| Python爬取京东书籍信息(包括书籍评论数、简介等) | 您所在的位置:网站首页 › 图书详情页代码 › Python爬取京东书籍信息(包括书籍评论数、简介等) |
Python爬取京东书籍信息(包括书籍评论数、简介等)
|
Python爬取京东书籍信息(包括书籍评论数、简介等)
一. 工具二. 准备爬取的数据三. 内容简述四. 页面分析(一) 寻找目录中商品所在标签(二) 寻找页面中能爬取到的所有数据(三) 寻找评论数所在链接(四) 寻找书籍简介所在链接
五. 代码整合
一. 工具
PyCharmScrapyChrome浏览器
二. 准备爬取的数据
items.py import scrapy class JdbookItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() book_id = scrapy.Field() #书籍ID book_name = scrapy.Field() #书名 author = scrapy.Field() #作者 Publishing_house = scrapy.Field() #出版社 price = scrapy.Field() #价格 book_url = scrapy.Field() #书籍链接 comment_num = scrapy.Field() #评论数 cover_url = scrapy.Field() #封面链接 book_content = scrapy.Field() #书籍简介 pass 三. 内容简述 这里以爬取python书籍为例,因此以python书籍页面链接为base_url。若想要爬取其他书籍,可手动更改base_url,或者利用keword关键字构造链接模拟搜索功能书名、价格等基本信息可以在目录页面处爬取,但是评论数、书籍简介无法直接从目录页面爬取,因此需进一步寻找并构造链接这里有两点需要注意: 在目录页面中无法直接找到访问下一页的链接可以从目录页面中得到单一书籍的链接,但无法通过访问该链接直接爬取书籍的详细信息 四. 页面分析 (一) 寻找目录中商品所在标签先在京东的商品界面选择分类:图书→计算机与网络→编程语言与程序设计→python。 然后鼠标右键选“检查”,在点击左上角形似鼠标的图标 然后点击页面任意处,即可索引到点击处所在的标签。例如,我们点击第一本书的图片,会自动索引到该书籍图片与其封面图片所在位置 现在我们需要寻找其他的数据分别都在哪些标签下,然后直接提取即可。 寻找其他能够直接在目录页面下爬取的数据时,步骤与上述寻找书籍封面图片链接的步骤完全一致。 可以提取到的字段有:出版社、作者、 书籍ID 、书名、书的链接(提取后需要拼接)、封面图片链接、价格。 注: 书籍的ID在后续爬取书籍评论数和简介时需要用来拼接链接。 注: 由于要我们模拟翻页更能,所以构造链接base_url时需要有page关键字。在第一页时,链接是这样的: 后面的部分可以不要,没什么影响。 jd_spiders.py # -*- coding: utf-8 -*- from jingdong.items import JdbookItem from scrapy import Request from scrapy.spiders import Spider import json import re class JdbookerSpider(Spider): name = 'jdbooker' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36', } def start_requests(self): base_url = 'https://list.jd.com/list.html?cat=1713%2C3287%2C3797&ev=2563_22814%5E&page=' for page in range(1, 8): url = base_url + str(page) yield Request(url, callback=self.parse, headers=self.headers) def parse(self, response): #取出该ul标签下的所有li标签,及所有商品标签 books = response.xpath('//ul[@class="gl-warp clearfix"]/li') for book in books: item1 = JdbookItem() item1['book_id'] = book.xpath('./@data-sku').extract_first() item1['book_name'] = book.xpath('.//div[@class="p-name"]/a/em/text()').extract_first() #若存在作者 if book.xpath('.//div[@class="p-bookdetails"]/span[@class="p-bi-name"]/text()'): item1['author'] = book.xpath('.//div[@class="p-bookdetails"]/span[@class="p-bi-name"]/a[1]/text()').extract()[0] else: item1['author'] = '/' #若存在出版社 if book.xpath('.//div[@class="p-bookdetails"]/span[@class="p-bi-store"]/text()'): item1['Publishing_house'] = book.xpath('.//div[@class="p-bookdetails"]/span[@class="p-bi-store"]/a[1]/text()').extract()[0] else: item1['Publishing_house'] = '/' item1['price'] = book.xpath('.//div[@class="p-price"]/strong/i/text()').extract() item1['cover_url'] = book.xpath('.//div[@class="p-img"]/a/img/@src').extract_first() #无法通过该书籍链接进行详细信息的进一步爬取,应该是京东反爬所致 item1['book_url'] = 'http:' + book.xpath('.//div[@class="p-name"]/a/@href').extract_first() #利用书籍的ID构造获取书籍评论数的链接 url = "http://club.jd.com/clubservice.aspx?method=GetCommentsCount&referenceIds=" + str(item1['book_id']) yield Request(url, meta={'item': item1}, callback=self.parse_getCommentnum, headers=self.headers) (三) 寻找评论数所在链接这里提一下,其实本来我们是可以在目录也下找到书籍评论数所在的标签位置的,但是提取的时候却发现为空,这应该是因为评论数是动态加载的,所以无法直接获取。 