| 双重差分模型DID学习笔记 | 您所在的位置:网站首页 › 广义线性模型的缺点 › 双重差分模型DID学习笔记 |
双重差分模型DID学习笔记
|
双重差分模型DID学习
1.DID介绍1.1 特点1.2 传统DID1.3 经典DID1.4 异时DID1.5 广义DID1.6 异质性DID
2. DID 平行趋势检验3 实践举例3.1 所有个体开始受到政策冲击的时间均完全相同3.1.1 政策效果不随时间而变DID3.1.2 政策效果随时间而变DID
3.2 个体受到政策冲击的时间不相同3.2.1 政策效果不随时间而变DID3.2.2 政策效果随时间而变DID
1.DID介绍
1.1 特点
双重差分模型 (Difference-Differences, DID)是政策评估的非实验方法中最为常用的一种方法,其中交互项是DID的灵魂。 交互项形式拥有各种形式,包括(1)传统DID;(2)经典DID;(3)异时DID;(4)广义DID;以及(5)异质性DID。下面分别介绍这几种。 1.2 传统DID双重差分法是研究“处理效应”(treatment effects)的流行方法。一般来说,DID的使用场景为,在面板数据中,个体可分为两类,即受到政策冲击的“处理组”(treatment group)与未受政策影响的“控制组”(control group)。重点落在政策冲击和是否受到政策冲击,通过引入虚拟变量来实现。即: 政策冲击前后(pre-post)设为0和1,是否受到政策冲击(control-treat)设为0和1. 经典DID是在传统DID模型上控制了个体固定效应(individual fixed effects)和时间固定效应(time fixed effects),并去除单独变量。模型如下: 在传统与经典DID的模型设定中,一个隐含假设是,处理组的所有个体开始受到政策冲击的时间均完全相同。但有时也会遇到每位个体的处理期不完全一致的情形(heterogeneous timing);比如,某项试点政策在不同城市分批推出。此时,可使用“异时DID”(heterogeneous timing DID)。 异时DID的关键在于,既然每位个体的处理期不完全一致,则处理期虚拟变量也因个体而异,故应写为post(i,t),既依赖于个体 i,也依赖于时间 t。模型设定为如下任意一种形式:
以上各种DID方法均假设存在处理组与控制组的区别,但有时某项政策在全国统一铺开,此时只有处理组,并没有控制组,是否还能使用DID呢?答案是“能”,可以尝试“广义DID”(generalized DID)。 使用广义DID的重要前提是,虽然所有个体均同时受到政策冲击,但政策对于每位个体的影响力度并不相同,不妨以 intensity(i) 来表示。 传统的处理效应模型一般假设“同质性处理效应”(homogeneous treatment effects),即所有个体的处理效应都相同。显然,此假定太苛刻,在实践中难以成立。更为合理的假定则为“异质性处理效应”(heterogeneous treatment effects),即允许每位个体的处理效应不尽相同。具体而言: 1)在DID的框架下,引入异质性处理效应,即在于对交互项(treatpost)的调整,即引入在组别上的交互项(treatpost*group)。 2)模型建立上,在经典DID的模型中,再引入三重交互项 ,构建异质性DID模型。 注意,DID应用的前提是未受到政策冲击时,treat组和control组的变化趋势是平行的,因而进行平行趋势检验是绝对必要的。 从文献来看,最为常见的展示是否符合平行趋势假设的检验方法有两个: 其一,对比不同组别因变量均值的时间趋势;其二,回归中加入各时点虚拟变量与政策变量的交互项,若政策或称为处理发生前的交互项系数不显著,则表明的确有着平行趋势。 第一种的方法(图片来源于stata连享会)为: 第二种方式分为:代码操作和图形输出 第二种方式分为:代码操作和图形输出
安装命令:安装 coefplot 生成各时点虚拟变量与政策变量的交互项的交互项 进行回归 输出图形 例子学习于:多期DID:平行趋势检验图示 详见学习链接 3 实践举例 3.1 所有个体开始受到政策冲击的时间均完全相同例子参考学习自: 连享会-倍分法DID详解 (一):传统 DID /* 模拟数据的生成 */ ///设定60个观测值,设定随机数种子 clear all set obs 60 set seed 10101 gen id = _n // 每一个数值的数量扩大11倍,再减去前六十个观测值,即60*11-60 = 600,为60个体10年的面板数据 expand 11 drop in 1/60 count ///以id分组生成时间标识 bysort id : gen time = _n + 1999 xtset id