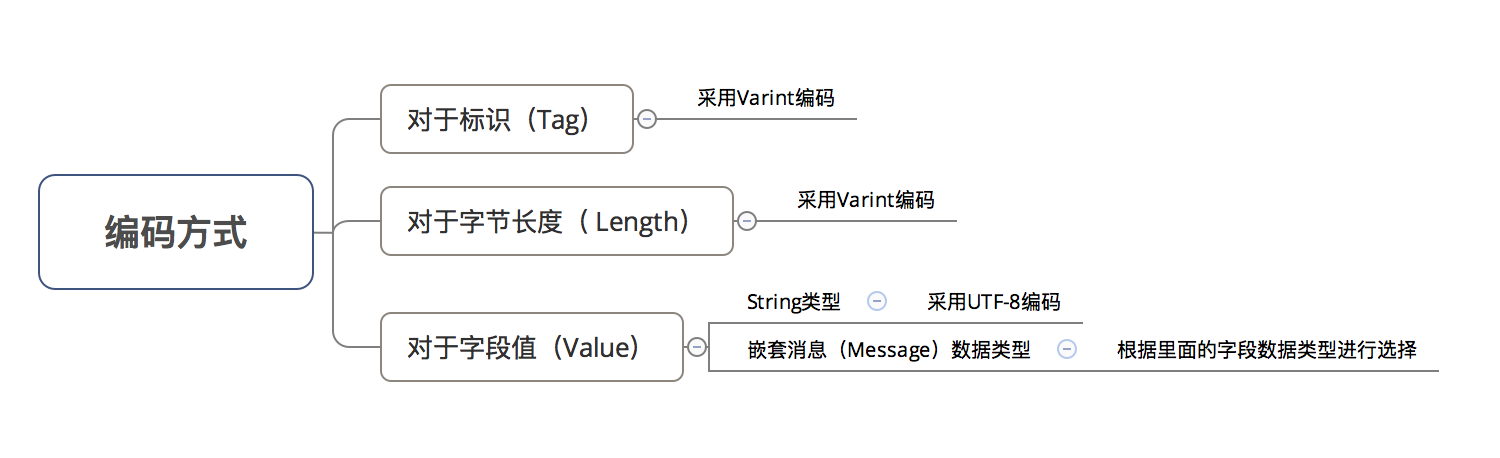 总结
protobuf编码/解码 方式简单,只需要简单的数学运算、位移等,序列化 & 反序列化速度很快protobuf采用了独特的编码方式,如Varint、Zigzag编码方式等等,采用T - L - V 的数据存储方式,数据存储得紧凑,数据压缩效果好
使用建议
总结
protobuf编码/解码 方式简单,只需要简单的数学运算、位移等,序列化 & 反序列化速度很快protobuf采用了独特的编码方式,如Varint、Zigzag编码方式等等,采用T - L - V 的数据存储方式,数据存储得紧凑,数据压缩效果好
使用建议
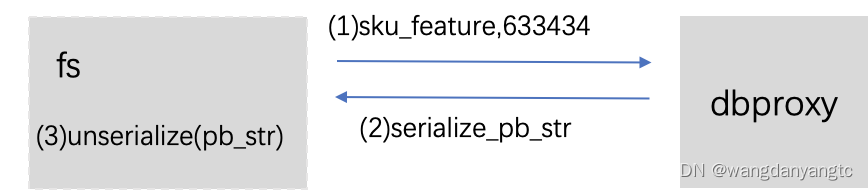
根据上面的序列化原理分析,有以下使用建议: 建议1:字段标识号(Field_Number)尽量只使用 1-15,且不要跳动使用 因为Tag里的Field_Number是需要占字节空间的。如果Field_Number>16时,Field_Number的编码就会占用2个字节,那么Tag在编码时也就会占用更多的字节;如果将字段标识号定义为连续递增的数值,将获得更好的编码和解码性能 建议2:若需要使用的字段值出现负数,请使用 sint32 / sint64,不要使用int32 / int64 因为采用sint32 / sint64数据类型表示负数时,会先采用Zigzag编码再采用Varint编码,从而更加有效压缩数据 建议3:对于repeated字段,尽量增加packed=true修饰 因为加了packed=true修饰repeated字段采用连续数据存储方式,即T - L - V - V -V方式 动态序列化dbproxy类型请求
message sku_feature { int64 sku_id = 1; int32 cid1 = 2; float price = 3; int32 cid2 = 4; int32 cid3 = 5; } 缺点: 只能支持pb级别的请求粒度,例如:只需要cid1字段,返回的是这个序列化的pbpb中增加一个字段,fs也需要代码层面修改pb文件,然后上线,比较繁琐。能否支持字段粒度的请求级别? feature storage类型请求
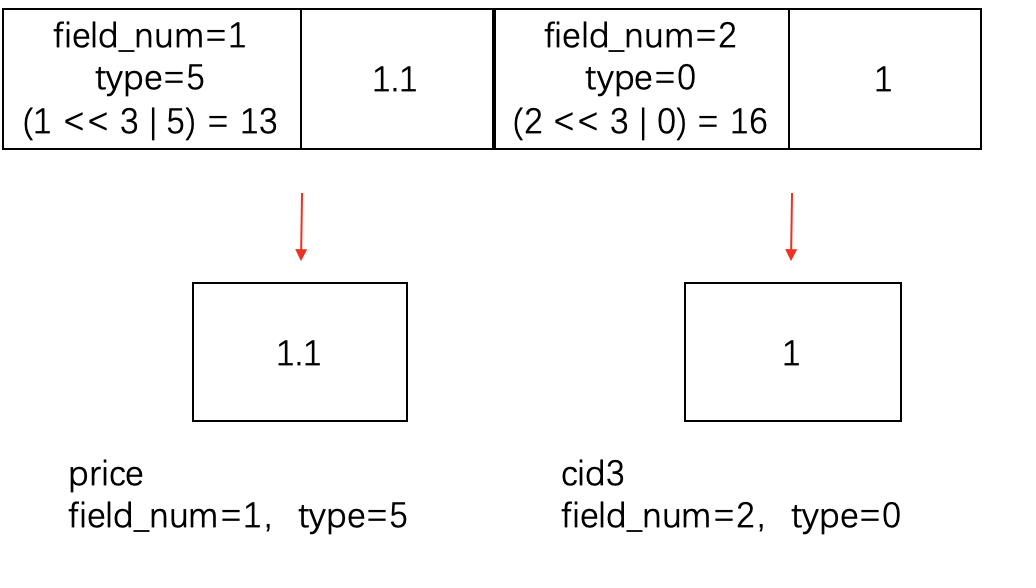
例如storage中 price=1.1, cid3=1 feature storage端:
fs端:
效果: 支持字段级别的请求粒度,例如:只需要cid1字段,返回的序列化字符串中只包含cid1的内容feature storage中增加一个字段,fs无需上线。目前进展: feature stoage端已经完全支持 fs的ufa插件还是通过pb来反序列化,现在正在去除pb逻辑,实现根据字段动态反序列化。 附:各种 Java 的序列化库的性能比较测试结果-51CTO.COM |






【本文地址】