| 几种常用的噪声估计算法(一) | 您所在的位置:网站首页 › 噪音测试公式计算表 › 几种常用的噪声估计算法(一) |
几种常用的噪声估计算法(一)
|
一、前言 噪声估计算法就是用来估计噪声,根据估计出的噪声完成VAD和降噪。噪声估计主要是根据含噪语音的一些特点或者现象实现的。 二、噪声估计的依据 1、闭塞音闭合段(两个词之间)频段能量趋近于噪声水平;正常语音之中包含大量的短暂的安静片段,尤其是清摩擦音期间的低频段(2khz以下)和元音或者浊音(半元音、鼻音)的高频段(大于4Khz)。 2、从语谱图和基频共振峰特性来看,即使在语音活动的区域,各个频带的信噪比也是有差异的,有些频带(基频、共振峰频率)集中了语音信号,信噪比很高,在另外一些频带,带噪语音信号的功率通常会衰减到噪声的功率水平,我们因此可以追踪在短时窗内(0.4~1s)带噪语音谱每个频带的最小值,实现各个频带噪声的估计。该现象是最小值跟踪算法(the minima-tracking algorithms)的支撑点。 3、每个频带能量的直方图揭示了一个理论:出现频次最高的值对应频带的噪声水平。有时谱能量直方图有两种模式:1)低能量模式对应无声段、语音的低能量段;2)高能量模式对应含噪语音(noisy)的浊音段。低能量成分大于高能量成分: 三、噪声估计算法实现 根据以上三种现象,得出的三种最基础的噪声估计算法。实际中用的噪声估计算法都是在这三种基础的算法之上进行延伸拓展得到的。 1、分位数噪声估计(Quantile Based Noise Estimation) 参考文献:《Quantile Based Noise Estimation For Spectral Subtraction And Wiener Filtering》 假设噪声相对语音来说是平稳的,能量小的。 但是在实际应用中,尤其是在线实时系统中,不可能允许把所有的语音帧计算出排序后,再进行噪声估计。??? 下面是WebRTC_ANS里面的噪声估计代码: static void NoiseEstimation(NoiseSuppressionC *self, float *lmagn, float *noise) { size_t i, s, offset = 0; float delta; if (self->updates offset = s * self->magnLen; float norm_counter_weight = 1.f / (self->counter[s] + 1); // newquantest(...) for (i = 0; i magnLen; i++) { // Compute delta. if (self->density[offset + i] > 1.0) { delta = FACTOR / self->density[offset + i]; } else { delta = FACTOR; } // Update log quantile estimate. if (lmagn[i] > self->lquantile[offset + i]) { self->lquantile[offset + i] += QUANTILE * delta * norm_counter_weight; } else { self->lquantile[offset + i] -= (1.f - QUANTILE) * delta * norm_counter_weight; } // Update density estimate. if (fabsf(lmagn[i] - self->lquantile[offset + i]) self->counter[s] = 0; if (self->updates >= END_STARTUP_LONG) { for (i = 0; i magnLen; i++) { self->quantile[i] = expf(self->lquantile[offset + i]); } } } self->counter[s]++; } // End loop over simultaneous estimates. // Sequentially update the noise