| 机器学习 | 您所在的位置:网站首页 › 因果关系的三种类型 › 机器学习 |
机器学习
|
因果
1. 什么是因果;为什么研究因果1.1 什么是1.2 为什么研究1.3 机器学习中用到的因果推论1.4 因果性和相关性的区别Two main questionsTwo main frameworks
2. 因果研究发展2.1 因果科学2.2 统计中的因果推断2.3 因果效益估计框架
3. 因果论文综述3.1 因果推断贝叶斯网络Constraint-based Algorithms(基于约束的算法)Score-based Algorithms(基于分数的方法)FCMs-based Algorithms
3.2 DL/RL 算法论文分享
4. 因果推断书籍book1: Causal Inference: What If[2020]简介
book2: Causal Inference: THE MIXTAPE(V.1.7)[2018]简介
book3: Advanced Data Analysis from an Elementary Point of View [2017]book4: Elements of Causal Inference Foundations and Learning Algorithms[2017]简介一些用到因果关系的论文
1. 什么是因果;为什么研究因果
1.1 什么是
causality:Causality is a generic relationship between an effect and the cause that gives rise to it. 直译理解就好 1.2 为什么研究参考:因果关系的必要性 机器学习基本上可以算是统计机器学习问题,也就是通过大量的数据学习到一些隐藏的patterns,从而得到数据与数据之前的相关关系,进而进行目标检测、追踪、知识问答等处理。很自然的一个问题就是,既然机器学习当前主流是以统计规律得到的相关关系为主,那么我们为什么要研究因果关系呢? Yule-Simpson’s Paradox (辛普森悖论): 变量X和Y在边缘上存在正相关,但是给定另外变量Z,在Z的每一个水平上,X和Y都存在负相关。举例来说,某实验对人进行处理,整体来看,对人的存活率有所提升,但是将人细分男、女,却发现该处理最后的存活率均是下降。事实表明,统计规律有时并不那么靠谱,我们需要建立起数据之间的因果联系,这也是因果推理在机器学习中存在的价值。 另外在机器学习中,目前有太多深度学习项目都单纯关注缺少因果关系的粗糙关联性,这常常导致深度学习系统在真实条件下(明显不同于训练场景的条件下)进行测试时,往往拿不出良好的实际表现。 1.3 机器学习中用到的因果推论 模型可解释性 (判断模型对因果的判断与哪些因素相关)迁移学习:不同任务的迁移能力提升。如何在无监督下学到领域无关的一致性表征模型歧视问题:歧视少数族或女性。模型可以自己回答反事实的问题,判断决策公平性学习速度提升与样本需求减少:类似主动学习(人类是优秀的小样本学习器,靠观察和想象);目前的机器学习模式类似达尔文进化论的发展历程(长颈鹿花了几百万年进化出了这么长的脖子),是一个非常耗时,低效的学习过程。强AI。传统机器学习模式,是无法发展出人类的超进化论(发展出奢侈品,网红店,物联网等等)这种智能产物。 1.4 因果性和相关性的区别举个例子:如果我们发现,夏天的时候,一个冰淇淋店的电费上涨的同时冰淇淋卖的也很好,我们可以说他们互相之间有因果的关系吗?不见得,他们之间可能只是统计上的相关性,而真正给他们带来的因果性的因子叫做气温,是因为气温的上升,导致电费的增加,也是因为气温的上升,导致了冰淇淋销量的上升。这个例子很好的向我们阐述了因果性和统计相关性的区别。 Two main questions Causal discovery(因果关系挖掘): 比如研究:温度升高是否是电费增加的原因?或者在商品价格,商品转化率,商品上市时间,商品成本等几个变量之间探究一个因果图,即变量两两之间是否有因果关系?如果有,谁是因谁是果?Causal effect(因果效应推理): 比如我们已经知道温度升高是电费增加的原因,我们想知道温度从20度升至30度,会对电费带来多少增加? Two main frameworksStructural Causal Models(SCM) (结构因果机制):我们需要先得到一张因果图,然后对于因果图,我们去使用Structural Equations来描述它。 