| 初探强化学习(9)DQN详解 | 您所在的位置:网站首页 › 家电现在的状态是什么 › 初探强化学习(9)DQN详解 |
初探强化学习(9)DQN详解
|
1. Q-learning
https://towardsdatascience.com/reinforcement-learning-explained-visually-part-4-q-learning-step-by-step-b65efb731d3e 这个大连理工的妹子(也可能是抖脚大汉吧),讲的挺好的。还讲了代码,值得参考。 1.1 Q-learning概述Q-Learning 是 Deep Q Learning 的基础。 Q 学习算法使用状态动作值(也称为 Q 值)的 Q 表。这个 Q 表对每个状态有一行,对每个动作有一个列。每个单元格包含相应状态-动作对的估计 Q 值。 我们首先将所有 Q 值初始化为零。当agent与环境交互并获得反馈时,算法会迭代地改进这些 Q 值,直到它们收敛到最优 Q 值。它使用贝尔曼方程更新它们。 1.2 我们如何构建一个 Q 表?我们以一个简单的游戏为例。考虑一个 3x3 的网格,玩家从起始(Start)方格开始,并希望到达目标(Goal)方格作为他们的最终目的地,在那里他们获得 5 分的奖励。有的格子是Clear,有的格子是危险danger,奖励分别为0分和-10分。在任何方格中,玩家可以采取四种可能的行动来向左、向右、向上或向下移动。 正如我们刚刚看到的,Q-learning 通过学习每个状态-动作(state-action)对的最优 Q 值来找到最优策略。 让我们看一下 Q-Learning 算法的整体流程。最初,agent随机选择动作。但是当agent与环境交互时,它会根据获得的奖励了解哪些action更好。它使用这种经验来增量更新 Q 值。 让我们看一个例子来理解这一点。 在算法的第 2 步中,agent使用
ε
−
g
r
e
e
d
y
ε-greedy
ε−greedy 策略从当前状态 (S1) 中选择当前动作 (a1)。这是它传递给环境执行的动作,并以奖励 (R1) 和下一个状态 (S2) 的形式获得反馈。  个人总结,一句话总结Q-learning的更新过程。 首先agent在S1状态出,然后根据贪婪策略选择了动作a1,获得奖励R1 = 2。此时该状态的Q值是Q1 = 4。执行动作a1后,agent到达状态S2,这是,agent前窥一下S2的四个动作的q值,发现a4的q值最大,然后就通过a4的q值通过TD方法来执行S1状态的Q值的更新。 个人总结,一句话总结Q-learning的更新过程。 首先agent在S1状态出,然后根据贪婪策略选择了动作a1,获得奖励R1 = 2。此时该状态的Q值是Q1 = 4。执行动作a1后,agent到达状态S2,这是,agent前窥一下S2的四个动作的q值,发现a4的q值最大,然后就通过a4的q值通过TD方法来执行S1状态的Q值的更新。 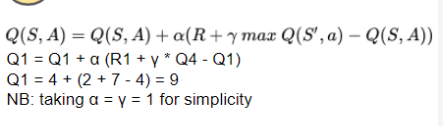  这可能听起来令人困惑,所以让我们继续下一个时间步骤,看看会发生什么。现在下一个状态已成为新的当前状态。 agent再次使用
ε
−
g
r
e
e
d
y
ε-greedy
ε−greedy 策略来选择一个动作a。如果它最终探索而不是开发,它执行的动作 (a2) 将不同于在前一个时间步中用于 Q 值更新的目标动作 (a4)。 这可能听起来令人困惑,所以让我们继续下一个时间步骤,看看会发生什么。现在下一个状态已成为新的当前状态。 agent再次使用
ε
−
g
r
e
e
d
y
ε-greedy
ε−greedy 策略来选择一个动作a。如果它最终探索而不是开发,它执行的动作 (a2) 将不同于在前一个时间步中用于 Q 值更新的目标动作 (a4)。  这被称为“off-policy”学习,因为执行的动作与用于学习的目标动作不同。
