| 神经网络翻译 | 您所在的位置:网站首页 › 基于神经网络的机器翻译模型 › 神经网络翻译 |
神经网络翻译
|
神经网络机器翻译(Neural Machine Translation, NMT)是最近几年提出来的一种机器翻译方法。相比于传统的统计机器翻译(SMT)而言,NMT能够训练一张能够从一个序列映射到另一个序列的神经网络,输出的可以是一个变长的序列,这在翻译、对话和文字概括方面能够获得非常好的表现。NMT其实是一个encoder-decoder系统,encoder把源语言序列进行编码,并提取源语言中信息,通过decoder再把这种信息转换到另一种语言即目标语言中来,从而完成对语言的翻译。 神经网络的seq2seq学习序列对序列的学习,顾名思义,假设有一个中文句子“我也爱你”和一个对应英文句子“I love you too”,那么序列的输入就是“我也爱你”,而序列的输出就是“I love you too”,从而对这个序列对进行训练。对于深度学习而言,如果要学习一个序列,一个重要的困难就是这个序列的长度是变化的,而深度学习的输入和输出的维度一般是固定的,不过,有了RNN结构,这个问题就可以解决了,一般在应用的时候encoder和decoder使用的是LSTM或GRU结构。
在这个新的结构中,定义条件概率:
p
(
y
)
=
Π
t
=
1
T
′
p
(
y
t
∣
{
y
1
,
⋯
,
y
t
−
1
}
,
c
)
p
(
y
t
∣
{
y
1
,
⋯
,
y
t
−
1
}
,
c
)
=
g
(
y
t
−
1
,
s
t
,
c
)
(3)
p(y)=\Pi^{T^{'}}_{t=1}p(y_t|\{y_1,\cdots,y_{t-1}\},c)\tag{3}\\ p(y_t|\{y_1,\cdots,y_{t-1}\},c)=g(y_{t-1},s_t,c)
p(y)=Πt=1T′p(yt∣{y1,⋯,yt−1},c)p(yt∣{y1,⋯,yt−1},c)=g(yt−1,st,c)(3) 其中,
g
g
g为非线性函数,
s
t
s_t
st是decoder的隐藏状态,
c
c
c是由encoder的隐藏序列产生的上下文向量,这个具体是什么等一会说。 把(3)式的条件概率写为:
p
(
y
i
∣
y
1
,
⋯
,
y
i
−
1
,
x
)
=
g
(
y
i
−
1
,
s
i
,
c
i
)
(4)
p(y_i|y_1,\cdots,y_{i-1},x)=g(y_{i-1},s_i,c_i)\tag{4}
p(yi∣y1,⋯,yi−1,x)=g(yi−1,si,ci)(4) 其中,
s
i
s_i
si是时间步
i
i
i的隐藏状态,可由下式来计算:
s
i
=
f
(
s
i
−
1
,
y
i
−
1
,
c
i
)
s_i = f(s_{i-1}, y_{i-1},c_i)
si=f(si−1,yi−1,ci) 下面来说说这个
c
i
c_i
ci是怎么出来的。上下文向量
c
i
c_i
ci依赖于一系列的注解
(
h
1
,
⋯
,
h
T
)
(h_1,\cdots,h_T)
(h1,⋯,hT),这些注解上面我们已经讲过。上下文向量是由这些注解
h
j
h_j
hj加权求和算出来的:
c
i
=
Σ
j
=
1
T
α
i
j
h
j
(5)
c_i = \Sigma_{j=1}^T\alpha_{ij}h_j\tag{5}
ci=Σj=1Tαijhj(5) 每个注解
h
j
h_j
hj的权重
α
i
j
\alpha_{ij}
αij由下式计算:
α
i
j
=
e
x
p
(
e
i
j
)
Σ
k
=
1
T
e
x
p
(
e
i
k
)
(6)
\alpha_{ij} = \frac{exp(e_{ij})}{\Sigma_{k=1}^Texp(e_{ik})}\tag{6}
αij=Σk=1Texp(eik)exp(eij)(6) 其中,
e
i
j
=
a
(
s
i
−
1
,
h
j
)
e_{ij}=a(s_{i-1},h_j)
eij=a(si−1,hj)为对位模型(alignment model),由于它计算位置
