| 数学建模 | 您所在的位置:网站首页 › 对回归方程做拟合优度检验 › 数学建模 |
数学建模
|
多元线性回归分析
回归分析数据分类 --- 通过数据类别选择合适的建模方法数据网站线性回归 --- 横截面数据对线性的理解用新变量替换时求对应的值可以使用Excel
回归系数回归系数解释使用回归前,要检验扰动项是否满足某些条件 --- 重点扰动项
μ
\mu
μ的 内生性解决外生性 --- 核心解释变量和控制变量
当式子中有对数时,对回归系数的解释总结:四类模型回归系数的解释多变量时
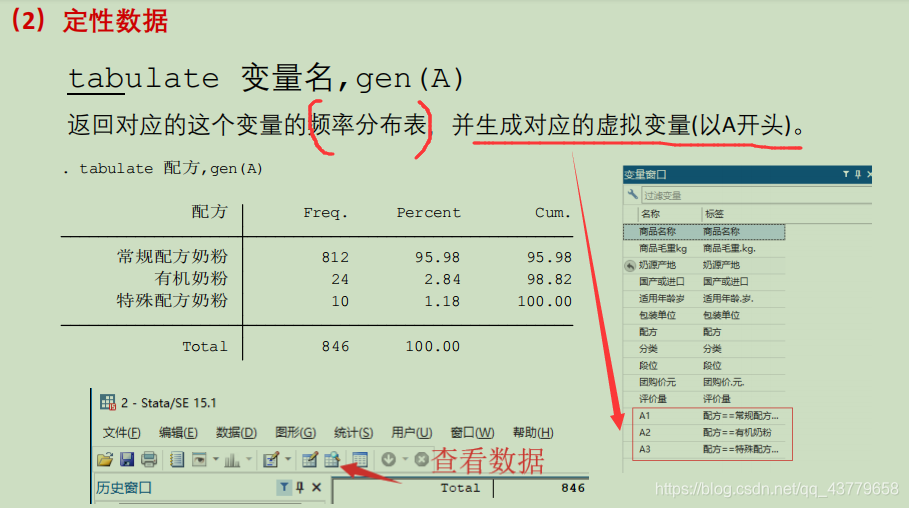
变量定性变量变为定量变量 --- 引入虚拟变量虚拟变量解释设置虚拟变量
含有交互项的自变量在论文对变量解释介绍
一元线性回归
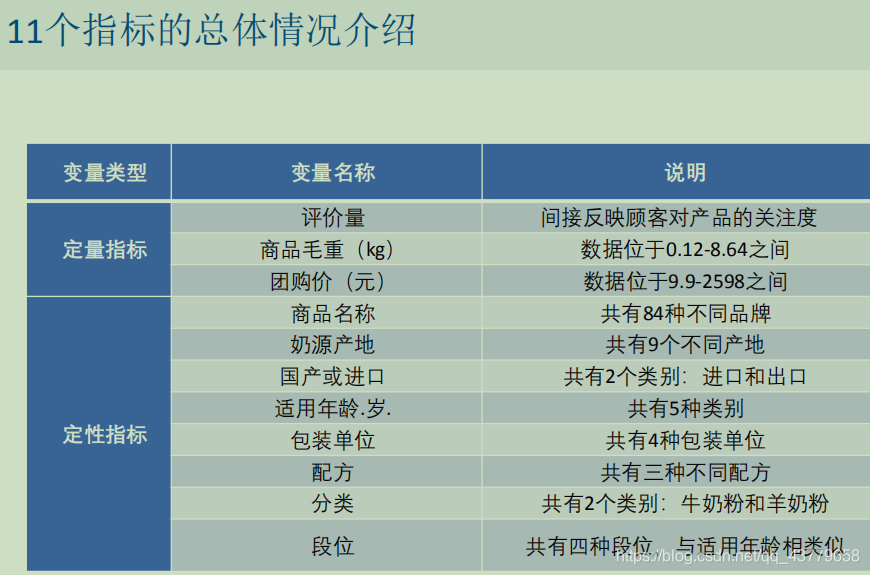
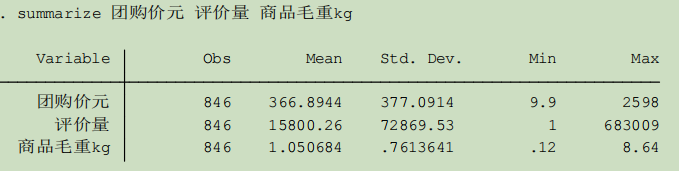
Stata对数据描述性统计定量数据定性数据 --- 生成虚拟变量Excel画出变量的频率扇形图
Stata 回归 --- 分析各个变量与因变量的关系使用回归前,要检验扰动项是否满足某些条件 --- 重点对定量变量回归联合显著性检验 ---
P
r
o
b
>
F
Prob>F
Prob>F的值看模型是否合理分析的变量选择 --- 回归系数显著回归系数解释
对定性变量回归联合显著性检验 ---
P
r
o
b
>
F
Prob>F
Prob>F的值看模型是否合理分析的变量选择 --- 回归系数显著回归系数的解释
Stata对回归分析结果用文档保存
Stata标准化回归 --- 分析各个变量对因变量的影响程度
求出的拟合优度
R
2
R^2
