| 大厂面试必问:如何设计一个扛高并发的系统? | 您所在的位置:网站首页 › 并发程序举例说明怎么写 › 大厂面试必问:如何设计一个扛高并发的系统? |
大厂面试必问:如何设计一个扛高并发的系统?
|
前言
大家好,我是路由器没有路。 三年前,我曾前往字节跳动参加面试。在三面面试环节中,我遇到了一道场景设计题目:如何设计一个高并发系统? 当时我的回答比较简略,但最近我朋友在准备面试,问我关于大厂面试的一些经验,于是我回想起来,因此整理出了 8 个在设计高并发系统时需要考虑的技术点或者说因素。 相信这些能够帮助大家更好地理解和应对高并发系统的场景。
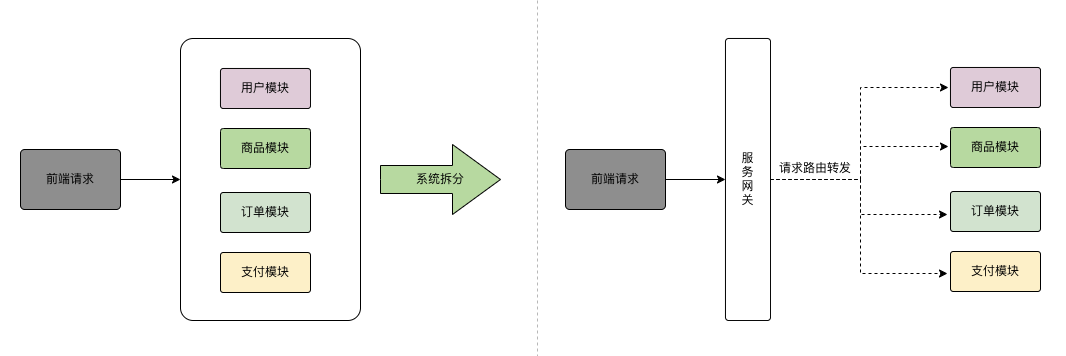
高并发系统是指:在短时间内同时有大量用户请求访问系统,需要系统能够快速、稳定地响应这些请求。 高并发系统案例例如,当某个电商平台在双十一期间推出大量优惠活动时,可能会有成千上万的用户同时访问该平台,这就是一个高并发系统。 在这种情况下,如果系统无法快速处理这些请求,就会导致用户体验下降,甚至导致系统崩溃。 因此,高并发系统需要具备快速、稳定地响应大量请求的能力,以保证系统的正常运行和用户体验。 高并发带来的问题1.系统压力增大:高并发请求会导致系统压力增大,可能会导致系统崩溃或运行缓慢。 2.响应时间延长:高并发请求会导致系统响应时间延长,用户体验下降。 3.数据不一致:高并发请求可能会导致数据不一致,例如在多个请求同时对同一数据进行操作时,可能会导致数据出现异常。 4.资源浪费:高并发请求可能会导致系统资源浪费,例如某些请求可能会占用过多的内存或 CPU 资源,导致其他请求无法正常运行。 而今天要讲的就是该如何设计一个高并发系统,需要考虑哪些因素,才能处理好高并发带来的问题,以保证系统的高并发处理能力。 1.分而治之:系统拆分系统拆分(微服务拆分)简单来说就是将一个系统拆分为多个子系统,换句话说就是将一个单体的应用按照功能单一性拆分为多个服务模块。 这样拆分后的每个系统连一个数据库,这样本来就一个库,现在多个数据库,也是可以扛高并发的。 例如,在商城系统中,可以将用户系统、订单系统、商品系统等功能拆分为不同的服务模块,从而实现请求流量的分摊,提高系统的并发处理能力。
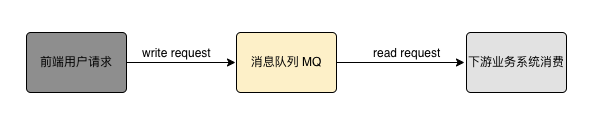
缓存是现代计算机系统中普遍存在的技术,无论是操作系统、浏览器还是一些复杂的中间件,都可以看到缓存的应用。 大部分的高并发场景,都是读多写少,要想提高数据的访问速度,那系统必须得加缓存。 我们使用缓存的主要目的是提高系统接口的性能,特别是在高并发场景下,缓存可以帮助系统支持更多的用户同时访问。 常见的缓存技术包括 Redis 缓存、JVM 本地缓存、memcached 等。 就以 Redis 为例,它单机就可以轻松应对几万的并发请求,因此在读取场景的业务中,使用缓存可以有效地抗击高并发请求。 但是使用缓存时,以下问题是需要考虑的: 缓存数据一致性 缓存雪崩 缓存穿透 缓存击穿前面我专门写过两篇关于缓存问题的文章,可以看下: 什么是 Redis 缓存雪崩、缓存穿透和缓存击穿?看此文就够了! 数据库和缓存一致性问题,看这一篇就够了 3.削峰处理:使用消息队列 MQ在系统中可能会出现高并发写的场景,例如在某个业务操作中需要频繁地对数据库进行增删改操作,这可能会导致系统崩溃。 如果使用 Redis 缓存来承载写操作,可能会出现数据被 LRU 淘汰的问题,而且 Redis 缓存不支持事务,因此不适合承载复杂写业务逻辑的场景。 在这种情况下,当然你可能会考虑直接使用 MySQL 来承载写操作,但是 MySQL 数据库需要注意控制写操作的并发数,避免对 MySQL 造成过大的压力。 为了解决高并发写场景的问题,可以使用消息队列(MQ)来异步处理写请求。 将大量的写请求灌入 MQ 中,让下游系统循序渐进地消费这些请求,控制在 MySQL 承载范围之内。 MQ 单机可以抗击几万并发请求,因此在处理高并发写场景时,使用 MQ 可以提升系统的吞吐量和并发性能。
