| 数字人解决方案 | 您所在的位置:网站首页 › 唇形比例图 › 数字人解决方案 |
数字人解决方案
|
简介
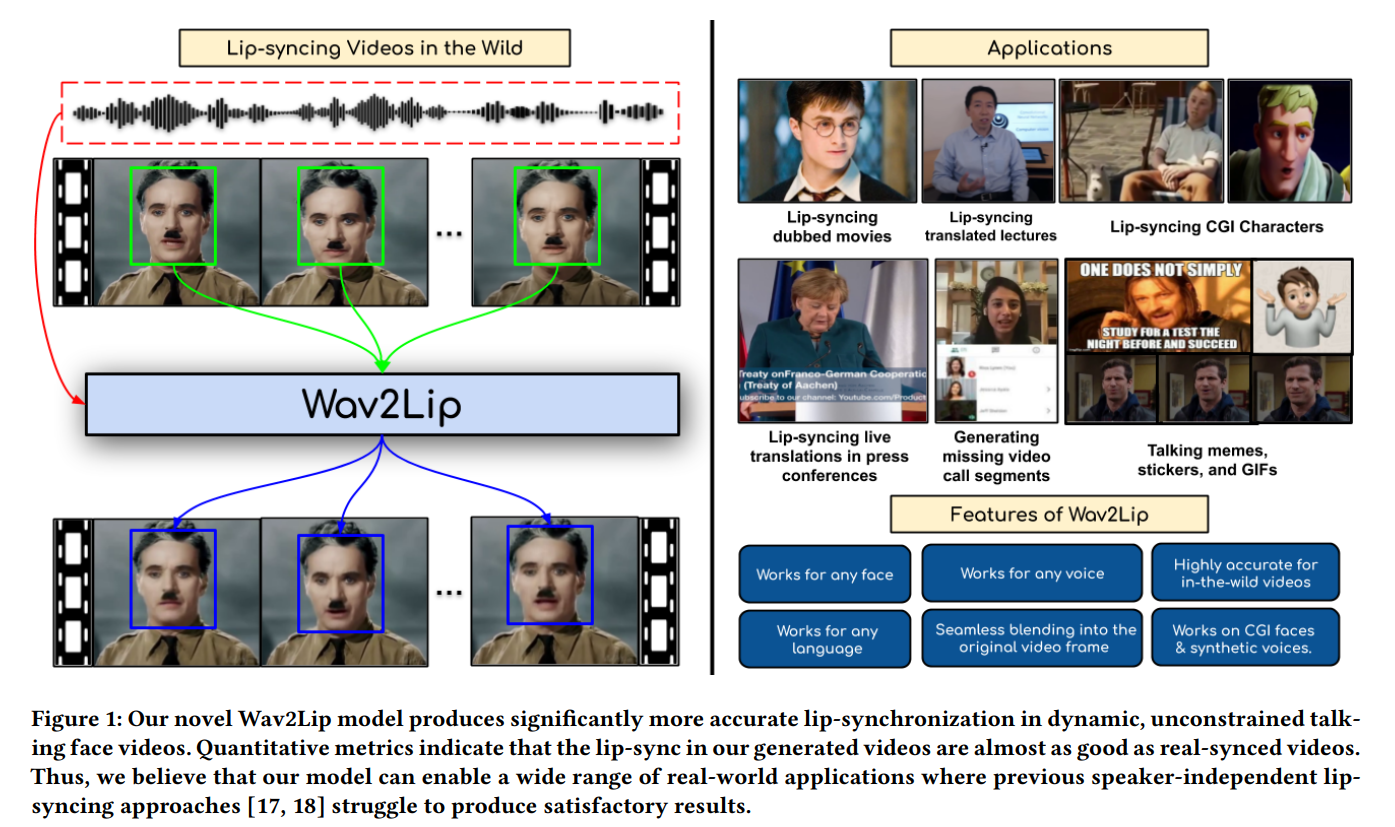
数字人技术可以分为3D和2D两种类型。在3D数字人领域,虚幻引擎的MetaHuman备受瞩目,其背后的技术涉及到诸如blendshape等技术。然而,2D的数字人可以选择的算法就有很多,比如最常见的Wav2Lip。Wav2Lip算法主要实现的是语音驱动嘴唇运动来生成视频。 常见的语音驱动嘴唇运动方法在处理动态和无约束的说话人脸视频时,通常无法准确合成口型,导致生成的视频与音频不同步。这主要是因为: 传统的基于像素的人脸重建损失无法有效约束音频-口型同步。由于面部重建损失是整个图像的计算结果,而唇部区域只占图像的很小一部分,因此无法充分关注唇部细节。此外,在人脸重建的训练过程中,对口型的优化往往在训练的中后期才开始,导致前期监督信息不足。 传统的基于GAN的判别器在音频-口型同步检测方面准确率较低。这些判别器通常只使用单帧图像来评估口型同步,缺乏时间上下文信息,因此无法有效评估口型动态变化的质量。此外,生成过程中可能出现伪影,导致GAN判别器更容易关注视觉伪影而忽略音频和口型的对应关系。 为了解决以上问题,wav2lip提出了一个专家口型同步判别器,该判别器在真实视频中进行预训练,并包含多帧信息,可用于判断音频和口型是否同步。实验证明,相比于基于像素的人脸重建方法,这个专家判别器在口型同步判别任务上更为准确。在训练阶段,该专家判别器保持冻结状态,以确保其判断结果不受伪影的干扰。 Wav2lip语音驱动数字人 方法与实现 模型训练wav2lip模型的训练分为两个阶段: 专家音频和口型同步判别器的预训练阶段: 提取音频特征,并将音频特征与人脸图像进行配对,形成音频-图像对。