1.5 Q 表是如何填充的? 这被称为“off-policy”学习,因为执行的动作与用于学习的目标动作不同。
1.5 Q 表是如何填充的?
在游戏开始时,agent不知道哪个动作比任何其他动作更好。因此,我们首先给所有 Q 值任意估计,并将 Q 表中的所有条目设置为 0。 让我们看一个例子,说明第一个时间步发生了什么,这样我们就可以看到 Q 表是如何填充实际值的。 如果你仔细想想,像 Q Learning 这样的算法完全收敛到最优值似乎是完全不可思议的。 您从任意估计开始,然后在每个时间步,用其他估计更新这些估计。 那么为什么这最终会给你更好的估计呢? 原因是在每个时间步,估计值会变得稍微准确一些,因为它们会根据真实观察结果进行更新。 更新公式以某种加权比例组合了三个项: 当前动作的奖励下一个状态动作的最佳估计 Q 值当前状态动作的估计 Q 值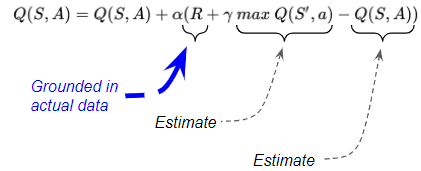 更新公式中的三个项中有两个是估计值,起初不是很准确。稍后我们将讨论这两个变量。 但是,第三项,即收到的奖励是具体的数据。这使agent能够根据环境的实际经验来学习和改进其估计。
1.7 Q 值更新为真实奖励 更新公式中的三个项中有两个是估计值,起初不是很准确。稍后我们将讨论这两个变量。 但是,第三项,即收到的奖励是具体的数据。这使agent能够根据环境的实际经验来学习和改进其估计。
1.7 Q 值更新为真实奖励
为了更清楚地看到这一点,让我们举一个例子,我们只关注 Q 表中的一个单元格(即一个状态-动作对),并跟踪该单元格的更新进度。 让我们看看状态 S3 和动作 a1(对应于橙色单元格)的 Q 值随着时间的推移会发生什么变化。我们第一次访问它时,这个单元格的 Q 值为 0。事实上,大部分 Q 表都用零填充。使用更新公式,我们用一个主要基于我们观察到的奖励 (R1) 的值来更新这个单元格。 现在让我们看看当我们再次访问该状态-动作对时会发生什么。这可能在同一episode中,也可能在未来的一episode中。 这次我们看到表中的其他一些 Q 值也被填充了值。随着代理遵循各种路径并开始访问状态-动作对,那些以前为零的单元格已被填充。 另外,请注意每次的奖励(对于来自相同状态的相同动作)不必相同。 我们已经看到奖励项如何在多次迭代中收敛到平均值或期望值。 但是更新公式中的其他两项是估计值而不是实际数据呢?尽管它们开始时非常不准确,但随着时间的推移,它们也会随着真实观察得到更新,从而提高了准确性。 下一个时间步是第 1 episode 的最后一个。在 Tᵗʰ 时间步中,agent选择一个动作以达到下一个状态,即终端状态。 由于下一个状态是Terminal ,因此没有目标动作。所以更新公式中的“最大”项为 0。这意味着对Terminal Q 值的更新仅基于实际奖励数据,而不依赖于任何估计值。这会导致Terminal Q 值的准确性提高。该episode 到此结束。 随着我们进行越来越多的迭代,更准确的 Q 值会慢慢传输到路径上更远的单元。并且随着每个单元格接收到更多更新,该单元格的 Q 值变得越来越准确。 随着越来越多的episode运行,Q 表中的值会多次更新。 我们刚刚看到 Q 值变得更加准确。但我们真正需要的是最优值。我们怎么知道我们正在到达那里? 我们了解到 State-Action Value 始终取决于策略。Q-Learning 算法隐含地使用 ε − g r e e d y ε-greedy ε−greedy 策略来计算其 Q 值。 该策略鼓励智能体探索尽可能多的状态和动作。它执行的迭代越多,探索的路径越多,我们就越有信心它已经尝试了所有可用的选项来找到更好的 Q 值。 这是 ε − g r e e d y ε-greedy ε−greedy 策略算法最终确实找到最优 Q 值的两个原因。我们已经非正式地看到了这些,但我们可以从确实存在更正式的数学证明这一事实中得到安慰! 