| Python高级应用课程设计作业 | 您所在的位置:网站首页 › 大数据作业设计 › Python高级应用课程设计作业 |
Python高级应用课程设计作业
|
1 #删除与本次数据分析无关的列
2 df.drop('hash',axis=1,inplace=True)#删除记录的字段和值的哈希值列,对本次实验无用数据
3 df.drop('last_refresh',axis=1,inplace=True)#删除上次更新记录的日期列,对本次实验无用数据
4 df.drop('id',axis=1,inplace=True)#删除ID列,对本次实验无用数据
5
6 #空值处理
7 df['disaster_number'].isnull().value_counts()#判断关键字段是否存在空值
8 df['incident_type'].isnull().value_counts()#判断关键字段是否存在空值
9 df['state'].isnull().value_counts()#判断关键字段是否存在空值
10 df['ih_program_declared'].isnull().value_counts()#判断关键字段是否存在空值
11 df['fy_declared'].isnull().value_counts()#判断关键字段是否存在空值
12 df['disaster_closeout_date'].isnull().value_counts()#判断关键字段是否存在空值
13 df['declaration_request_number'].isnull().value_counts()#判断关键字段是否存在空值
14 df['fips'].isnull().value_counts()#判断关键字段是否存在空值
15 df['incident_begin_date'].isnull().value_counts()#判断关键字段是否存在空值
16
17 #删除重复数据
18 df = df.drop_duplicates()
19
20 #空格处理
21 df['fema_declaration_string']=df['fema_declaration_string'].map(str.strip)
22 df['state']=df['state'].map(str.strip)
23 df['declaration_type']=df['declaration_type'].map(str.strip)
24 df['declaration_date']=df['declaration_date'].map(str.strip)
25 df['incident_type']=df['incident_type'].map(str.strip)
26 df['declaration_title']=df['declaration_title'].map(str.strip)
27 df['designated_area']=df['designated_area'].map(str.strip)
28 df['incident_begin_date']=df['incident_begin_date'].map(str.strip)
29
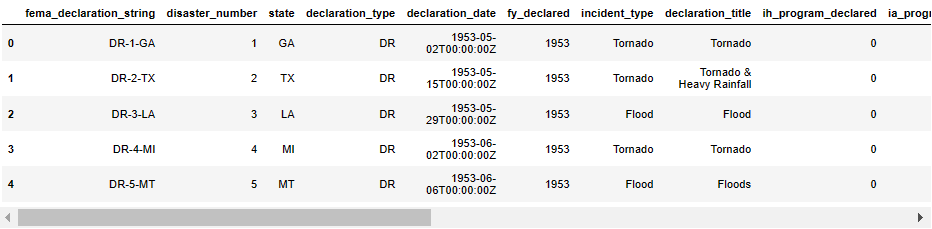
30 df.head()
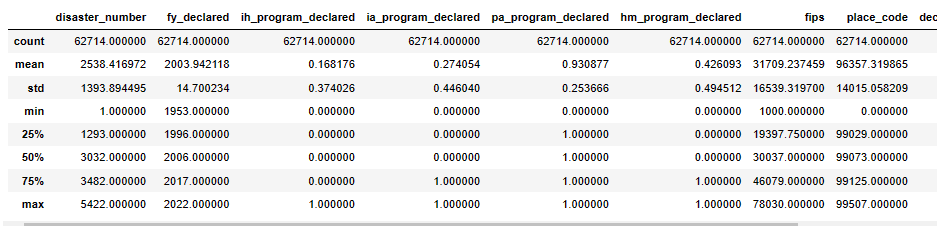
2.进一步数据清理:通过describe()函数查询异常值 1 #异常值处理 2 df.describe()
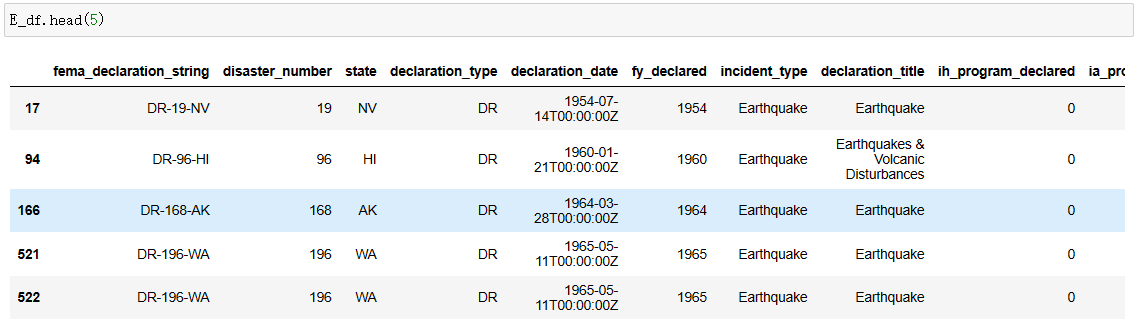
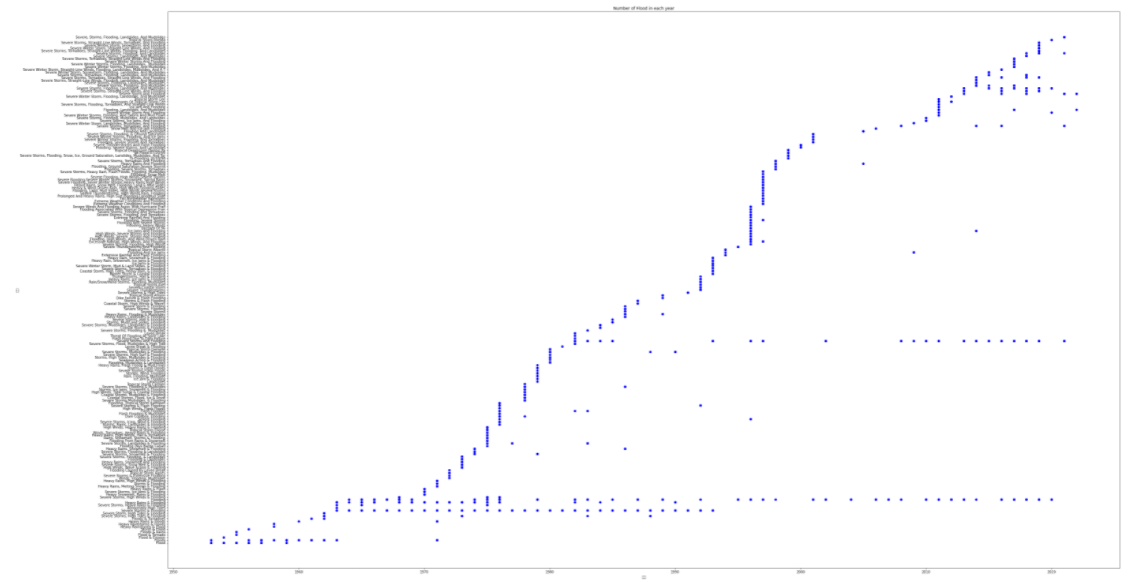
未发现异常值 三、数据可视化 1.用不同图形绘制不同灾害发生频率图 1 #提取数据 2 E_df = df[df['incident_type'] == 'Earthquake']#提取出灾难类型为地震的数据 3 T_df = df[df['incident_type'] == 'Tornado']#提取出灾难类型为龙卷风的数据 4 F_df = df[df['incident_type'] == 'Flood']#提取出灾难类型为洪水的数据
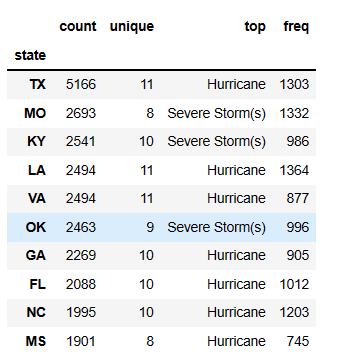
由图我们可以看出,洪水的发生频次远大于地震与龙卷风,并且随着年份的增加发生次数也有相应的增长。 1 #调取各州所对应的自然灾害数据 2 m=df[['state','incident_type']].groupby('state').describe() 3 m['incident_type'].sort_values(by='count',ascending=False).head(10)
