| 《Java高并发与集合框架》第三部分在高并发场景中工作的集合 | 您所在的位置:网站首页 › 并发list › 《Java高并发与集合框架》第三部分在高并发场景中工作的集合 |
《Java高并发与集合框架》第三部分在高并发场景中工作的集合
|
《Java高并发与集合框架》第三部分在高并发场景中工作的集合
前言1.高并发场景中的List、Map和Set集合1.1 CopyOnWriteArrayList1.2 CopyOnWriteArrayList不支持的使用场景1.3 CopyOnWriteArrayList主要方法1.4 java.util.Collections.synchronizedList()方法的补充作用1.4.1 CopyOnWriteArrayList集合工作机制的特点1.4.2 java.utiI.CoIIections.synchronizedList()方法
1.5 Map集合实现——ConcurrentHashMap1.6 高并发场景中的List、Map、Set集合说明
2. 高并发场景中的Queue集合2.1 什么是阻塞队列,什么是非阻塞队列2.2 Queue集合实现——ArrayBlockingQueue
前言
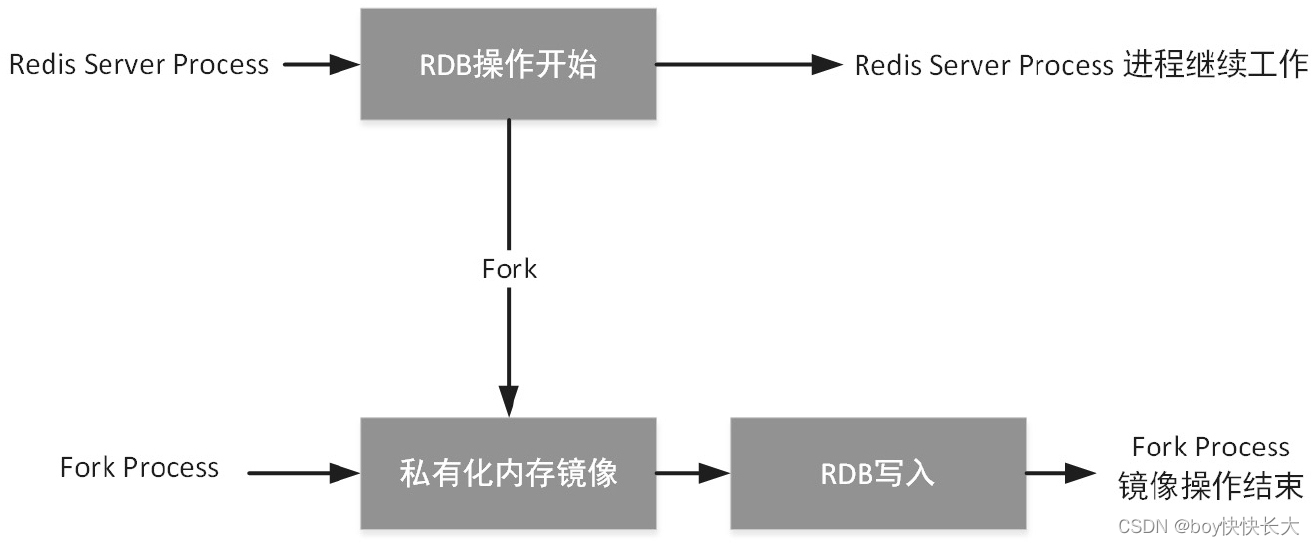
高并发场景中的集合,其优先关注的问题通常不是集合的整体性能,而是工作的稳定性和在特定场景中的高性能。 1.高并发场景中的List、Map和Set集合 1.1 CopyOnWriteArrayListCopy On Write的字面意思是写时复制。当进行指定数据的写操作时,为了不影响其他线程同时在进行的集合数据读操作,可以使用如下策略:在进行写操作前,首先复制一个数据副本,并且在数据副本中进行写操作;在副本中完成写操作后,将当前数据替换成副本数据。 很多软件在设计上都存在Copy On Write思想,被技术人员广泛熟知的是Redis中对Copy On Write思想的应用。Redis为了保证其读操作性能,在周期性进行RDB(持久化)操作时使用了CopyOn Write思想。由于RDB的操作时间主要取决于磁盘I/O性能,因此如果内存中需要进行持久化操作的数据量过大,就会产生较长的操作时间,从而影响Redis性能。改进办法是,在进行持久化操作前,先做一个当前数据的副本,并且根据副本内容进行持久化操作,从而使当前数据的状态被固定下来,并且不影响对原始数据的任何操作,如图下图所示 因此CopyOnWriteArrayList集合适合用于读操作远远多于写操作,并且在使用时需要保证集合读操作性能的多线程场景。 