| 机器学习实战15 | 您所在的位置:网站首页 › 实战训练是什么意思 › 机器学习实战15 |
机器学习实战15
|
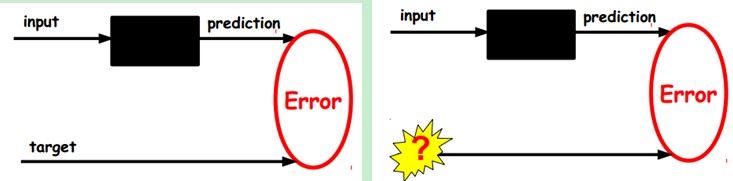
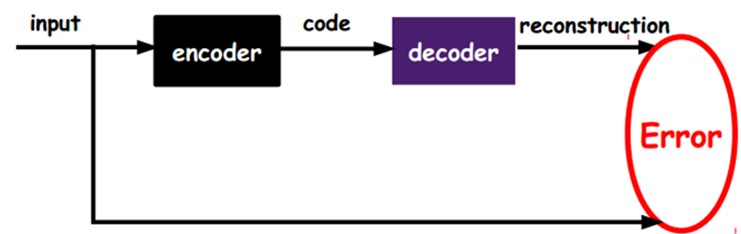
大话循环神经网络(RNN):https://my.oschina.net/u/876354/blog/1621839 自动编码器自动编码器是能够在无监督的情况下学习输入数据的有效表示(编码)的人工神经网络(训练集是未标记)。这些编码通常具有比输入数据低得多的维度,使得自编码器对降维有用。更重要的是,自动编码器可以作为强大的特征检测器,它们可以用于无监督的深度神经网络预训练。最后,他们能够随机生成与训练数据非常相似的新数据;这被称为生成模型。例如,您可以在脸部图片上训练自编码器,然后可以生成新脸部。 自编码器只需学习将输入复制到其输出即可工作。 这听起来像是一件小事,但我们会看到以各种方式约束网络可能会让它变得相当困难。例如,限制内部表示的大小,或者可以向输入添加噪声并训练网络以恢复原始输入。这些约束防止自编码器将输入直接复制到输出,这迫使它学习表示数据的有效方法。编码是自编码器在某些限制条件下尝试学习恒等函数的副产品。 我们假设其输出与输入是相同的,然后训练调整其参数,得到每一层中的权重。我们就得到了输入I的几种不同表示(每一层代表一种表示),这些表示就是特征。自动编码器就是一种尽可能复现输入信号的神经网络。为了实现这种复现,自动编码器就必须捕捉可以代表输入数据的最重要的因素,就像PCA那样,找到可以代表原信息的主要成分。 具体过程简单的说明如下: 1)给定无标签数据,用非监督学习学习特征: 在我们之前的神经网络中,如第一个图,我们输入的样本是有标签的,即(input, target),这样我们根据当前输出和target (label)之间的差去改变前面各层的参数,直到收敛。但现在我们只有无标签数据,也就是右边的图。那么这个误差怎么得到呢? 如上图,我们将input输入一个encoder编码器,就会得到一个code,这个code也就是输入的一个表示,那么我们怎么知道这个code表示的就是input呢?我们加一个decoder解码器,这时候decoder就会输出一个信息,那么如果输出的这个信息和一开始的输入信号input是很像的(理想情况下就是一样的),那很明显,我们就有理由相信这个code是靠谱的。所以,我们就通过调整encoder和decoder的参数,使得重构误差最小,这时候我们就得到了输入input信号的第一个表示了,也就是编码code了。因为是无标签数据,所以误差的来源就是直接重构后与原输入相比得到。 自动编码器由两部分组成:一个编码器函数h = f(x) 和一个生成重构的解码器r = g(h)。传统上,自动编码器被用于降维或特征学习。是一种无监督学习算法,它使用了反向传播算法,并让目标值等于输入值,比如y(i)=x(i) 。 换句话说,它尝试逼近一个恒等函数,从而使得输出y(1)接近于输入x(1) 。恒等函数虽然看上去不太有学习的意义,但是当我们为自编码神经网络加入某些限制,比如限定隐藏神经元的数量,我们就可以从输入数据中发现一些有趣的结构。举例来说,假设某个自编码神经网络的输入x 是一张 10×10图像(共100个像素)的像素灰度值,于是 n=100 ,其隐藏层L2中有50个隐藏神经元。注意,输出也是100维。由于只有50个隐藏神经元,我们迫使自编码神经网络去学习输入数据的压缩表示,也就是说,它必须从50维的隐藏神经元激活度向量a(2)中重构出100维的像素灰度值输入x 。 自动编码器通常和多层感知器MLP具有相同的架构,不同之处在于自动编码器的输出层的神经元数量必须等于输入层的数量。在这个例子中,只有一个隐藏层,由两个神经元(编码器)组成,一个输出层,由三个神经元(解码器)组成。