during startup. if (self->updates self->quantile[i] = expf(self->lquantile[offset + i]); } memcpy(noise, self->quantile, self->magnLen * sizeof(*noise)); } else { memcpy(noise, self->quantile, self->magnLen * sizeof(*noise)); } }2、直方图噪声估计(histogram-based noise-estimation algorithms) 直方图的噪声估计算法是基于单个频带中最频繁的能量值对应于指定频带的噪声水平的观测,即噪声级对应于能量值直方图的最大值。在某些情况下,谱能量值直方图可能包含两种模式:(a)低能量模式,对应于语音不存在和语音的低能量部分;(b)高能量模式,对应于(noisy)浊音部分的语音。在这两种模式中,前一种模式通常出现的次数最多。然而,直方图有时并不只包含一种模式,这取决于所检查的频带、所考虑的信号持续时间、噪声类型和输入信噪比。此外,由于语音频谱的低通特性,也不太可能在低频波段看到高能量模式的最大值。 算法实现: 直方图噪声估计存在两个问题: 1)Step2中的平滑因子影响噪声估计的表现,当平滑因子等于0时,就相当于最小值跟踪算法。下图是alpha=0的情形: (2)增加一个阈值,去掉能量比较大的点。 3、最小值跟踪噪声估计(the minima-tracking algorithms) 最小值跟踪算法j基于这样一个假设:即使语音,含噪语音信号在各个频段的功率往往会衰减到噪声的功率水平。通过跟踪各个频带的功率最小值,就可以得到每个频带的的噪声水平。主要有两种:1)最小值统计量算法——minimum statistics Noise estimation,在一个有限时间窗内跟踪语音功率谱的最小值; 2)连续谱最小值跟踪——continuous spectral minimum tracking,不需要分析窗就可以连续跟踪最小值。 (1)最小值统计——minimum statistics Noise estimation 针对上述问题,该算法有两种改进措施:1)推导一个偏置因子补偿; 2)平滑因子不是固定的,随时间和频率而改变。 改进措施1:推导偏置因子 Step1:计算带噪语音的短时谱; Step2:计算平滑参数alpha(时变): Step5:D帧内最小值搜索: Step6:噪声估计: (2)连续谱最小值跟踪——continuous spectral minimum tracking 如果有D帧的数据,最小值统计算法需要2D帧的延迟,即使划分V帧子窗,也要D+V的延迟(最大情况)。连续谱最小值跟踪算法主要用来减少这部分延迟。 由于只有 Pmin 涉及到延迟问题,其他操作不变。 总结: 本篇简单概括了噪声估计算法原理以及生理理论依据,并具体介绍了分位数噪声估计、直方图噪声估计和最小值跟踪噪声估计算法,由于篇幅及本人精力有限,本篇先暂时写到这。基于递归平均噪声估计算法及其衍生算法,在下一篇再进行详细介绍。 本文参考文献: 1、《Speech enhancement: theory and practice》 2、https://www.cnblogs.com/xingshansi/p/6956556.html 3、https://blog.csdn.net/golfbears/article/details/90698567 4、https://www.cnblogs.com/icoolmedia/p/noise_estimate.html 主要就是依据《Speech enhancement: theory and practice》这本书。 |
 上图(a)是scoop、purple、turquoise三个词的语音波形,(b)中实线是200Hz(低频)做出的幅值包络,虚线是6000Hz(高频)做出的幅值包络。 由于上述特性,噪声在频谱上是非均匀分布的,不同频带具有不同的SNR,例如车噪具有低频特性,高频部分受影响较小,从而高频部分提取的带噪谱可以更有效地估计和更新噪声谱。更一般地,对于任意类型噪声,只要该频带无语音的概率很高或者SNR很低,则可以估计/更新该频带的噪声谱(即在上述安静片段估计出的噪声可以认为是该频带的噪声水平),这类思想是递归平均噪声估计算法(the recursive-averaging type of noise-estimation algorithms)的支撑点。