随着每次迭代,Q值变得更好如果您进行了足够多的迭代,您将评估所有可能的选项,并且您将找不到更好的 Q 值。随着每次更新,Q 值逐渐变得更加准确,越来越接近最优值。 Q Learning 构建了一个包含 State-Action 值的 Q 表,维度为(s, a),其中s是状态数,a是动作数。从根本上说,Q 表将状态和动作对映射到 Q 值。 为了解决这个限制,我们使用 Q 函数而不是 Q 表,它实现了将状态和动作对映射到 Q 值的相同结果。 由于神经网络非常擅长对复杂函数进行建模,因此我们可以使用称为 Deep Q networks的神经网络来估计这个 Q 函数。 此函数将状态映射到可以从该状态执行的所有动作action的 Q 值。 DQN 架构有两个神经网络,Q 网络和目标网络,以及一个名为 Experience Replay 的组件。Q 网络是经过训练以产生 Optimal State-Action 值的agent。 Experience Replay 与环境交互以生成数据来训练 Q 网络。 DQN 在许多episode中经过多个时间步长进行训练。它在每个时间步执行一系列操作: 现在让我们放大第一阶段。 所有先前的体验回放观察都保存为训练数据。我们现在从该训练数据中随机抽取一批样本,使其包含较旧和较新样本的混合。 然后将这批训练数据输入到两个网络。Q 网络从每个数据样本中获取当前状态和动作,并预测该特定动作的 Q 值。这是“预测 Q 值”。 目标网络从每个数据样本中获取下一个状态,并预测可以从该状态采取的所有动作中的最佳 Q 值。这就是“目标 Q 值”。 预测 Q 值、目标 Q 值和来自数据样本的观察到的奖励用于计算损失以训练 Q 网络。目标网络没有经过训练。 您可能想知道为什么我们需要一个单独的经验回放内存?为什么我们不简单地采取行动,观察环境结果,然后将这些数据提供给 Q 网络? 答案很简单。我们知道神经网络通常需要一批数据。如果我们用单个样本训练它,每个样本和对应的梯度都会有太大的方差,网络权重永远不会收敛。 好吧,在那种情况下,显而易见的答案是,为什么我们不一个接一个地按顺序执行一些操作,然后将这些数据作为一批提供给 Q 网络?这应该有助于消除噪音并导致更稳定的训练,不是吗? 这里的答案要微妙得多。回想一下,当我们训练神经网络时,最佳实践是在随机打乱训练数据后选择一批样本。这确保了训练数据有足够的多样性,以允许网络学习有意义的权重,这些权重可以很好地泛化并可以处理一系列数据值。 如果我们从顺序操作中传递一批数据,会发生这种情况吗?让我们以机器人学习在工厂车间导航的场景为例。假设在某个时间点,它正试图在工厂的某个特定角落寻找出路。它将在接下来的几个动作中采取的所有行动都将仅限于工厂的那个部分。 如果网络试图从这批动作中学习,它将更新其权重以专门处理工厂中的该位置。但它不会了解工厂其他部分的任何信息。如果稍后某个时间,机器人移动到另一个位置,它的所有动作以及网络的学习将在一段时间内狭隘地集中在那个新位置上。然后它可能会撤消它从原始位置学到的东西。 希望您开始看到这里的问题。顺序动作彼此高度相关,并且不会像网络所希望的那样随机打乱。这导致了一个称为灾难性遗忘的问题,其中网络忘记了它不久前学到的东西。 这就是引入经验回放内存的原因。智能体从一开始就采取的所有动作和观察结果(当然受内存容量的限制)都会被存储。然后从这个内存中随机选择一批样本。这确保了批次是“混洗”的,并且包含来自较旧和较新样本的足够多样性(例如,来自工厂车间的多个区域和不同条件下),以允许网络学习权重,以推广到它将成为的所有场景需要处理。 2.11 为什么我们需要第二个神经网络(目标网络)?第二个令人费解的事情是为什么我们需要第二个神经网络?而且那个网络没有得到训练,这使得它更加令人费解。 首先,可以构建一个只有一个 Q 网络而没有目标网络的 DQN。在这种情况下,我们通过 Q 网络进行两次传递,首先输出预测 Q 值,然后输出目标 Q 值。 但这可能会产生潜在的问题。Q Network 的权重在每个时间步都会更新,从而改进了 Predicted Q 值的预测。