| CVPR2021 | 您所在的位置:网站首页 › 基于transformer的预测金额 › CVPR2021 |
CVPR2021
|
点击上方“迈微AI研习社”,选择“星标★”公众号 重磅干货,第一时间送达
今天分享的论文是之前《CVPR2021快报!目标检测和语义分割论文分类汇总 | 源码》中收录的第六篇。
链接:https://arxiv.org/pdf/2011.14503.pdf 摘要 视频实例分割(VIS)是一项需要同时对视频中感兴趣的对象实例进行分类、分割和跟踪的任务。最近研究人员提出了一个新的基于Transformers的视频实例分割框架VisTR,它将VIS任务看作一个直接的端到端并行序列解码/预测问题。给定一个由多个图像帧组成的视频片段作为输入,VisTR直接输出视频中每个实例的掩码序列。其核心是一种新的、有效的instance sequence匹配与分割策略,它在序列级对实例进行整体监控和分割。VisTR从相似性学习的角度对实例进行分割和跟踪,大大简化了整个流程,与现有方法有很大的不同。 VisTR在现有的VIS模型中速度最高,在YouTubeVIS数据集上使用单一模型的方法中效果最好。这是第一次,研究人员展示了一个更简单,更快的视频实例分割框架建立在Transformer,实现了竞争的准确性。研究人员希望VisTR能推动未来更多的视频理解任务的研究。 研究贡献 • 研究人员提出了一个新的基于Transformers的视频实例分割框架,称为VisTR,它将VIS任务视为一个直接的端到端并行序列解码/预测问题。该框架与现有方法大不相同,大大简化了整个流程。 • VisTR从相似性学习的新角度解决了VIS。实例分割就是学习像素级的相似度,实例跟踪就是学习实例之间的相似度。因此,在相同的实例分割框架下,可以无缝、自然地实现实例跟踪。 • VisTR成功的关键是为研究人员的框架定制了一种新的instance sequence匹配和分割策略。这个精心设计的2策略使研究人员能够在整个序列级别上对实例进行监控和分段。 • VisTR在YouTube VIS数据集上取得了很好的效果,在mask mAP中以27.7 FPS的速度(如果排除数据加载,则为57.7 FPS)获得了35.3%的效果,这是使用单一模型的方法中最好、最快的。
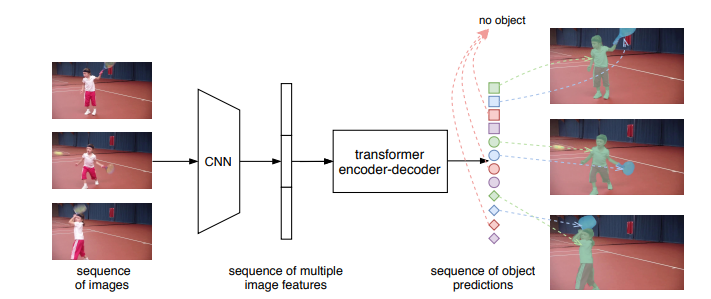
图1:Overall pipeline of VisTR 该模型将一系列图像作为输入,并输出一系列实例预测。此处,相同的形状表示一幅图像中的预测,而相同的颜色表示同一对象实例的预测。请注意,整体预测遵循输入帧的顺序,并且不同图像的对象预测的顺序保持相同(屏幕上最佳观看)。 研究思路 研究人员将视频实例分割问题建模为一个直接的序列预测问题。给定由多个图像帧组成的视频片段作为输入,VisTR按顺序输出视频中每个实例的掩码序列。为了实现这一目标,研究人员引入了instance sequence匹配和分割策略,在序列级对实例进行整体监控和分割。
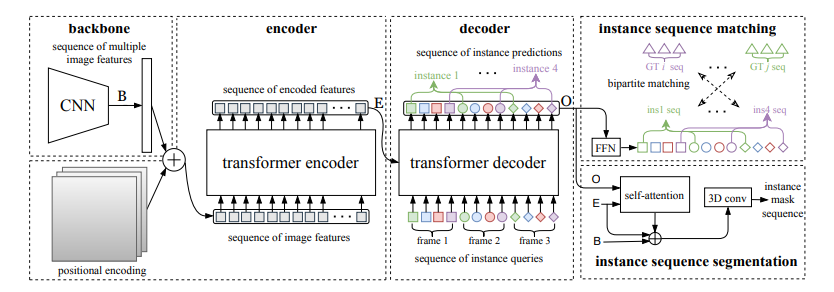
图2:The overall architecture of VisTR 它包含四个主要组件:1)CNN主干,提取多个图像的特征表示;2)编码器-解码器Transformer,其对像素级特征的关系进行建模并对实例级特征进行解码;3)监督模型的实例序列匹配模块;4)实例序列分割模块,其输出最终的掩模序列(在屏幕上最佳观看)。 VisTR架构 整个VisTR架构如上图所示。它由四个主要部分组成:一个用于提取多帧压缩特征表示的CNN backbone、一个用于建立像素级相似性建模的编码-解码的transformer、一个用于监控模型的instance sequence matching模块和一个instance sequence segmentation模块。 1)Backbone:Backbone提取输入视频片段的原始像素级特征序列,提取每一帧的特征并将所有的特征图联系在一起。 2)Transformer encoder:采用编码器对图像中所有像素级特征的相似性进行建模,建模视频内每一个像素之间的相似性。首先使用11的卷积对输入的特征图张量进行降维。然后对特征图从空间和时间上展平到一维。 3)Temporal and spatial positional encoding:Transformer的结构是排列不变的,而分割任务需要精确的位置信息。为了补偿这一点,研究人员用固定的位置编码信息来补充特征,这些信息包含三维(时间、水平和垂直)位置信息,然后再关联在一起。
4)Transformer decoder:Transformer解码器的目标是解码能够代表每帧实例的像素特征。受DETR的启发,研究人员还引入了固定数量的输入嵌入来从像素特征中查询实例特征,称为instance queries。这些instance queries是通过模型学习得到的。编码器的输入为预设的instance queries和编码器的输出。这样,预测的结果按照原始视频帧序列的顺序输出,输出为nT个instance向量,即学习到的instance queries。 Instance Sequence Matching: VisTR在一次通过解码器的过程中推断出N个预测的固定大小序列。该框架的主要挑战之一是保持同一实例在不同图像(即instance sequence)中预测的相对位置。为了找到相应的ground truth并对instance sequence进行整体监控,引入了instance sequence匹配策略。 解码器输出的固定个数的预测序列是无序的,每一帧包含n个instance sequence。本论文和DETR相同,利用匈牙利算法进行匹配。ViTR采用了和DETR类似的方法,虽然是实例分割,但需要用到目标检测中的bounding box方便组合优化计算。通过FFN,即全连接计算出归一化的bounding box中心,宽和高。通过softmax计算出该bounding box的标签。最后得到n×T个bounding box。利用上述得到label概率分布和bounding box匹配instance sequence和gournd truth。
最后计算匈牙利算法的loss,同时考虑label的概率分布以及bounding box的位置。Loss基本遵循DETR的设计,使用L1 loss和IOU loss。下式为训练用的loss。由label,bounding box,instance sequence三者的loss组成。
Instance Sequence Segmentation: Instance sequence分割模块的目标是预测每个实例的掩码序列。为了实现这一点,该模型首先对每个实例进行mask features的积累,然后对积累的特征进行掩模序列分割。 通过计算对象预测O和Transformer编码特征E之间的相似度映射得到mask features。为了简化计算,研究人员只对每个对象预测使用其对应帧的特征进行计算。对于每一帧,对象预测O和相应的编码特征映射E被馈送到模块中以获得初始attention maps。然后attention maps将与对应帧的初始backbone的特征B和变换后的编码特征E融合,遵循与DETR类似的实践。融合的最后一层是可变形卷积层。通过这种方式,获得不同帧的每个实例的mask features。
实验 在本节中,研究人员在YouTubeVIS[30]数据集上进行实验,该数据集包含2238个训练、302个验证和343个测试视频剪辑。数据集的每个视频都用每像素分割掩码、类别和实例标签进行注释。对象类别号为40。当测试集评估结束时,研究人员在验证集中评估研究人员的方法。评价指标为平均精度(AP)和平均召回率(AR),以mask sequences的视频交集为阈值。 在下表中,研究人员将VisTR与一些最新的视频实例分割方法进行了比较。从精度和速度两方面进行了比较。前三行中的方法最初用于跟踪或VOS。研究人员引用了其他研究中针对VIS的重新实现所报告的结果。其他方法包括MaskTrack RCNN、MaskProp和STEmSeg最初是按时间顺序为VIS任务提出的。
下图显示了YouTube VIS验证数据集上VisTR的可视化,每一行包含从同一视频中采样的图像。VisTR可以很好地跟踪和分割具有挑战性的实例,例如:(a)实例重叠,(b)实例之间相对位置的变化,(c)由相近的同类实例引起的混淆和(d)不同姿势的实例。
图3:YouTube-VIS [30]验证数据集上的VisTR可视化。每行包含来自同一视频的图像。对于每个视频,此处相同的颜色表示相同实例的遮罩序列(最好在屏幕上观看)。 总结 本文提出了一种基于Transformers的视频实例分割框架,将VIS任务看作一个直接的端到端并行序列解码/预测问题。VisTR从相似性学习的新角度解决了VIS问题。因此,在相同的实例分割框架下,可以无缝、自然地实现实例跟踪。该框架与现有方法大不相同,也比现有方法简单,大大简化了整个流程。通过大量的实验来研究和验证VisTR的核心因素。在YouTube-VIS数据集上,VisTR在使用单一模型的方法中取得了最好的结果和最高的速度。据研究人员所知,研究人员的工作是第一个将Transformer应用于视频实例分割。研究人员希望类似的方法可以应用到更多的视频理解任务中。 预告下一篇将会发布一篇详细的Transformer模型综述,其在学界和工业界都有着十分的热度。 在NLP领域transformer已经是成功地取代了RNN(LSTM/GRU),在CV领域也出现了应用,比如目标检测和图像加注,还有RL领域。 -->Google综述:细数Transformer模型的17大高效变种推荐阅读 (点击标题可跳转阅读) 详解Transformer (Attention Is All You Need) Transformer有可能替代CNN吗?未来有哪些研究方向?听听大家都怎么说 CV和NLP通吃!谷歌提出OmniNet:Transformers的全方位表示 CVPR 2021 Oral | Transformer再发力!华南理工和微信提出UP-DETR:无监督预训练检测器
© THE END 转载请联系本公众号获得授权 投稿或寻求报道:[email protected]
|


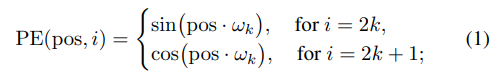

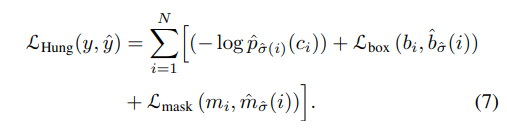




【本文地址】