还有另一点,其实我们之前已经爬到了每本书的详情链接,但是也无法直接通过该链接进入页面爬取书籍的详情,因为页面是动态加载的。 接下来我们先进入详情页面分析,右键→检查→Network→JS,然后刷新一下页面,接着→随便点一个文件→Preview。 打开链接看文本是怎么样的,然后上代码: 注: 这里又利用书籍ID构造获取书籍简介的链接,进行下一步的请求。 (四) 寻找书籍简介所在链接接着依旧是类似(三)的步骤,不过这次是在Response中看,因为Preview里面不把鼠标移过去看不到简介内容: 打开链接发现需要将文本头尾的部分去掉,并将其转换为字典形式,匹配出关键字"content"对应的部分之后(该步骤也可省略,直接用正则表达式提取简介即可),此部分文本为html格式的字符串,即可用正则表达式提取出内容简介(图中深色部分): 这里给出提取书籍简介的代码: jd_spiders.py def parse_getContent(self, response): item1 = response.meta['item'] text = response.text #取出rexponse的文本 text1 = text[9:-1] #去掉文本字符串头尾的多余部分 js = json.loads(text1) #将剩余的字符串转化为字典形式 content = js['content'] #提取出关键字content对应的文本 # Selector(text=content)将字符串形式的content转化为html形式,以便用xpath()提取文本 # 判断标签div[@class="book-detail-content"]下是否有p标签,有则进 if Selector(text=content).xpath('.//div[@class="book-detail-content"]/p/text()').extract_first(): introduction = Selector(text=content).xpath('.//div[@class="book-detail-content"]/p/text()').extract_first() else: introduction = Selector(text=content).xpath('.//div[@class="book-detail-content"]/text()').extract_first() # 这里有一个问题就是部分数据的简介页面数据很杂,标签div[@class="book-detail-content"]下除了p标签外还有br标签等,无法有效提取 # 在xpath()里面用//text()也达不到提取效果,害 希望有人能够突破一下 introduction = introduction.strip() # 去掉字符串开头或结尾的空格 if introduction: item1['book_content'] = introduction else: #若未提取到书籍简介 item1['book_content'] = '/' return item1 五. 代码整合items.py import scrapy class JdbookItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() book_id = scrapy.Field() #书籍ID book_name = scrapy.Field() #书名 author = scrapy.Field() #作者 Publishing_house = scrapy.Field() #出版社 price = scrapy.Field() #价格 book_url = scrapy.Field() #书籍链接 comment_num = scrapy.Field() #评论数 cover_url = scrapy.Field() #封面链接 book_content = scrapy.Field() #书籍简介 passjd_spiders.py # -*- coding: utf-8 -*- from jingdong.items import JdbookItem from scrapy import Request from scrapy.spiders import Spider import json import re class JdbookerSpider(Spider): name = 'jdbooker' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36', } def start_requests(self): base_url = 'https://list.jd.com/list.html?cat=1713%2C3287%2C3819&page=' for page in range(1, 8): url = base_url + str(page) yield Request(url, callback=self.parse, headers=self.headers) def parse(self, response): #取出该ul标签下的所有li标签,及所有商品标签 books = response.xpath('//ul[@class="gl-warp clearfix"]/li') for book in books: item1 = JdbookItem() item1['book_id'] = book.xpath('./@data-sku').extract_first() item1['book_name'] = book.xpath('.//div[@class="p-name"]/a/em/text()').extract_first() #若存在作者 if book.xpath('.//div[@class="p-bookdetails"]/span[@class="p-bi-name"]/text()'): item1['author'] = book.xpath('.//div[@class="p-bookdetails"]/span[@class="p-bi-name"]/a[1]/text()').extract()[0] else: item1['author'] = '/' #若存在出版社 if book.xpath('.//div[@class="p-bookdetails"]/span[@class="p-bi-store"]/text()'): item1['Publishing_house'] = book.xpath('.