1 #事件数量 2 fig,axes=plt.subplots(2,2) 3 sns.distplot(df['incident_type'].value_counts(),ax=axes[0][0]) 4 sns.distplot(df['incident_type'].value_counts(),kde=False,ax=axes[0][1]) 5 sns.distplot(df['incident_type'].value_counts(),rug=True,ax=axes[1][0]) 6 sns.distplot(df['incident_type'].value_counts(),vertical=True,ax=axes[1][1])
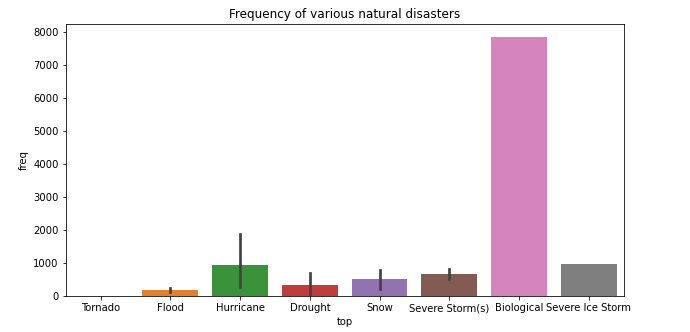
1 #各种自然灾害发生的频率 2 m=df[['fy_declared','incident_type']].groupby('fy_declared').describe()['incident_type'].reset_index() 3 plt.figure(figsize=(10,5)) 4 plt.title('Frequency of various natural disasters') 5 sns.barplot(x='top',y='freq',data =m)
由图我们可以直观的看出不同灾害的发生频率,由于数据集中加入了生物灾害,2020新冠爆发,所以生物灾害发生频率远大于其他灾害。
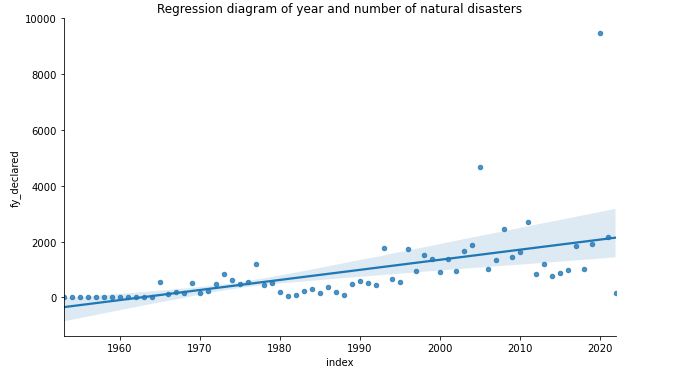
2.画出年份与灾害发生次数的回归图 1 #年份与自然灾害发生次数的回归图 2 m=df['fy_declared'].value_counts().reset_index() 3 sns.lmplot(x='index',y='fy_declared',data=m.sort_values(by='fy_declared'), 4 aspect=1.7, height=5,markers=['o'], scatter_kws={'s':20}); 5 plt.title('Regression diagram of year and number of natural disasters')
由此回归图可以看出,从1960年到2020年美国每年发生灾害的次数呈线性增加
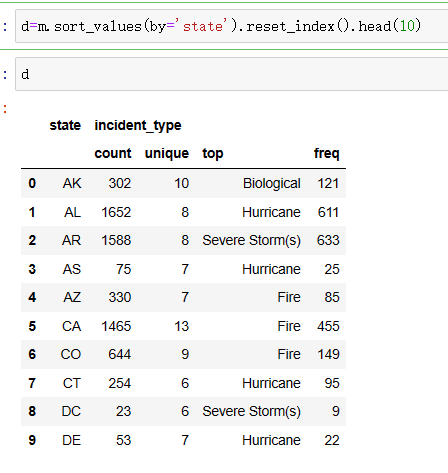
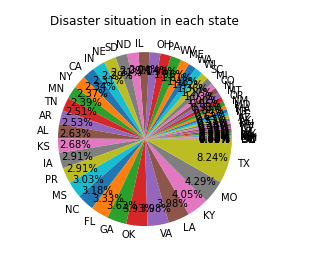
3.接下来制作各个州受灾所占比例的饼图和柱状图 1.饼图 1 #调取州所对应的数据 2 d=m.sort_values(by='state').reset_index().head(10)
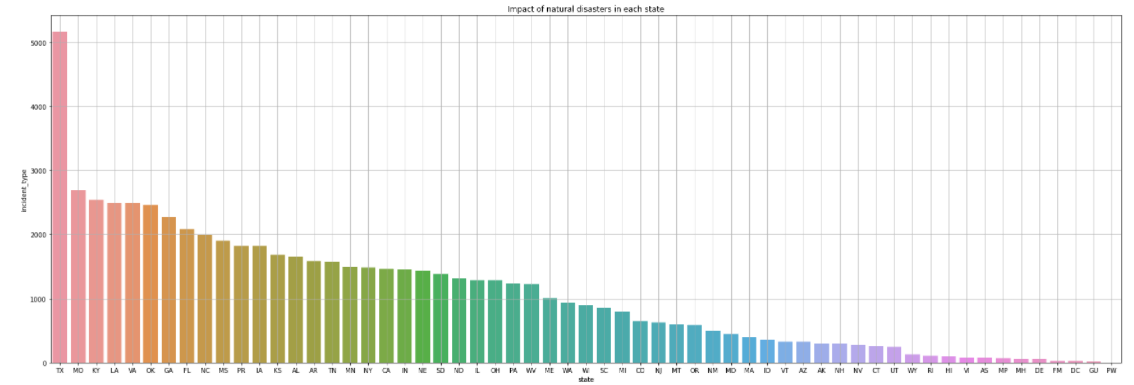
2.柱状图 1 #调取州所对应的事件类型 2 S = df[['state','incident_type']].groupby('state').count().head(10)
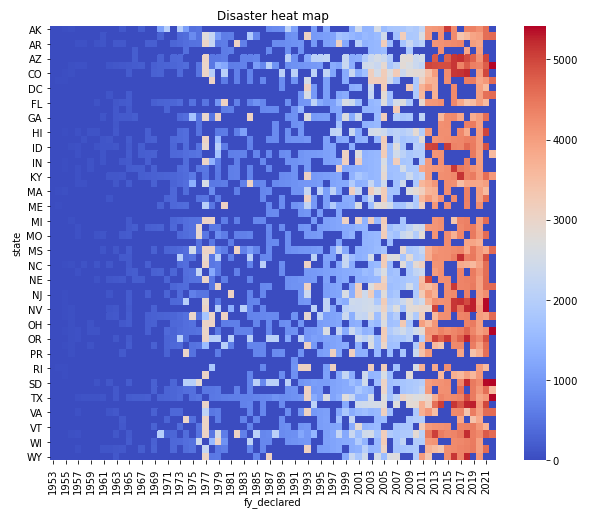
3.热力图 1 #热力图来展现各州在不同年份受自然灾害的影响情况 2 pt = df.pivot_table(values ='disaster_number', index = 'state', columns = 'fy_declared').fillna(0) 3 plt.figure(figsize=(10,8)) 4 sns.heatmap(pt, cmap='coolwarm'); 5 plt.savefig('heatmap.png') 6 plt.title('Disaster heat map')
结合图像可以直观的看出:TX(德克萨斯州)是美国受自然灾害影响最大的州,PW是受自然灾害影响最小的,GA(佐治亚州)的受灾情况接近平均值。
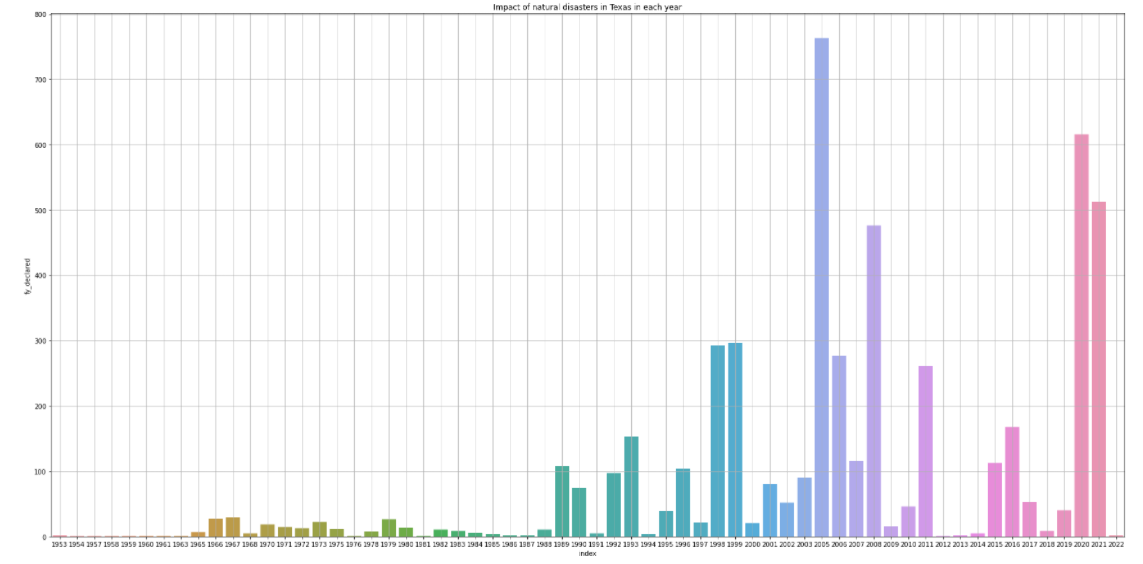
4.下面我们就德克萨斯州和佐治亚州进行具体的分析 画出德克萨斯州各个年份受自然灾害影响情况 1 #德克萨斯州 2 m=df.query('state=="TX"')['fy_declared'].value_counts().reset_index() 3 plt.figure(figsize=(30,15)) 4 sns.barplot(x='index',y='fy_declared',data=m.sort_values(by='fy_declared')); 5 plt.title('Impact of natural disasters in Texas in each year') 6 plt.grid()