time ///生成协变量x1, x2 gen x1 = rnormal(1,7) gen x2 = rnormal(2,5) ///生成个体固定效应和时间固定效应 sort time id by time : gen ind = _n sort id time by id : gen T = _n ///生成treat和post变量,以2005年为接受政策干预的时点,id为30-60的个体为处理组,其余为控制组 gen D = 0 replace D = 1 if id > 29 gen post = 0 replace post = 1 if time >= 2005 ///将基础数据结构保存成dta文件,命名为DID_Basic_Simu.dta,默认保存在当前的 working directory 路径下 save "DID_Basic_Simu.dta",replace 3.1.1 政策效果不随时间而变DID ///调用本文第二部分生成的基础数据结构 use "DID_Basic_Simu.dta",clear ///生成两种潜在结果,并且合成最终的结果变量,令政策的真实效果为10 bysort id : gen y0 = 10 + 5*x1 + 3*x2 + T +ind + rnormal() bysort id : gen y1 = 10 + 5*x1 + 3*x2 + T +ind + rnormal() if time = 2005 gen y = y0 + D*(y1-y0) ///去除协变量和个体效应对y的影响,画出剩余残差的图像 xtreg y x1 x2,fe r predict e, ue binscatter e time, line(connect) by(D) ///输出生成的图片,令格式为800*600 graph export "article1_1.png",as(png) replace width(800) height(600) ///多种回归形式 reg y c.D#c.post x1 x2 i.time i.id,robust eststo reg xtreg y c.D#c.post x1 x2 i.time,absorb(id) robust eststo areg reghdfe y y c.D#c.post x1 x2, absorb(id time) vce(robust) estout *, title("The Comparison of Actual Paramerer Values") /// cells(b(star fmt(%9.3f)) se(par)) /// stats(N N_g, fmt(%9.0f %9.0g) label(N Groups)) /// legend collabels(none) varlabels(_cons Constant) keep(x1 x2 c.D#c.post) ///ESA及图示法 ///预先生成年度虚拟变量 tab time,gen(year) reg y i.D#i.time x1 x2, vce(robust) reghdfe y c.D#(c.year2-year10) x1 x2, absorb(id time) vce(robust) coefplot, /// keep(c.D#c.year2 c.D#c.year3 c.D#c.year4 c.D#c.year5 c.D#c.year6 c.D#c.year7 c.D#c.year8 c.D#c.year9 c.D#c.year10) /// coeflabels(c.D#c.year2 = "-4" /// c.D#c.year3 = "-3" /// c.D#c.year4 = "-2" /// c.D#c.year5 = "-1" /// c.D#c.year6 = "0" /// c.D#c.year7 = "1" /// c.D#c.year8 = "2" /// c.D#c.year9 = "3" /// c.D#c.year10 = "4") /// vertical /// yline(0) /// ytitle("Coef") /// xtitle("Time passage relative to year of adoption of implied contract exception") /// addplot(line @b @at) /// ciopts(recast(rcap)) /// scheme(s1mono) ///输出生成的图片,令格式为800*600 graph export "article1_3.png", as(png) replace width(800) height(600) 3.1.2 