输出通常被称为重建,因为自动编码器尝试重建输入,并且成本函数包含重建损失,当重建与输入不同时,该损失会惩罚模型。 如上图,因为内部表示的维度低于输入数据(它是2D而不是3D),因此自动编码器不完整。不完整的自动编码器不能简单地复制输入到编码,但是它必须找到一种输出其输入副本的方法。它被强制学习输入数据中最重要的功能(并删除不重要的功能)。让我们看看如何实现一个用来降低维度的非常简单的不完整自动编码器。 1、使用不完整的线性自动编码器实现PCA如果自动编码器仅使用线性激活,并且成本函数是均方误差(MSE),则表示它可以用来实现主要组件分析。以下代码构建了一个简单的线性自动编码器,用于执行PCA,将3D数据集投影为2D。 import numpy.random as rnd rnd.seed(4) m=200 w1,w2=0.1,0.3 noise=0.1 angles=rnd.rand(m)*3*np.pi/2-0.5 data=np.empty((m,3)) data[:,0]=np.cos(angles) + np.sin(angles)/2 + noise * rnd.randn(m) / 2 data[:, 1] = np.sin(angles) * 0.7 + noise * rnd.randn(m) / 2 data[:, 2] = data[:, 0] * w1 + data[:, 1] * w2 + noise * rnd.randn(m) from sklearn.preprocessing import StandardScaler#标准化 scaler=StandardScaler() X_train=scaler.fit_transform(data[:100])# 前100行用于训练 X_test=scaler.transform(data[100:]) import tensorflow as tf reset_graph() n_inputs=3 n_hidden=2 n_outputs=n_inputs learning_rate=0.01 X=tf.placeholder(tf.float32,shape=[None,n_inputs]) hidden=tf.layers.dense(X,n_hidden) outputs=tf.layers.dense(hidden,n_outputs) reconstruction_loss=tf.reduce_mean(tf.square(outputs-X)) optimizer=tf.train.AdamOptimizer(learning_rate) train_op=optimizer.minimize(reconstruction_loss) init=tf.global_variables_initializer() n_iterations=1000 codings=hidden with tf.Session() as sess: init.run() for iteration in range(n_iterations): train_op.run(feed_dict={X:X_train}) codings_val=codings.eval(feed_dict={X:X_test})与MLP相比,这段代码并没有多大的不同。需要注意的有两点: ·输出的数量等于输入的数量。·为了执行简单的PCA,我们设置activation_fn=None(即所有的神经元是线性的),并且成本函数是MSE。
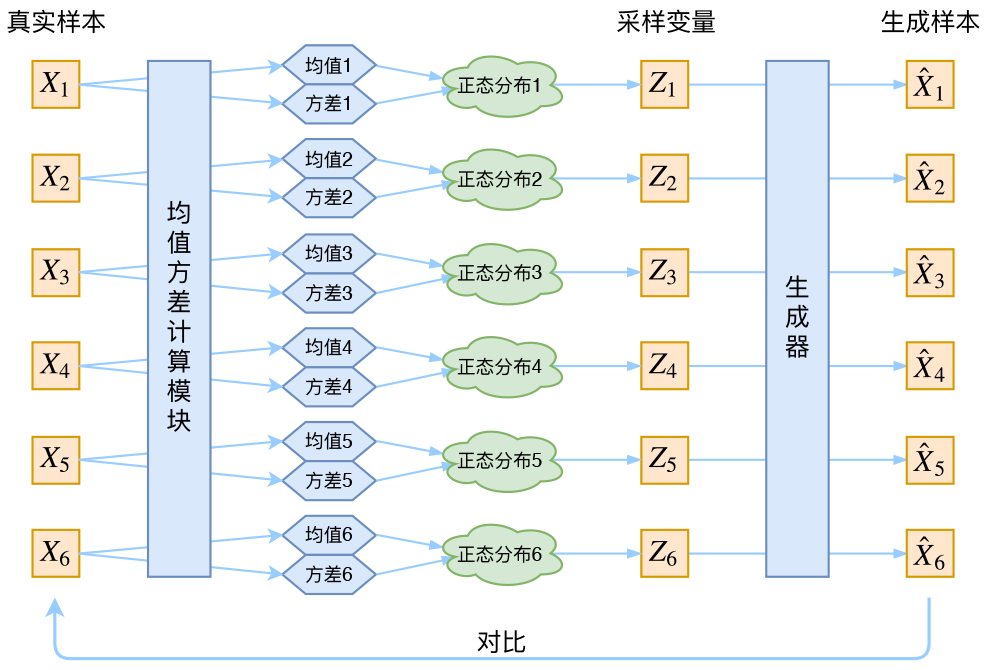