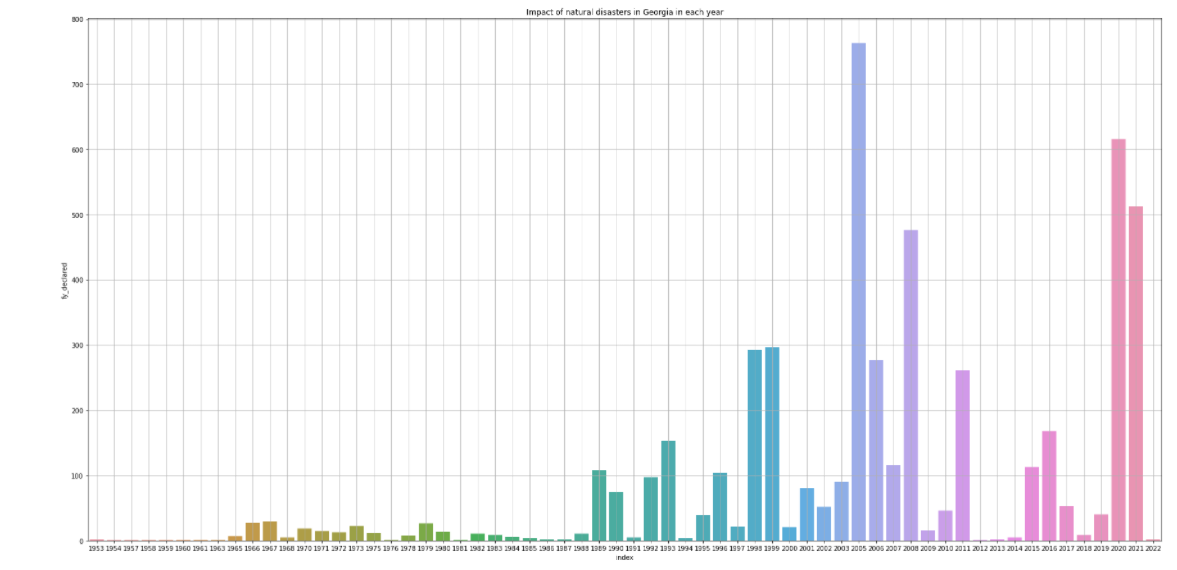
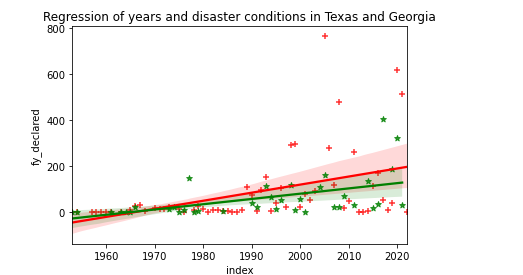
从柱状图中可以看出德克萨斯州在2005年时受自然灾害影响最大,每年自然灾害的发生的次数有相应的降低,佐治亚州在2017年时受自然灾害影响最大。 从回归图中可以看出在1975年以前佐治亚州每年自然灾害发生次数大于德克萨斯州,1975年以后德克萨斯州每年自然灾害发生次数大于佐治亚洲。
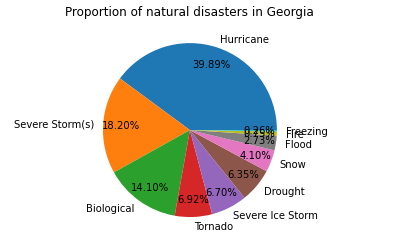
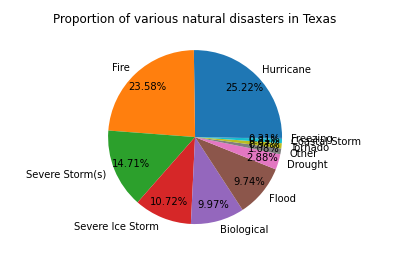
5. 用饼图分析德克萨斯州和佐治亚州各种自然灾害所占比例 1 #佐治亚州各种自然灾害所占比例 2 a=df.query('state=="GA"')['incident_type'].value_counts().reset_index() 3 b=a['index'] 4 c=np.array(b) 5 d=a['incident_type'] 6 plt.pie(d,labels=b,autopct='%1.2f%%',pctdistance=0.8) #画饼图(数据,数据对应的标签,百分数保留两位小数点,调节距离) 7 plt.title('Proportion of natural disasters in Georgia') 8 plt.figure(figsize=(20,6.5))
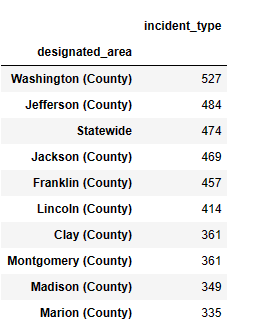
有图可知,飓风和火灾是德克萨斯州常发的自然灾难,飓风和强冰暴是佐治亚州常发的自然灾害 1 #查询受自然灾害影响最大的郡 2 df[['designated_area','incident_type']].groupby('designated_area').count().sort_values(by='incident_type',ascending=False).head(10)
华盛顿郡受自然灾害影响最大。
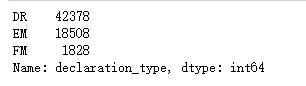
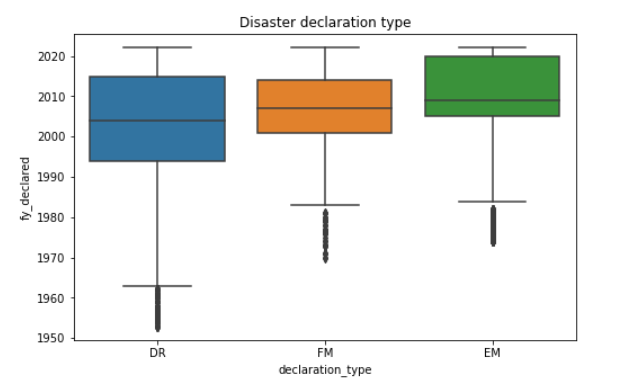
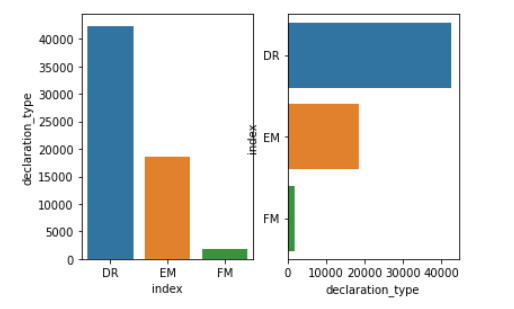
6.自然灾害的声明类型有三种“DR" (重大灾害), "EM" (紧急灾难), or "FM" (= "火灾") 1 #灾害声明类型统计 2 df['declaration_type'].value_counts()
在所有数据中重大灾害有42378条,紧急灾害有18508条,火灾有1828条
用盒图和柱状图来展现灾害声明类型 1 #用盒图来展现灾害声明类型 2 m=df[['fy_declared','declaration_type']] 3 plt.figure(figsize=(8,5)) 4 sns.boxplot(x='declaration_type',y='fy_declared',data=m); 5 plt.title('Disaster declaration type')
用盒图和柱状图我们可以更直观的看出灾害声明类型的数量分布
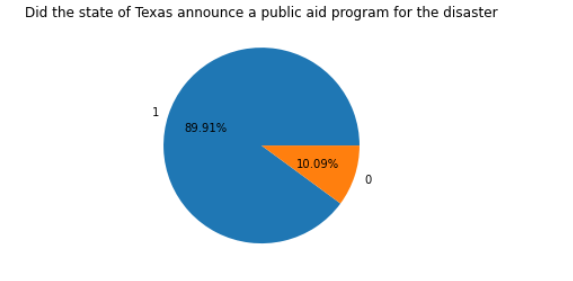
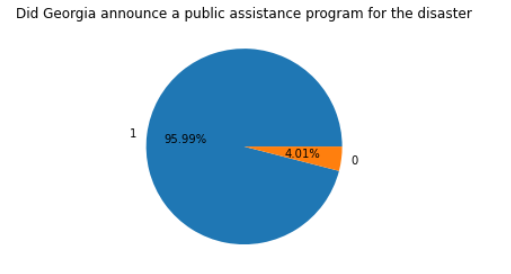
7.德克萨斯州和佐治亚州公共援助计划占比
pa_program_declared:二进制标志,指示是否为此灾难宣布了“公共援助计划”。(1有, 0没有) ia_program_declared:二进制标志,指示是否为此灾难宣布了“个人援助计划”。(1有, 0没有) 1 #德克萨斯州 2 #二进制标志,指示是否为此灾难宣布了“公共援助计划"(1有 0没有) 3 m=df.query('state=="TX"')['pa_program_declared'].value_counts().reset_index() 4 b=m['index'] 5 c=np.array(b) 6 d=m['pa_program_declared'] 7 plt.pie(d,labels=b,autopct='%1.2f%%') #画饼图(数据,数据对应的标签,百分数保留两位小数点,调节距离) 8 plt.title('Did the state of Texas announce a public aid program for the disaster') 9 plt.figure(figsize=(20,6.5))