政策效果随时间而变DID ///调用本文第二部分生成的基础数据结构 use "DID_Basic_Simu.dta",clear ///生成两种潜在结果,并且合成最终的结果变量,令政策的真实效果随时间发生变化,即(5*T-T),由于从2005年开始接受干预,因此,每年的政策效果应为24,28,32,36,40. bysort id: gen y0 = 10 + 5 * x1 + 3 * x2 + T + ind + rnormal() bysort id: gen y1 = 10 + 5 * x1 + 3 * x2 + T + ind + rnormal() if time = 2005 gen y = y0 + D * (y1 - y0) ///去除协变量和个体效应对y的影响,画出剩余残差的图像 xtreg y x1 x2 , fe r predict e,ue binscatter e time, line(connect) by(D) ///输出生成的图片,令格式为800*600 graph export "article1_1.png",as(png) replace width(800) height(600) ///多种回归形式 reg y c.D#c.post x1 x2 i.time i.id, r eststo reg xtreg y c.D#c.post x1 x2 i.time, r fe eststo xtreg_fe areg y c.D#c.post x1 x2 i.time, absorb(id) robust eststo areg reghdfe y c.D#c.post x1 x2, absorb(id time) vce(robust) eststo reghdfe estout *, title("The Comparison of Actual Paramerer Values") /// cells(b(star fmt(%9.3f)) se(par)) /// stats(N N_g, fmt(%9.0f %9.0g) label(N Groups)) /// legend collabels(none) varlabels(_cons Constant) keep(x1 x2 c.D#c.post) ///ESA及图示法 ///预先生成年度虚拟变量 tab time, gen(year) reghdfe y i.D#i.time x1 x2, vce(robust) absorb(id time) reghdfe y c.D#(c.year2-year10) x1 x2, absorb(id time) vce(robust) coefplot, /// keep(c.D#c.year2 c.D#c.year3 c.D#c.year4 c.D#c.year5 c.D#c.year6 c.D#c.year7 c.D#c.year8 c.D#c.year9 c.D#c.year10) /// coeflabels(c.D#c.year2 = "-4" /// c.D#c.year3 = "-3" /// c.D#c.year4 = "-2" /// c.D#c.year5 = "-1" /// c.D#c.year6 = "0" /// c.D#c.year7 = "1" /// c.D#c.year8 = "2" /// c.D#c.year9 = "3" /// c.D#c.year10 = "4") /// vertical /// yline(0) /// ytitle("Coef") /// xtitle("Time passage relative to year of adoption of implied contract exception") /// addplot(line @b @at) /// ciopts(recast(rcap)) /// scheme(s1mono) ///输出生成的图片,令格式为800*600 graph export "article1_4.png",as(png) replace width(800) height(600) 3.2 个体受到政策冲击的时间不相同倍分法DID详解 (二):多时点 DID (渐进DID) 所有个体开始受到政策冲击的时间均完全相同:Standard DID |

 因而,模型常设计为
因而,模型常设计为 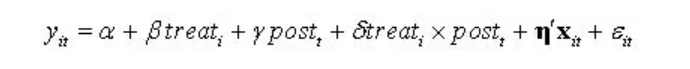 处理组虚拟变量 beta 捕捉了处理组的组别效应(处理组与控制组的固有差别),处理期虚拟变量lambda控制了处理期的时间效应(处理期前后的固有时间趋势), X为其他控制变量,而交互项xigema 则代表了处理组在处理期的真正效应(受到政策冲击的效应),这正是我们关心的处理效应。然后进行OLS估计即可。