如果业务发展的比较迅速的话,数据库将会成为性能的瓶颈。 也就是说,当业务的体量上来了,MySQL 数据库单机的磁盘容量可能会达到上限。 此外,数据库连接数也是有限的,因此在高并发场景下,大量请求访问数据库,MySQL 单机无法承受。在高并发场景下,可能会出现too many connections 的报错。 因此,为了应对高并发的挑战,需要将高并发系统拆分为多个数据库,多个库来扛更高的并发,以提高系统的并发处理能力。 如果单表数据量也非常大,存储和查询的性能就也会遇到瓶颈。 在进行了分库优化之后,如果提升性能的效果不太大,就需要考虑进行分表操作了。 一般来说,当单表数据量达到千万级别时,就需要考虑进行分表操作了,将数据分散到多个表中,以提高 SQL 查询性能。 可以看下我前面写的关于分库分表的文章: 数据库之分库分表的一些总结 5.读多写少场景:读写分离读写分离是指将数据库中的读操作和写操作分别分配到不同的数据库实例上进行处理的技术。 读写分离的好处是可以提高系统的并发处理能力和性能,因为读操作和写操作通常具有不同的特点,读操作通常比较频繁,而写操作通常比较耗时。 因此,将读操作和写操作分别分配到不同的数据库实例上进行处理,可以有效地提高系统的并发处理能力和性能。 例如,在一个电商平台中,用户经常会进行商品浏览、搜索等读操作,而商品的添加、修改、删除等写操作则相对较少。 此时,可以将读操作和写操作分别分配到不同的数据库实例上进行处理,以提高系统的并发处理能力和性能。 另外,读写分离还可以提高系统的可用性和可靠性。当主库出现故障时,从库可以接管主库的读操作,保证系统的正常运行。 6.异构数据索引:ElasticSearchElasticSearch,简称 ES,是一种分布式的搜索和分析引擎,可以随意扩容,并且天然支持高并发。 由于 ES 可以动态地扩容并增加更多的机器来处理更高的并发请求,因此它天然地具备了处理高并发请求的能力。 因此,对于一些比较简单的查询、统计类的操作,可以考虑使用 ES 来承载。此外,对于一些全文搜索类的操作,也可以使用 ES 来承载。 前面也写过两遍文章关于 ES 的介绍和使用规范: Elasticsearch 简单介绍和如何使用 在工作中 ElasticSearch 的一些使用规范 7.静态资源访问:CDN 什么是 CDN?CDN 是指内容分发网络,是一种将内容分发到全球各地的网络架构。 CDN 可以将网站的静态资源(如图片、CSS、JavaScript 等文件)缓存到全球各地的服务器上,当用户请求这些资源时,可以从离用户最近的服务器上获取资源,从而提高资源的访问速度和用户的访问体验。 CDN 的作用有哪些?CDN 的主要作用是: 提高网站的访问速度 降低带宽成本 提高可用性。同样,在高并发场景下,CDN 可以发挥重要的作用。 由于高并发场景下会有大量的用户同时访问网站,如果所有的请求都直接访问源站,就会导致源站的带宽和服务器资源受到过大的压力,从而导致网站的访问速度变慢或者出现宕机等问题。 因此,在高并发场景下,使用 CDN 可以将流量分散到全球各地的服务器上,从而减轻源站的压力,提高网站的访问速度和可用性。 8.微服务治理:上容器、k8s 弹性伸缩管理前面写了几篇关于容器和 K8S 的文章,可以看看,这里就不再赘述概念性的东西。 如何用 Docker 容器编排工具 Kubernetes 提高应用程序的可靠性和可扩展性? 原来这就是 k8s?假设有一个电商平台,该平台的用户量在特定的时间段内会出现高峰期,例如双十一、618 等大型促销活动期间。 在这些高峰期内,平台需要处理大量的并发请求,因此可以使用容器化技术和 k8s 弹性伸缩技术来解决高并发问题。 具体而言,该电商平台可以将应用程序容器化,并使用 k8s 进行容器编排、服务发现和负载均衡。 当用户发起请求时,请求会被 k8s 自动分发到不同的容器实例上,从而实现负载均衡。 此外,该电商平台还可以使用 k8s 的自动伸缩功能,在高峰期自动增加容器实例的数量,以应对高并发请求。当高峰期结束后,k8s 会自动减少容器实例的数量,以避免资源浪费。 通过使用容器化技术和 k8s 弹性伸缩技术,该电商平台可以提高系统的稳定性、性能和可用性,从而提高性能和实现更好的用户体验。 总结如何设计一个扛高并发的系统,是每个上进程序员都需要考虑的问题。 在设计高并发系统时,可以从上面讲的 8 个方面去考虑,从而实现系统的高并发处理能力和可靠性。 当然还有其它需要考虑的,比如:降级、熔断、限流等。 |

【本文地址】