然而,由于网络及其权重相同,它也改变了我们预测的 Target Q 值的方向。它们不会保持稳定,但会在每次更新后波动。这就像追逐一个移动的目标。 通过使用未经训练的第二个网络,我们确保目标 Q 值至少在短时间内保持稳定。但这些 Target Q 值毕竟也是预测值,我们确实希望它们得到改进,因此做出了妥协。在预先配置的时间步长之后,从 Q 网络学习到的权重被复制到目标网络。 已经发现使用目标网络会导致更稳定的训练。 2.12 DQN 深度操作现在我们了解了整体流程,我们来看看DQN的详细操作。首先,网络被初始化。 2.13 初始化对环境执行一些操作以引导重播数据。 从第一个时间步开始,Experience Replay 开始生成执行训练数据阶段phase ,并使用 Q 网络选择一个
ε
−
g
r
e
e
d
y
ε-greedy
ε−greedy动作。Q 网络在与环境交互以生成训练样本时充当agent。在此阶段不进行 DQN 训练。 Q 网络预测可以从当前状态采取的所有动作的 Q 值。我们使用这些 Q 值来选择一个
ε
−
g
r
e
e
d
y
ε-greedy
ε−greedy动作。 Experience Replay 执行
ε
−
g
r
e
e
d
y
ε-greedy
ε−greedy动作,并接收下一个状态和奖励。 我们现在开始训练 DQN 的阶段。从回放数据中选择一批训练的随机样本作为两个网络的输入。 为了简化解释,让我们从批次中获取一个样本。Q 网络可以预测从状态中采取的所有动作a的 Q 值。 从输出 Q 值中,为示例操作选择一个。这是预测的 Q 值。 样本的下一个状态输入到目标网络。目标网络预测可以从下一个状态采取的所有动作的 Q 值,并选择这些 Q 值中的最大值。 使用下一个状态作为输入来预测所有动作的 Q 值。目标网络选择所有这些 Q 值的最大值。 目标 Q 值是目标网络的输出加上样本的奖励。 使用目标 Q 值和预测 Q 值之间的差异计算均方误差损失。
使用梯度下降反向传播损失并更新 Q 网络的权重。target网络没有经过训练并且保持固定,因此不计算损失,也不进行反向传播。这样就完成了这个时间步的处理。 目标网络没有经过训练,因此没有计算损失,也没有进行反向传播。 2.22 重复下一个时间步处理重复下一个时间步长。Q 网络权重已更新,但target网络未更新。这使得 Q 网络能够学习预测更准确的 Q 值,而target Q 值在一段时间内保持固定,因此我们不是在追逐移动的目标。 在 T 个时间步之后,将 Q 个网络权重复制到目标网络。这让目标网络获得了改进的权重,因此它还可以预测更准确的 Q 值。处理像以前一样继续。 |
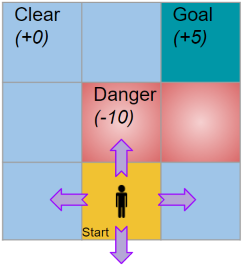 这个问题有 9 个状态,因为玩家可以位于网格的 9 个方格中的任何一个中。它有 4 个动作。所以我们构造了一个 9 行 4 列的 Q 表。 现在我们可以使用 Q 表来查找任何状态-动作(state-action)对的 Q 值。例如。特定单元格中的值,例如 ((2, 2), Up) 是状态 (2, 2) 和动作“Up”的 Q 值(或 State-Action 值)。
这个问题有 9 个状态,因为玩家可以位于网格的 9 个方格中的任何一个中。它有 4 个动作。所以我们构造了一个 9 行 4 列的 Q 表。 现在我们可以使用 Q 表来查找任何状态-动作(state-action)对的 Q 值。例如。特定单元格中的值,例如 ((2, 2), Up) 是状态 (2, 2) 和动作“Up”的 Q 值(或 State-Action 值)。  我们首先将所有 Q 值初始化为 0。
我们首先将所有 Q 值初始化为 0。 众所周知,Qlearning和sarsa算法是时间差分TD的典型代表。因此差值(difference)是 Qlearning算法的关键标志,在于它如何更新其估计值。用于在第四步中进行更新的方程基于贝尔曼方程,但如果你仔细检查它,它会使用我们之前研究过的公式的轻微变化。 让我们放大流程并更详细地检查它。
