| python之Selenium+pyquery爬取有大量反爬虫的天眼查 | 您所在的位置:网站首页 › 天眼查使用教程 › python之Selenium+pyquery爬取有大量反爬虫的天眼查 |
python之Selenium+pyquery爬取有大量反爬虫的天眼查
|
天眼查:一个还有大量公司的信息的网站。 所以反爬程度是相当高的,首先直接用requests.get(url)来获取页面源代码,你会发现,明明显示在页面上的公司的一些数据都不在,他是利用其它的js的方法表达出来的,因为这个网站有专门的反爬虫人员,可以在一些招聘网上看到工资还可以15k-30k 所以说用这些方法根本就不爬到什么 那么只有使出我们的杀手锏,selenium,他的好处在于可以模拟浏览器操作,非常方便获取属性也很方便。 首先这个网站不登录的话,你会发现,怎么源代码上面的是和页面表示出来的不一样啊,明明是****公司**,在源代码上却是 @#¥····,连公司的基本信息,比如邮箱什么的,都是*****[email protected]什么的,不能看到全部的信息,这是因为不登录的话,天眼查对于大部分的公司的信息,进行了一些保护,登录了才可以页面的源代码才会正确。 所以首先我们注册注册一个天眼查的账号: 接下来我们知道selenium驱动的浏览器是一个非常纯净的,没有任何cookies,及一些信息的保存,目前来说是这样,所以每一次访问这个网站,都是全新的,没有任何的登录信息在上面,所以我们怎么实现selenium模拟登录呢,这就要用到phantomjs,因为这个网站上面的登录注册时用js代码生成的,源代码上是没有这些东西的,如果我们用phantomjs的话,可以直接解析出来所有js包含的html代码。 下面一步一步来解析代码: 这是拼接完整的代码,keyword就是关键字,等会在main函数里自行输入,在search函数里加入phantomjs解析,这个要先安装好phantomjs。 browser = webdriver.Chrome() browser.maximize_window()#将浏览器最大化 wait = WebDriverWait(browser,10) def search(keyword): url_keyword = urllib.parse.quote(keyword) # 中文转码为url格式 url = 'http://www.tianyancha.com/search/' + url_keyword + '?checkFrom=searchBox' driver = webdriver.PhantomJS( executable_path='D:\\Program Files\\phantomjs-2.1.1-windows\\bin\\phantomjs') # phantomjs的绝对路径 time.sleep(2) driver.get(url) browser.get(url) return url def main(): keyword = '阿里巴巴' url = search(keyword) if __name__ == '__main__': main()当我们运行代码后发现:怎么回事啊,为什么和我不加phantomjs代码不一样啊,现在直接出现一个登陆的界面,需要登陆之后才能进入,这就是为什么要注册一个账号的原因之一: 我们可以看到每个公司的class为search-result-single, 现在到了最关键的一步,就是翻页,因为有很多页,目前不是vip只有5页可以查找 下面是selenuim关于翻页的操作:这里面有很多坑,当时也折腾我了好久, 下面我来一一分析,当他在第一页的时候,下面有个企业认证的广告,刚好把翻页的按钮挡住了,当时这个bug我调了好久才找到,我们就用刚刚介绍的元素选择器把它关掉就行了,把它关掉才可以点击下一页那个按钮, 第二个坑出现了,居然第一页的下一步的按钮和第二页第三页的selector不一样,这里也调了很久,代码里可以看到我写了判断,最后再**执行get_company_info()**获取信息就行了。main里面的那个循环就是用来翻页的,从1到5页。 move_to_bottom是用来翻到网页最下面的。 def move_to_bottom(): js = "var q=document.documentElement.scrollTop=100000" browser.execute_script(js) def next_page(page_number): print('------------------------------------正在爬取',page_number,'页-----------------------------------------------------------------') try: if page_number == 2: closeAdvertisement = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#tyc_banner_close'))) closeAdvertisement.click() move_to_bottom() if page_number == 2: nextPageButton = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#web-content > div > div.container-left > div.search-block > div.result-footer > div:nth-child(1) > ul > li:nth-child(12) > a'))) nextPageButton.click() if page_number > 2: nextPageButton = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#web-content > div > div.container-left > div.search-block > div.result-footer > div:nth-child(1) > ul > li:nth-child(13) > a'))) nextPageButton.click() get_company_info() time.sleep(3) except TimeoutException: next_page(page_number) def main(): keyword = '阿里巴巴' url = search(keyword) login() for page in range(2,6): next_page(page) browser.close()最后存储到mongodb: 在get_company_info()方法里调用就行了。 