| 数据科学的制图和数据可视化方法 | 您所在的位置:网站首页 › 尼康怎么调出九宫格 › 数据科学的制图和数据可视化方法 |
数据科学的制图和数据可视化方法
|
大部分的基础数据科学都集中在寻找以下几个方面的关系 特征 (预测变量)和一个 目标变量(结果).预测变量也被称为 独立变量,而目标变量是 因变量. 绘图和数据可视化可以在特征和目标变量之间讲述不同类型的故事,例如,比较不同的数量,研究趋势,量化关系,或显示比例等。绘图或数据可视化是数据科学中最古老和最重要的分支。 在这篇文章中,我们将研究数据科学和机器学习中使用的各种类型的图。 生成一个图的基本组成部分一个好的图或数据可视化是由几个组件组成的,这些组件必须拼凑在一起才能产生一个最终产品。 数据组件。决定如何将数据可视化的重要的第一步是知道它是什么类型的数据,例如,分类数据、离散数据、连续数据、时间序列数据等。 几何成分:在这里你要决定什么样的可视化方式适合你的数据,例如,散点图、线图、条形图、直方图、Q-Q图、平滑密度图、Boxplots、配对图、热图、饼图等。 绘图组件:在这里,你需要决定用什么变量作为你的 自变量*(x-variable*)和什么作为你的 因变量*(y-variable*)。这很重要,特别是当你的数据集是多维的,有几个特征的时候。 标度组件:在这里,你决定在你的图中使用什么样的标度,例如,线性标度、对数标度等。 标签组件:这包括像轴标签、标题、图例、使用的字体大小等。 道德成分:在这里,你要确保你的可视化描述了真实的故事。在清理、总结、处理和制作数据可视化时,你需要注意你的行为,并确保你没有利用你的可视化来误导或操纵你的观众。