CopyOnWriteArrayList集合的内部结构和工作原理 CopyOnWriteArrayList集合的主要属性如下。 CopyOnWriteArrayList集合除了直接实现了java.util.List接口,还实现了java.util.RandomAccess接口。java.util.RandomAccess接口是一种标识接口,表示实现类在随机索引位上的数据读取性能不受存储的数据规模影响,即进行数据读操作的时间复杂度始终为O(1) 1.2 CopyOnWriteArrayList不支持的使用场景因为CopyOnWriteArrayList集合在进行数据写操作时,会依靠一个副本进行操作,所以不支持必须对原始数据进行操作的功能。例如,不支持在迭代器上进行的数据对象更改操作(使用remove()方法、set()方法和add()方法)源码如下。 get(int)方法 get(int)方法主要用于从CopyOnWriteArrayList集合中获取指定索引位上的数据对象,该方法无须保证线程安全性,任何操作者、任何线程、任何时间点都可以使用该方法或类似方法获取CopyOnWriteArrayList集合中的数据对象,因为该集合中的所有写操作都在一个内存副本中进行,所以任何读操作都不会受影响。 add(E)方法 add(E)方法主要用于向CopyOnWriteArrayList集合中数组的最后一个索引位上添加一个新的数据对象,添加的数据对象可以为null set(int, E)方法 1.4 java.util.Collections.synchronizedList()方法的补充作用 1.4.1 CopyOnWriteArrayList集合工作机制的特点据CopyOnWriteArrayList集合的相关介绍,可以大致归纳出CopyOnWriteArrayList集合的特点,具体如下。 该集合适合应用于多线程并发操作场景中,如果读者使用集合的场景中不涉及多线程并发操作,那么不建议使用该集合,甚至不建议使用JUC中的任何集合,使用java.util包中符合使用场景的基本集合即可。该集合在多线程并发操作场景中,优先关注点集中在如何保证集合的线程安全性和集合的数据读操作性能。因此,该集合以显著牺牲自身的写操作性能和内存空间的方式换取读操作性能不受影响。这个特征很好理解,在每次进行读操作前,都要创建一个内存副本,这种操作一定会对内存空间造成浪费,并且内存空间复制操作一定会造成多余的性能消耗。该集合适合应用于多线程并发操作、多线程读操作次数远远多于写操作次数、集合中存储的数据规模不大的场景中。 