| 【Transformer论文】Transformers 的多模式学习: 一项综述 | 您所在的位置:网站首页 › 多模态应用研究 › 【Transformer论文】Transformers 的多模式学习: 一项综述 |
【Transformer论文】Transformers 的多模式学习: 一项综述
|
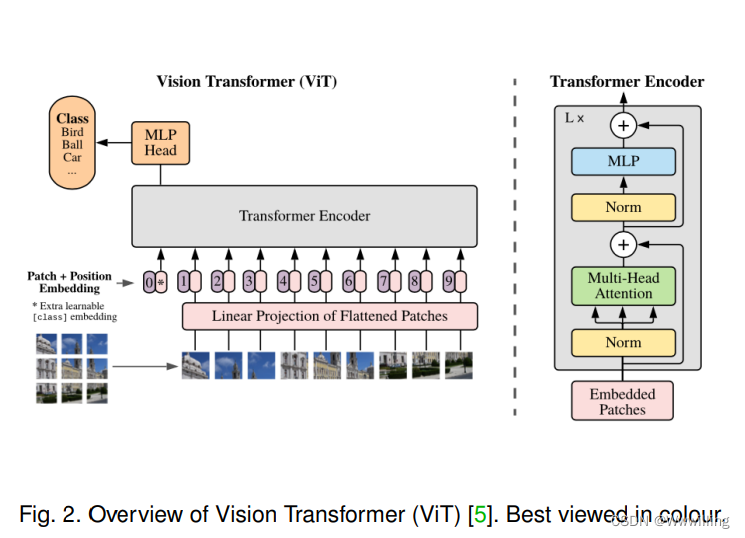
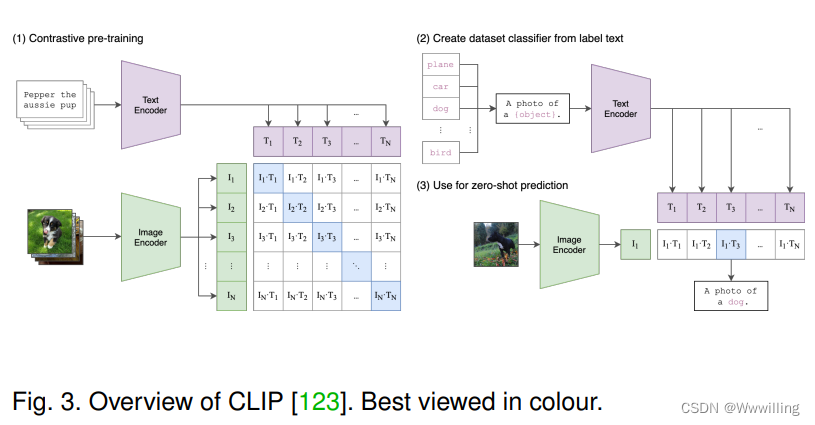
Transformer正在成为有前途的学习者。 得益于其自我注意,Vanilla Transformer [2] 受益于自我注意机制,是最初为 NLP 提出的序列特定表示学习的突破性模型,在 各种 NLP 任务。 随着 Vanilla Transformer 的巨大成功,许多衍生模型被提出,例如 BERT [4]、BART [90]、GPT [91]、GPT-2 [92]、GPT-3 [93]、Longformer [ 40]、Transformer-XL [94]、XLNet [95]。 Transformers 目前在 NLP 领域处于主导地位,这促使研究人员尝试将 Transformers 应用于其他模式,例如视觉领域。 在视觉领域的早期尝试中,早期探索的一般流程是“CNN 特征 + 标准 Transformer 编码器”,研究人员通过调整原始图像大小到低分辨率并重新整形为一维序列来实现 BERT 式预训练 [96 ]。 Vision Transformer (ViT) [5] 是一项开创性的工作,它通过将 Transformer 的编码器应用于图像来提供端到端的解决方案。 (参见图 2。)ViT 及其变体都已广泛应用于各种计算机视觉任务,包括低级任务 [97]、识别 [98]、检测 [99]、分割 [100] 等 ,并且对于有监督的[98]和自我监督的[101]、[102]、[103]视觉学习也很有效。 此外,一些最近发布的作品为 ViT 提供了进一步的理论理解,例如,它的内部表示鲁棒性 [104]、其潜在表示传播的连续行为 [105]、[106]。 在 Transformer 和 ViT 的巨大成功的推动下,VideoBERT [7] 是一项突破性的工作,是第一个将 Transformer 扩展到多模态任务的工作。 VideoBERT 展示了 Transformer 在多模态环境中的巨大潜力。 在 VideoBERT 之后,许多基于 Transformer 的多模态预训练模型(例如,ViLBERT [107]、LXMERT [108]、LXMERT [108]、VisualBERT [109]、VL-BERT [110]、UNITER [111]、CBT [112] , Unicoder-VL [113], B2T2 [114], VLP [115], 12-in-1 [116], Oscar [117], Pixel-BERT [118], ActBERT [119], ImageBERT [120], HERO [121],UniVL [122])已成为机器学习领域越来越感兴趣的研究课题。 2021 年,提出了 CLIP [123](如图 3 所示)。 这是一个新的里程碑,它使用多模态预训练将分类转换为检索任务,使预训练模型能够处理零样本识别。 因此,CLIP 是一个成功的实践,它充分利用了大规模多模态预训练来实现零样本学习。 最近,进一步研究了 CLIP 的思想,例如基于 CLIP 预训练模型的零样本语义分割 [124]、ALIGN [125]、CLIP-TD [126]。 |
【本文地址】