处理组虚拟变量 beta 捕捉了处理组的组别效应(处理组与控制组的固有差别),处理期虚拟变量lambda控制了处理期的时间效应(处理期前后的固有时间趋势), X为其他控制变量,而交互项xigema 则代表了处理组在处理期的真正效应(受到政策冲击的效应),这正是我们关心的处理效应。然后进行OLS估计即可。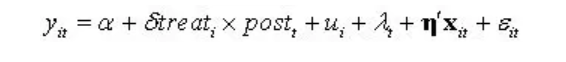 模型解释如下: (1)u 为个体固定效应。加入个体固定效应之后,就不必再放入处理组虚拟变量(treat i),否则会引起多重共线性问题。因为前者包含比后者更多的信息(前者控制到个体层面,而后者仅控制到组别层面)。 (2)入 为时间固定效应。同理,加入时间固定效应就不用再加处理期虚拟变量(post t)。否则,将导致严格多重共线性,因为前者包含比后者更多的信息(前者控制了每一期的时间效应,而后者仅控制处理期前后的时间效应) (3)注意:估计方法依然是OLS,但须使用“聚类稳健标准误”(cluster-robust standard errors)。
模型解释如下: (1)u 为个体固定效应。加入个体固定效应之后,就不必再放入处理组虚拟变量(treat i),否则会引起多重共线性问题。因为前者包含比后者更多的信息(前者控制到个体层面,而后者仅控制到组别层面)。 (2)入 为时间固定效应。同理,加入时间固定效应就不用再加处理期虚拟变量(post t)。否则,将导致严格多重共线性,因为前者包含比后者更多的信息(前者控制了每一期的时间效应,而后者仅控制处理期前后的时间效应) (3)注意:估计方法依然是OLS,但须使用“聚类稳健标准误”(cluster-robust standard errors)。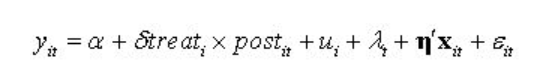
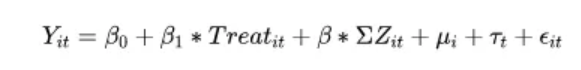 举一个5期面板数据在stata的应用: 1)定义变量:定义因个体而异的处理期虚拟变量post(i,t); 2)识别受影响:post1(i,t) = (0,0,1,1,1)代表第1位个体从第3期开始受到政策处理;post2(i,t) = (0,0,0,1,1)代表第2位个体从第4期开始受到政策处理;post3(i,t) = (0,0,0,0,0)代表从未受到政策冲击(属于控制组)。
举一个5期面板数据在stata的应用: 1)定义变量:定义因个体而异的处理期虚拟变量post(i,t); 2)识别受影响:post1(i,t) = (0,0,1,1,1)代表第1位个体从第3期开始受到政策处理;post2(i,t) = (0,0,0,1,1)代表第2位个体从第4期开始受到政策处理;post3(i,t) = (0,0,0,0,0)代表从未受到政策冲击(属于控制组)。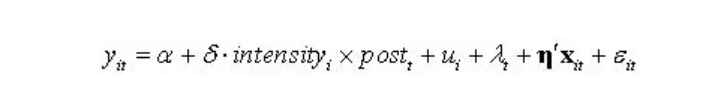
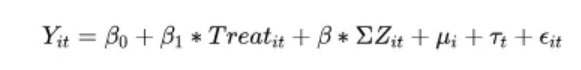 其中,交互项系数为我们关注的对象。此外对于广义DID,文献中也有门槛区分组别的方法,即人为地设定一个门槛值 c,根据 变量是否超过此门槛值来定义处理组与控制组。因为将连续变量压缩为二分变量损失了不少信息,故在实践中已不多见。
其中,交互项系数为我们关注的对象。此外对于广义DID,文献中也有门槛区分组别的方法,即人为地设定一个门槛值 c,根据 变量是否超过此门槛值来定义处理组与控制组。因为将连续变量压缩为二分变量损失了不少信息,故在实践中已不多见。 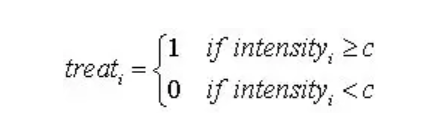
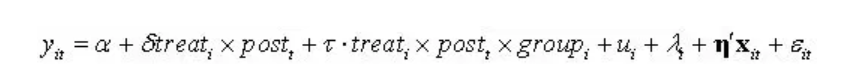 由上式可知,对于group=0 那类处理组个体,其处理效应为 s。而对于 group=1那类处理组个体,其处理效应为(s+t) 。因而其处理效应是异质的(只要三重交互项的系数显著)。 3)推广到多雷,只要将将所有个体分为 M 类,设立 (M -1) 个类别虚拟变量。
由上式可知,对于group=0 那类处理组个体,其处理效应为 s。而对于 group=1那类处理组个体,其处理效应为(s+t) 。因而其处理效应是异质的(只要三重交互项的系数显著)。 3)推广到多雷,只要将将所有个体分为 M 类,设立 (M -1) 个类别虚拟变量。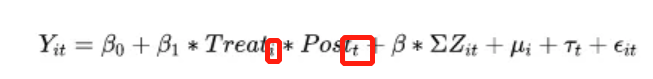 个体开始受到政策冲击的时间不相同:Time-varying DID
个体开始受到政策冲击的时间不相同:Time-varying DID 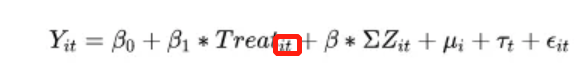
【本文地址】