Potential Outcome Framework–: 简单来说,计算因果效应最直接的手段就是控制住所有的变量不变,只变化cause,比如把温度从20变到30度,然后直接看outcome变化,也就是直接用30度时的电费减去20度时的电费,既可以得到causal effect。HOWEVER,easier said than done!!!如果这个世界有两个平行时空,那么我们可以做这个实验,但是如果没有呢?我们知道温度不可能在同一个地方,同一个时间,即20度又30度,那么必然20度的时候,30度时的电费就叫potential outcome。而这个framework,就是相方设法从能观察到的数据中得到这个potential的结果,然后二者相减,就是我们想要的答案啦! 2. 因果研究发展知乎参考 人类在探索整个宇宙和动物行为的过程,其思维的变迁经历了漫长的过程,且因果观念的逻辑分析自科学诞生之日,就没中断过。 因果中的必要因(若非因[but for]),为后来因果推理提供强大工具(反事实推理)。贝叶斯提出的逆概率定理,认为概率现象也是主观信念程度的变化和更新,让概率也失去了客观性统计学创始人高尔顿和学生皮尔逊用相关关系取代了因果关系。Judea Pearl研究中发现统计相关性并不能取代因果性(Yule-Simpson Paradox【x与y边缘正相关,在某个变量z的每一水平上负相关】),无法处理具有共同混杂因子的变量关系,统计数据常因果颠倒(无方向性),造就伪相关,对数据要求也很高(iid),泛化性,鲁棒性都很差。 2.1 因果科学因果科学是研究因果关系或回答因果问题的学科。现代因果定义为在保证其他因素不变,改变X引起Y的改变,则X为Y的一个原因。 简单从历史上看,因果研究一般分为3类 物理学定义因果(最清晰定义的因果) 物理系统演化动力学,基于时间讨论因果 哲学定义因果 Type Causality:某原因导致什么结果,由因推果,干预主义思想(因果效应定义),用来帮助预测Actual Causality:关注事物发生的原因,由果推因,与反事实思维相关。【反事实:主要是研究“若非(but for)”,“若非“过去A事件发生,结果事件B可能不发生,常用于因果检测。】 2.2 统计中的因果推断从现实数据中提取出某些变量间的因果关系 Judea Pearl的因果信息革命提出的因果关系之梯,根据因果问题的可答性,对比了目前的机器学习(深度学习)和因果推断区别。 把任务分为递进的3类: association(what is)------关联(是什么)intervention(what if)------干预(如果是什么)counterfactuals(retrospection)------反事实(回顾)。传统机器学习(关联层)是在问你what is?,即给定属性,问你是什么的概率; 第二层(干预层)是在问what if?即,如果我对你做了什么,你会怎么样? 终极(反事实层)的当然是回答哲学反事实问题,如果我当时那样做了,会怎么样?(唱:"想回到过去,试着让故事继续“) 关联和干预区别就是seeing和doing的区别,pearl发明了do算子,既p(y|x) != p(y|do(x));反事实层是回答“若非“的问题,要求将现实世界与未发生某行为的反事实世界进行比较(假如当时我没那么做,导致这样的结果概率是什么?)。这里层层递进,高层可以回答低层的问题,反之则不行,因为不具备充足的信息。 2.3 因果效益估计框架 D.B Rubin的Rubin Causal Model (RCM) 基于Potential Outcome Framework,更加简单直观,统计和社科用的多。它设想与观测相悖情况,是一种反事实因果,被称为Experimental causality(但其一般回答干预层的问题)。因果分析步骤主要有 1. 定义问题构建粗粒化因果图 2. Do-Calculus(干预)基于概率计算效应 基于Judea Pearl的结构因果模型(SCM) Pearl提出小图灵测试是实现真正智能的必要条件(机器如何迅速访问必要信息、正确回答问题,输出因果知识)。