| 【大数据】用Spark进行用户行为分析 | 您所在的位置:网站首页 › 基于spark网站用户行为分析方法 › 【大数据】用Spark进行用户行为分析 |
【大数据】用Spark进行用户行为分析
|
目录
1.文件下载
2.上传文件
3.数据预处理
4.用Spark RDD操作、Spark SQL DataFrame操作和SQL语句三种方法完成以下数据分析。
1.文件下载
数据
淘宝用户购物行为数据集 https://tianchi.aliyun.com/dataset/649
完整数据文件UserBehavior.csv,3.42G https://pan.baidu.com/s/1Y_RKr_Dw2dcnUJR4m3LHzw 提取码:p8gz
小测试文件 UserBehaviorSmall.csv 18M https://pan.baidu.com/s/1CpiGrNSGkA0KVLxxmVcg8Q 提取码:hnaq
缩减版数据 https://pan.baidu.com/s/1WEtY1aDrlsTz5dntKNjkqA 提取码:onaz
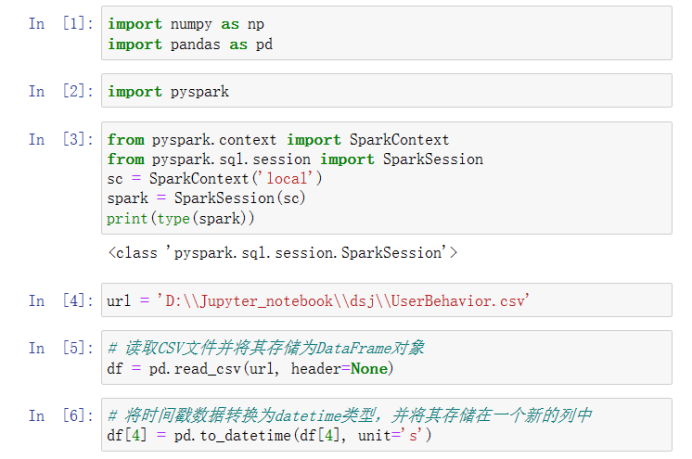
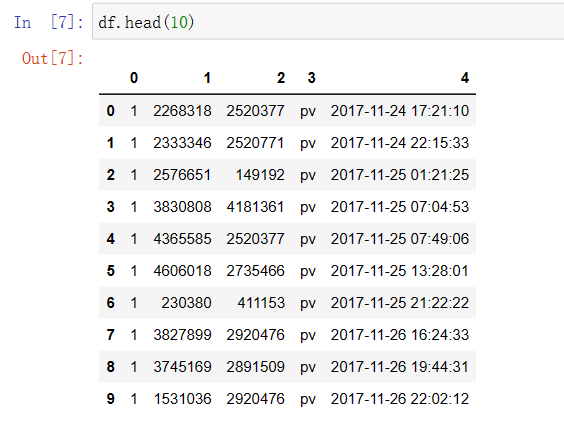
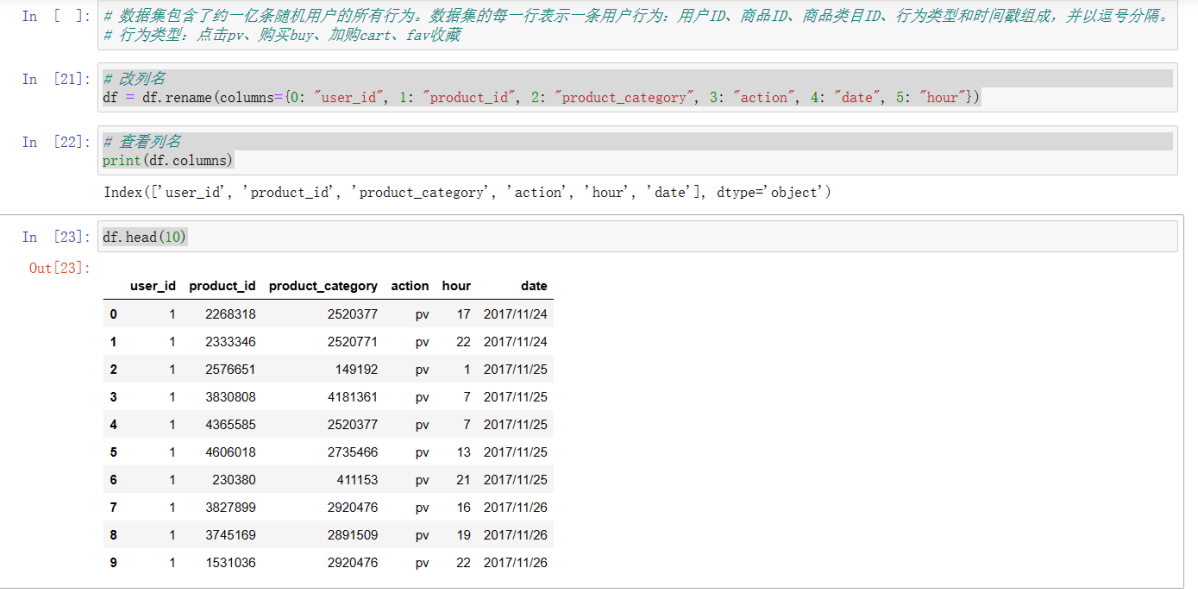
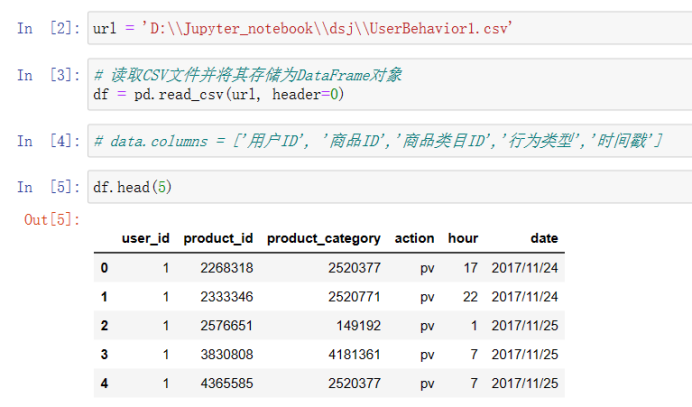
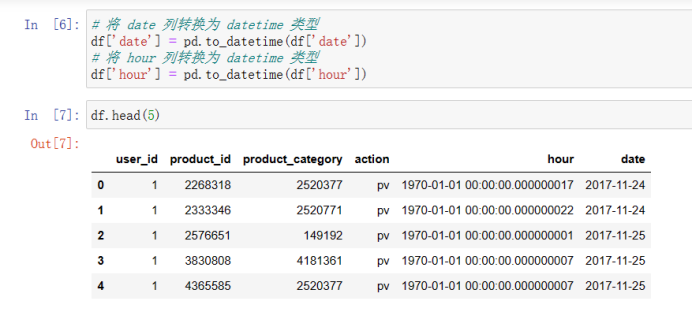
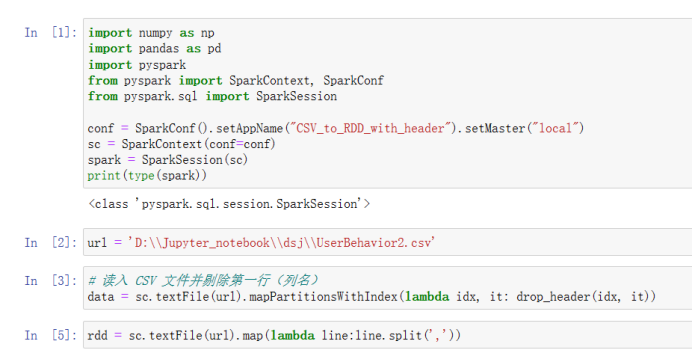