重要的数据可视化工具包括Python的matplotlib和seaborn包,以及R的ggplot2包。 图形和数据可视化的例子在本节中,我们将讨论数据科学和机器学习中使用的几个图。每个图的标题都包含一个链接,可以带你到原始文章,在那里你可以找到更多的细节,如数据集和用于生成图的源代码。 1.用于比较不同数量的柱状图
|
 照片:Isaac SmithonUnsplash
照片:Isaac SmithonUnsplash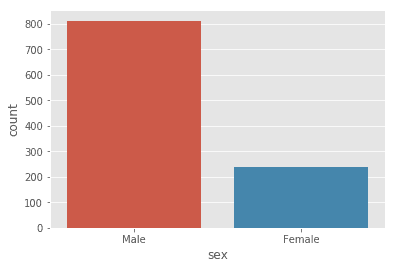 图1.数据集的分布。N=1050:812(男性)和238(女性)身高。这表明我们有一个非常不平衡的数据集,77%是男性身高,23%是女性身高。源于此。贝叶斯定理的解释。
图1.数据集的分布。N=1050:812(男性)和238(女性)身高。这表明我们有一个非常不平衡的数据集,77%是男性身高,23%是女性身高。源于此。贝叶斯定理的解释。
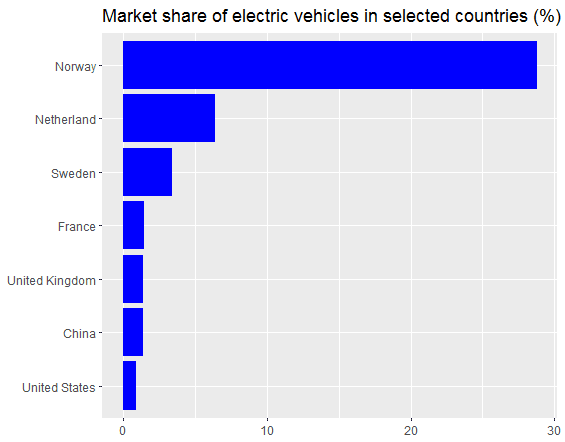 图2.2016年选定国家的电动汽车市场份额。图片由Benjamin O. Tayo提供。
图2.2016年选定国家的电动汽车市场份额。图片由Benjamin O. Tayo提供。
 图3. 2020年全球使用LinkedIn搜索工具的技能的工作数量。图片由Benjamin O. Tayo提供。
图3. 2020年全球使用LinkedIn搜索工具的技能的工作数量。图片由Benjamin O. Tayo提供。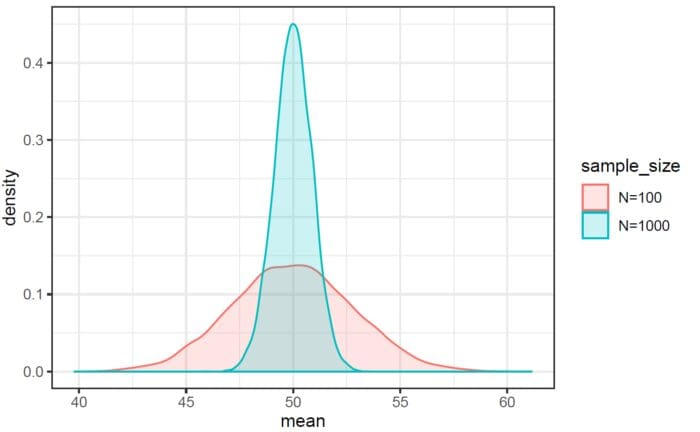 图4. 使用Monte-Carlo模拟的均匀分布的样本平均值的概率分布。图片由Benjamin O. Tayo提供。