提出因果推理引擎,以假设(图模型)、数据和Query输入,输出Estimand(基于do-calculus判断query是否可识别)、Estimate(概率估计)和Fit Indices(评估)。其中do-calculus是判断因果问题是否可解的前提,原理就是贝叶斯网络中D-seperation(图分离与概率独立等价条件,参考PRML)一般回答反事实问题需要SCM模型,由图模型(表示因果知识)、反事实和干预逻辑(形式化问题)和结构方程(链接因果知识【图模型】和因果问题【反事实和干预逻辑】的语义)组成。一般步骤为 1. abduction(基于现有事实分布【先验】p(u|e)更新图概率p(u)) 2. action(基于结构方程更新x) 3. prediction(预测反事实)统计估计的主要困难是数据缺失,如何去除数据产生的偏差(Debias)是核心主题。Pearl提出解决混杂偏差、选择偏差和迁移学习方法(数据本身特点导致) 反事实基本定律 Y x ( u ) = Y M x ( u ) Y_x(u) = Y_{M_x}(u) Yx(u)=YMx(u)将SCM和RCM联系起来,左边是反事实,M_x是干预后的模型。SCM中使用函数关系描述因果关系,避免了条件概率表示因果关系时认知论上的困难。 3. 因果论文综述 3.1 因果推断 贝叶斯网络贝叶斯网络是一个DAG(directed acyclic graph,有向无环图),然后我们可以把它当作一个概率图,也就是可以概率表达它。 这一类算法通过找到上面三种结构来构建因果图,寻找方式就是通过条件独立的检验,一般的方式都是从一个无向的全链接图出发开始寻找,通过一系列规则最终生成一个图。 两类重要假设: Conditional independence imply d-separate, vice versa条件独立意味着d-分离,反之亦然.No unobserved confounder (common cause)。没有未观察到的混杂因素(共同原因).缺点在于: 不能有unobserved confounder,这个条件即便在如今大数据的时代下,也很难满足。当然有类似IC*和FCI这种算法可以loose这个unobserved confounder的假设。所以这个缺点还好。对于上面的chain和fork,由于他们都imply a和b基于c条件独立,故称为马尔可夫等价类,而这类算法无法从马尔可夫等价类中区分出不同的DAG,即对于这类算法,他认为chain和fork是一个东西,这也意味着对于上图,a有可能是c的因,也可能是果,这显然不make sense。假设极其严格,需要非常多且高质量的数据,因为faithfulness假设使得我们只能通过conditional independence来测试,如果数据很少,有可能这些测试互相都会相斥,做起图非常困难 Score-based Algorithms(基于分数的方法)这一类算法是通过最优化一个给每个图打分的score function来找到最优的图。要想成为打分函数,其要有两个基本部分。 structural equation from candidate G’,other constraints of G’。比如学过统计的朋友们都知道BIC就是一个打分函数: 这类方法的优点是由于使用goodness of fit(适合度)替代了conditional independent,于是relax了上面的第一类假设, 但是缺点是仍然无法区分马尔可夫等价类。 另一个大的缺点是这类算法因为要找到最优的分数,就要搜索全部的图,这是一个NP-hard和NP-complete的问题,复杂度极高且容易陷入局部最优。 相关论文: GES algorithm: 一个经典的scored-based algorithm, 使用下面BDeu这个打分函数来给每个图打分。但是这个方法只要求找到一个局部最优解即可。方法使用2阶段的贪婪搜索,第一阶段只insert edges,每轮insert operator只操作可以让这个打分函数最高分的三元组,直到达到local optimum。然后第二阶段只delete edges,同理delete operator只操作可以让这个打分函数最高分的三元组,直到达到local optimum。 fGES algorithm: fast GES, 是快速版,复杂度低版的GES,有两处改变:parallelize and reorganize caching in the GES. 