| 尚硅谷Kafka | 您所在的位置:网站首页 › 尚硅谷课程时间 › 尚硅谷Kafka |
尚硅谷Kafka
|
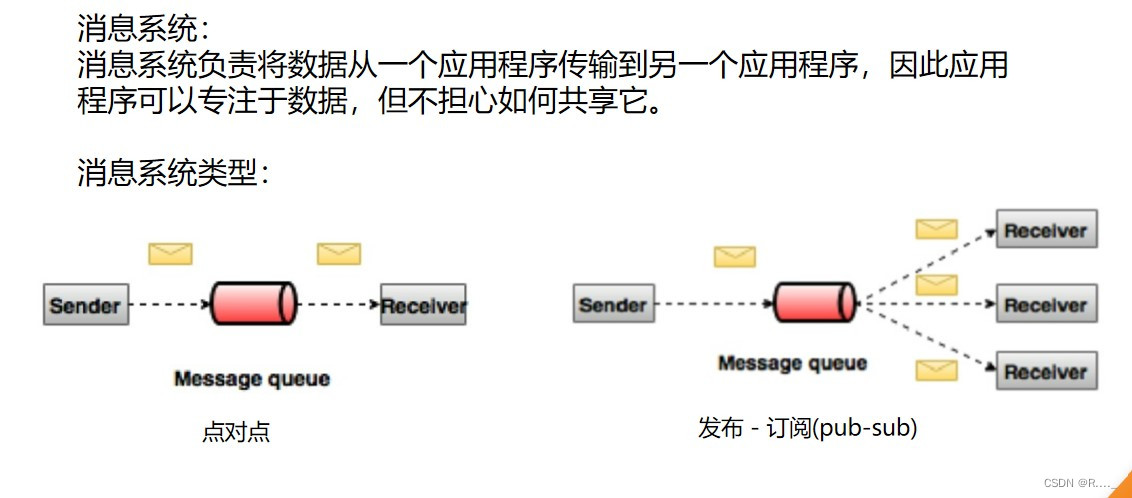
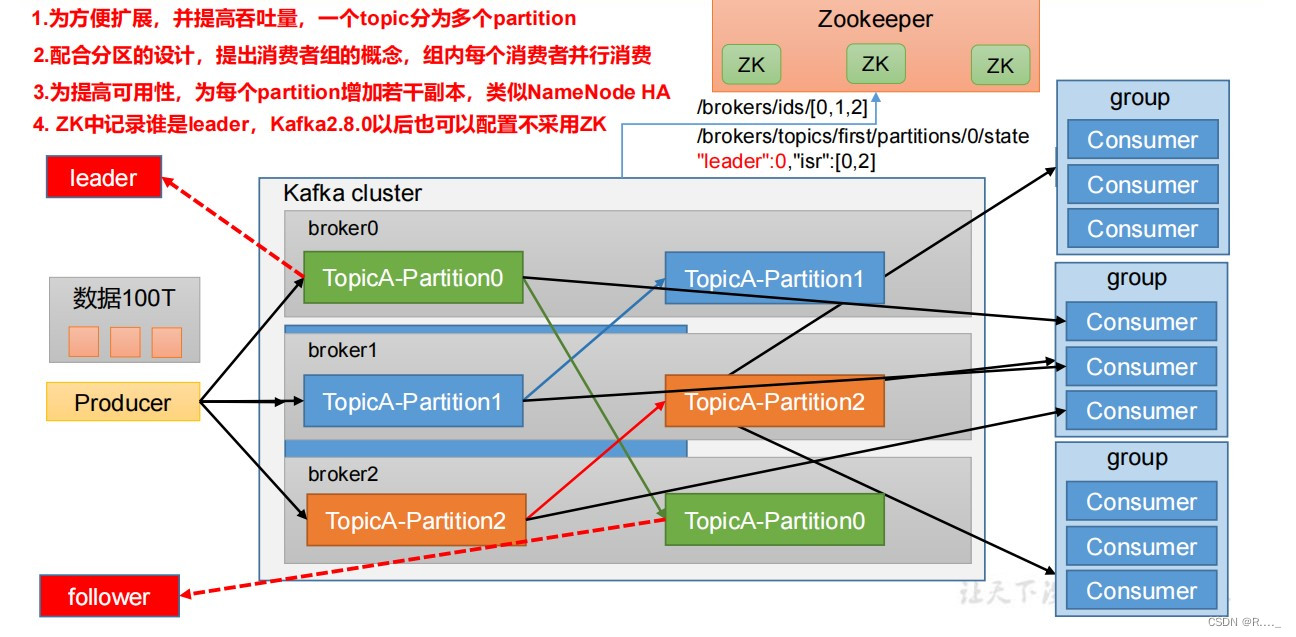
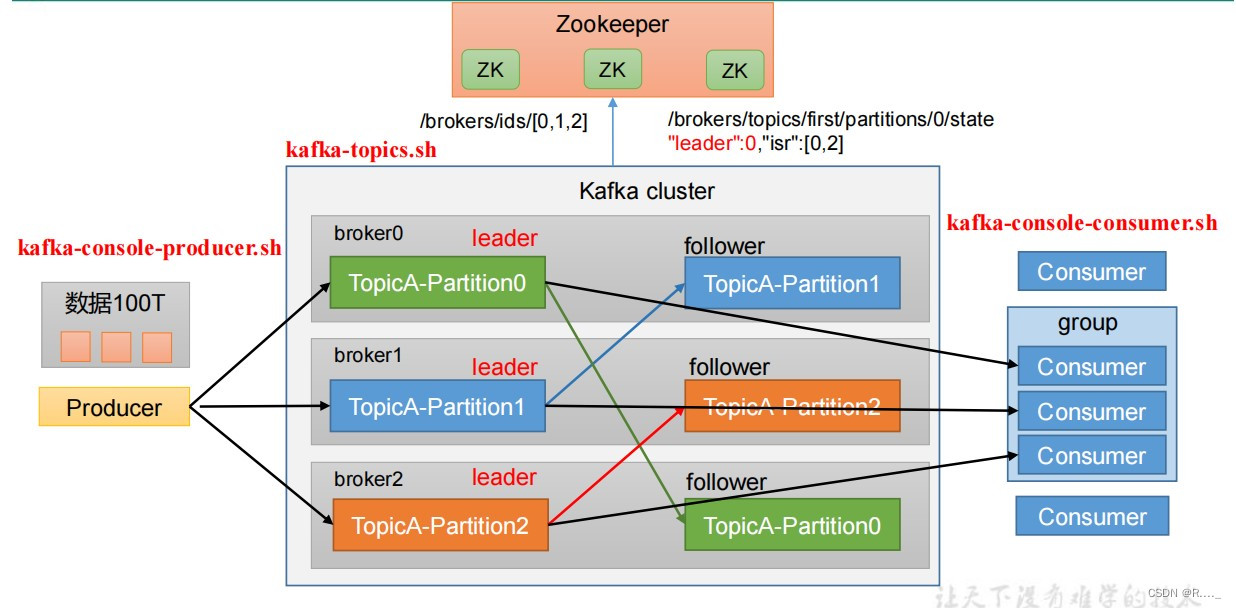
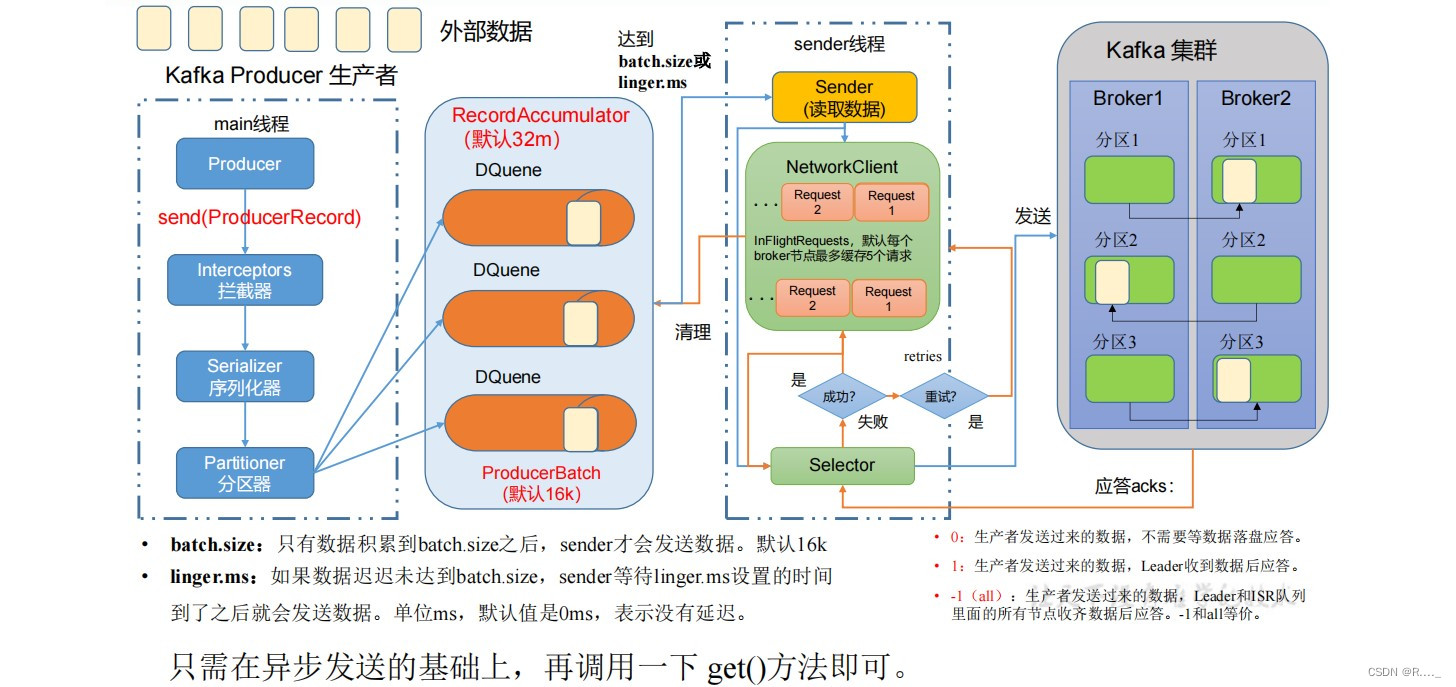
目录 一、Kafka 概述 1.1 消息队列 1.1.1 传统消息队列的应用场景 1.1.2 消息队列的两种模式 2.1 Kafka 基础架构 二、Kafka 操作 2.1 Kafka 命令行操作 2.1.1 主题命令行操作 2.2.1 生产者命令行操作 2.3.1 消费者者命令行操作 三、Kafka API 3.1 生产者消息发送流程 