R2较低时拟合优度和调整后的拟合优度
回归分析
研究X与Y的相关性  不同数据处理方法 不同数据处理方法  数据分类 — 通过数据类别选择合适的建模方法
横截面数据 — 在某一时间点收集的不同对象的数据 比如:某年各省的GDP时间序列数据 — 对统一对象在不同时间所得数据 比如: 一个省每年的GDP面板数据 — 横截面数据与时间序列数据综合起来 比如: 2008-2018,各省份GDP
数据分类 — 通过数据类别选择合适的建模方法
横截面数据 — 在某一时间点收集的不同对象的数据 比如:某年各省的GDP时间序列数据 — 对统一对象在不同时间所得数据 比如: 一个省每年的GDP面板数据 — 横截面数据与时间序列数据综合起来 比如: 2008-2018,各省份GDP  数据网站
数据网站
【简道云汇总】110+数据网站 【汇总】数据来源/大数据平台 大数据工具导航 大数据查询导航 线性回归 — 横截面数据 对线性的理解自变量和因变量可以通过变量变换而转化为线性模型
多元线性回归扰动项满足的条件 扰动项 μ \mu μ的 内生性 误差项 μ \mu μ与自变量 x x x相关扰动项 μ \mu μ中包含了与 y y y有关但没有放到模型中的变量
加一句:在控制其他自变量不变的情况下 变量 定性变量变为定量变量 — 引入虚拟变量
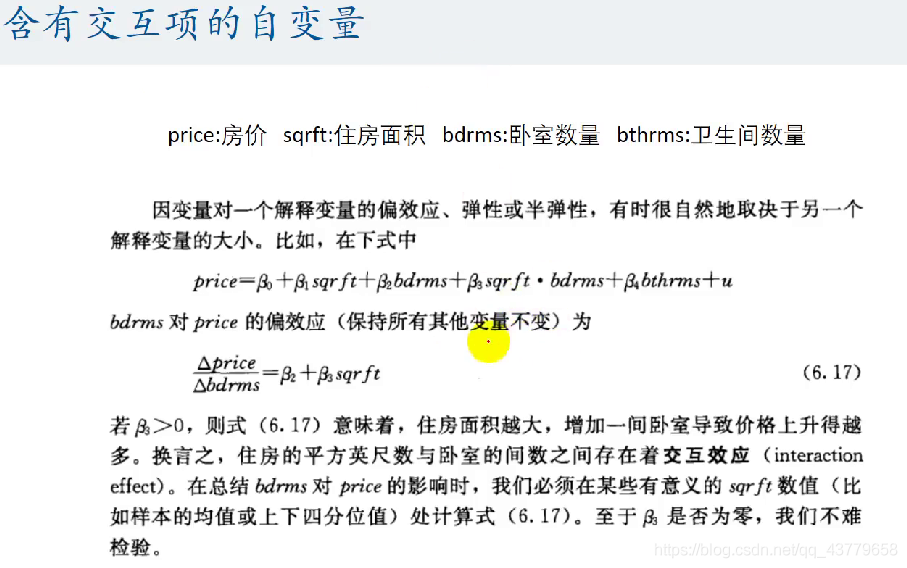
例如研究性别与工资影响: y i = β 0 + δ 0 F e m a l e i + β 1 x 1 i + β 2 x 2 i + . . . + μ i y_i=\beta_0+\delta_0Female_i+\beta_1x_{1i}+\beta_2x_{2i}+...