文章地址 FCMs-based Algorithmsfunctional causal model 不严谨的来说就是上面我提到的Structural Causal Models的图里右边那一堆function,假设我们能先得到这些function,我们就可以还原左边的图。大概就是这个思路。举个例子,对于s,d,y三个变量,如果我们通过某个算法得到了如下的等式关系,也就是一个下三角阵: 论文分享: LiNGAM: 一个最经典的FCM-based algorithm, 用于连续数据。方法最常用的是用ICA(independent component analysis)作为求解的武器,核心逻辑就是估计一个类似上图的那种strictly lower triangle matrix (下三角阵),然后这个下三角阵就得到了一个unique的causal order。但是有严格的假设,分别是如下三个假设 (a) 数据生成过程是线性的, (b) 没有观察不到的混杂因素 ( c) 扰动变量具有非零方差的非高斯分布。 这个方法还有几个优化的变体,DirectLiNGAM,LvLiNGAM,SLIM,LiNGAM-GC-UK等 文章地址 3.2 DL/RL 算法这类方法有别于上述方法,更多使用深度学习或者强化学习等思路来挖掘因果图,里面的方法其实基本是也是上面的三类,只不过他们的实现路径不太好直接去归类到其中某一类,故我们就单列一类 论文分享CGNN: AWESOME! 一个极其强大的算法。可以在如下情况下使用,can be used for multi-variable, can be used in asymmetric distribution, can be used in unobserved confounder, non-linear cases. 回忆我们刚刚提到的FCM方程,里面有一个个f,这些f我们刚刚说可以是linear也可以是nonlinear的,这里是使用神经网络作为FCM 里的f,然后用他来生成拟合的一个FCM作为拟合出来的joint distribution来approximate the real joint distribution of data,用拟合的distribution和真正的distribution之间的差距作为损失函数,网络的目标即为最小化这个损失函数。损失函数表达如下: 具体怎么实现呢?首先我们需要输入一个skeleton,就是一个先验的无向的因果图,这个图一般由专家知识得到。如果是score-based method,就会有一个搜索的策略,CGNN也是如此,他一共有3步搜索策略。 对于两两相邻的变量,通过这两个变量做一个pairwise(成对) CGNN,然后两个方向分别去训练一波,得到最优的损失,选比较小的损失作为选定的方向。于是我们就得到了两两的方向,即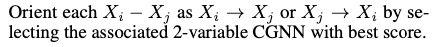 顺着目前得到图的任意一个节点,找找有没有环,有环则把他反转,这步就是保证不存在任意一个环,即 顺着目前得到图的任意一个节点,找找有没有环,有环则把他反转,这步就是保证不存在任意一个环,即  对于目前的图,不断的尝试reverse(反转)其中某个边,然后再去训练,看最后损失能不能减少,如果可以就reverse。这步一般使用hill-climbing算法。即 对于目前的图,不断的尝试reverse(反转)其中某个边,然后再去训练,看最后损失能不能减少,如果可以就reverse。这步一般使用hill-climbing算法。即 
这样就得到了最后的图,所以NN其实是在每次需要计算score的时候都训练一遍,且参数并不保留,都是重新训练。还有就是,这个方法可以处理hidden confounder,方法就是把noise作为variables也放进图里。 论文详细 SAM: recovering full causal models from continuous observational data along a multivariate non-parametric setting。也是可以处理有hidden confounder的情况。