3.1.1 发送原理 3.2 异步发送API 3.2.1 异步发送 3.2.2 带回调函数的异步发送 3.3 同步发送API 一、Kafka 概述Kafka是最初由Linkedin公司开发,是⼀个分布式、⽀持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最⼤的特性就是可以实时的处理⼤量数据以满⾜各种需求场景:⽐如基于hadoop的批处理系统、低延迟的实时系统、Storm/Spark流式处理引擎,web/nginx⽇志、访问⽇志,消息服务等等,⽤scala语⾔编写,Linkedin于2010年贡献给了Apache基⾦会并成为顶级开源项⽬。 Kafka传统定义:Kafka是一个分布式的基于发布/订阅模式的消息队列(MessageQueue),主要应用于大数据实时处理领域. 发布/订阅:消息的发布者不会将消息直接发送给特定的订阅者,而是将发布的消息分为不同的类别,订阅者只接收感兴趣的消息。 Kafka最新定义 : Kafka是 一个开源的分布式事件流平台 (Event Streaming Platform),被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用。
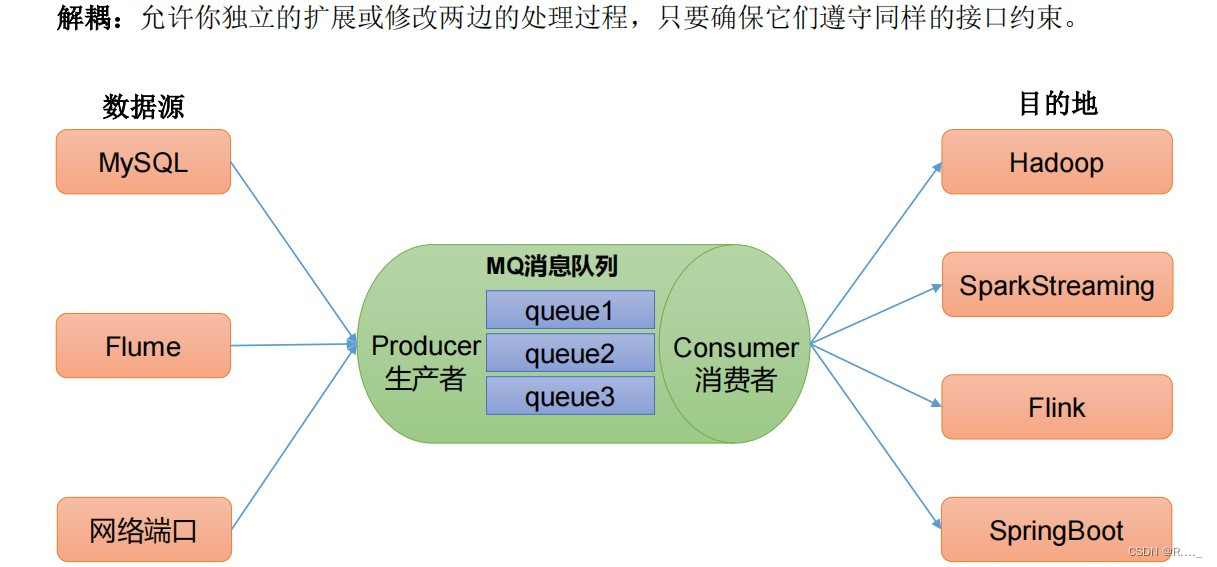
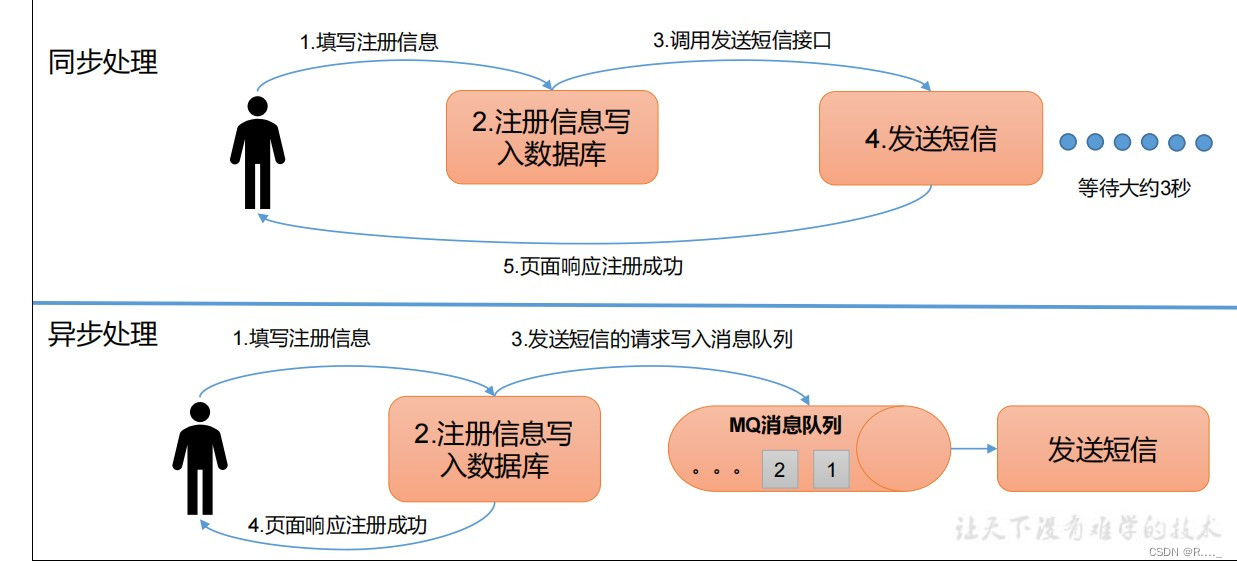
什么是流式平台呢? 流式平台有以下几种特性: 1、可以发布或订阅流式记录,类似MQ或消息系统。 2、可以存储流式记录,并有较好的容错性。 3、可以实时处理流式记录。 什么又是流式数据? 1、流数据是指由数千个数据源持续生成的数据,通常也同时以数据记录的形式发送,规模较小(约几千字节)。 