数据集包含了约一亿条随机用户的所有行为: 数据集的每一行表示一条用户行为:用户ID、商品ID、商品类目ID、行为类型和时间戳组成,并以逗号分隔。 行为类型:点击pv、购买buy、加购cart、fav收藏 操作代码: 用Spark进行用户行为分析 可以点击上面这个链接直接下载代码,我分了4个代码文件,按照我写的注意事项进行操作即可。本文是记录我学习pyspark操作小实验,仅供参考,欢迎指正与讨论! 2.上传文件下载好文件并且上传到虚拟机: 由于本人虚拟机运行不了大文件,所以改用jupyter notebook: 1)原始文件时间戳数据转换为datetime类型,能按日期和时间进行查找。 import numpy as np import pandas as pd import pyspark from pyspark.context import SparkContext from pyspark.sql.session import SparkSession sc = SparkContext('local') spark = SparkSession(sc) print(type(spark)) url = 'D:\\Jupyter_notebook\\dsj\\UserBehavior.csv' # 读取CSV文件并将其存储为DataFrame对象 df = pd.read_csv(url, header=None) # 将时间戳数据转换为datetime类型,并将其存储在一个新的列中 df[4] = pd.to_datetime(df[4], unit='s') df.head(10)
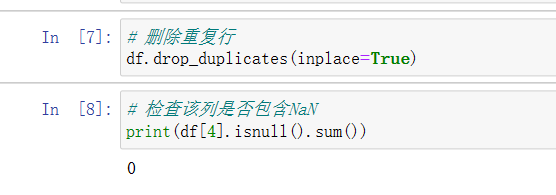
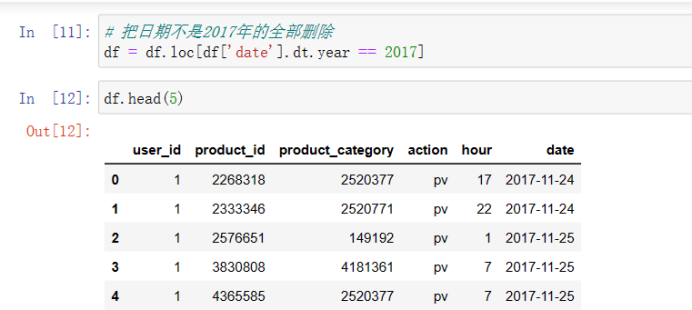
2)删除不正常数据(例如日期不是2017年的) # 删除重复行 df.drop_duplicates(inplace=True) # 检查该列是否包含NaN print(df[4].isnull().sum())
新建一个文件,处理刚才存下来的新文件
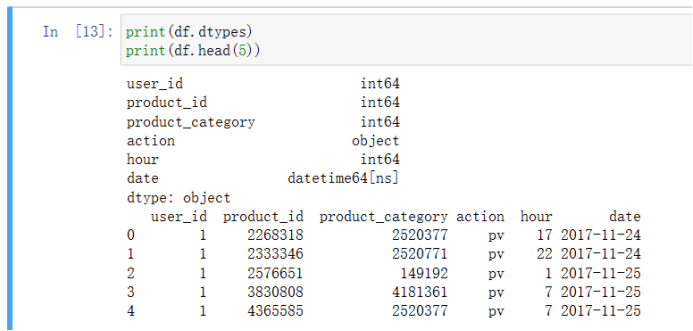
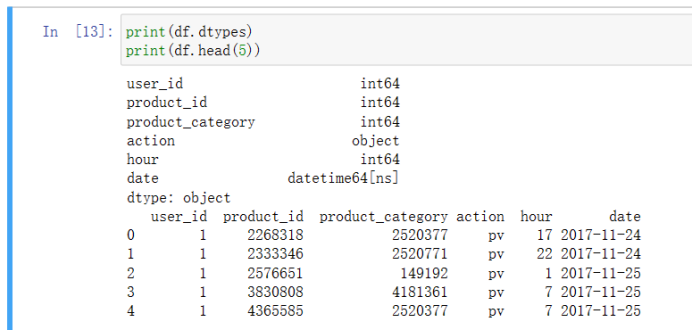
3)字段解析 print(df.dtypes) print(df.head(5))
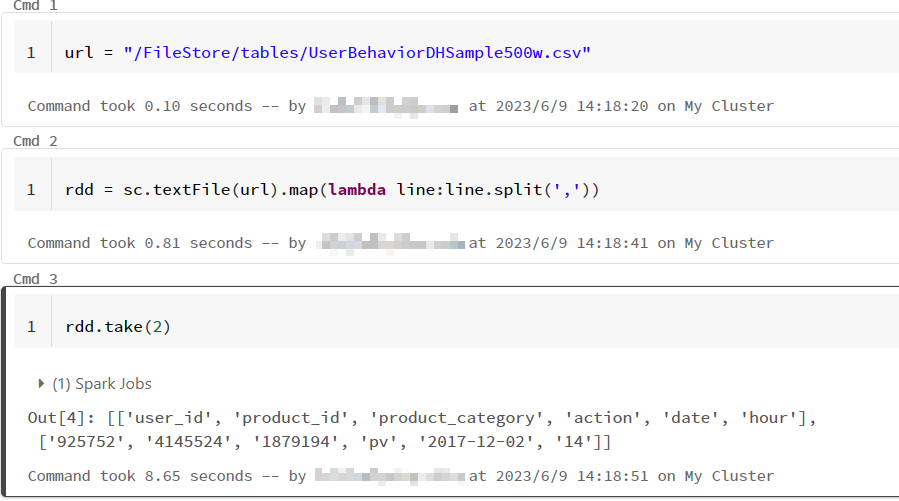
4)生成RDD rdd = sc.textFile(url).map(lambda line:line.split(','))
由于notebook运行rdd的时候报错了,所以后面所有rdd相关操作都用databricks运行,而DF和sparkSQL语句则用notebook,因为用虚拟机的时候崩溃了
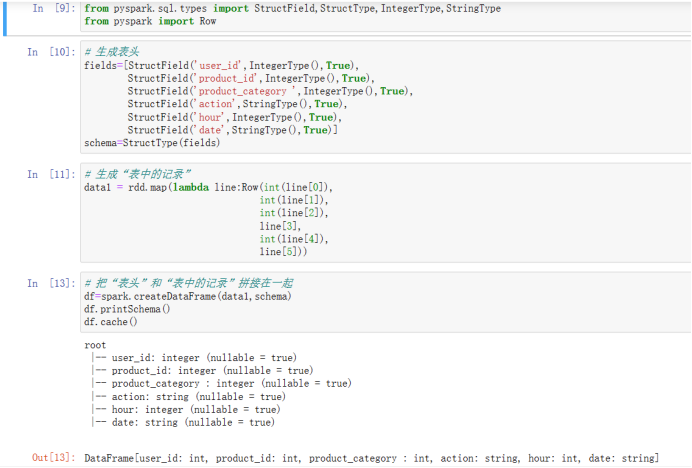
5)生成DataFrame 第一种 from pyspark.sql.types import StructField,StructType,IntegerType,StringType from pyspark import Row # 生成表头 fields=[StructField('user_id',IntegerType(),True), StructField('product_id',IntegerType(),True), StructField('product_category ',IntegerType(),True), StructField('action',StringType(),True), StructField('hour',IntegerType(),True), StructField('date',StringType(),True)] schema=StructType(fields) # 生成“表中的记录” data1 = rdd.map(lambda line:Row(int(line[0]), int(line[1]), int(line[2]), line[3], int(line[4]), line[5])) # 把“表头”和“表中的记录”拼接在一起 df=spark.createDataFrame(data1,schema) df.printSchema() df.cache() df.createOrReplaceTempView("scs")
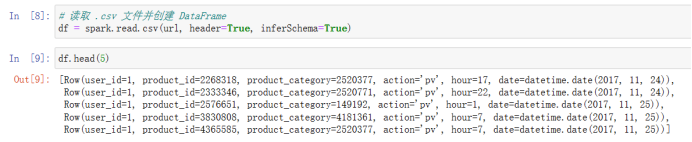
第三种 # 读取 .csv 文件并创建 DataFrame df = spark.read.csv(url, header=True, inferSchema=True)
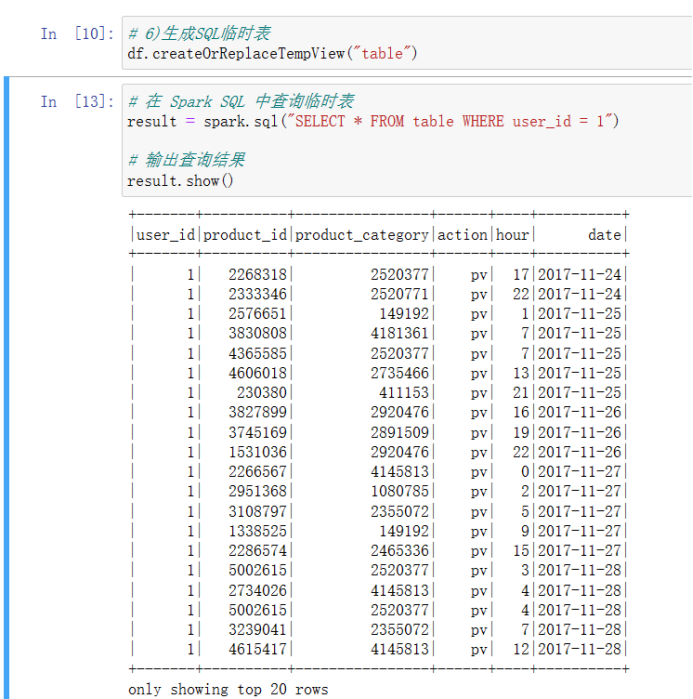