训练专家音频和口型同步判别器,该判别器用于评估音频和口型之间的同步程度。在这个阶段,模型通过大量的音频-图像对来学习如何准确地判断口型与音频的同步情况。GAN网络的训练阶段: 使用生成对抗网络(GAN)学习音频-图像对之间的映射关系。GAN包含一个生成器和两个判别器。生成器网络负责生成逼真的嘴唇动作,它将输入的音频特征转换为相应的嘴唇形状。专家音频和口型同步判别器在这个阶段保持冻结状态,不再更新参数,以确保口型同步的评估不受干扰。另一个判别器是视觉质量判别器,它负责评估生成的嘴唇动作的真实性和一致性。通过不断的训练和反馈,生成器网络逐渐学习到如何根据音频特征生成与之匹配的真实嘴唇动作。训练完成后,wav2lip模型可以根据输入的音频信息逐帧生成一个说话的人脸视频,实现音频-图像的同步合成。 本文使用的LRS2数据集是来自BBC的口语视频数据集,包含4万多个口语句子。该数据集将训练集、验证集和测试集按照广播日期进行了划分。同时,作者也建议用户可以自行收集各种视频数据,以提升模型在特定场景下的效果。 针对数据处理,推荐的设置如下: 视频帧率应设置为25fps,即每秒钟处理25帧图像。音频采样率应设置为16k,即每秒钟采样16000次。视频的一帧对应音频块的长度为16,这表示音频数据应该被分割成长度为16的块,以便与视频帧对齐。 专家音频和口型同步判别器预训练wav2lip专家音频和口型同步判别器是用于评估生成的唇部动作与音频的同步性的重要组件。该判别器是由SyncNet改进而来,SyncNet包含一个人脸编码器和一个音频编码器,两者都由一系列2D卷积层组成。 具体来说: 人脸编码器的输入是一个大小为的视频窗口,其中包含连续的人脸帧,但这些帧仅保留人脸下半部分。