+\mu_i yi=β0+δ0Femalei+β1x1i+β2x2i+...+μi F e m a l e i = 1 Female_i =1 Femalei=1:表示第 i i i个样本为女性 F e m a l e i = 0 Female_i =0 Femalei=0:表示第 i i i个样本为男性 核心解释变量: F e m a l e Female Female 控制变量: x m ( m = 1 , 2 , . . . k ) x_m(m=1,2,...k) xm(m=1,2,...k) 设置虚拟变量
设置虚拟变量
为了避免完全多重共线性的影响,引入虚拟变量的个数一般为分类数 - 1 比如:定性变量(男/女),有两个分类,所以设置一个虚拟变量 当出现完全多重共线性时,回归系数无法计算 含有交互项的自变量 因变量受到一个核心解释变量和另一个核心解释变量共同影响
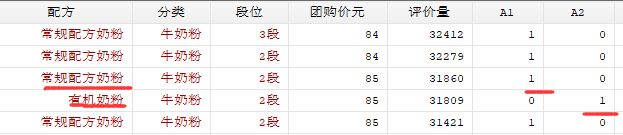
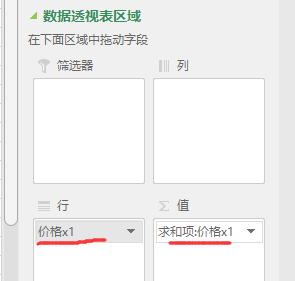 可以选择值显示的方式(数字或百分比)画出扇形图 分析 -> 数据透视图 可以选择值显示的方式(数字或百分比)画出扇形图 分析 -> 数据透视图 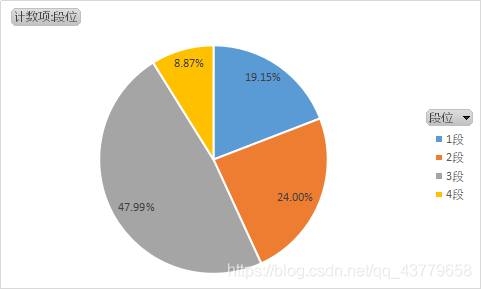
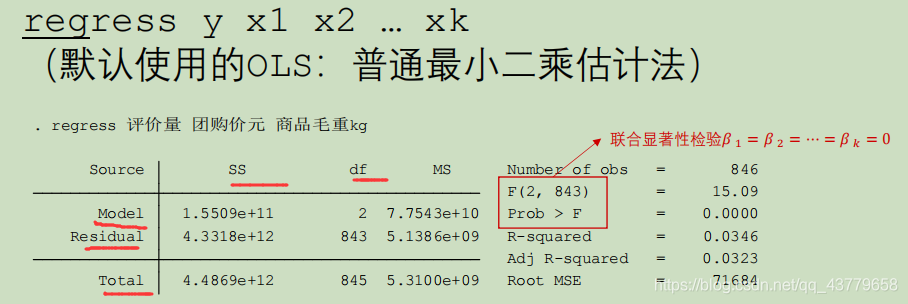
在图中加入数字 为了让画出来的图有美感 可以先进行排序后再画开始 -> 排序 可以进行颜色的变更:页面布局 -> 颜色 Stata 回归 — 分析各个变量与因变量的关系 使用回归前,要检验扰动项是否满足某些条件 — 重点多元线性回归扰动项满足的条件 对定量变量回归 regress y x1 x2 ...