众所周知,Qlearning和sarsa算法是时间差分TD的典型代表。因此差值(difference)是 Qlearning算法的关键标志,在于它如何更新其估计值。用于在第四步中进行更新的方程基于贝尔曼方程,但如果你仔细检查它,它会使用我们之前研究过的公式的轻微变化。 让我们放大流程并更详细地检查它。 现在,对于第 4 步,算法必须使用来自下一个状态的 Q 值,以便更新当前状态和所选动作的估计 Q 值 (Q1)。 这就是 Q-Learning 算法使用其巧妙技巧的地方。下一个状态有几个动作,那么它使用哪个 Q 值?它使用具有最高 Q 值 (Q4) 的下一个状态的动作 (a4)。需要注意的关键是,它将此操作视为仅用于更新到 Q1 的目标操作。当它到达下一个时间步时,它不一定会从下一个状态开始执行。
现在,对于第 4 步,算法必须使用来自下一个状态的 Q 值,以便更新当前状态和所选动作的估计 Q 值 (Q1)。 这就是 Q-Learning 算法使用其巧妙技巧的地方。下一个状态有几个动作,那么它使用哪个 Q 值?它使用具有最高 Q 值 (Q4) 的下一个状态的动作 (a4)。需要注意的关键是,它将此操作视为仅用于更新到 Q1 的目标操作。当它到达下一个时间步时,它不一定会从下一个状态开始执行。  现在它已经确定了目标 Q 值,它使用更新公式计算当前 Q 值的新值,使用奖励和目标 Q 值……
现在它已经确定了目标 Q 值,它使用更新公式计算当前 Q 值的新值,使用奖励和目标 Q 值……  …并更新当前的 Q 值。
…并更新当前的 Q 值。  换句话说,涉及两个动作:
换句话说,涉及两个动作: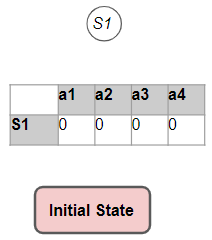 然后算法选择一个
ε
−
g
r
e
e
d
y
ε-greedy
ε−greedy 动作,从环境中获取反馈,并使用公式更新 Q 值,如下所示。这个新的 Q 值反映了我们观察到的奖励。
然后算法选择一个
ε
−
g
r
e
e
d
y
ε-greedy
ε−greedy 动作,从环境中获取反馈,并使用公式更新 Q 值,如下所示。这个新的 Q 值反映了我们观察到的奖励。  通过这种方式,Q 表的一个单元格从零值变为填充了来自环境的一些真实数据。 我们的目标是让 Q 值收敛到它们的最优值。我们看到这些 Q 值被填充了一些东西,但是,它们是用随机值更新的,还是它们逐渐变得更加准确?
通过这种方式,Q 表的一个单元格从零值变为填充了来自环境的一些真实数据。 我们的目标是让 Q 值收敛到它们的最优值。我们看到这些 Q 值被填充了一些东西,但是,它们是用随机值更新的,还是它们逐渐变得更加准确? 个人解释:从这边可以看出设置奖励值的重要性。在Q值都是0的前N步,这些状态-动作对的Q值的更新完全由奖励函数确定。而且这种影响很可能会后续的算法的准确性
个人解释:从这边可以看出设置奖励值的重要性。在Q值都是0的前N步,这些状态-动作对的Q值的更新完全由奖励函数确定。而且这种影响很可能会后续的算法的准确性 让我们第三次访问那个单元格。顺便说一句,请注意,在我们的三个访问中,目标操作(紫色)不必相同。
让我们第三次访问那个单元格。顺便说一句,请注意,在我们的三个访问中,目标操作(紫色)不必相同。  让我们在一张图片中布局我们对同一单元格的所有访问,以可视化随时间的进展。随着我们在许多情节中越来越多地访问相同的状态-动作对,我们每次都会收集奖励。个人奖励观察可能会波动,但随着时间的推移,奖励将趋于其预期值。这允许 Q 值也随时间收敛。
让我们在一张图片中布局我们对同一单元格的所有访问,以可视化随时间的进展。随着我们在许多情节中越来越多地访问相同的状态-动作对,我们每次都会收集奖励。个人奖励观察可能会波动,但随着时间的推移,奖励将趋于其预期值。这允许 Q 值也随时间收敛。  回想一下 Q 值(或 State-Action 值)代表什么。它说您首先从特定状态s采取特定动作a,然后遵循该策略直到episode结束,然后衡量回报。如果你在很多episode中多次这样做,Q 值就是你会得到的平均回报。