音频编码器的输入是一个大小为的语音片段,其中和 分别是视频和音频的时间步长。SyncNet的两个编码器分别计算音频嵌入和视频嵌入,然后使用最大间隔损失进行训练,最小化匹配的音频-口型对之间的嵌入距离。最大间隔损失的原理是基于最大间隔分类器的思想,通过最大化类别之间的间隔来提高分类器的鲁棒性和泛化能力。wav2lip对SyncNet进行了三个方面的改进,以训练更优秀的专家口型同步判别器: 使用RGB图像作为输入。增加模型的深度。使用余弦相似度二元交叉熵损失,即余弦相似度BCE损失。在训练过程中,wav2lip使用LRS2训练集对判别器进行训练。每个样本的时间维度设置为5帧(Tv = 5),按通道维度拼接起来,以获取视频帧的上下文信息。在测试集上评估,wav2lip的专家判别器的准确率达到了91%,而LipGAN中使用的判别器的准确率只有56%。 口型生成器wav2lip的生成器负责生成包含目标口型的人脸图像,是一个2D-CNN编码器-解码器结构,包含三个由卷积网络组成的模块:Identity Encoder,Speech Encoder,Face Decoder。 其中,Identity Encoder用于编码身份特征,把随机参考帧与姿势先验帧按通道维度拼接起来作为输入。参考帧包含目标人脸的完整外观特征,如嘴唇的形状、颜色和纹理等,用于唇部形状和运动的合成。姿势先验帧的下半部分被掩蔽,但提供了目标人脸的姿势信息,比如头部和脸部的方向和角度等信息,确保合成的唇部动作与目标人脸的姿势一致。同时,姿势先验帧也作为重建目标。这两个图像共同作为输入,确保生成的人脸的外观、口型和姿态更加准确。 