上面三个对应的值在SS列中 R-squared: 代表 R 2 R^2 R2,拟合优度 0 < = R 2 < = 1 0 F Prob>F Prob>F 对应的值要 < 0.05 |t|一列 P>∣t∣一列,当值 < 0.05 F Prob>F的值看模型是否合理 P r o b > F Prob>F Prob>F 对应的值要 < 0.05 |t|一列 P>∣t∣一列,当值 < 0.05 |


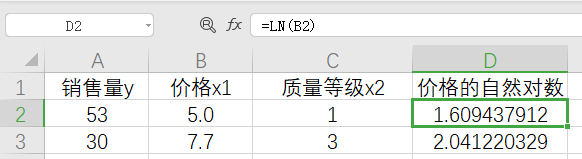


 1.对于扰动项
μ
\mu
μ满足一定的条件为:不存在内生性,不存在异方差 2. 例如: 在仅有变量
x
x
x为产品品质时,会出现内生性
1.对于扰动项
μ
\mu
μ满足一定的条件为:不存在内生性,不存在异方差 2. 例如: 在仅有变量
x
x
x为产品品质时,会出现内生性 仅仅保证核心解释变量与
μ
\mu
μ无关,而不用保证控制变量与
μ
\mu
μ无关
∴
\therefore
∴ 控制变量就是为了控制那些对核心解释变量影响的遗漏的变量(这些变量在
μ
\mu
μ中)
仅仅保证核心解释变量与
μ
\mu
μ无关,而不用保证控制变量与
μ
\mu
μ无关
∴
\therefore
∴ 控制变量就是为了控制那些对核心解释变量影响的遗漏的变量(这些变量在
μ
\mu
μ中)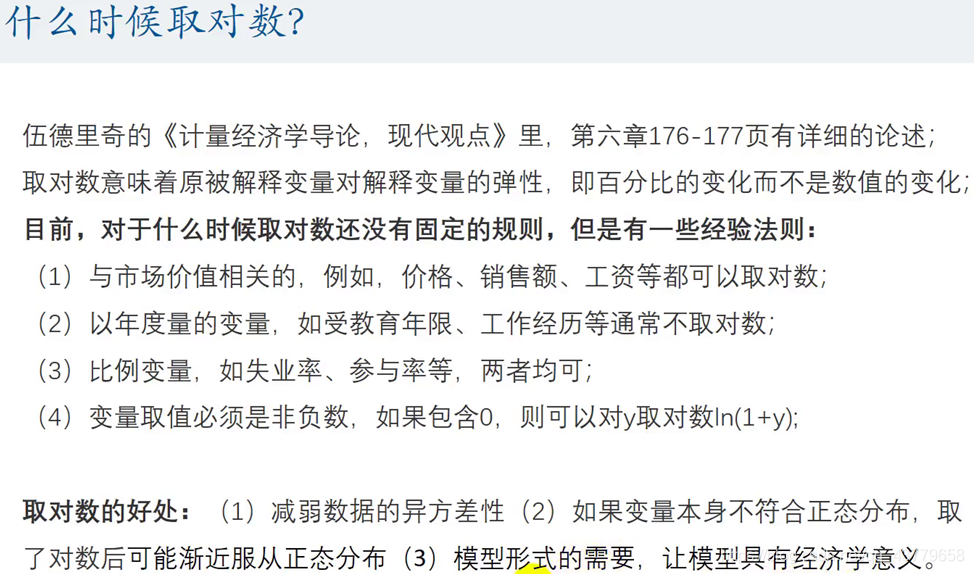




【本文地址】