1.4.2 java.utiI.CoIIections.synchronizedList()方法Java中有没有提供一些适合在多线程场景中使用,读操作性能和写操作性能保持一定平衡性,虽然整体性能不是最好,但仍然保证线程安全的List集合呢?答案是有的。 java.util.Collections是Java为开发人员提供的一个和集合操作有关的工具包(从JDK 1.2开始提供,各版本进行了不同程度的功能调整),其中提供了一组方法,可以将java.util包下的不支持线程安全性的集合转变为支持线程安全的集合。实际上是使用Object Monitor机制将集合方法进行了封装。java.util.Collections.synchronizedList()方法的相关源码如下。
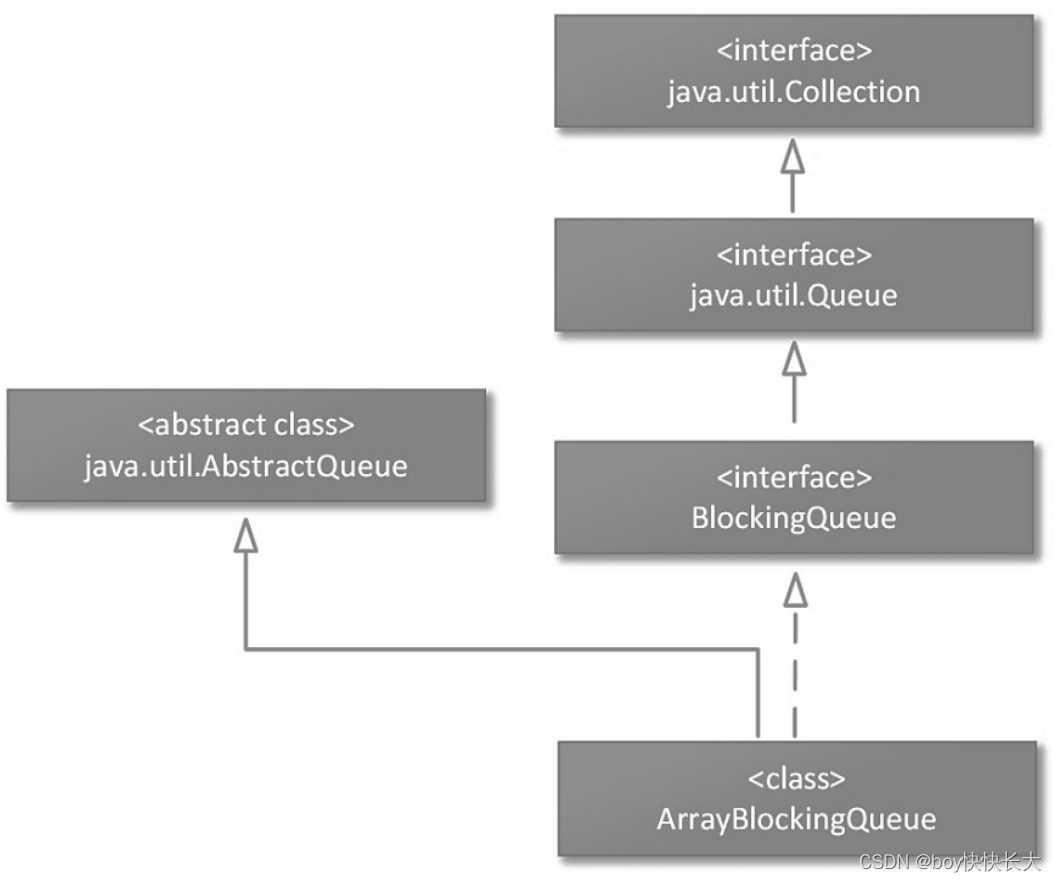
我们知道,Queue接口是BlockingQueue接口的父级接口,前者定义了一些与队列有关的接口,后者在此基础上补充了一些接口功能,Queue接口的主要方法如下。 ArrayBlockingQueue队列是一种经常使用的线程安全的Queue集合实现,它是一种内部基于数组的,可以在高并发场景中使用的阻塞队列,也是一种容量有界的队列。该队列符合先进先出(FIFO)的工作原则,也就是说,该队列头部的数据对象是最先进入队列的,也是最先被调用者取出的数据对象;该队列尾部的数据对象是最后进入队列的,也是最后被调用者取出的数据对象。 在多线程同时读/写ArrayBlockingQueue队列中的数据对象时,该队列还支持一种公平性策略,这是一种为生产者/消费者工作模式提供的功能选项(可以将ArrayBlockingQueue队列的读取操作线程看成消费者角色,将写入操作线程看成生产者角色),如果启用了这个功能选项,那么ArrayBlockingQueue队列会分别保证多个生产者线程和多个消费者线程获取ArrayBlockingQueue队列操作权限的顺序——先请求操作的线程会先获得操作权限。ArrayBlockingQueue队列的基本继承体系如图9-2所示。 |
 Copy On Write思想在Java中的一种具体实现是CopyOnWriteArrayList集合,该集合在进行写操作时会创建一个内存副本,并且在副本中进行相关操作,最后使用副本内存空间替换真实的内存空间。但是创建副本内存空间是有性能消耗的,特别是当CopyOnWriteArrayList集合中的数据量较大时。