这篇文章比较骚的地方在于他提到自己不是上述任意一类的方法,他说他是一个集大成者,即用到了conditional independence如constraint-based,又做了regularization如score-based,同时又可以和CGNN,CAM等方法一样解决distributional asymmetries的问题。可见现在学术圈有多卷! 详细可以看原论文 CAUSAL DISCOVERY WITH REINFORCEMENT LEARNING: 这篇文章来自华为的诺亚实验室,他利用Reinforcement Learning (RL)来寻找得分最高的DAG. Its encoder-decoder model takes observable data as input and generates graph adjacency matrices that are used to compute rewards. It uses RL as a search strategy and its final output would be the graph, among all graphs generated during training, that achieves the best reward, is the best DAG. 使用RL作为因果挖掘的思想非常straightforward,因为在RL里的每个action可以看作是一个treatment的改变,而reward就可以是图的分数,这个思想非常好 详细可以看原论文 4. 因果推断书籍参考:因果推断书籍推荐 book1: Causal Inference: What If[2020] 简介在本书中,强调需认真地对待因果问题,并描绘数据和假设对因果推理的作用。一旦这些基础到位,因果推论必然变得不那么随意,这有助于防止混淆。这本书描述了各种数据分析方法,当收集一个群体中每个个体的数据时,这些方法可以用来估计在一组特定假设下兴趣的因果效应。这本书的一个关键信息是,因果推理不能简化为数据分析的食谱集合。在整篇文章中,穿插了详细阐述正文中提到的某些主题的要点和技术要点。精细点是为所有读者设计的,而技术点是为受过中级统计学培训的读者设计的。这本书对因果推理的概念和方法提供了一个连贯的介绍,这些概念和方法目前分散在几个学科的期刊上。我们希望对因果推理感兴趣的任何人都会对这本书感兴趣,例如流行病学家、统计学家、心理学家、经济学家、社会学家、政治学家、计算机科学家。。。 book2: Causal Inference: THE MIXTAPE(V.1.7)[2018] 简介这本书是为几个不同的人写的。它首先是写给实践者的,这就是为什么它包括易于下载的数据集和程序的原因'这也是为什么我做了几项努力来审查论文并尽可能多地复制它们。我希望读者既能理解这一领域,又能感到有能力将这些方法和技术应用到他们自己的研究问题上,我心目中的另一个人是希望重新规划的有经验的社会科学家。也许这些人有更多的理论倾向或背景,也可能是他们的人力资本存在漏洞。我希望这本书能帮助他们学习现代社会科学中常见的因果关系理论,并提供一个有向非循环图形模型的微积分,帮助他们将理论知识与计量经济学识别联系起来,不管是本科生,还是刚毕业的博士。我希望这本书能给你一个跳跃式的开始,这样你就不必像我们很多人那样,曲折地走上这些方法的迷宫。 book3: Advanced Data Analysis from an Elementary Point of View [2017]下载链接 最初是卡内基梅隆大学的36-402《高级数据分析》的笔记。 book4: Elements of Causal Inference Foundations and Learning Algorithms[2017] 简介因果关系是一个引人入胜的研究课题。它的数学化相对来说才刚刚开始,许多概念问题仍在争论中——通常激烈程度相当高。虽然这本书总结了花十年时间分析因果关系的结果,但其他人研究这个问题的时间比我们长得多,并且已经存在关于因果关系的书籍,包括Pearl [2009],Spirtes et al. [2000], and Imbens and Rubin [2015]。我们希望本书能够在两个方面补充现有的工作。首先,本书代表了对因果关系子问题的偏见,这可能被认为是最基本和最不现实的。这就是因果问题,被分析的系统只包含两个可观测值。在过去的十年里,我们对这个问题进行了较为详细的研究。