2、流数据(或数据流)是指在时间分布和数量上无限的一系列动态数据集合体,数据的价值随着时间的流逝而降低,因此必须实时计算给出秒级响应。 1.1 消息队列 1.1.1 传统消息队列的应用场景 传统的消息队列的主要应用场景包括: 缓存 / 消峰 、 解耦 和 异步通信。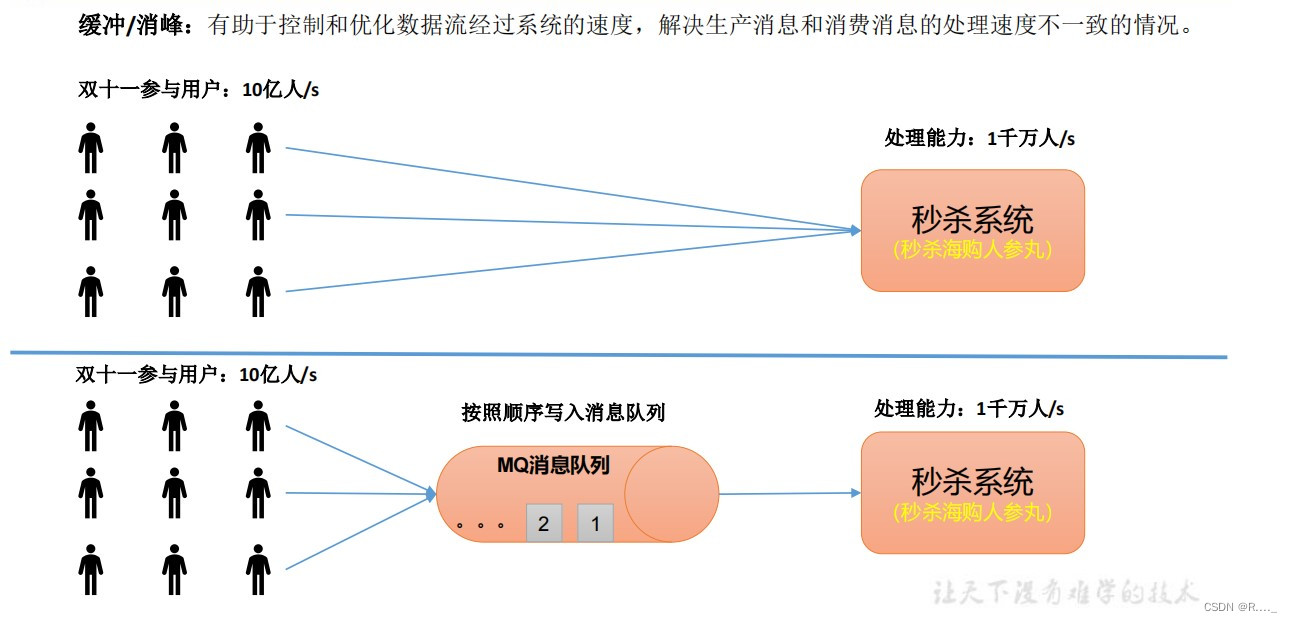
异步通信:允许用户把一个消息放入队列,但并不立即处理它,然后在需要的时候再去处理它们。
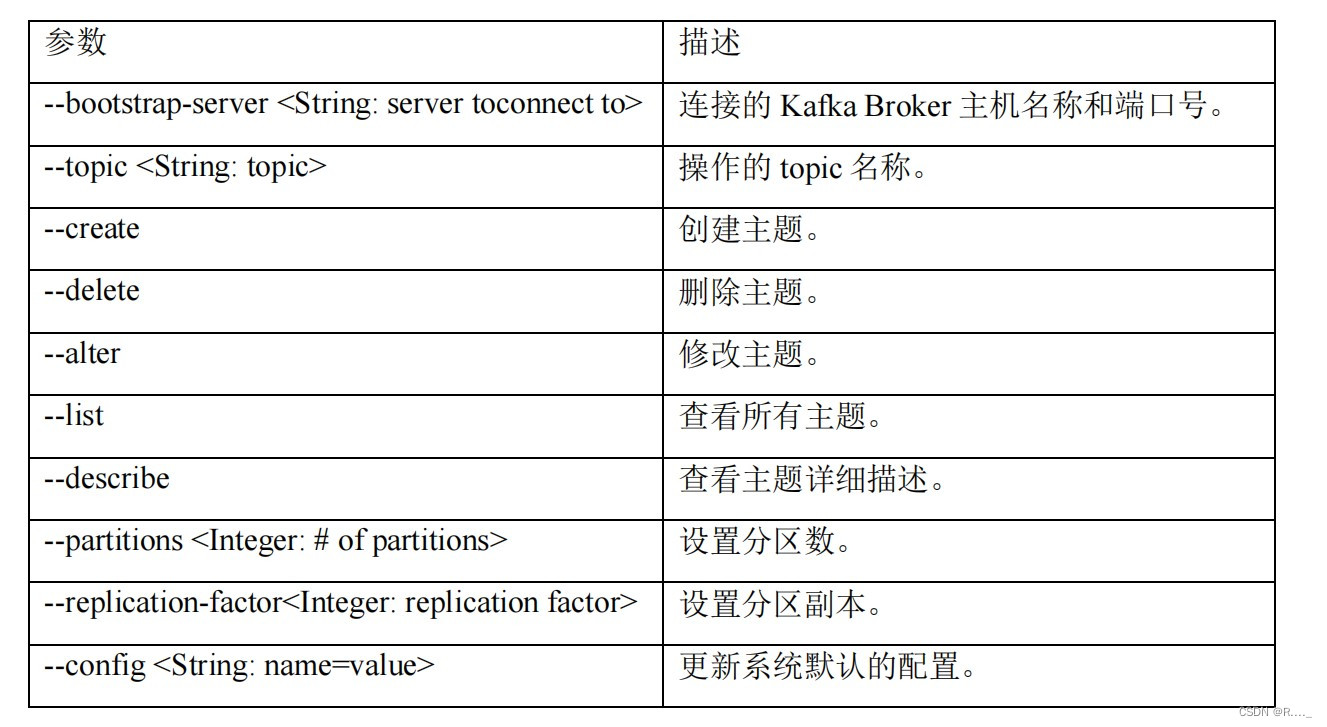
查看所有主题:
创建主题:
查看主题详细描述:
发送消息:
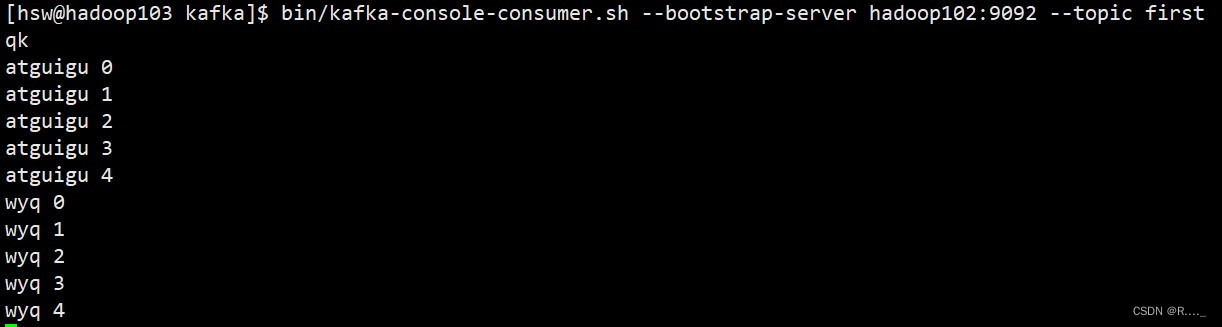
消费 first 主题中的数据:
把主题中所有的数据都读取出来(包括历史数据):
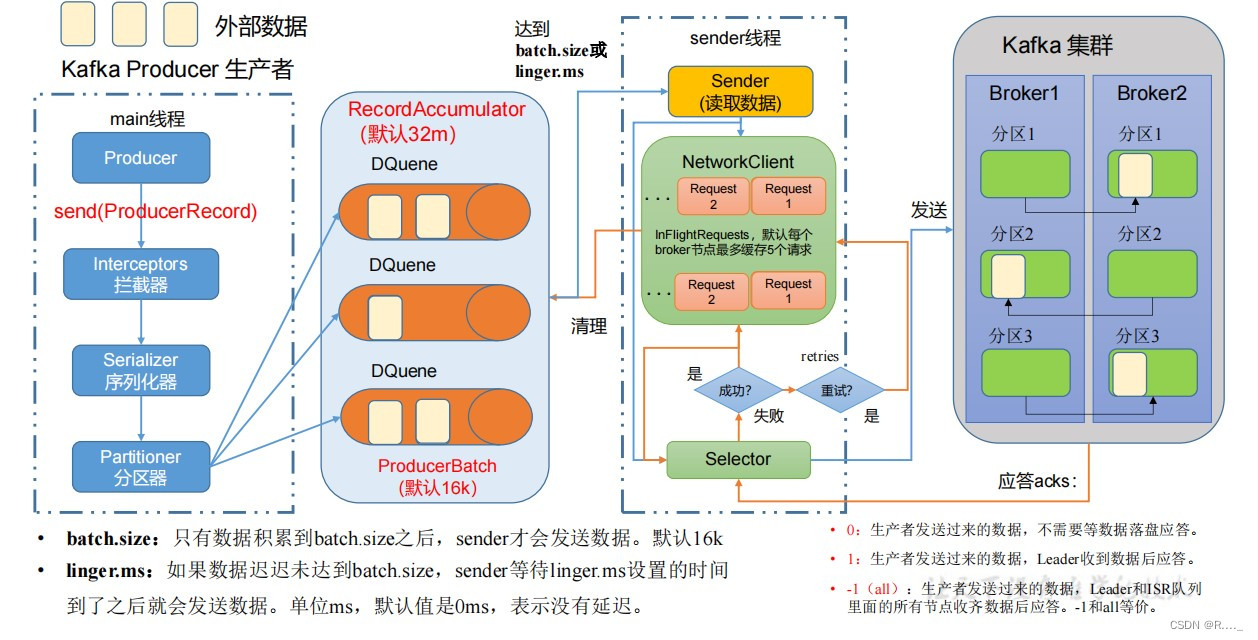 3.2 异步发送API
3.2.1 异步发送
3.2 异步发送API
3.2.1 异步发送
代码编写: public class CustomProducer { public static void main(String[] args) { // 1. 创建 kafka 生产者的配置对象 Properties properties = new Properties(); // 2. 给 kafka 配置对象添加配置信息:bootstrap.servers properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092"); // key,value 序列化(必须):key.serializer,value.serializer properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName()); // 3. 创建 kafka 生产者对象 KafkaProducer kafkaProducer = new KafkaProducer(properties); // 4. 调用 send 方法,发送消息 for (int i = 0; i < 5; i++) { kafkaProducer.send(new ProducerRecord("first","wyq " + i)); } // 5. 关闭资源 kafkaProducer.close(); } }
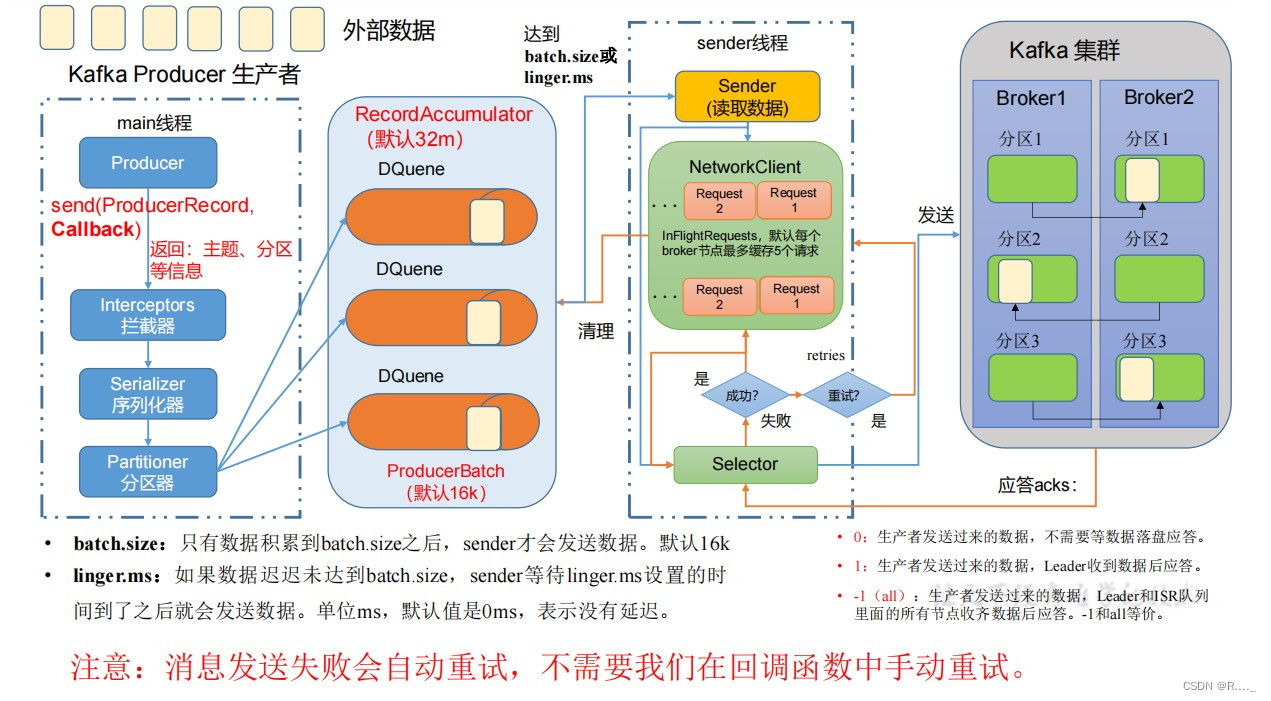
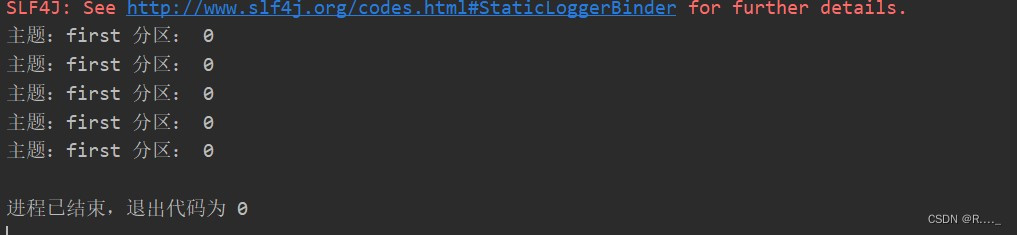
代码编写: public class CustomProducer { public static void main(String[] args) { // 1. 创建 kafka 生产者的配置对象 Properties properties = new Properties(); // 2. 给 kafka 配置对象添加配置信息:bootstrap.servers properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092"); // key,value 序列化(必须):key.serializer,value.serializer properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName()); // 3. 创建 kafka 生产者对象 KafkaProducer kafkaProducer = new KafkaProducer(properties); // 4. 调用 send 方法,发送消息 for (int i = 0; i < 5; i++) { kafkaProducer.send(new ProducerRecord("first", "wyq " + i), new Callback() { @Override public void onCompletion(RecordMetadata metadata, Exception exception) { if(exception==null){ System.out.println("主题:"+metadata.topic()+" 分区: "+metadata.partition()); } } }); } // 5. 关闭资源 kafkaProducer.close(); } }
|









【本文地址】