import pymongo mongoclient = pymongo.MongoClient("localhost",port=27017,connect = False) db = mongoclient .AugEleventh classname = db.alibaba def save_to_mongo(result): if classname.insert(result): print('存储到mongoDB成功',result) else: print('存储到mongoDb失败')这里告诉大家基本以及爬完了,你想爬什么公司的在keyword中输入就可以了,但是不是vip只有最多5页的内容。这个不用vip获取更多公司信息就说了,毕竟人家要靠这个赚钱,就放过他吧(其实是我完全不知道!!) 下面贴出完整代码: from selenium import webdriver import urllib from pyquery import PyQuery as pq import json from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.by import By from selenium.common.exceptions import TimeoutException import time import pymongo mongoclient = pymongo.MongoClient("localhost",port=27017,connect = False) db = mongoclient .AugEleventh classname = db.alibaba browser = webdriver.Chrome() browser.maximize_window()#将浏览器最大化 wait = WebDriverWait(browser,10) def move_to_bottom(): js = "var q=document.documentElement.scrollTop=100000" browser.execute_script(js) def search(keyword): url_keyword = urllib.parse.quote(keyword) # 中文转码为url格式 url = 'http://www.tianyancha.com/search/' + url_keyword + '?checkFrom=searchBox' driver = webdriver.PhantomJS( executable_path='D:\\Program Files\\phantomjs-2.1.1-windows\\bin\\phantomjs') # phantomjs的绝对路径 time.sleep(2) driver.get(url) browser.get(url) return url def get_total_page(url): total = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#web-content > div > div.container-left > div.search-block > div.result-footer > div:nth-child(1) > ul > li:nth-child(11) > a'))) get_company_info() return total.text def login(): try: userInput = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#web-content > div > div > div > div.position-rel.container.company_container > div > div.in-block.vertical-top.float-right.right_content.mt50.mr5.mb5 > div.module.module1.module2.loginmodule.collapse.in > div.modulein.modulein1.mobile_box.pl30.pr30.f14.collapse.in > div.pb30.position-rel > input'))) passwordInput = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#web-content > div > div > div > div.position-rel.container.company_container > div > div.in-block.vertical-top.float-right.right_content.mt50.mr5.mb5 > div.module.module1.module2.loginmodule.collapse.in > div.modulein.modulein1.mobile_box.pl30.pr30.f14.collapse.in > div.pb40.position-rel > input'))) userInput.send_keys('15995028879') passwordInput.send_keys('19981027lcy') changeLoginWay = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#web-content > div > div > div > div.position-rel.container.company_container > div > div.in-block.vertical-top.float-right.right_content.mt50.mr5.mb5 > div.module.module1.module2.loginmodule.collapse.in > div.modulein.modulein1.mobile_box.pl30.pr30.f14.collapse.in > div.c-white.b-c9.pt8.f18.text-center.login_btn'))) changeLoginWay.click() except TimeoutException: login() def get_company_info(): wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.search-block .result-list .search-result-single'))) html = browser.page_source doc = pq(html) items = doc('.search-block .result-list .search-result-single').items() for item in items: company = { 'urlInfo':item.find('.name ').attr('href'), 'name' : item.find('.name').text(), 'LegalRepresentative':item.find('.info .title a').text(), 'registerMoney':item.find('.info .title span').eq(0).text(), 'registerTime':item.find('.info .title span').eq(1).text(), 'tel':item.find('.contact .link-hover-click').eq(0).text(), 'email':item.find('.contact .link-hover-click').eq(1).text(), 'LegalPersonInfo':item.find('.content .match span').eq(1).text() } save_to_mongo(company) def next_page(page_number): print('------------------------------------正在爬取',page_number,'页-----------------------------------------------------------------') try: if page_number == 2: closeAdvertisement = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#tyc_banner_close'))) closeAdvertisement.click() move_to_bottom() if page_number == 2: nextPageButton = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#web-content > div > div.container-left > div.search-block > div.result-footer > div:nth-child(1) > ul > li:nth-child(12) > a'))) nextPageButton.click() if page_number > 2: nextPageButton = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#web-content > div > div.container-left > div.search-block > div.result-footer > div:nth-child(1) > ul > li:nth-child(13) > a'))) nextPageButton.click() get_company_info() time.sleep(3) except TimeoutException: next_page(page_number) def save_to_mongo(result): if classname.insert(result): print('存储到mongoDB成功',result) else: print('存储到mongoDb失败') def main(): keyword = '阿里巴巴' url = search(keyword) login() total_pages = int(get_total_page(url)[-3:])#获取下他的总页数,但是没用,因为不是vip只能爬5页,本来我不是想吧下面那个6换成total_pages 的 for page in range(2,6): next_page(page) browser.close() if __name__ == '__main__': main()目前的我的模拟登录不是最好的,还有种是直接利用登录后的cookies信息,用selenuim登录后直接就是已经登陆的状态,目前我还不怎么清楚怎么做,希望有大神在评论区说说。 |
 现在我们就需要利用selenuim模拟登录了,首先要做到的就是获取输入框,在刚刚这个界面按F12审查元素,再点击选择元素的小箭头,之后点击输入手机号码那里,就可以在下面看到输入框在源代码中的位置,找到那个位置,右键,copy,selector,就可以得到他的这个元素的选择器,因为我们用的是selenuim中一个查找元素为位置的元素,具体看我的代码,之后用send_keys()输入你的账户密码,然后同样的找到登录的那个位置的css_selector,再点击就进入了。
现在我们就需要利用selenuim模拟登录了,首先要做到的就是获取输入框,在刚刚这个界面按F12审查元素,再点击选择元素的小箭头,之后点击输入手机号码那里,就可以在下面看到输入框在源代码中的位置,找到那个位置,右键,copy,selector,就可以得到他的这个元素的选择器,因为我们用的是selenuim中一个查找元素为位置的元素,具体看我的代码,之后用send_keys()输入你的账户密码,然后同样的找到登录的那个位置的css_selector,再点击就进入了。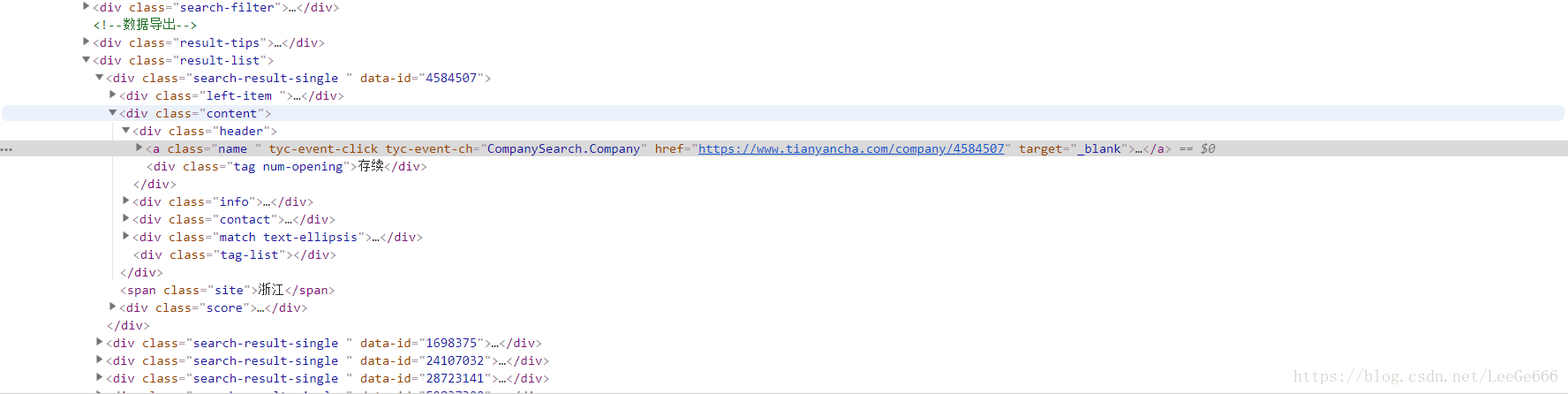 直接看代码: 这里就要用到pyquery了,用它来解析公司的每一个信息:具体pyquery使用方法就不详谈了,具体可以看我上一篇文章。
直接看代码: 这里就要用到pyquery了,用它来解析公司的每一个信息:具体pyquery使用方法就不详谈了,具体可以看我上一篇文章。【本文地址】