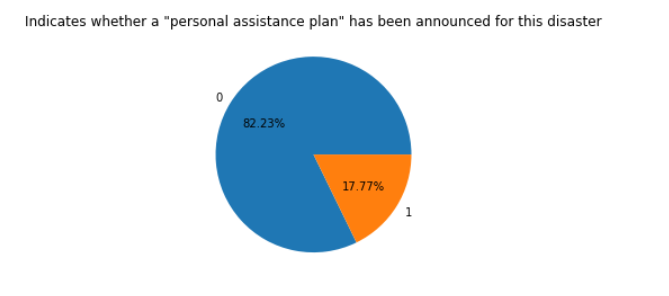
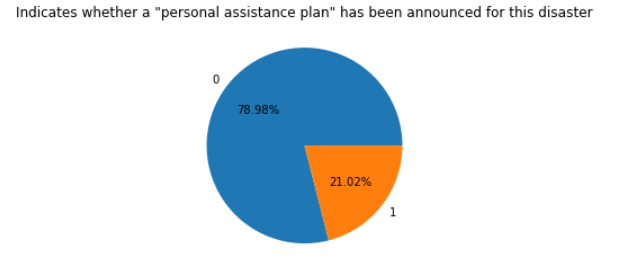
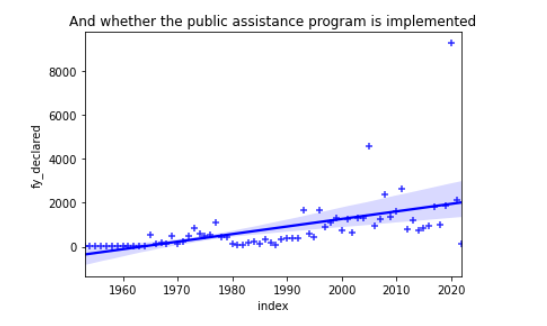
由饼图可知佐治亚洲的公共援助服务比德克萨斯州好,公共援助率达到了95.99% 由回归图我们可以看出美国公共援助服务量不断增加。
四、完整代码 1 import numpy as np 2 import pandas as pd 3 import matplotlib.pyplot as plt 4 import seaborn as sns 5 import warnings 6 warnings.filterwarnings('ignore') 7 from datetime import datetime 8 #读取数据集 9 filename = 'D:/us_disaster_declarations.csv' 10 df = pd.read_csv(filename) 11 12 #删除与本次数据分析无关的列 13 df.drop('hash',axis=1,inplace=True)#删除记录的字段和值的哈希值列,对本次实验无用数据 14 df.drop('last_refresh',axis=1,inplace=True)#删除上次更新记录的日期列,对本次实验无用数据 15 df.drop('id',axis=1,inplace=True)#删除ID列,对本次实验无用数据 16 17 #空值处理 18 df['disaster_number'].isnull().value_counts()#判断关键字段是否存在空值 19 df['incident_type'].isnull().value_counts()#判断关键字段是否存在空值 20 df['state'].isnull().value_counts()#判断关键字段是否存在空值 21 df['ih_program_declared'].isnull().value_counts()#判断关键字段是否存在空值 22 df['fy_declared'].isnull().value_counts()#判断关键字段是否存在空值 23 df['disaster_closeout_date'].isnull().value_counts()#判断关键字段是否存在空值 24 df['declaration_request_number'].isnull().value_counts()#判断关键字段是否存在空值 25 df['fips'].isnull().value_counts()#判断关键字段是否存在空值 26 df['incident_begin_date'].isnull().value_counts()#判断关键字段是否存在空值 27 28 #删除重复数据 29 df = df.drop_duplicates() 30 31 #空格处理 32 df['fema_declaration_string']=df['fema_declaration_string'].map(str.strip) 33 df['state']=df['state'].map(str.strip) 34 df['declaration_type']=df['declaration_type'].map(str.strip) 35 df['declaration_date']=df['declaration_date'].map(str.strip) 36 df['incident_type']=df['incident_type'].map(str.strip) 37 df['declaration_title']=df['declaration_title'].map(str.strip) 38 df['designated_area']=df['designated_area'].map(str.strip) 39 df['incident_begin_date']=df['incident_begin_date'].map(str.strip) 40 41 df.head() 42 #异常值处理 43 df.describe() 44 45 E_df = df[df['incident_type'] == 'Earthquake'].head(5)#提取出灾难类型为地震的数据 46 T_df = df[df['incident_type'] == 'Tornado']#提取出灾难类型为龙卷风的数据 