| DataX (原理, 增量全量同步数据实践) | 您所在的位置:网站首页 › 增量和全量数据 › DataX (原理, 增量全量同步数据实践) |
DataX (原理, 增量全量同步数据实践)
|
目录 理解 mysql -> mysql (增量,全量) 增量导入 全量导入 mysql -> hive (增量,全量) 增量导入 全量导入 理解datax每张表都需要对应的配置文件。 Reader:数据采集模块,负责采集数据源的数据,将数据发送给Framework。 Writer:数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。 Framework:用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。 datax底层是以双缓冲阻塞队列为整个数据交换的媒介,读进程负责读取并向队列中添加读到的记录,写进程负责接收数据并从队列中取出写入记录。 mysql -> mysql (增量,全量) 1.先创建2张mysql数据表 数据源 1.CREATE DATABASE /*!32312 IF NOT EXISTS*/`userdb` /*!40100 DEFAULT CHARACTER SET utf8 */; 2.USE `userdb`; 3.CREATE TABLE `emp` ( `id` int(11) DEFAULT NULL, `name` varchar(100) DEFAULT NULL, `deg` varchar(100) DEFAULT NULL, `salary` int(11) DEFAULT NULL, `dept` varchar(10) DEFAULT NULL, `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP, `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, `is_delete` bigint(20) DEFAULT '1' ) ENGINE=InnoDB DEFAULT CHARSET=latin1; 4.insert into `emp`(`id`,`name`,`deg`,`salary`,`dept`,`create_time`,`update_time`,`is_delete`) values (1201,'gopal','manager',50000,'TP','2018-06-17 18:54:32','2019-01-17 11:19:32',1),(1202,'manishahello','Proof reader',50000,'TPP','2018-06-15 18:54:32','2018-06-17 18:54:32',0),(1203,'khalillskjds','php dev',30000,'AC','2018-06-17 18:54:32','2019-03-14 09:18:27',1),(1204,'prasanth_xxx','php dev',30000,'AC','2018-06-17 18:54:32','2019-04-07 09:09:24',1),(1205,'kranthixxx','admin',20000,'TP','2018-06-17 18:54:32','2018-12-08 11:50:33',0),(1206,'garry','manager',50000,'TPC','2018-12-10 21:41:09','2018-12-10 21:41:09',1),(1207,'oliver','php dev',2000,'AC','2018-12-15 13:49:13','2018-12-15 13:49:13',1),(1208,'hello','phpDev',200,'TP','2018-12-16 09:41:48','2018-12-16 09:41:48',1),(1209,'ABC','HELLO',300,NULL,'2018-12-16 09:42:04','2018-12-16 09:42:24',1),(1210,'HELLO','HELLO',5800,'TP','2019-01-24 09:02:43','2019-01-24 09:02:43',1),(1211,'WORLD','TEST',8800,'AC','2019-01-24 09:03:15','2019-01-24 09:03:15',1),(1212,'sdfs','sdfsdf',8500,'AC','2019-03-13 22:01:38','2019-03-13 22:01:38',1),(1213,NULL,'sdfsdf',9800,'sdfsdf','2019-03-14 09:08:31','2019-03-14 09:08:54',1),(1214,'xxx','sdfsdf',9500,NULL,'2019-03-14 09:13:32','2019-03-14 09:13:44',0),(1215,'sdfsf','sdfsdfsdf',9870,'TP','2019-04-07 09:10:39','2019-04-07 09:11:18',0),(1216,'hello','HELLO',5600,'AC','2019-04-07 09:37:05','2019-04-07 09:37:05',1),(1217,'HELLO2','hello2',7800,'TP','2019-04-07 09:37:40','2019-04-07 09:38:17',1);
目标表: 1.USE userdb; 2.CREATE TABLE `emp3` ( `id` INT(11) DEFAULT NULL, `name` VARCHAR(100) DEFAULT NULL, `deg` VARCHAR(100) DEFAULT NULL, `salary` INT(11) DEFAULT NULL, `create_time` timestamp default CURRENT_TIMESTAMP, `update_time` timestamp default CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP ) ENGINE=INNODB DEFAULT CHARSET=latin1;
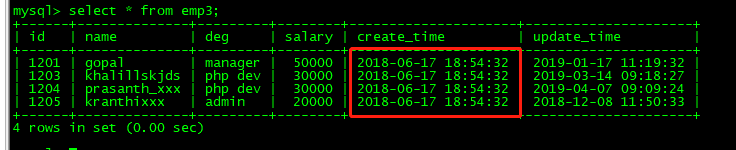
vim mysql2mysql.json { "job": { "setting": { "speed": { "channel":1 } }, "content": [ { "reader": { "name": "mysqlreader", "parameter": { "username": "root", "password": "root%123", "connection": [ { "querySql": [ "select id,name,deg,salary,create_time,update_time from emp where create_time > '${start_time}' and create_time < '${end_time}';" ], "jdbcUrl": [ "jdbc:mysql://192.168.72.112:3306/userdb" ] } ] } }, "writer": { "name": "mysqlwriter", "parameter": { "writeMode": "insert", "username": "root", "password": "root%123", "column": [ "id", "name", "deg", "salary","create_time","update_time" ], "session": [ "set session sql_mode='ANSI'" ], "preSql": [ "delete from emp3" ], "connection": [ { "jdbcUrl": "jdbc:mysql://192.168.72.112:3306/userdb?useUnicode=true&characterEncoding=utf-8", "table": [ "emp3" ] } ] } } } ] } } 3.执行dataX同步任务 python ../bin/datax.py ./mysql2mysql.json -p "-Dstart_time='2018-06-17 00:00:00' -Dend_time='2018-06-18 23:59:59'"结果查看:增量同步17-18日的数据成功。
只需将上面配置文件中的querySql 改为: select id,name,deg,salary,create_time,update_time from emp 即可。 mysql -> hive (增量,全量) 增量导入 1.创建hive表 create external table emp( id int,name string, deg string,salary double, dept string, create_time timestamp, update_time timestamp , isdeleted string) row format delimited fields terminated by '\001'; 2.编辑dataX配置文件{ "job": { "setting": { "speed": { "channel":1 } }, "content": [ { "reader": { "name": "mysqlreader", "parameter": { "username": "root", "password": "root%123", "connection": [ { "querySql": [ "select * from emp where create_time > '${start_time}' and create_time < '${end_time}'" ], "jdbcUrl": [ "jdbc:mysql://192.168.72.112:3306/userdb" ] } ] } }, "writer": { "name": "hdfswriter", "parameter": { "defaultFS": "hdfs://node01:8020", "fileType": "text", "path": "/warehouse/tablespace/external/hive/datax.db/emp", "fileName": "emp", "column": [ { "name": "id", "type": "INT" }, { "name": "name", "type": "STRING" }, { "name": "deg", "type": "STRING" }, { "name": "salary", "type": "DOUBLE" }, { "name": "dept", "type": "STRING" }, { "name": "create_time", "type": "TIMESTAMP" }, { "name": "update_time", "type": "TIMESTAMP" }, { "name": "isdeleted", "type": "STRING" } ], "writeMode": "append", "fieldDelimiter": "\u0001" } } } ] } } 注意:writeMode 仅支持append, nonConflict两种模式 3.执行脚本
python ../bin/datax.py ./mysql2hive.json -p "-Dstart_time='2018-06-17 00:00:00' -Dend_time='2018-06-18 23:59:59'" 查看增量导入结果
全量只需修改配置文件querysql即可。 |



【本文地址】