图4. 使用Monte-Carlo模拟的均匀分布的样本平均值的概率分布。图片由Benjamin O. Tayo提供。
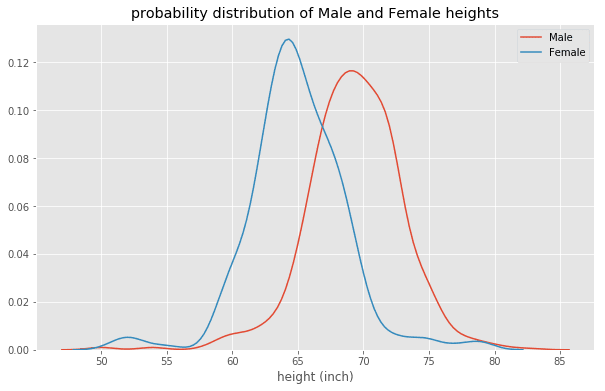 图5.男性和女性身高的概率分布。显示男性平均比女性高。
图5.男性和女性身高的概率分布。显示男性平均比女性高。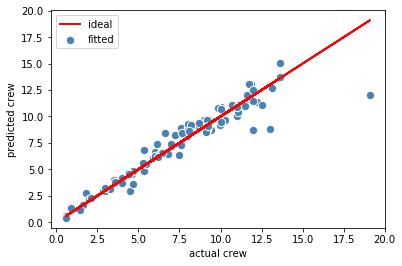 图6.使用多元回归分析的船员变量的理想图和拟合图。图片由Benjamin O. Tayo提供。
图6.使用多元回归分析的船员变量的理想图和拟合图。图片由Benjamin O. Tayo提供。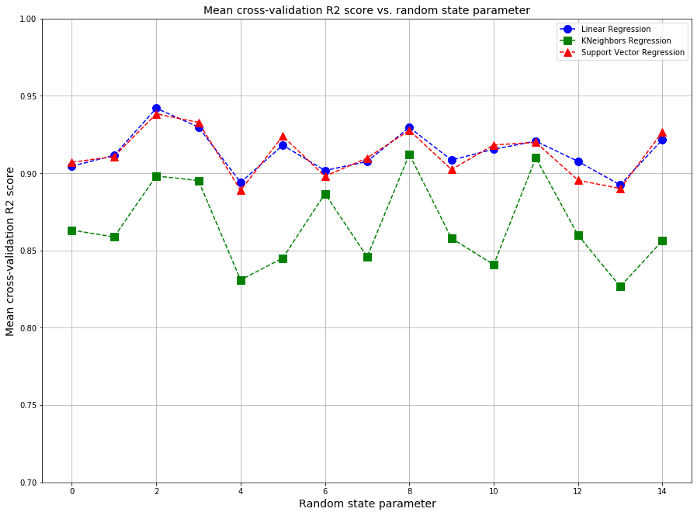 图7.不同回归模型的平均交叉验证分数。图片由Benjamin O. Tayo提供。
图7.不同回归模型的平均交叉验证分数。图片由Benjamin O. Tayo提供。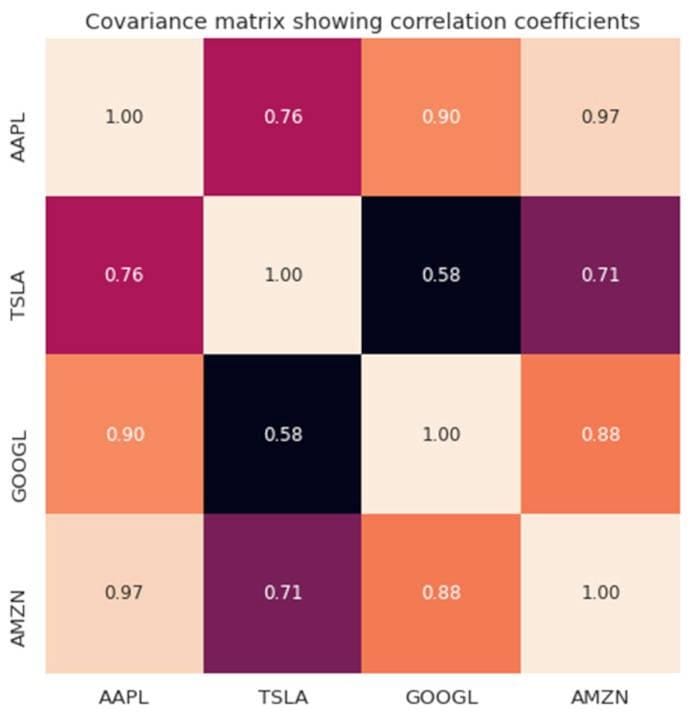 图8.所选科技股的协方差矩阵图。
图8.所选科技股的协方差矩阵图。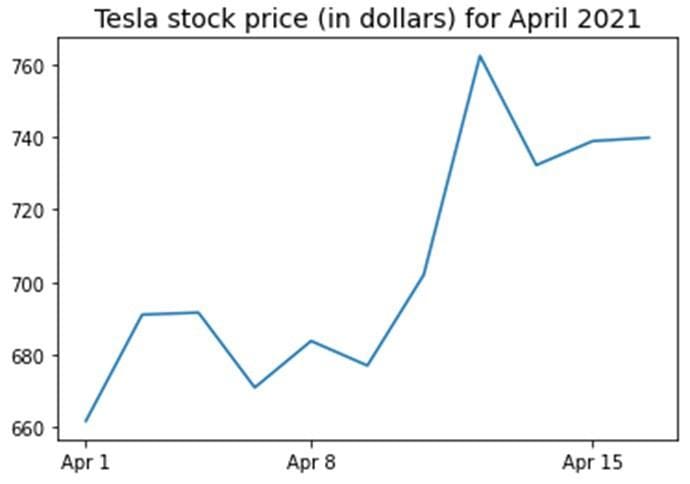 图9.特斯拉在2021年4月前16天的股价。
图9.特斯拉在2021年4月前16天的股价。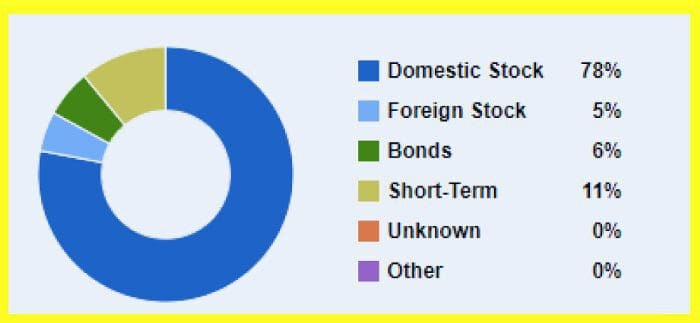 图10.显示投资组合中各种资产类别的饼图。
图10.显示投资组合中各种资产类别的饼图。【本文地址】