上图(a)是scoop、purple、turquoise三个词的语音波形,(b)中实线是200Hz(低频)做出的幅值包络,虚线是6000Hz(高频)做出的幅值包络。 由于上述特性,噪声在频谱上是非均匀分布的,不同频带具有不同的SNR,例如车噪具有低频特性,高频部分受影响较小,从而高频部分提取的带噪谱可以更有效地估计和更新噪声谱。更一般地,对于任意类型噪声,只要该频带无语音的概率很高或者SNR很低,则可以估计/更新该频带的噪声谱(即在上述安静片段估计出的噪声可以认为是该频带的噪声水平),这类思想是递归平均噪声估计算法(the recursive-averaging type of noise-estimation algorithms)的支撑点。 但这个现象并不是一成不变,实验验证得出了结论:通常低频具有双峰分布,中频-高频为单峰。以上现象,频带能量直方图最大值对应频带的噪声水平,这是直方图噪声估计算法(histogram-based noise-estimation algorithms)的支撑点。
但这个现象并不是一成不变,实验验证得出了结论:通常低频具有双峰分布,中频-高频为单峰。以上现象,频带能量直方图最大值对应频带的噪声水平,这是直方图噪声估计算法(histogram-based noise-estimation algorithms)的支撑点。 分位数噪声估计的想法是建立这样一个共识,即使是语音段,输入信号在某些频带分量也可能没有信号能量。那么假设将某个频带上所有语音帧的能量做一个统计,设定一个分位数值,低于分位数值的认为是噪声,高于分位数值的认为是语音,相比于逐帧判断(VAD),这样就进一步细化了噪声统计的粒度,即使语音帧也能提取有效的噪声信息进行平滑。
分位数噪声估计的想法是建立这样一个共识,即使是语音段,输入信号在某些频带分量也可能没有信号能量。那么假设将某个频带上所有语音帧的能量做一个统计,设定一个分位数值,低于分位数值的认为是噪声,高于分位数值的认为是语音,相比于逐帧判断(VAD),这样就进一步细化了噪声统计的粒度,即使语音帧也能提取有效的噪声信息进行平滑。 

 Step1:计算含噪语音的能量谱; Step2:使用一阶递归平滑含噪语音的PSD; Step3:计算过去D帧的含噪语音的PSD估计; Step4:在直方图中选择选择频次最大的功率,作为噪声谱估计; Step5:使用一阶递归平滑噪声谱估计。
Step1:计算含噪语音的能量谱; Step2:使用一阶递归平滑含噪语音的PSD; Step3:计算过去D帧的含噪语音的PSD估计; Step4:在直方图中选择选择频次最大的功率,作为噪声谱估计; Step5:使用一阶递归平滑噪声谱估计。 2)下图是使用直方图方法估计的噪声,明显看出噪声的过估计。噪声过估计是窗长引起的,当窗长不足以覆盖语音峰值时,就会出现过估计,这种情况更容易出现在低频段,因为低频段语音能量高,峰值出现频繁,而高频能量峰值出现缓慢。所以高频段可以使用较短的窗长。
2)下图是使用直方图方法估计的噪声,明显看出噪声的过估计。噪声过估计是窗长引起的,当窗长不足以覆盖语音峰值时,就会出现过估计,这种情况更容易出现在低频段,因为低频段语音能量高,峰值出现频繁,而高频能量峰值出现缓慢。所以高频段可以使用较短的窗长。  解决方法: (1)增加统计的帧数D; 较长的窗口确实消除了噪声过高估计,但代价是降低了估计器的跟踪能力;也就是说,长窗产生的噪声估计器不能跟踪噪声水平的快速变化。这就是噪声过高估计和跟踪能力之间的权衡,不仅是直方图算法,最小跟踪算法同样需要。对于长窗口,用直方图算法获得的噪声估计模式类似于最小跟踪算法的模式。
解决方法: (1)增加统计的帧数D; 较长的窗口确实消除了噪声过高估计,但代价是降低了估计器的跟踪能力;也就是说,长窗产生的噪声估计器不能跟踪噪声水平的快速变化。这就是噪声过高估计和跟踪能力之间的权衡,不仅是直方图算法,最小跟踪算法同样需要。对于长窗口,用直方图算法获得的噪声估计模式类似于最小跟踪算法的模式。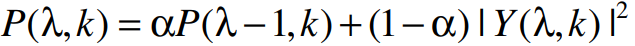 上式中:Y^2是语音的功率谱,因为波动比较快,所以采用一阶递归平滑得到功率谱P。通过跟踪P的最小值,得到噪声估计。但是会有问题:
上式中:Y^2是语音的功率谱,因为波动比较快,所以采用一阶递归平滑得到功率谱P。通过跟踪P的最小值,得到噪声估计。但是会有问题:  上图中,(a)中细线是200Hz的平滑功率谱(P),粗线是跟踪的最小值(即估计的噪声功率谱);(b)中细线是真实的噪声功率谱,粗线是估计的噪声功率谱。容易看出,1.5 ~ 2s和2.4 ~ 2.8s,噪声估计明显偏低。由于平滑因子是固定值,有可能因选择不当出现估计偏差,过高的估计噪声水平。
上图中,(a)中细线是200Hz的平滑功率谱(P),粗线是跟踪的最小值(即估计的噪声功率谱);(b)中细线是真实的噪声功率谱,粗线是估计的噪声功率谱。容易看出,1.5 ~ 2s和2.4 ~ 2.8s,噪声估计明显偏低。由于平滑因子是固定值,有可能因选择不当出现估计偏差,过高的估计噪声水平。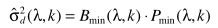 (1) 上述中B就是偏置因子,由下式计算得到:
(1) 上述中B就是偏置因子,由下式计算得到: 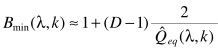 (2)
(2) 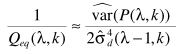 (3)
(3) 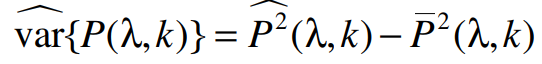 (4)
(4)  改进措施2:平滑因子随时间和频率而改变
改进措施2:平滑因子随时间和频率而改变

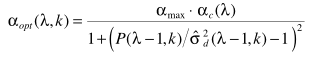 (1) 上式的推导过程主要利用最小均方误差准则:
(1) 上式的推导过程主要利用最小均方误差准则: 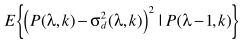 (2) 其中:
(2) 其中: 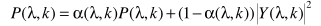 (3) 将(3)式带入(2)式,对alpha求偏导,令偏导数等于0,得到:
(3) 将(3)式带入(2)式,对alpha求偏导,令偏导数等于0,得到: 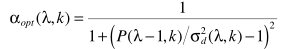 (4) 上式中的噪声谱估计可以使用上一帧的噪声谱估计代替。但当α接近于1时,更新太慢,因此有学者做了改进:
(4) 上式中的噪声谱估计可以使用上一帧的噪声谱估计代替。但当α接近于1时,更新太慢,因此有学者做了改进: 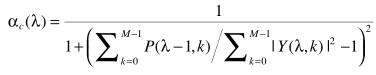 (5) 在此基础上再级联一个限定最大值的α(αmax = 0.96)估计,并认为两者是独立关系,得出最终的α:
(5) 在此基础上再级联一个限定最大值的α(αmax = 0.96)估计,并认为两者是独立关系,得出最终的α: 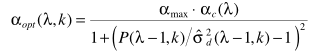 (6) Step3:
(6) Step3: 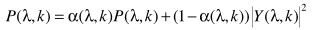 (7) Step4:主要计算偏差因子
(7) Step4:主要计算偏差因子 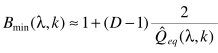 (8) 上式中,D是指统计的帧数(需要延迟D帧),Q由下式得到:
(8) 上式中,D是指统计的帧数(需要延迟D帧),Q由下式得到: 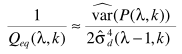 (9)
(9) 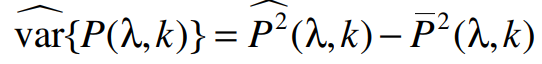

 (10)
(10)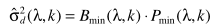 (11)
(11)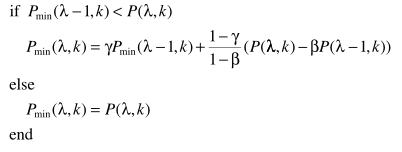 参数说明:
参数说明: 
 上图是连续谱最小值跟踪的效果图,箭头的地方表示噪声过高估计。
上图是连续谱最小值跟踪的效果图,箭头的地方表示噪声过高估计。【本文地址】