回想一下 Q 值(或 State-Action 值)代表什么。它说您首先从特定状态s采取特定动作a,然后遵循该策略直到episode结束,然后衡量回报。如果你在很多episode中多次这样做,Q 值就是你会得到的平均回报。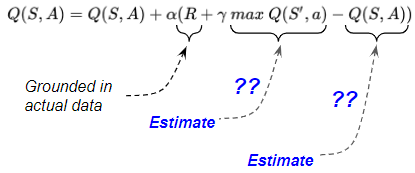 为了理解这一点,让我们看一个episode 的最后两个时间步长的例子,当我们到达终端状态时。我们将看到终端 Q 值的准确性得到提高,因为它只使用真实的奖励数据进行更新,而没有估计值。并且该 Q 值开始回溯到它之前的 Q 值,依此类推,逐步提高 Q 值在路径上的准确性。 我们将在episode 结束时关注Terminal Q 值(蓝色单元格)和Terminal前 Q 值(绿色单元格)的更新。 假设在第 1 episode 快结束时,在 (T - 1)ˢᵗ 时间步中,agent选择如下动作。Before-Terminal Q 值根据目标动作进行更新。
为了理解这一点,让我们看一个episode 的最后两个时间步长的例子,当我们到达终端状态时。我们将看到终端 Q 值的准确性得到提高,因为它只使用真实的奖励数据进行更新,而没有估计值。并且该 Q 值开始回溯到它之前的 Q 值,依此类推,逐步提高 Q 值在路径上的准确性。 我们将在episode 结束时关注Terminal Q 值(蓝色单元格)和Terminal前 Q 值(绿色单元格)的更新。 假设在第 1 episode 快结束时,在 (T - 1)ˢᵗ 时间步中,agent选择如下动作。Before-Terminal Q 值根据目标动作进行更新。  注意:为简单起见,我们将分别使用符号 Q2 和 Q6 代替 Q(2, 2) 和 Q(6,4)
注意:为简单起见,我们将分别使用符号 Q2 和 Q6 代替 Q(2, 2) 和 Q(6,4) 每当我们在后续episode (例如情节 2)中再次访问Terminal 前状态时,在 (T - 1)ˢᵗ 时间步长中,Terminal 前 Q 值会像以前一样根据目标动作进行更新。 更新公式中的“最大”项对应于Terminal Q 值。因此,当更新发生时,就好像这个Terminal Q 值被向后传输到Terminal 前 Q 值。
每当我们在后续episode (例如情节 2)中再次访问Terminal 前状态时,在 (T - 1)ˢᵗ 时间步长中,Terminal 前 Q 值会像以前一样根据目标动作进行更新。 更新公式中的“最大”项对应于Terminal Q 值。因此,当更新发生时,就好像这个Terminal Q 值被向后传输到Terminal 前 Q 值。  让我们在一张图片中列出这三个时间步长,以可视化随时间的进展。我们已经看到Terminal Q 值(蓝色单元格)使用实际数据而不是估计值进行了更新。我们还看到,这个Terminal Q 值回溯到Terminal 前 Q 值(绿色单元格)。
让我们在一张图片中列出这三个时间步长,以可视化随时间的进展。我们已经看到Terminal Q 值(蓝色单元格)使用实际数据而不是估计值进行了更新。我们还看到,这个Terminal Q 值回溯到Terminal 前 Q 值(绿色单元格)。  因此,随着Terminal Q 值的准确性缓慢提高,Terminal 前 Q 值也变得更加准确。 随后,这些 Q 值逐渐回到 (T - 2)ᵗʰ 时间步长,依此类推。 通过这种方式,随着估计的 Q 值沿着情节的路径回溯,两个估计的 Q 值项也以实际观察为基础,并提高了准确性。