47 F_df = df[df['incident_type'] == 'Flood']#提取出灾难类型为洪水的数据 48 49 E_df = df[df['incident_type'] == 'Earthquake']#提取出灾难类型为地震的数据 50 51 #提取数据 52 a=np.array(E_df['incident_begin_date']) 53 b=np.array(E_df['declaration_title']) 54 55 #绘制地震的折线图 56 plt.figure(figsize=(50,15)) 57 plt.xlabel("日期") 58 plt.ylabel("地震") 59 plt.plot(a,b,linewidth=5.0,c='y',label="地震") 60 plt.title('Number of earthquakes in each year') 61 plt.show() 62 63 T_df = df[df['incident_type'] == 'Tornado']#提取出灾难类型为龙卷风的数据 64 65 #提取数据 66 a=np.array(T_df['incident_begin_date']) 67 b=np.array(T_df['declaration_title']) 68 69 #绘制龙卷风的折线图 70 plt.figure(figsize=(50,15)) 71 plt.xlabel("日期") 72 plt.ylabel("龙卷风") 73 plt.plot(a,b,linewidth=5.0,c='r',label="龙卷风") 74 plt.title('Number of Tornado in each year') 75 plt.show() 76 77 F_df = df[df['incident_type'] == 'Flood']#提取出灾难类型为洪水的数据 78 79 #提取数据 80 a=np.array(F_df['incident_begin_date']) 81 b=np.array(F_df['declaration_title']) 82 83 #绘制洪水的折线图 84 plt.figure(figsize=(50,30)) 85 plt.xlabel("日期") 86 plt.ylabel("洪水") 87 plt.plot(a,b,linewidth=5.0,c='b',label="洪水") 88 plt.title('Number of Flood in each year') 89 plt.show() 90 91 #调取各州所对应的自然灾害数据 92 m=df[['state','incident_type']].groupby('state').describe() 93 m['incident_type'].sort_values(by='count',ascending=False).head(10) 94 95 #事件数量 96 fig,axes=plt.subplots(2,2) 97 sns.distplot(df['incident_type'].value_counts(),ax=axes[0][0]) 98 sns.distplot(df['incident_type'].value_counts(),kde=False,ax=axes[0][1]) 99 sns.distplot(df['incident_type'].value_counts(),rug=True,ax=axes[1][0]) 100 sns.distplot(df['incident_type'].value_counts(),vertical=True,ax=axes[1][1]) 101 102 #各种自然灾害发生的频率 103 m=df[['fy_declared','incident_type']].groupby('fy_declared').describe()['incident_type'].reset_index() 104 plt.figure(figsize=(10,5)) 105 plt.title('Frequency of various natural disasters') 106 sns.barplot(x='top',y='freq',data =m) 107 108 #年份与自然灾害发生次数的回归图 109 m=df['fy_declared'].value_counts().reset_index() 110 sns.lmplot(x='index',y='fy_declared',data=m.sort_values(by='fy_declared'), 