Speech Encoder 用于编码输入的语音片段,Face Decoder则通过反卷积进行上采样,用于重建人脸图像,它的输入是编码后的音频特征和身份特征的拼接。 生成器通过最小化生成帧与真实帧之间的L1重构损失来提高生成的帧的质量,重建目标函数为: 具体来说,为了在训练过程中与专家判别器的配合,生成器需要生成
T
v
=
5
T_v = 5
Tv=5个连续帧,但只使用生成的人脸的下半部分进行判别,生成器通过最小化来自专家判别器的同步损失来提高生成的帧的口型同步质量,同步损失函数为余弦相似度二元交叉熵损失: 实验观察到,使用专家口型同步判别器可以使生成器生成准确的口型形状,但有时候会导致生成区域出现模糊或者伪影。为了提高生成图像质量,wav2lip在生成器中使用了一个额外的的视觉质量判别器。 具体来讲,wav2lip有两个判别器,口型同步判别器和质量判别器,一个用于提高口型同步准确性,另一个用于提高生成图像视觉质量。口型同步判别器在GAN训练期间保持冻结,视觉质量判别器只对生成的人脸的质量进行监督,不负责口型同步。 视觉质量判别器 D 由多个卷积块组成,训练目标是最大化目标函数
L
d
i
s
c
:
L_{disc}:
Ldisc: 生成器的最终优化目标是重建损失、同步损失和对抗损失的加权和,用公式表示如下: 我这里使用的环境是win 10,gpu是3080: 使用conda创建新的虚拟环境并激活: conda create -n wav2lip python=3.7 conda activate wav2lip 克隆或下载Wav2Lip源码,并安装依赖: git clone https://github.com/Rudrabha/Wav2Lip.git pip install -r requirements.txt 安装ffmpeg: 