6)生成SQL临时表 df.createOrReplaceTempView("table") # 在 Spark SQL 中查询临时表 result = spark.sql("SELECT * FROM table WHERE user_id = 1") # 输出查询结果 result.show()
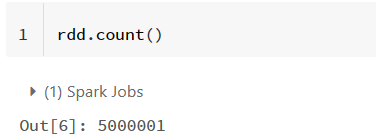
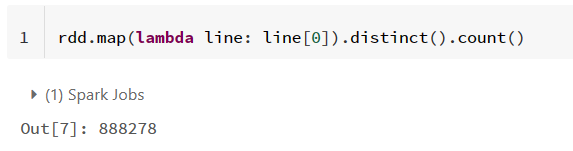
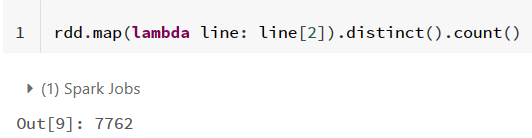
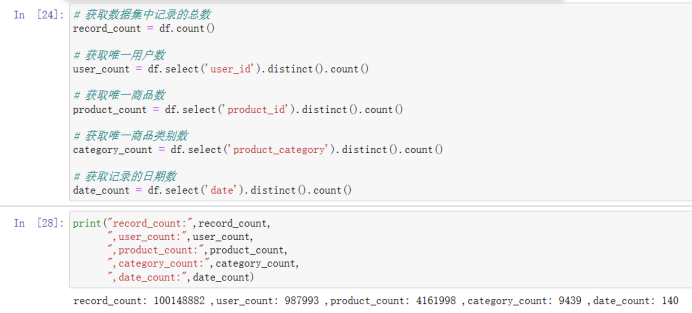
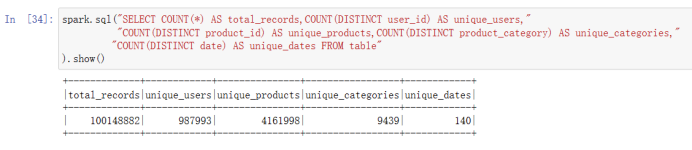
1)数据整体概况:数据集中有多少条记录,有多少个用户,有多少件商品,有多少个商品类别,记录了多少个日期的数据。
2)人均点击次数(总点击量pv/点击用户数) (1)rdd操作: # 2)人均点击次数(总点击量pv/点击用户数) # 过滤出所有 action 为 pv 的记录,并提取出 user_id 字段 pv_rdd = rdd.filter(lambda x: x[3] == 'pv').map(lambda x |
 由于本人电脑内存不足,所以到这里先把前面处理好的数据保存到本地,不然电脑会崩溃
由于本人电脑内存不足,所以到这里先把前面处理好的数据保存到本地,不然电脑会崩溃
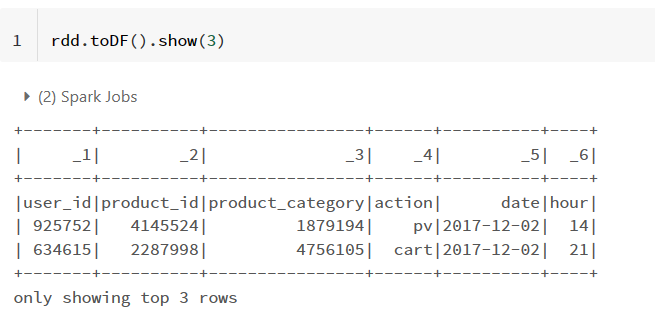
 第二种
第二种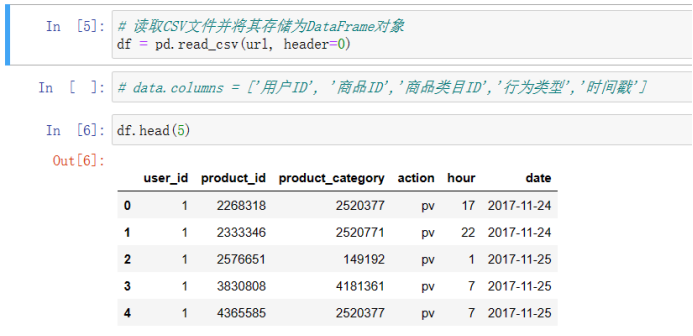


【本文地址】
公司简介
联系我们