111 aspect=1.7, height=5,markers=['o'], scatter_kws={'s':20}); 112 plt.title('Regression diagram of year and number of natural disasters') 113 114 #调取州所对应的数据 115 d=m.sort_values(by='state').reset_index().head(10) 116 117 #用饼图来展现每个州的受自然灾害影响的情况 118 d=m.sort_values(by='state').reset_index() 119 c=d['state'] 120 a=d['index'] 121 e=np.array(a) 122 plt.pie(c ,labels=e,autopct='%1.2f%%',pctdistance=0.8) #画饼图(数据,数据对应的标签,百分数保留两位小数点,调节距离) 123 plt.title('Disaster situation in each state') 124 plt.figure(figsize=(30,30)) 125 126 #调取州所对应的事件类型 127 S = df[['state','incident_type']].groupby('state').count().head(10) 128 129 #用柱状图来展现每个州的受自然灾害影响的情况 130 S = df[['state','incident_type']].groupby('state').count() 131 S.reset_index(inplace=True) 132 S=S.sort_values(by='incident_type',ascending=False) 133 plt.figure(figsize=(30,10)) 134 sns.barplot(x="state", y="incident_type", data=S,) 135 plt.title('Impact of natural disasters in each state') 136 total_width,n=0.8,3#设置间隔 137 plt.grid()#增加网格 138 139 #热力图来展现各州在不同年份受自然灾害的影响情况 140 pt = df.pivot_table(values ='disaster_number', index = 'state', columns = 'fy_declared').fillna(0) 141 plt.figure(figsize=(10,8)) 142 sns.heatmap(pt, cmap='coolwarm'); 143 plt.savefig('heatmap.png') 144 plt.title('Disaster heat map') 145 146 #德克萨斯州 147 m=df.query('state=="TX"')['fy_declared'].value_counts().reset_index() 148 plt.figure(figsize=(30,15)) 149 sns.barplot(x='index',y='fy_declared',data=m.sort_values(by='fy_declared')); 150 plt.title('Impact of natural disasters in Texas in each year') 151 plt.grid() 152 153 #佐治亚州 154 a=df.query('state=="GA"')['fy_declared'].value_counts().reset_index() 155 plt.figure(figsize=(30,15)) 156 sns.barplot(x='index',y='fy_declared',data=m.sort_values(by='fy_declared')); 157 plt.title('Impact of natural disasters in Georgia in each year') 158 plt.grid() 159 160 #德克萨斯州年份与受灾情况的回归图 161 m=df.query('state=="TX"')['fy_declared'].value_counts().reset_index() 162 sns.regplot(x='index',y='fy_declared', data=m.sort_values(by='fy_declared'), 163 color='r',marker='+') 164 165 #佐治亚州年份与受灾情况的回归图 166 a=df.query('state=="GA"')['fy_declared'].value_counts().reset_index() 167 sns.regplot(x='index',y='fy_declared', data=a.sort_values(by='fy_declared'), 168 color='g',marker='*') 169 170 plt.title('Regression of years and disaster conditions in Texas and Georgia') 171 172 #佐治亚州各种自然灾害所占比例 173 a=df.query('state=="GA"')['incident_type'].value_counts().reset_index() 174 b=a['index'] 175 c=np.array(b) 176 d=a['incident_type'] 177 plt.pie(d,labels=b,autopct='%1.2f%%',pctdistance=0.8) #画饼图(数据,数据对应的标签,百分数保留两位小数点,调节距离) 178 plt.title('Proportion of natural disasters in Georgia') 179 plt.figure(figsize=(20,6.5)) 180 181 #德克萨斯州各种自然灾害所占比例 182 m=df.query('state=="TX"')['incident_type'].value_counts().reset_index() 183 b=m['index'] 184 c=np.array(b) 185 d=m['incident_type'] 186 plt.pie(d,labels=b,autopct='%1.2f%%',pctdistance=0.8) #画饼图(数据,数据对应的标签,百分数保留两位小数点,调节距离) 187 plt.title('Proportion of various natural disasters in Texas') 188 plt.figure(figsize=(20,6.5)) 189 190 #查询受自然灾害影响最大的郡 191 df[['designated_area','incident_type']].groupby('designated_area').count().sort_values(by='incident_type',ascending=False).head(10) 192 193 #灾害声明类型统计 194 df['declaration_type'].value_counts() 195 196 #用盒图来展现灾害声明类型 197 m=df[['fy_declared','declaration_type']] 198 plt.figure(figsize=(8,5)) 199 sns.boxplot(x='declaration_type',y='fy_declared',data=m); 200 plt.title('Disaster declaration type') 201 202 #用柱状图来展现灾害声明类型 203 fig,axes=plt.subplots(1,2) 204 plt.figure(figsize=(10,5)) 205 sns.barplot(x='index',y='declaration_type',data=df['declaration_type'].value_counts().reset_index(),ax=axes[0]) 206 sns.barplot(x='declaration_type',y='index',data=df['declaration_type'].value_counts().reset_index(),ax=axes[1]) 207 plt.title('Disaster declaration type') 208 209 #德克萨斯州 210 #二进制标志,指示是否为此灾难宣布了“公共援助计划"(1有 0没有) 211 m=df.query('state=="TX"')['pa_program_declared'].value_counts().reset_index() 212 b=m['index'] 213 c=np.array(b) 214 d=m['pa_program_declared'] 215 plt.pie(d,labels=b,autopct='%1.2f%%') #画饼图(数据,数据对应的标签,百分数保留两位小数点,调节距离) 