因此,随着Terminal Q 值的准确性缓慢提高,Terminal 前 Q 值也变得更加准确。 随后,这些 Q 值逐渐回到 (T - 2)ᵗʰ 时间步长,依此类推。 通过这种方式,随着估计的 Q 值沿着情节的路径回溯,两个估计的 Q 值项也以实际观察为基础,并提高了准确性。 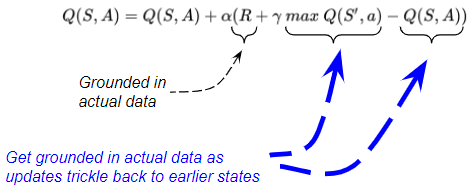

 这显然不是严格的证明,但希望这能让您对 Q Learning 的工作原理以及它为何收敛有一个直观的感受。 了解了Q-learning之后,下面开始讲解DQN
这显然不是严格的证明,但希望这能让您对 Q Learning 的工作原理以及它为何收敛有一个直观的感受。 了解了Q-learning之后,下面开始讲解DQN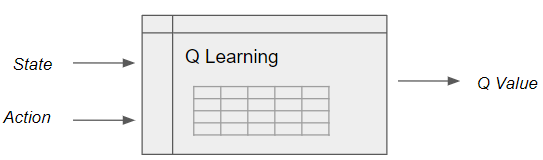 然而,在现实世界的场景中,状态的数量可能很大,使得构建表格在计算上变得难以处理。
然而,在现实世界的场景中,状态的数量可能很大,使得构建表格在计算上变得难以处理。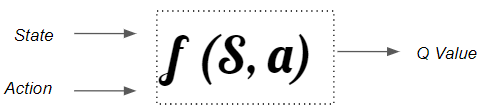 需要一个状态动作函数来处理具有大状态空间的现实世界场景。
需要一个状态动作函数来处理具有大状态空间的现实世界场景。 它学习网络的参数(权重),以便输出最优 Q 值。 DQN的基本原理与 Q 学习算法非常相似。它从任意 Q 值估计开始,并使用
ε
−
g
r
e
e
d
y
ε-greedy
ε−greedy策略探索环境。在其核心,它使用双重动作的相同概念,即具有当前 Q 值的当前动作和具有目标 Q 值的目标动作,用于其更新逻辑以改进其 Q 值估计。
它学习网络的参数(权重),以便输出最优 Q 值。 DQN的基本原理与 Q 学习算法非常相似。它从任意 Q 值估计开始,并使用
ε
−
g
r
e
e
d
y
ε-greedy
ε−greedy策略探索环境。在其核心,它使用双重动作的相同概念,即具有当前 Q 值的当前动作和具有目标 Q 值的目标动作,用于其更新逻辑以改进其 Q 值估计。 Q 网络是一个相当标准的神经网络架构,如果你的状态可以通过一组数值变量来表示,它可以像具有几个隐藏层的线性网络一样简单。或者,如果您的状态数据表示为图像或文本,您可能会使用常规的 CNN 或 RNN 架构。 Target 网络与 Q 网络相同,这两个网络的结构是一样的,只是更新的时间段不一样,。
Q 网络是一个相当标准的神经网络架构,如果你的状态可以通过一组数值变量来表示,它可以像具有几个隐藏层的线性网络一样简单。或者,如果您的状态数据表示为图像或文本,您可能会使用常规的 CNN 或 RNN 架构。 Target 网络与 Q 网络相同,这两个网络的结构是一样的,只是更新的时间段不一样,。
 Experience Replay 从当前状态中选择一个
ε
−
g
r
e
e
d
y
ε-greedy
ε−greedy 动作,在环境中执行,取回一个奖励
r
r
r和下一个状态
s
′
s'
s′。
Experience Replay 从当前状态中选择一个
ε
−
g
r
e
e
d
y
ε-greedy
ε−greedy 动作,在环境中执行,取回一个奖励
r
r
r和下一个状态
s
′
s'
s′。  它将这个观察结果保存为训练数据的样本。
它将这个观察结果保存为训练数据的样本。  接下来,我们将放大流程的下一阶段。
接下来,我们将放大流程的下一阶段。 



 使用随机权重初始化 Q 网络并将它们复制到target 网络。
使用随机权重初始化 Q 网络并将它们复制到target 网络。 

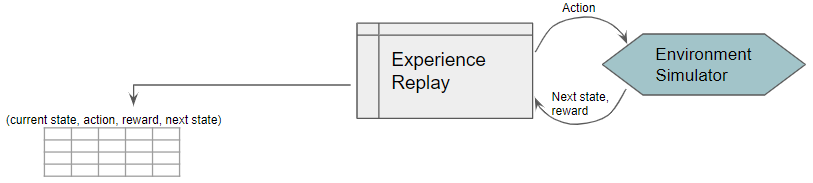
 它将结果存储在回放数据中。每个这样的结果都是一个样本观察,稍后将用作训练数据。
它将结果存储在回放数据中。每个这样的结果都是一个样本观察,稍后将用作训练数据。 









 Q 网络权重和目标网络再次相等。
Q 网络权重和目标网络再次相等。【本文地址】
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |