| 【Python】学习笔记 #1 | 您所在的位置:网站首页 › 如何用python爬取网站图片 › 【Python】学习笔记 #1 |
【Python】学习笔记 #1
|
目录
Step 1:下载requests包 Step 2:导包 Step 3:requests使用 Step 4:Re的使用 Step 5:os的使用 Step 6:保存文件 Step 7:综合案例 Step 1:下载requests包常见的方式是在windows系统上win+R调出运行,输入cmd进入控制台。 输入指令pip list可以看见目前已经安装的包
下载requests包指令为:pip install requests 由于下载包默认引用的地址是国外的网站,因此可能出现界面卡住,进度条过慢的情况, 一般我们手动通过引用国内镜像源,例如: 1、清华 https://mirrors.tuna.tsinghua.edu.cn/ 2、中科大USTC镜像源 https://mirrors.ustc.edu.cn/ 3、163 http://mirrors.163.com/ 4、阿里 https://opsx.alibaba.com/mirror 引用清华镜像源后的下载指令为:pip install requests -i https://mirrors.tuna.tsinghua.edu.cn/ Tips:不排除有新手程序员安装了多个版本的python,导致pycharm里查看下载的包的时候与控制台不一致的问题。 解决方式是,在需要的工程中,点开下方的Terminal,在出现的控制台中输入指令下载也是可以的。 另:注意联网
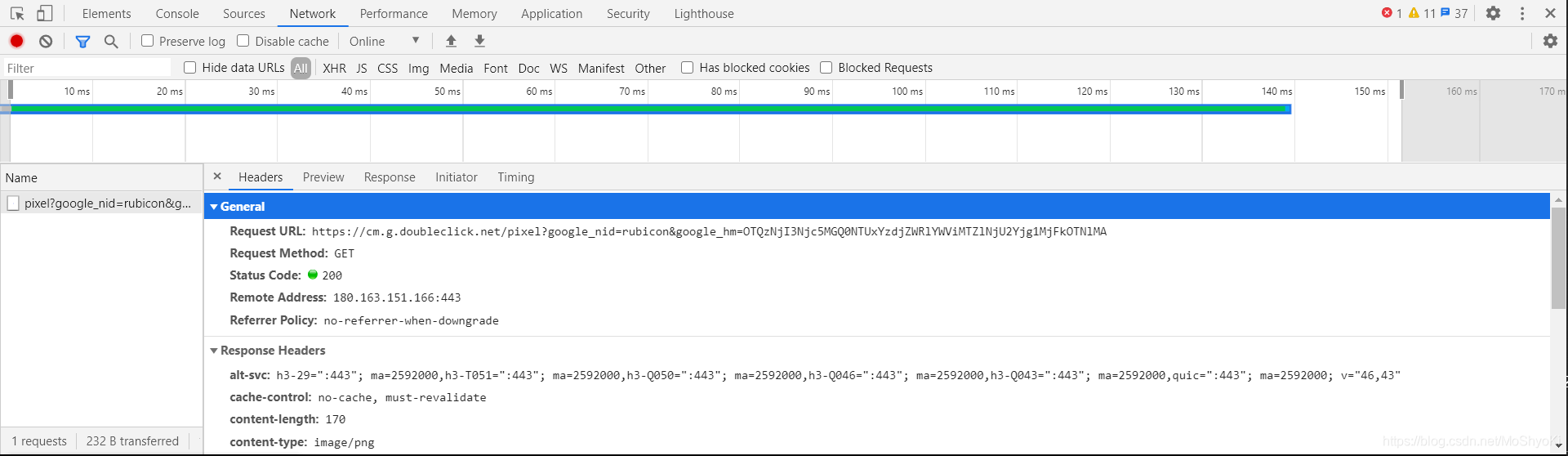
本次我的学习案例中,共需导入3个包: import requests # 实用的Python HTTP客户端库 import os # 包含负责新建文件、改文件名、路径、操作电脑系统相关的功能集合的包 import re # 包含使用正则表达式的包 Step 3:requests使用requests的请求方式有两种:get与post 面对不同的网站,使用get还是post需要灵活变对。 以站长素材(https://sc.chinaz.com/),谷歌浏览器为例: 鼠标右击,点击最下面的检查,弹出检查框,选择Network,点击第一个文件,再选择headers,出现如下信息: 其中,General下对应的Request Method对应的值为GET, 由此可见,我们本次使用的requests方法应为对应的get方法。 import requests url = "https://sc.chinaz.com/" response = requests.get(url)利用requests.get(url)的方式去获取页面信息,并用变量response接收 。 打印下response的信息: print(response)如果正确,会得到: 进程已结束,退出代码 0其中,200表示状态码 常见的状态码: 200 - 请求成功301 - 资源(网页等)被永久转移到其它URL404 - 请求的资源(网页等)不存在500 - 内部服务器错误我要获取的是页面信息,那我应该输出什么呢? 有两种方式: print(response.content) print(response.text)response.content是直接从网页上抓取的数据,没有任何解码 response.text是对response.content进行解码的字符串,但是可能会出现乱码的情况,此时我们可以通过设置字符编码的方式纠正: response.encoding = response.apparent_encodingresponse.encoding设置获取的响应数据的字符编码, response.apparent_encoding自动获取响应数据的字符编码。 经过以上操作,我们便能获取基本正确的网页数据。 如果我们尝试爬取(www.baidu.com)的网页源代码,会发现输出的源代码与我右击—查看网页源代码的内容大相径庭,这是什么原因呢? 答:反爬机制 网络通信毕竟是交换信息的一个过程,我要从网站获取信息,必定是先传出信息给到网站, 若是有反爬机制的网站,审查你的信息后,就能判断是人为浏览,还是爬取数据。 而一般审查的,就是User—Agent信息:
因此我们直接复制上图User—Agent信息,用字典的数据形式设置headers: headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36" } url = "https://www.baidu.com/" response = requests.get(url, headers=headers) response.encoding = response.apparent_encoding print(response.text) Step 4:Re的使用最简单的re模块使用: import re pattern = '' re_result = re.findall(pattern, response.text)用一个变量保存正则表达式字符串 使用findall函数筛选数据:re.findall(正则表达式,文本) 再用一个变量保存筛选的信息 常见元字符: . 表示一个任意字符 {} 表示前一个字符出现多少次 [] 包含[]内的字符 [0-9a-zA-Z] 表示包含所有数字与所有英文字母 * 表示前一个字符出现0次或多次 + 表示前一个字符出现1次或多次 ? 表示前一个字符出现0次或1次 在* + ?后使用?表示匹配到最近的立即停止匹配 Step 5:os的使用本案例中,我们只需使用os模块中的两个函数: import os os.mkdir("站长素材-唯美意境") os.chdir("站长素材-唯美意境")os.mkdir表示创建文件夹 os.chdir表示进入文件夹 os.chdir("..")亦可表示返回上一级文件夹 Step 6:保存文件 f = open(fileName, "wb") f.write(content) f.close()open打开文件,若文件不存在则在当前目录创建文件,需包含后缀名,参数(文件名,打开方式) 打开方式包含 只读r , 覆盖w ,追加a b含义为以二进制形式写入文件。 Step 7:综合案例目的:1.爬取站长素材中唯美意境图片 2.用户自行输入要保存几页图片 3.创建对应文件夹并保存图片,要求有各自的图片名称
分析:1.爬取需要requests,re包,创建文件夹需要os包 2.爬取唯美意境图片网页中所有高清大图对应的网址 3.进入高清大图网址爬取图片地址与图片名称并下载保存 4.展示动态化保存过程 代码展示: import re import os import requests # 创建保存图片文件夹 os.mkdir("站长素材-唯美意境") os.chdir("站长素材-唯美意境") # 统计任务总量 pic_count = 1 page_count = 1 # 手动输入爬取图片页数 page_num = int(input("请输入下载的页数:")) for page in range(page_num): # 创建二级保存图片文件夹 os.mkdir("page%s" % (page + 1)) os.chdir("page%s" % (page + 1)) # 分页数改变网页URL if page == 0: html_url = "https://sc.chinaz.com/tupian/weimeiyijingtupian.html" else: html_url = "https://sc.chinaz.com/tupian/weimeiyijingtupian_%s.html" % (page + 1) # 获取网页相应数据 response = requests.get(html_url) response.encoding = response.apparent_encoding # 正则表达式筛选图片下级地址 pattern = '' re_result = re.findall(pattern, response.text) # 循环依次进入图片下级地址 for url in re_result: # 拼接得到新的图片下级地址 url = "http:" + url # 获取下级网页相应数据 response = requests.get(url) response.encoding = response.apparent_encoding # 正则表达式筛选图片高清地址与标题 pattern = '' pic_re_result = re.findall(pattern, response.text) img_url = "http:" + pic_re_result[0][0] img_title = pic_re_result[0][1] print(img_url, img_title, "共%s/%s张 %s/%s页" % (pic_count, len(re_result), page_count, page_num)) # 保存图片 response = requests.get(img_url) f = open(img_title + ".jpg", "wb") f.write(response.content) f.close() # 计数统计 pic_count += 1 # 重置图片计数统计,增加页数统计 pic_count = 1 page_count += 1 # 返回上级目录,进入新的目录 os.chdir("..") print("任务完成!")结果展示:
|




【本文地址】