216 plt.title('Did the state of Texas announce a public aid program for the disaster') 217 plt.figure(figsize=(20,6.5)) 218 219 #佐治亚洲 220 #二进制标志,指示是否为此灾难宣布了“公共援助计划"(1有 0没有) 221 m=df.query('state=="GA"')['pa_program_declared'].value_counts().reset_index() 222 b=m['index'] 223 c=np.array(b) 224 d=m['pa_program_declared'] 225 plt.pie(d,labels=b,autopct='%1.2f%%') #画饼图(数据,数据对应的标签,百分数保留两位小数点,调节距离) 226 plt.title('Did Georgia announce a public assistance program for the disaster') 227 plt.figure(figsize=(20,6.5)) 228 229 #德克萨斯州 230 #二进制标志,指示是否为此灾难宣布了“个人援助计划"(1有 0没有) 231 m=df.query('state=="TX"')['ia_program_declared'].value_counts().reset_index() 232 b=m['index'] 233 c=np.array(b) 234 d=m['ia_program_declared'] 235 plt.pie(d,labels=b,autopct='%1.2f%%') #画饼图(数据,数据对应的标签,百分数保留两位小数点,调节距离) 236 plt.title('Indicates whether a "personal assistance plan" has been announced for this disaster') 237 plt.figure(figsize=(20,6.5)) 238 239 #佐治亚州 240 #二进制标志,指示是否为此灾难宣布了“个人援助计划"(1有 0没有) 241 m=df.query('state=="GA"')['ia_program_declared'].value_counts().reset_index() 242 b=m['index'] 243 c=np.array(b) 244 d=m['ia_program_declared'] 245 plt.pie(d,labels=b,autopct='%1.2f%%') #画饼图(数据,数据对应的标签,百分数保留两位小数点,调节距离) 246 plt.title('Indicates whether a "personal assistance plan" has been announced for this disaster') 247 plt.figure(figsize=(20,6.5)) 248 249 #年份与是否执行公共援助计划情况的回归图 250 m=df.query('pa_program_declared==1')['fy_declared'].value_counts().reset_index() 251 sns.regplot(x='index',y='fy_declared', data=m.sort_values(by='fy_declared'),color='b',marker='+') 252 plt.title('And whether the public assistance program is implemented')
五、总结 1、通过这次对美国自然灾害大数据分析与可视化,我了解了美国发生频率最高的自然灾害、美国每年受自然灾害影响最大的州和郡、美国每年对待自然灾害所提供的公共援助计划的实施率,并对受自然灾害影响最大的州进行了相应的分析。 2、随着对数据集的分析与可视化的渐渐深入,一些问题也体现了出来,美国每年自然灾害发生次数不断上升,这很大一部分原因来自人类活动,这应当引起人们的警觉。随着人类对自然资源的加速开采和“空洞”效应的继续扩大,人为的自然地质性灾害将越来越频繁地发生,地陷、火山爆发、地震、海啸、山体滑坡等等重大破坏性因素将危及人类的繁衍生存,为此我们应当把环境保护放在推进现代化建设过程中的关键位置,我们应该认识到:保护和改善环境也是保护和发展生产力。 3.个人收获:通过这次对数据集分析与可视化,我掌握了数据清洗的基本步骤,熟悉了直方图、散点图、回归图、饼图等常见图的画法。加深了对大数据分析与可视化的理解。
|

【本文地址】