j
j
j周围的输入与位置
i
i
i的输出相匹配的得分,所以又称为得分函数。而向量
α
i
=
(
α
i
1
,
α
i
2
,
⋯
,
α
i
T
)
\alpha_i=(\alpha_{i1},\alpha_{i2},\cdots,\alpha_{iT})
αi=(αi1,αi2,⋯,αiT)为注意力向量,又为词对位向量。 整个过程的图示如下: 训练集WMT’14 英语-法语,字典30000常用词,不在字典中的生词用[unk]表示,没有改变大小写,没有进行词干化。 两个模型,一个RNN encoder-decoder模型(RNNencdec),另一个为建议模型(RNNsearch),训练两次,一次句子长度最大30,另一次最大50RNNencdec的encoder和decoder各有1000个隐藏单元。RNNsearch的encoder前后向RNN各1000隐藏单元,decoder1000个隐藏单元输出使用maxout函数,L2正则化损失函数带有Adadelta( ϵ = 1 0 − 6 , ρ = 095 \epsilon=10^{-6},\rho = 095 ϵ=10−6,ρ=095)的minbatch SGD,min-batch=80Bahdanau与Sutskever的几点不同: 在结构上,Sutskever使用了单向的RNN,而Bahdanau使用了双向的RNNSutskever使用了encoder的最后一个隐藏状态来作为decoder的输入并且后续的过程中不再把decoder的隐藏层作为下一时间步的输入,而Bahdanau使用了所有的encoder的隐藏状态并经过注意力机制与decoder的隐藏层一起作为decoder的初始输入,并且在后续中前一decoder的隐藏层和输出作为下一时间步的输入Bahdanau加入了注意力机制,获得了注意力向量 α i = ( α i 1 , α i 2 , ⋯ , α i T ) \alpha_i=(\alpha_{i1},\alpha_{i2},\cdots,\alpha_{iT}) αi=(αi1,αi2,⋯,αiT) ##注意力机制的改进 在Bahdanau提出注意力机制后不久,Luong又在其基础上把注意力机制分为全局注意力(globale attention)机制和局部注意力(local attention)机制。简单的来说,是使用全部的encoder的隐藏层还是部分。要进行预测,首先还是要获得这个上下文向量 c t c_t ct,这个上下文向量用来捕获源语言的相关信息来预测目标词 y t y_t yt,然后把decoder的隐藏状态 s t s_t st与这个上下文向量 c t c_t ct拼接起来通过非线性函数产生注意力隐藏状态(attentional hidden state): h t ~ = t a n h ( W c [ c t ; s t ] ) (7) \tilde{h_t} = tanh(W_c[c_t;s_t])\tag{7} ht~=tanh(Wc[ct;st])(7) 最后,使用softmax函数进行预测: p ( y t ∣ y < t , x ) = s o f t m a x ( W s h t ~ ) (8) p(y_t|y_{ϵ(yk)−logQ(yk)}(15) 在这里只是使用了一个目标字典的较小的一个子集 V s V^{s} Vs就能计算出正则项。但是怎么选择这个提议分布呢?首先Jean在实践中把训练语料进行分区,在训练前,对每个分区定义一个目标词汇子集 V ′ V^{'} V′,然后顺序扫描句子,抽取不同的单词,直到到达一个阈值 τ = ∣ V ′ ∣ \tau=|V^{'}| τ=∣V′∣,这些句子就作为一个分区,而这个词汇子集就用于这个分区的训练,重复上述过程直到把训练目标句子分区完。假设第 i i i个分区用的目标词典为 V i ′ V_i^{'} Vi′,对于每一个分区都对应一个 Q i Q_i Qi,在 V i ′ V_i^{'} Vi′内,每一个目标词都具有相同的概率,而不在 V i ′ V_i^{'} Vi′内的概率为0: Q i ( y k ) = { 1 ∣ V i ′ ∣ i f y t ∈ V i ′ 0 o t h e r w i s e (16) Q_i(y_k)=\begin{cases} \frac{1}{|V_i^{'}|} & if\quad y_t\in V_i^{'}\\ 0 & otherwise \end{cases}\tag{16} Qi(yk)={∣Vi′∣10ifyt∈Vi′otherwise(16) 而这个提议分布可以抵消(15)式的校正项 − l o g Q ( y k ) -logQ(y_k) −logQ(yk),非常简单,我们来推导一下: ω k = e x p { ϵ ( y k ) − l o g Q ( y k ) } = e x p { ϵ ( y k ) − l o g 1 ∣ V i ′ ∣ } = e x p { ϵ ( y k ) + l o g ∣ V i ′ ∣ } = e x p { ϵ ( y k ) + l o g τ } \omega_k = exp\{\epsilon(y_k)-logQ(y_k)\}\\ =exp\{\epsilon(y_k)-log\frac{1}{|V_i^{'}|}\}\\ =exp\{\epsilon(y_k)+log|V_i^{'}|\}\\ =exp\{\epsilon(y_k)+log\tau\} ωk=exp{ϵ(yk)−logQ(yk)}=exp{ϵ(yk)−log∣Vi′∣1}=exp{ϵ(yk)+log∣Vi′∣}=exp{ϵ(yk)+logτ} 最后得到与(11)式近似的概率: p ( y t ∣ y < t , x ) = e x p { w t ′ ϕ ( y t − 1 , s t , c t ) + b t } Σ k : y k ∈ V ′ e x p { w k ′ ϕ ( y t − 1 , s t , c t ) + b k } (17) p(y_t|y_{ |
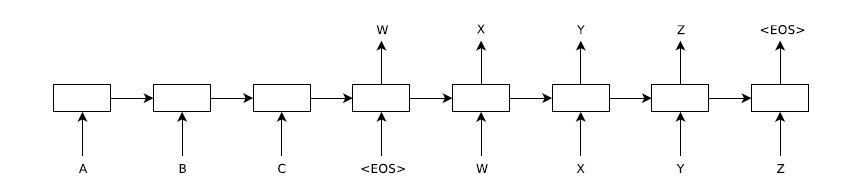 如上图,输入一个句子ABC以及句子的终结符号< EOS>,输出的结果为XYZ及终结符号< EOS>。在encoder中,每一时间步输入一个单词直到输入终结符为止,然后由encoder的最后一个隐藏层
h
t
h_t
ht作为decoder的输入,在decoder中,最初的输入为encoder的最后一个隐藏层,输出为目标序列词X,然后把该隐藏层以及它的输出X作为下一时间步的输入来生成目标序列中第二个词Y,这样依次进行直到< EOS>。下面看它详细的模型。 给定一个输入序列
(
x
1
,
⋯
,
x
T
)
(x_1,\cdots, x_T)
(x1,⋯,xT),经过下面的方程迭代生成输出序列
(
y
1
,
⋯
,
y
T
′
)
(y_1,\cdots, y_{T^{'}})
(y1,⋯,yT′):
h
t
=
f
(
W
h
x
x
t
+
W
h
h
h
t
−
1
)
y
t
=
W
y
h
h
t
(1)
h_t = f(W^{hx}x_t + W^{hh}h_{t-1})\tag{1}\\ y_t = W^{yh}h_t
ht=f(Whxxt+Whhht−1)yt=Wyhht(1) 其中,
W
h
x
W^{hx}
Whx为输入到隐藏层的权重,
W
h
h
W^{hh}
Whh为隐藏层到隐藏层的权重,
h
t
h_t
ht为隐藏结点,$ W^{yh}
为
隐
藏
层
到
输
出
的
权
重
。
在
这
个
结
构
中
,
我
们
的
目
标
是
估
计
条
件
概
率
为隐藏层到输出的权重。 在这个结构中,我们的目标是估计条件概率
为隐藏层到输出的权重。在这个结构中,我们的目标是估计条件概率p(y_1,\cdots,y_{T{’}}|x_1,\cdots,x_T)$,首先通过encoder的最后一个隐藏层获得$(x_1,\cdots,x_T)$的固定维度的向量表示$v$,然后通过decoder进行计算$y_1,\cdots,y_{T{’}}
的
概
率
,
这
里
的
初
始
隐
藏
层
设
置
为
向
量
的概率,这里的初始隐藏层设置为向量
的概率,这里的初始隐藏层设置为向量v$:
p
(
y
1
,
⋯
,
y
T
′
∣
x
1
,
⋯
,
x
T
)
=
Π
t
=
1
T
′
p
(
y
t
∣
v
,
y
1
,
⋯
,
y
t
−
1
)
(2)
p(y_1,\cdots,y_{T^{'}}|x_1,\cdots,x_T) = \Pi^{T^{'}}_{t=1}p(y_t|v,y_1,\cdots,y_{t-1})\tag{2}
p(y1,⋯,yT′∣x1,⋯,xT)=Πt=1T′p(yt∣v,y1,⋯,yt−1)(2) 在这个方程中,每个
p
(
y
t
∣
v
,
y
1
,
⋯
,
y
t
−
1
)
p(y_t|v,y_1,\cdots,y_{t-1})
p(yt∣v,y1,⋯,yt−1)为一个softmax函数。 Sutskever等人在实际建模中有三点与上述描述不同:
如上图,输入一个句子ABC以及句子的终结符号< EOS>,输出的结果为XYZ及终结符号< EOS>。在encoder中,每一时间步输入一个单词直到输入终结符为止,然后由encoder的最后一个隐藏层
h
t
h_t
ht作为decoder的输入,在decoder中,最初的输入为encoder的最后一个隐藏层,输出为目标序列词X,然后把该隐藏层以及它的输出X作为下一时间步的输入来生成目标序列中第二个词Y,这样依次进行直到< EOS>。下面看它详细的模型。 给定一个输入序列
(
x
1
,
⋯
,
x
T
)
(x_1,\cdots, x_T)
(x1,⋯,xT),经过下面的方程迭代生成输出序列
(
y
1
,
⋯
,
y
T
′
)
(y_1,\cdots, y_{T^{'}})
(y1,⋯,yT′):
h
t
=
f
(
W
h
x
x
t
+
W
h
h
h
t
−
1
)
y
t
=
W
y
h
h
t
(1)
h_t = f(W^{hx}x_t + W^{hh}h_{t-1})\tag{1}\\ y_t = W^{yh}h_t
ht=f(Whxxt+Whhht−1)yt=Wyhht(1) 其中,
W
h
x
W^{hx}
Whx为输入到隐藏层的权重,
W
h
h
W^{hh}
Whh为隐藏层到隐藏层的权重,
h
t
h_t
ht为隐藏结点,$ W^{yh}
为
隐
藏
层
到
输
出
的
权
重
。
在
这
个
结
构
中
,
我
们
的
目
标
是
估
计
条
件
概
率
为隐藏层到输出的权重。 在这个结构中,我们的目标是估计条件概率
为隐藏层到输出的权重。在这个结构中,我们的目标是估计条件概率p(y_1,\cdots,y_{T{’}}|x_1,\cdots,x_T)$,首先通过encoder的最后一个隐藏层获得$(x_1,\cdots,x_T)$的固定维度的向量表示$v$,然后通过decoder进行计算$y_1,\cdots,y_{T{’}}
的
概
率
,
这
里
的
初
始
隐
藏
层
设
置
为
向
量
的概率,这里的初始隐藏层设置为向量
的概率,这里的初始隐藏层设置为向量v$:
p
(
y
1
,
⋯
,
y
T
′
∣
x
1
,
⋯
,
x
T
)
=
Π
t
=
1
T
′
p
(
y
t
∣
v
,
y
1
,
⋯
,
y
t
−
1
)
(2)
p(y_1,\cdots,y_{T^{'}}|x_1,\cdots,x_T) = \Pi^{T^{'}}_{t=1}p(y_t|v,y_1,\cdots,y_{t-1})\tag{2}
p(y1,⋯,yT′∣x1,⋯,xT)=Πt=1T′p(yt∣v,y1,⋯,yt−1)(2) 在这个方程中,每个
p
(
y
t
∣
v
,
y
1
,
⋯
,
y
t
−
1
)
p(y_t|v,y_1,\cdots,y_{t-1})
p(yt∣v,y1,⋯,yt−1)为一个softmax函数。 Sutskever等人在实际建模中有三点与上述描述不同: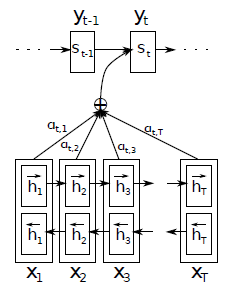
【本文地址】