Copy On Write思想在Java中的一种具体实现是CopyOnWriteArrayList集合,该集合在进行写操作时会创建一个内存副本,并且在副本中进行相关操作,最后使用副本内存空间替换真实的内存空间。但是创建副本内存空间是有性能消耗的,特别是当CopyOnWriteArrayList集合中的数据量较大时。 在以上源码中,CopyOnWriteArrayList集合中只有两个关键属性。lock属性是前面已经介绍过的ReentrantLock对象,CopyOnWriteArrayList集合在高并发场景中,主要使用lock属性控制线程操作权限,从而保证集合中数据对象在多线程写操作场景中的数据正确性
在以上源码中,CopyOnWriteArrayList集合中只有两个关键属性。lock属性是前面已经介绍过的ReentrantLock对象,CopyOnWriteArrayList集合在高并发场景中,主要使用lock属性控制线程操作权限,从而保证集合中数据对象在多线程写操作场景中的数据正确性
 根据add(E)方法的详细描述可知,该集合通过Arrays.copyOf()方法(其内部是System.arraycopy方法)创建一个新的内存空间,用于存储副本数组,并且在副本数组中进行写操作,最后将CopyOnWriteArrayList集合中的数组引用为副本数组
根据add(E)方法的详细描述可知,该集合通过Arrays.copyOf()方法(其内部是System.arraycopy方法)创建一个新的内存空间,用于存储副本数组,并且在副本数组中进行写操作,最后将CopyOnWriteArrayList集合中的数组引用为副本数组 在使用经过java.util.Collections工具包封装的集合时,需要特别注意:原始集合的迭代器(iterator)、可拆分的迭代器(spliterator)、处理流(stream)、并行流(parallelStream)的运行都不受这种封装机制的保护,如果用户需要使用集合中的这些方法,则必须自行控制这些方法的线程安全。
在使用经过java.util.Collections工具包封装的集合时,需要特别注意:原始集合的迭代器(iterator)、可拆分的迭代器(spliterator)、处理流(stream)、并行流(parallelStream)的运行都不受这种封装机制的保护,如果用户需要使用集合中的这些方法,则必须自行控制这些方法的线程安全。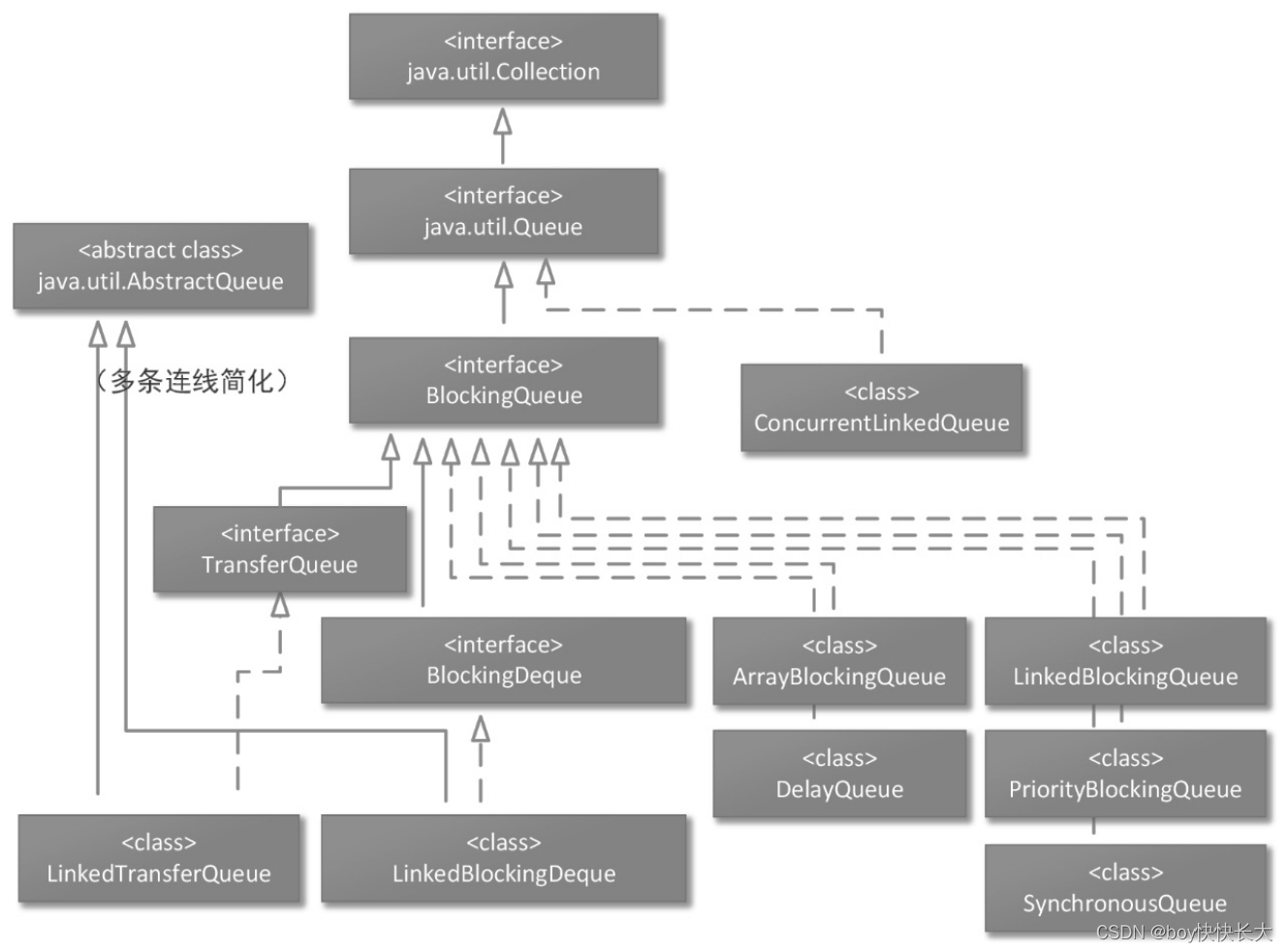


 // TODO
// TODO【本文地址】