自动编码器可以有多个隐藏层。在这种情况下,它被称为栈式自动编码器(或者深度自动编码器)。增加更多的层帮助自动编码器学习更加复杂的编码。然而,不要让自动编码器变得太强大。想象一下,编码器强大到只是学习将每个输入映射到任意单个数字上。将完美地重建训练数据,但是在这个过程中没有任何有效的数据表示(并且不可能推广到新的实例)。 栈式自动编码器的结构通常对称于中央隐藏层(编码层)。例如一个MNIST的自动编码器可能有784个输入,随后是一个有300个神经元的隐藏层,然后是一个有150个神经元的中央隐藏层,然后是一个有300个神经元的隐藏层,最后是一个有784个神经元的输出层。这个栈式自动编码器如图所示: 可以像实现一个常规的深度MLP一样实现一个栈式自动编码器。特别是,可以使用我们在第11章训练深度网络的技术实现。例如,以下代码使用He初始化,ELU激活函数,以及正则化构建了一个MNIST栈式自动编码器。除了没有标签外(没有y),代码基本相似。源码到文末GitHub链接查找。 权重绑定当自动编码器和我们刚刚构建的那样严格对称时,一种常见的术是将解码层的权重和编码层的权重联系起来。这种方式将模型的权重减半,提高训练速度,限制了过度配置的风险。 weights1 = tf.Variable(weights1_init, dtype=tf.float32, name="weights1") weights2 = tf.Variable(weights2_init, dtype=tf.float32, name="weights2") weights3 = tf.transpose(weights2, name="weights3") # tied weights weights4 = tf.transpose(weights1, name="weights4") # tied weights需要注意: ·第一,weights3和weights4不是变量,它们分别是weights2和weights1的转置(它们被“绑定”在一起)。 ·第二,因为它们不是变量,所以没有必要进行正则化:只正则化weights1和weights2。 ·第三,偏置项从来不会被绑定,也不会被正则化 3、去噪自动编码器另一种强制自动编码器学习有用特征的方法是在输入中增加噪音,训练它以恢复原始的无噪音输入。这种方法阻止了自动编码器简单地复制其输入到输出,最终必须找到数据中的模式。噪音可以是添加到输入中的纯高斯噪音,或者是随机打断输入的噪音,如dropout。下图显示了上面的两种方法: 在TensorFlow实现去噪自动编码器不是很难。从高斯噪音开始。除了为输入增加噪音和根据原始输入计算重建损坏之外,它和训练常规自动编码器很相似。 X = tf.placeholder(tf.float32, shape=[None, n_inputs]) X_noisy = X + tf.random_normal(tf.shape(X)) [...] hidden1 = activation(tf.matmul(X_noisy, weights1) + biases1) [...] reconstruction_loss = tf.reduce_mean(tf.square(outputs - X)) # MSE [...] 4、稀疏自动编码器另一种导致良好特征提取的约束是稀疏性:通过在成本函数中增加适当的条件,推动自动编码器减小编码层中活动神经元的数量。例如,使编码层只有平均5%的显著激活神经元。这迫使自动编码器使用少量激活神经元的组合来表示输入。结果编码层的每个神经元都最终代表一个有用特征(如果你每个月只能说几个单词,那么你可能会尝试让它们变得有意义)。 一旦我们对每个神经元进行平均激活,我们希望通过向损失函数添加稀疏损失来惩罚太活跃的神经元。 例如,如果我们测量一个神经元的平均激活值为 0.3,但目标稀疏度为 0.1,那么它必须受到惩罚,才能激活更少。 一种方法可以简单地将平方误差(0.3-0.1)^2添加到损失函数中,但实际上更好的方法是使用 K-L 散度,其具有比均方误差更强的梯度。 一旦计算了编码层每个神经元的稀疏度损失,我们只需要累加这些损失,然后将其结果加到成本函数中。为了控制稀疏度损伤和重建损失的相对重要性,我们可以通过一个稀疏度权重超参数来增加稀疏度损失。 如果这个权重过高,模型将非常接近目标稀疏度,但是可能不能正确地重建输入,使得模型无用。相反,如果它的值过低,模型将忽略大多数稀疏性目标,并且学习不到什么有用特征。 5、变分自编码器(VAE)最受欢迎的自编码器类型之一:变分自编码器。它们与我们迄今为止讨论的所有自编码器完全不同,特别是: 它们是概率自编码器,意味着即使在训练之后,它们的输出部分也是偶然确定的(相对于仅在训练过程中使用随机性的自编码器的去噪)。最重要的是,它们是生成自编码器,这意味着它们可以生成看起来像从训练集中采样的新实例。这两个属性使它们与 RBM 非常相似,但它们更容易训练,并且取样过程更快。 我们来看看它们是如何工作的。图左展示了一个变分自动编码器。一个编码器后是一个解码器(在这个例子中,它们都有两个隐藏层)。 但是有一点不同:不是直接为给定的输入生成编码 ,而是编码器产生平均编码μ和标准差σ。然后从平均值μ和标准差σ的高斯分布随机采样实际编码。之后,解码器正常解码采样的编码。 在此之后,自动编码器只需要正常地解码采样编码。图右半部分展示了一个通过此编码器的训练实例。首先,编码器产生了μ和σ,然后编码是随机采样(注意,它不是精确位于μ中),最后这些编码被解码,并最终输出训练实例。 从图中可以看出,尽管输入可能具有非常复杂的分布,但变分自动编码器往往会产出一个像是从简单的高斯分布中采样的编码:在训练期间,损失函数推动编码在编码空间内(也称潜在空间)逐步迁移到看起来像一个高斯点集成的大致(超)球面区域。一个重要的结果是,变分自动编码器在训练之后,可以很容易地生成一个新实例:只需从高斯分布中抽取一个随机编码,对它进行解码就可以了! 我们来看看成本函数。它由两部分组成。首先是常规的重建损耗,推动自动编码器重现其输入(可以使用交叉熵)。第二部分是潜在损耗,使用编码的目标分布(高斯分布)和实际分布之间的KL散度,使得自动编码器的编码看起来像是从简单的高斯分布中进行采样。数学计算比之前更加复杂,尤其是因为高斯噪音限制了传输到编码层的信息量(从而推动自动编码器学习更加有意 义的特征)。幸运的是,潜在损坏可以简化为如下代码: eps = 1e-10 # smoothing term to avoid computing log(0) which is NaN latent_loss = 0.5 * tf.reduce_sum( tf.square(hidden3_sigma) + tf.square(hidden3_mean) - 1 - tf.log(eps + tf.square(hidden3_sigma)))一个常见的变体是训练编码器输出γ= log(σ^2)而不是σ。 只要我们需要σ,我们就可以计算σ= exp(2/γ)。这使得编码器更容易捕获不同比例的σ,从而帮助提高收敛的速度。潜在损失最终将会比较简单 。 latent_loss = 0.5 * tf.reduce_sum( tf.exp(hidden3_gamma) + tf.square(hidden3_mean) - 1 - hidden3_gamma)网络为每一个样本Xk都配上了一个专属的正态分布,才方便后面的生成器做还原。这样有多少个X就有多少个正态分布了。我们知道正态分布有两组参数:均值μ和方差σ2,那我怎么找出专属于Xk的正态分布p(Z|Xk)的均值和方差呢?好像并没有什么直接的思路。那好吧,那我就用神经网络来拟合出来吧!这就是神经网络时代的哲学:难算的我们都用神经网络来拟合。 于是我们构建两个神经网络
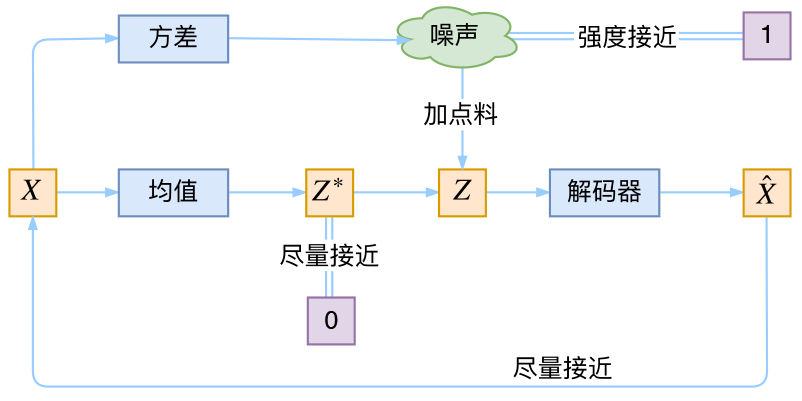
在VAE中,它的Encoder有两个,一个用来计算均值,一个用来计算方差,这已经让人意外了:Encoder不是用来Encode的,是用来算均值和方差的,这真是大新闻了,还有均值和方差不都是统计量吗,怎么是用神经网络来算的? 事实上,VAE从让普通人望而生畏的变分和贝叶斯理论出发,最后落地到一个具体的模型中,虽然走了比较长的一段路,但最终的模型其实是很接地气的:它本质上就是在我们常规的自编码器的基础上,对encoder的结果(在VAE中对应着计算均值的网络)加上了“高斯噪声”,使得结果decoder能够对噪声有鲁棒性;而那个额外的KL loss(目的是让均值为0,方差为1),事实上就是相当于对encoder的一个正则项,希望encoder出来的东西均有零均值。 那另外一个encoder(对应着计算方差的网络)的作用呢?它是用来动态调节噪声的强度的。直觉上来想,当decoder还没有训练好时(重构误差远大于KL loss),就会适当降低噪声(KL loss增加),使得拟合起来容易一些(重构误差开始下降);反之,如果decoder训练得还不错时(重构误差小于KL loss),这时候噪声就会增加(KL loss减少),使得拟合更加困难了(重构误差又开始增加),这时候decoder就要想办法提高它的生成能力了。
说白了,重构的过程是希望没噪声的,而KL loss则希望有高斯噪声的,两者是对立的。所以,VAE跟GAN一样,内部其实是包含了一个对抗的过程,只不过它们两者是混合起来,共同进化的。从这个角度看,VAE的思想似乎还高明一些,因为在GAN中,造假者在进化时,鉴别者是安然不动的,反之亦然。当然,这只是一个侧面,不能说明VAE就比GAN好。GAN真正高明的地方是:它连度量都直接训练出来了,而且这个度量往往比我们人工想的要好。 from:https://spaces.ac.cn/archives/5253 生成数字让我们用这个变分自动编码器生成一些看起来像手写数字的图片。我们需要做的是训练模型,然后从高斯分布中随机采样编码并对其进行解码。 1、训练模型 from functools import partial n_inputs = 28 * 28 n_hidden1 = 500 n_hidden2 = 500 n_hidden3 = 20 # codings n_hidden4 = n_hidden2 n_hidden5 = n_hidden1 n_outputs = n_inputs learning_rate = 0.001 initializer = tf.contrib.layers.variance_scaling_initializer() my_dense_layer = partial( tf.layers.dense, activation=tf.nn.elu, kernel_initializer=initializer) X = tf.placeholder(tf.float32, [None, n_inputs]) hidden1 = my_dense_layer(X, n_hidden1) hidden2 = my_dense_layer(hidden1, n_hidden2) hidden3_mean = my_dense_layer(hidden2, n_hidden3, activation=None) hidden3_sigma = my_dense_layer(hidden2, n_hidden3, activation=None) noise = tf.random_normal(tf.shape(hidden3_sigma), dtype=tf.float32) hidden3 = hidden3_mean + hidden3_sigma * noise hidden4 = my_dense_layer(hidden3, n_hidden4) hidden5 = my_dense_layer(hidden4, n_hidden5) logits = my_dense_layer(hidden5, n_outputs, activation=None) outputs = tf.sigmoid(logits) xentropy = tf.nn.sigmoid_cross_entropy_with_logits(labels=X, logits=logits) reconstruction_loss = tf.reduce_sum(xentropy) eps = 1e-10 # smoothing term to avoid computing log(0) which is NaN latent_loss = 0.5 * tf.reduce_sum( tf.square(hidden3_sigma) + tf.square(hidden3_mean) - 1 - tf.log(eps + tf.square(hidden3_sigma))) loss = reconstruction_loss + latent_loss optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate) training_op = optimizer.minimize(loss) init = tf.global_variables_initializer() saver = tf.train.Saver() n_epochs = 2 # 用50 batch_size = 150 with tf.Session() as sess: init.run() for epoch in range(n_epochs): n_batches = mnist.train.num_examples // batch_size for iteration in range(n_batches): print("\r{}%".format(100 * iteration // n_batches), end="") sys.stdout.flush() X_batch, y_batch = mnist.train.next_batch(batch_size) sess.run(training_op, feed_dict={X: X_batch}) loss_val, reconstruction_loss_val, latent_loss_val = sess.run([loss, reconstruction_loss, latent_loss], feed_dict={X: X_batch}) print("\r{}".format(epoch), "Train total loss:", loss_val, "\tReconstruction loss:", reconstruction_loss_val, "\tLatent loss:", latent_loss_val) saver.save(sess, "./my_model_variational.ckpt")
2、加载模型: import numpy as np n_digits = 60 with tf.Session() as sess: saver.restore(sess,"./my_model_variational.ckpt") #加载模型 codings_rnd = np.random.normal(size=[n_digits, n_hidden3]) outputs_val = outputs.eval(feed_dict={hidden3: codings_rnd}) n_rows = 6 n_cols = 10 plot_multiple_images(outputs_val.reshape(-1, 28, 28), n_rows, n_cols) save_fig("generated_digits_plot") plt.show()
源码地址:https://github.com/liuzheCSDN/Scikit-Learn https://github.com/apachecn/hands-on-ml-zh/blob/master/docs/15.%E8%87%AA%E7%BC%96%E7%A0%81%E5%99%A8.md |







【本文地址】