|
哈喽兄弟们,今天给大家带来最新版如何实现 百度文库VIP内容获取
💥需求如下:
对于这类的文档, 我们想要点击下载, 都是需要 “氪金” 才行, 但是作为咱们这类人来说, 能白嫖就白嫖!

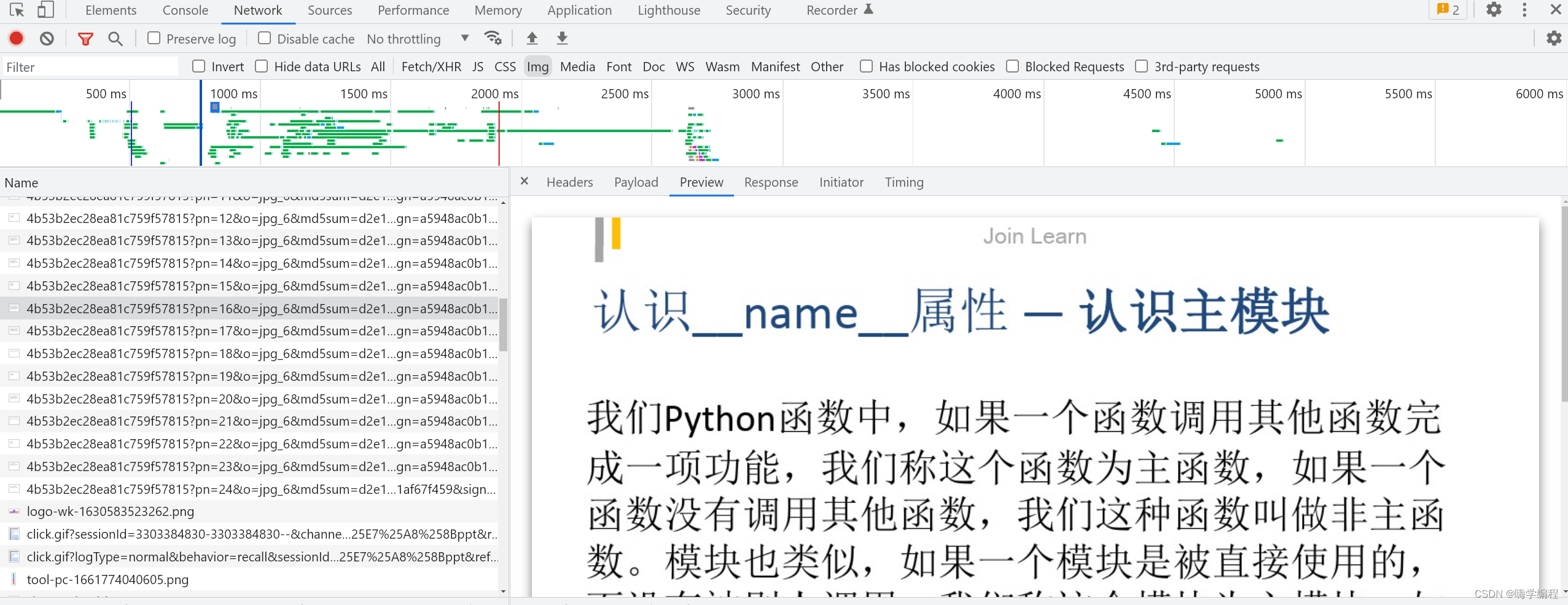
💥找数据源:
通过开发者工具抓包, 可以看到数据都是图片的形式存在, 那我们可以获取它所有的数据内容, 然后保存下载下来, 以PPT的形式保存
💥代码如下:
# 导入数据请求模块
import requests
# 导入ppt模块
from pptx import Presentation
# 导入ppt模块 设置边距
from pptx.util import Cm
# 导入文件操作模块
import os
# 给大家准备了数百本Python电子书、各种源码、实战视频教程、基础视频讲解
# 直接在这个抠裙 708525271 自取
# 请求链接
url = 'https://wenku.baidu.com/ndocview/readerinfo'
# 请求参数
data = {
'docId': '5330607f541810a6f524ccbff121dd36a32dc482',
'clientType': '1',
'powerId': '2',
'pn': '1',
'rn': '100',
'bizName': 'mainPc',
'edtDocSrc': '0',
'bdQuery': '百度文库',
'wkQuery': 'python编程ppt',
}
# 伪装
headers = {
# 用户代理
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36',
}
# 发送请求
response = requests.get(url=url, params=data, headers=headers)
# 循环次数
page = 1
# for 循环遍历
for index in response.json()['data']['htmlUrls']:
# 获取图片数据
img_content = requests.get(url=index, headers=headers).content
# 保存数据
with open('img\\' + str(page) + '.jpg', mode='wb') as f:
# 写入数据
f.write(img_content)
print(index)
# 每次循环+1
page += 1
# 实例化对象
prs = Presentation()
# 使用第7个模块
blank_slide_layout = prs.slide_layouts[6]
# 读取文件
files = os.listdir('img\\')
# 遍历文件名
for file in files:
# 文件路径
filename = f'img\\{file}'
# 添加图片
# slide.shapes.add_picture(图片路径, 距离左边,距离顶端, 宽度,高度)
slide = prs.slides.add_slide(blank_slide_layout)
slide.shapes.add_picture(filename, Cm(0), Cm(0), Cm(25.40), Cm(19.06))
# 保存ppt
prs.save('python编程.pptx')
💥采集效果:

💥总结:
今天的分享就到这结束了,下期大家想看什么,可以在评论区留下你想看的内容名字,随机抽取幸运观众 ,有什么不明白的地方也可以留言。
|