下载FFmpeg并将其路径添加到系统环境变量PATH中准备素材: 下载测试视频和对应长度的音频: wget --no-check-certificate https://bhaasha.iiit.ac.in/lipsync/static/samples/game.mp4 ffmpeg -ss 00:00:15 -t 00:00:03 -i input.mp4 -vcodec copy -acodec copy test.mp4 ffmpeg -i test.mp4 -vn test.mp3准备脸部检测预训练模型: 下载地址:https://www.adrianbulat.com/downloads/python-fan/s3fd-619a316812.pth将下载的模型文件放置在face_detection/detection/sfd目录下,并重命名为s3fd.pth。准备Wav2Lip模型文件: 选择其中一个模型文件,推荐使用Wav2Lip + GAN模型。下载地址:https://iiitaphyd-my.sharepoint.com/:u:/g/personal/radrabha_m_research_iiit_ac_in/EdjI7bZlgApMqsVoEUUXpLsBxqXbn5z8VTmoxp55YNDcIA?e=n9ljGW运行代码: 合成视频和音频: python inference.py --checkpoint_path wav2lip_gan.pth --face test.mp4 --audio test.mp3 合成图片和音频: python inference.py --checkpoint_path wav2lip_gan.pth --face 1.jpg --audio test.mp3生成的新视频文件保存在results文件夹中,而生成的中间文件存放在temp文件夹中。 整合包安装下载完整之后,点Wav2lip启动.bat启动:
|
 企鹅交流群:787501969,整合包下载地址可以加交流群获者从csdn下载:https://download.csdn.net/download/matt45m/88974110
企鹅交流群:787501969,整合包下载地址可以加交流群获者从csdn下载:https://download.csdn.net/download/matt45m/88974110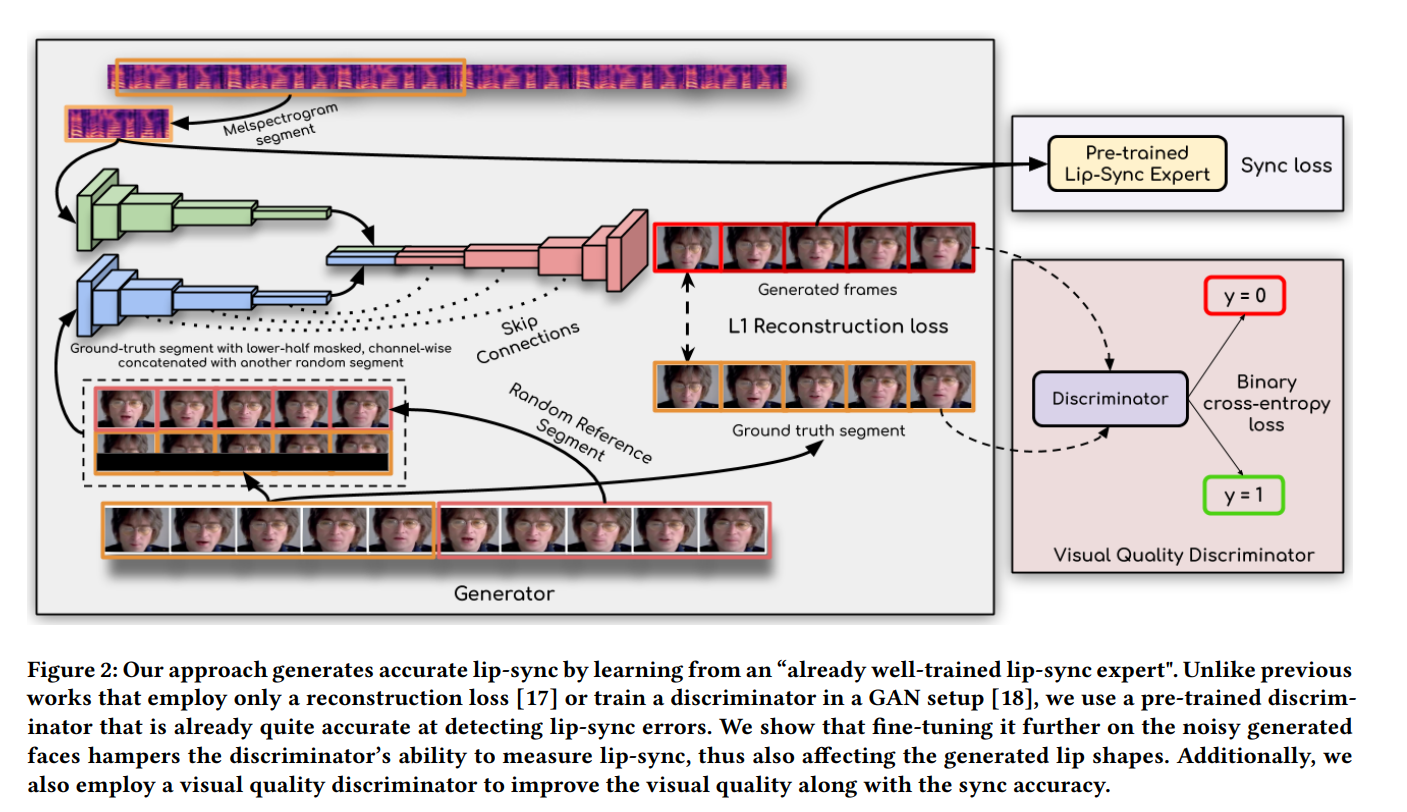
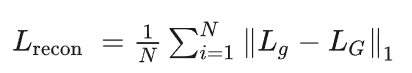 wav2lip生成器独立地生成每一帧,然后将连续生成的帧序列输入给预训练的专家音频和口型同步判别器。
wav2lip生成器独立地生成每一帧,然后将连续生成的帧序列输入给预训练的专家音频和口型同步判别器。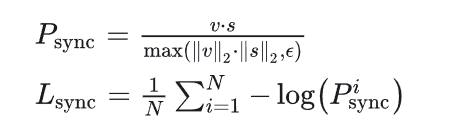 在生成器的训练过程中,专家判别器的权重保持不变,因为专家判别器是从真实视频中的口型数据训练的,无需改变。通过这种生成器的结构和专家判别器的共同作用,可以生成任意人脸对象,并且口型与语音的同步性较好。但由于LRS2数据集的清晰度偏低,生成的图像可能会有一定模糊度,特别是在牙齿部分的还原度可能稍差。为了解决这个问题,可以采用以下方法之一:
在生成器的训练过程中,专家判别器的权重保持不变,因为专家判别器是从真实视频中的口型数据训练的,无需改变。通过这种生成器的结构和专家判别器的共同作用,可以生成任意人脸对象,并且口型与语音的同步性较好。但由于LRS2数据集的清晰度偏低,生成的图像可能会有一定模糊度,特别是在牙齿部分的还原度可能稍差。为了解决这个问题,可以采用以下方法之一: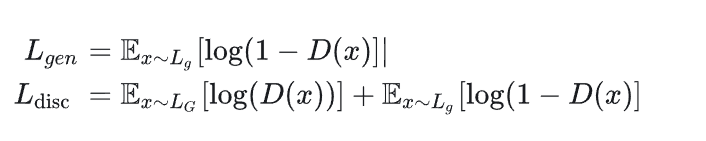 其中,
L
g
L_g
Lg 对应于生成器 G 生成的图像,
L
G
L_G
LG对应于真实图像。
其中,
L
g
L_g
Lg 对应于生成器 G 生成的图像,
L
G
L_G
LG对应于真实图像。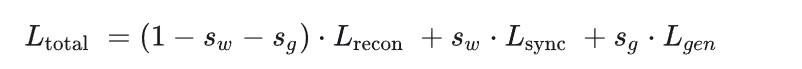 其中,
s
w
s_w
sw同步惩罚权重,
s
g
s_g
sg对抗损失权重。 重建损失衡量生成器生成的图像与原始图像之间的差异,同步损失衡量生成口型与目标口型之间的差异,对抗损失衡量生成的图像在对抗训练中与判别器的对抗表现。通过最小化这些损失函数的加权和,生成器可以生成口型同步的高质量人脸图像。
其中,
s
w
s_w
sw同步惩罚权重,
s
g
s_g
sg对抗损失权重。 重建损失衡量生成器生成的图像与原始图像之间的差异,同步损失衡量生成口型与目标口型之间的差异,对抗损失衡量生成的图像在对抗训练中与判别器的对抗表现。通过最小化这些损失函数的加权和,生成器可以生成口型同步的高质量人脸图像。 启动完成:
启动完成:  然后在浏览器里面打开:http://127.0.0.1:7860/
然后在浏览器里面打开:http://127.0.0.1:7860/ 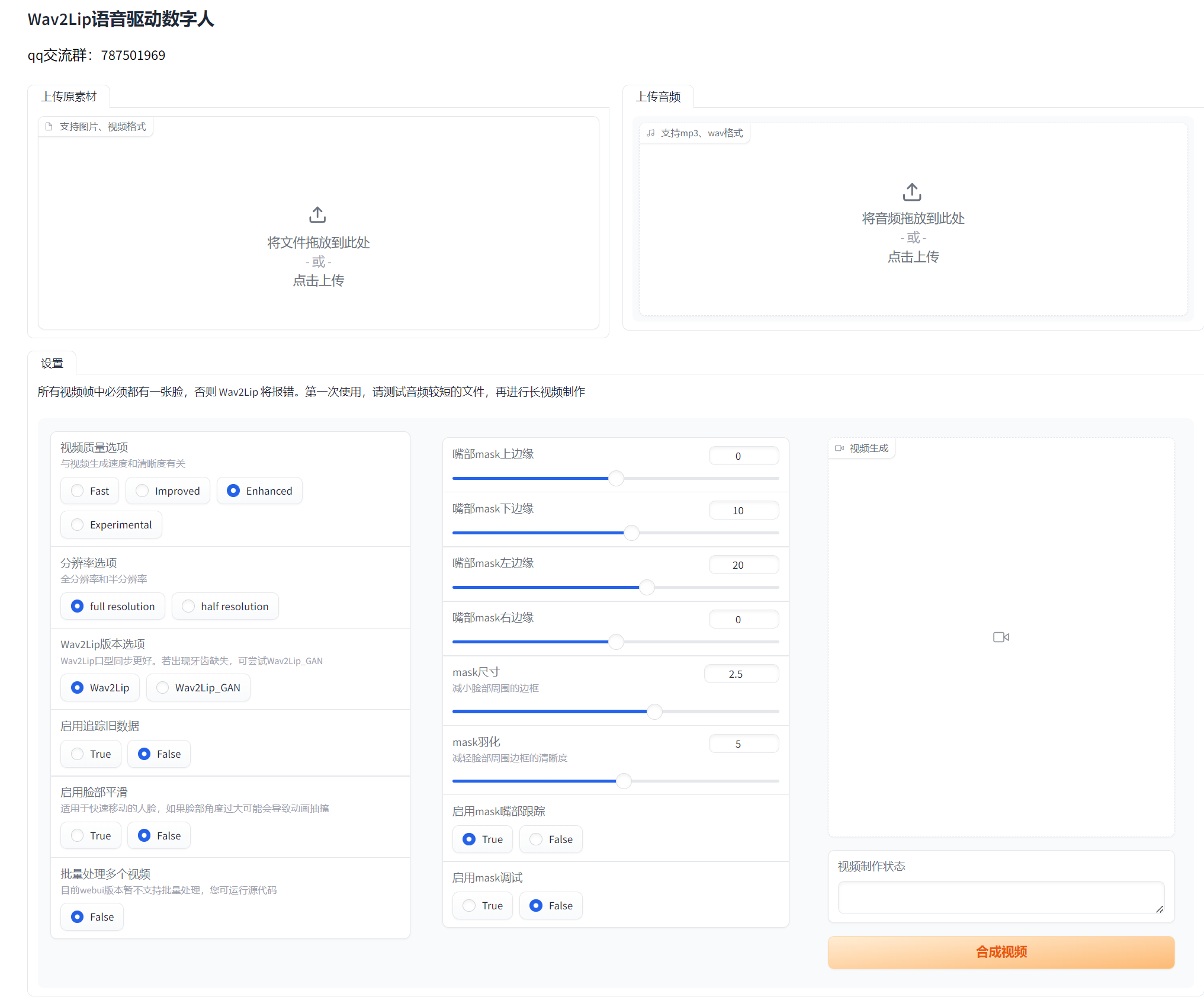 然后上传视频或者图像,还有要合成的音频:
然后上传视频或者图像,还有要合成的音频: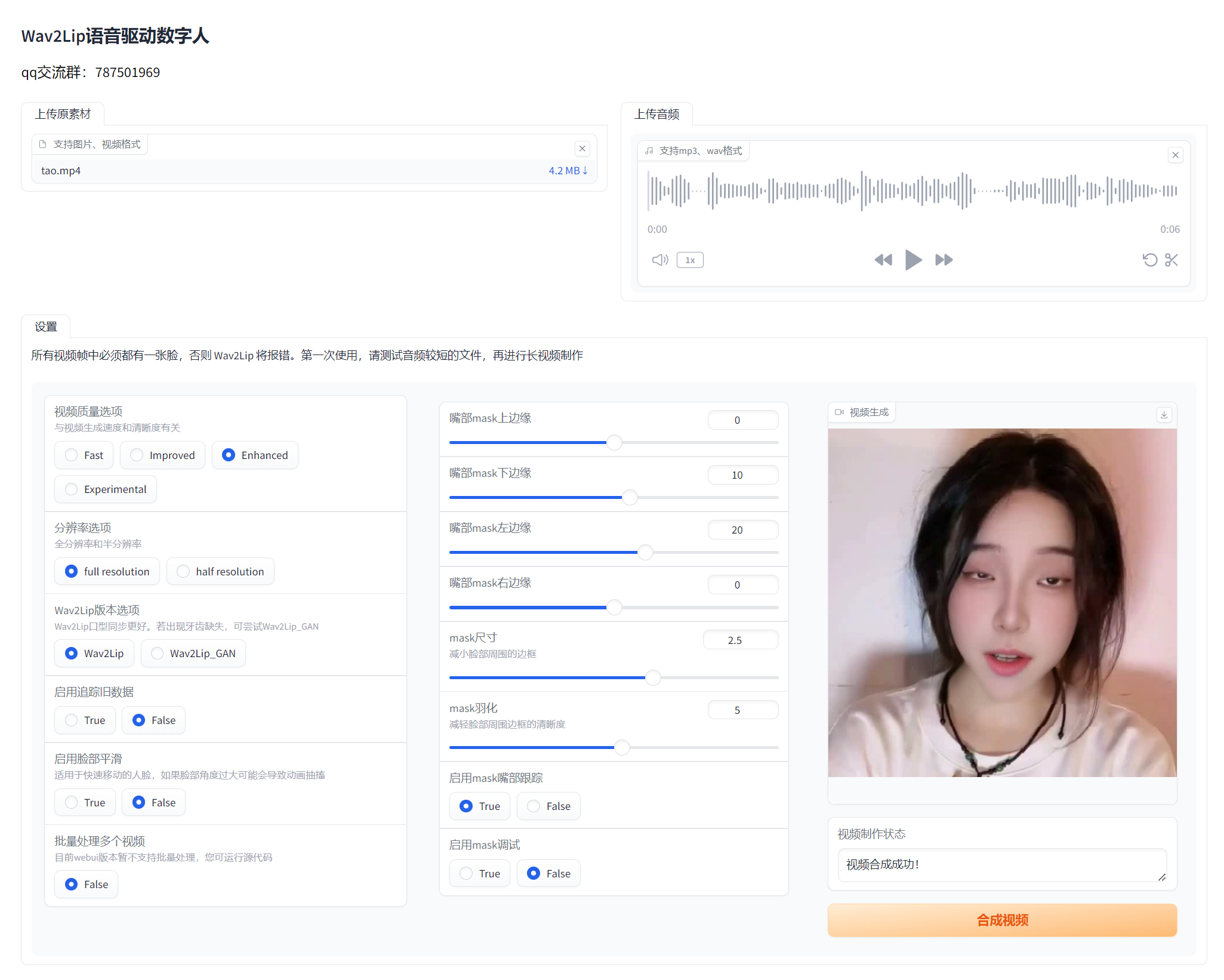
【本文地址】