//div[@class="p-bookdetails"]/span[@class="p-bi-store"]/a[1]/text()').extract()[0] else: item1['Publishing_house'] = '/' item1['price'] = book.xpath('.//div[@class="p-price"]/strong/i/text()').extract() item1['cover_url'] = book.xpath('.//div[@class="p-img"]/a/img/@src').extract_first() #无法通过该书籍链接进行详细信息的进一步爬取,应该是京东反爬所致 item1['book_url'] = 'http:' + book.xpath('.//div[@class="p-name"]/a/@href').extract_first() #利用书籍的ID构造获取书籍评论数的链接 url = "http://club.jd.com/clubservice.aspx?method=GetCommentsCount&referenceIds=" + str(item1['book_id']) yield Request(url, meta={'item': item1}, callback=self.parse_getCommentnum, headers=self.headers) def parse_getCommentnum(self, response): item1 = response.meta['item'] # response.text取出response的文本 # json.loads(str)可以将str转化为字典形式 js = json.loads(str(response.text)) # 取出js中的评论数 item1['comment_num'] = js['CommentsCount'][0]['CommentCount'] #利用书籍的ID构造获取书籍简介的链接 content_url = 'https://dx.3.cn/desc/' + str(item1['book_id']) + '?encode=utf-8&cdn=2&callback=showdesc' yield Request(content_url, meta={'item': item1}, callback=self.parse_getContent, headers=self.headers)这部分代码本来应该写在上面的JdbookerSpider类里面,但是发现代码太长的话手机端显示不全,没办法所以把这个函数写在下面。 jd_spiders.py def parse_getContent(self, response): item1 = response.meta['item'] text = response.text #取出rexponse的文本 text1 = text[9:-1] #去掉文本字符串头尾的多余部分 js = json.loads(text1) #将剩余的字符串转化为字典形式 content = js['content'] #提取出关键字content对应的文本 #剔除一些无用的html文本标签 content = re.sub('||||||', '', content) #正则表达式匹配书籍的内容简介 book_content = re.findall('.*?>内容简介 |

 于是我们便找到了书籍封面链接所在的位置,即 div class=“p-img” 标签下的 a 标签下的 img 标签的 src 属性内,后面直接爬取即可。 接下来我们往下拉,发现一列有规律的li标签
于是我们便找到了书籍封面链接所在的位置,即 div class=“p-img” 标签下的 a 标签下的 img 标签的 src 属性内,后面直接爬取即可。 接下来我们往下拉,发现一列有规律的li标签  于是我们回到上面将第一个打开的li标签收起来,发现所有的li标签都在该ul标签下
于是我们回到上面将第一个打开的li标签收起来,发现所有的li标签都在该ul标签下 而每一本书所能够提取的数据全部藏在它的li标签下,所以后续我们可直接提取该ul标签下的li标签列
而每一本书所能够提取的数据全部藏在它的li标签下,所以后续我们可直接提取该ul标签下的li标签列 我们还不确定怎么加上page关键字,没关系,我们手动点击下一页,发现链接变成这样:
我们还不确定怎么加上page关键字,没关系,我们手动点击下一页,发现链接变成这样:  好了,现在可以得到base_url是:https://list.jd.com/list.html?cat=1713%2C3287%2C3797&ev=2563_22814%5E&page=
好了,现在可以得到base_url是:https://list.jd.com/list.html?cat=1713%2C3287%2C3797&ev=2563_22814%5E&page= 接下来就得下苦功夫了,一个文件一个文件找,最终发现我们要的评论数comment_num在这个文件夹里:
接下来就得下苦功夫了,一个文件一个文件找,最终发现我们要的评论数comment_num在这个文件夹里: 
 查看他的request(请求)链接的形式
查看他的request(请求)链接的形式  链接为:
链接为: 再打开两本书的页面找到这个链接,分别为:
再打开两本书的页面找到这个链接,分别为: 
 发现规律:其实这里的referenceIds关键字就是前面爬取到的书籍的ID,而referenceIds关键字后面的其实是多余部分,丢弃之后发现没影响。构造链接的代码在上一块代码末尾。
发现规律:其实这里的referenceIds关键字就是前面爬取到的书籍的ID,而referenceIds关键字后面的其实是多余部分,丢弃之后发现没影响。构造链接的代码在上一块代码末尾。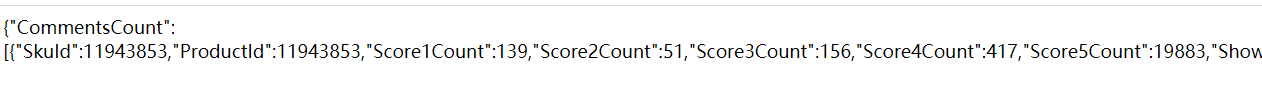 jd_spiders.py
jd_spiders.py 找到文件所在位置:
找到文件所在位置:  接着观察链接形式:
接着观察链接形式:  链接为:
链接为:  同样是多打开几本书,并找到该链接来观察链接形式
同样是多打开几本书,并找到该链接来观察链接形式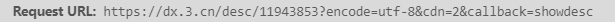
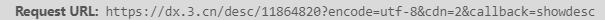 发现只有中间数字那个部分在发生改变,其实那就是前面爬取到的书籍ID,因此我们就可以构造链接了,构造链接的代码在上一块代码末尾。
发现只有中间数字那个部分在发生改变,其实那就是前面爬取到的书籍ID,因此我们就可以构造链接了,构造链接的代码在上一块代码末尾。
【本文地址】