我们报告了这项工作的大部分内容,并试图将其嵌入到我们认为对选择性但深刻理解因果关系问题至关重要的更大背景中。虽然先研究二元情况可能有指导意义,但按照顺序的章节顺序,也可能直接开始阅读多元章节。其次,我们的处理受到机器学习和计算统计学领域的激励和影响。我们感兴趣的是其方法如何帮助因果结构的推理,更感兴趣的是因果推理是否能告知我们应该如何进行机器学习。事实上,我们认为,如果我们不以概率分布描述的随机实验为出发点,而是考虑分布背后的因果结构,机器学习的一些最深刻的开放问题就能得到最好的理解。我们试图为熟悉概率论和统计学或机器基础的读者提供对该主题的系统介绍。 其他观看参考链接–英文书籍 参考链接—中文书籍 一些用到因果关系的论文
|
 比如对于这一张因果图,箭头由因指向果,X和E都是变量。然后右边的一系列方程就是Structural Equations来描述这个图,每一个方程f都表示着由因到果的一个映射或者说一个表达式,这个方程可以是linear也可以是nonlinear的,取决于他们的因果关系是否线性。
比如对于这一张因果图,箭头由因指向果,X和E都是变量。然后右边的一系列方程就是Structural Equations来描述这个图,每一个方程f都表示着由因到果的一个映射或者说一个表达式,这个方程可以是linear也可以是nonlinear的,取决于他们的因果关系是否线性。
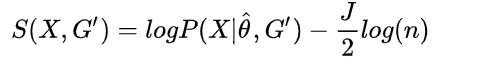 他由两部分组成,Maximize likelihood(第一项)的同时regularize graph size(第二项),正好对应了上面的两个基本部分。
他由两部分组成,Maximize likelihood(第一项)的同时regularize graph size(第二项),正好对应了上面的两个基本部分。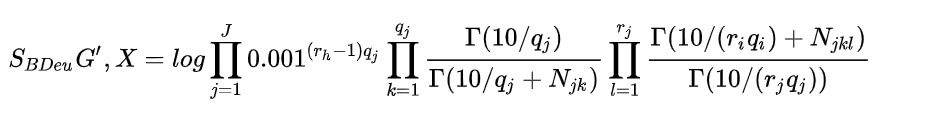 文章地址
文章地址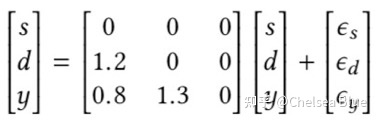 那我们可以通过它得到一个causal order,也就是一个序,比如对于s,d,y来说就是1,2,3。通过这个序,我们知道s一定在d和y前面,d一定在y前面,于是我们有下图的因果DAG
那我们可以通过它得到一个causal order,也就是一个序,比如对于s,d,y来说就是1,2,3。通过这个序,我们知道s一定在d和y前面,d一定在y前面,于是我们有下图的因果DAG 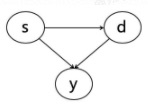 这类方法最大的优点就在于能够从马尔可夫等价类中区分出不同的DAG,从而保证有序的因果关系。
这类方法最大的优点就在于能够从马尔可夫等价类中区分出不同的DAG,从而保证有序的因果关系。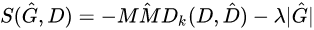 其中
∣
G
^
∣
|{\hat{G}}|
∣G^∣ 是
G
^
{\hat{G}}
G^ 的edge的个数, 另外:
其中
∣
G
^
∣
|{\hat{G}}|
∣G^∣ 是
G
^
{\hat{G}}
G^ 的edge的个数, 另外: 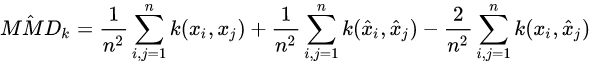 这里k就是某种核函数,衡量距离用的,MMD就是用来衡量两个分布的接近程度的,当两个分布完全一样时,MMD=0。所以大家其实可以看出来,这是一个score-based method,因为他的score function由两部分组成,一部分评估SCM的效果,一部分是对图的构造做了限制。不过这个方法理论上我理解是可以区分马尔可夫等价类的,所以也不算一般的score-based method
这里k就是某种核函数,衡量距离用的,MMD就是用来衡量两个分布的接近程度的,当两个分布完全一样时,MMD=0。所以大家其实可以看出来,这是一个score-based method,因为他的score function由两部分组成,一部分评估SCM的效果,一部分是对图的构造做了限制。不过这个方法理论上我理解是可以区分马尔可夫等价类的,所以也不算一般的score-based method
【本文地址】
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |