| redis系列 | 您所在的位置:网站首页 › 哈希表结构图 › redis系列 |
redis系列
|
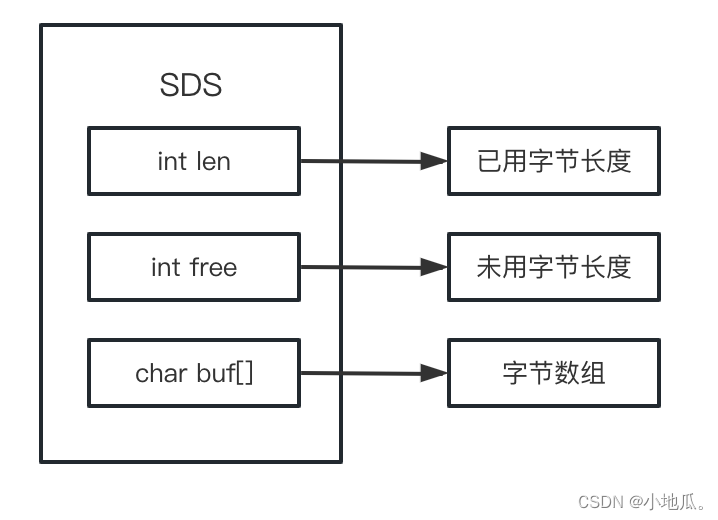
一、字符串内部结构SDS(简单动态字符串) 字符串结构体SDS :
字符串结构特点: O(1)时间复杂度获取:字符串长度、已用长度、未用长度。可用于保存字节数组,支持二进制数据存储。内部实现空间预分配机制,降低内存再分配次数。惰性删除机制,字符串缩减后的空间不释放,作为预分配空间保留。不同长度的字符串使用不同的结构体来表示。空间预分配规则: 第一次创建按照len属性等于数据实际大小,free为0,不预分配。修改后如果已有free空间不够不够且数据小于1M,每次预分配1倍容量。修改后如果已有free空间不够且数据大于1M,每次预分配1MB数据。惰性空间释放:缩短SDS保存的字符串,程序不立即回收内存,只记录缩短后的长度len,剩余空间用来后续扩展字符串用。 注意:尽量减少字符串频繁修改操作如append改为set。降低预分配带来的内存浪费和内存碎片化。 二、hashtablehashtable结构的数据会用到一个叫dict的复合型数据结构。 dict内部结构:
渐进式hash:对旧数组里元素进行操作(查询删除修改)时搬迁到新数组,删除旧数组元素。一直未操作的元素redis会有定时器定期扫描迁移到新数组。 hashtable的查找使用了一个hash函数,决定了hashtable的性能。如果hash函数将key打散的比较均匀的话使用效率就越高。redis的hash函数默认是siphash,siphash在key很小的情况,也可以产生随机性特别好的输出。 扩容条件:当hash表中的元素个数等于第一维数组的长度,就开始扩容,扩容原数组的2倍。 缩容条件:元素个数低于数组长度的10%,hash表会进行缩容减少hash表的第一维数组空间占用。 三、intsetset集合的元素都是整数并且长度不超过set-max-intset-entries配置时会用intset来存储元素。intset是紧凑的数据结构,支持16,32和64位整数。存储有序,不重复的整数集。 内部结构图:
intset字段结构说明: struct intset { int32 encoding; // 整数表示类型,根据集合内最长整数值确定类型,整数类型划分为三种:int-16、int-32、int-64。 int32 length; // 集合元素个数 int contents; // 整数数组,按从小到大顺序保存。可以是 16 位、32 位和 64 位 }注意:数据值尽量保持一致,防止大的值触发集合升级,产生内存浪费。升级后没有回退操作。升级操作将会导致重新申请内存空间,把原有数据按转换类型后拷贝到新数组。 set下内存和速度测试:
ziplist结构内的所有数据都是采用线性连续存储的内存结构。适合存储小对象和长度有限的数据。数据两比较多的时候会变成quicklist。使用LZF 算法压缩。主要目的是节约内存。但是操作耗时。原则是追求空间和时间的平衡。针对性能要求较高的场景使用ziplist,建议长度不要超过1000,每个元 素大小控制在512字节以内。 内部结构图:
ziplist字段结构说明: struct ziplist { int32 zlbytes; //压缩列表占用字节长度 int32 zltail_offset; //最后一个元素距离压缩列表起始位置的偏移量,用于快速定位到最后一个 节点 int16 zllength; // 元素个数 T[] entries; // 元素内容列表,挨个挨个紧凑存储 int8 zlend; //尾结点 }entry具体内容: struct entry { int prevlen; // 前一个 entry 的字节长度(压缩列表倒着遍历时,需要通过这 个字段来快速定位到下一个元素的位置) int encoding; // 元素类型编码 optional byte[] content; // 元素内容 }ziplist在hash,list,zset内存和速度测试:  五、quicklist(快速列表) 五、quicklist(快速列表)
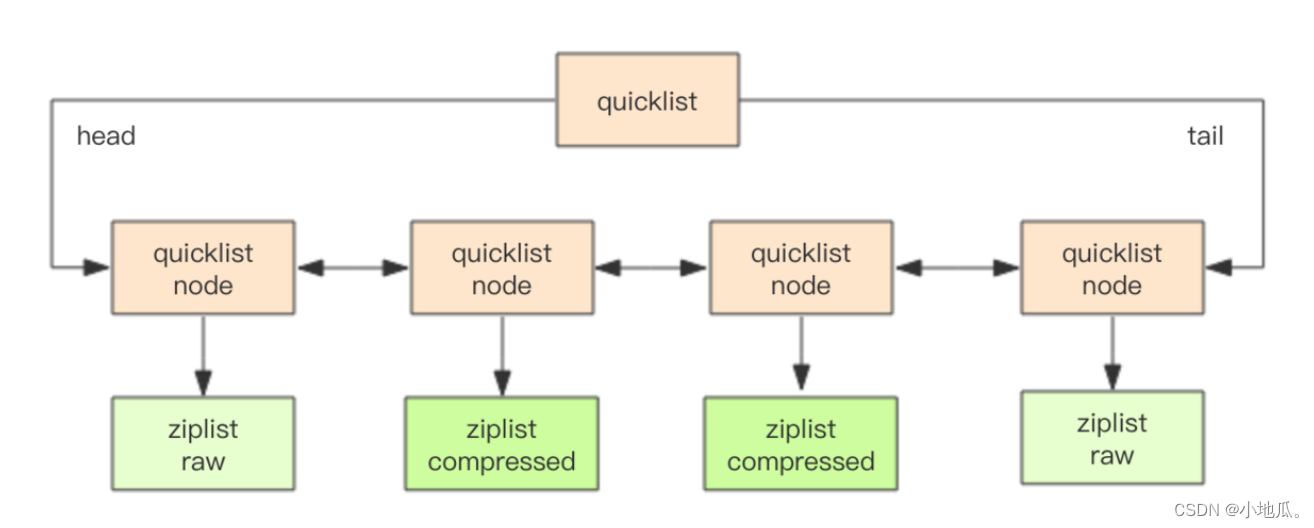
quicklist 是 ziplist 和 linkedlist 的混合体。将linkedlist 按段切分,使用ziplist 连续存储,多个 ziplist 之间使用双向链表指针串接起来。 内部结构图:
linkedlist 链表插入和删除O(1),内存利用率低,内存不连续容易产生内存碎片。ziplist 内存连续存储效率高,插入和删除O(n),需要频繁进行数据搬移、释放或申请内存。quicklist 集合了ziplist +linkedlist 的优点。 quicklist每个ziplist默认8k,超过8k会新起一个ziplist,根据list-max-ziplist-size参数配置。 压缩深度:
quicklist压缩深度默认是0,可根据参数 listcompress-depth配置压缩深度。quicklist的首和尾都不压缩,是为了支持快速的push、pop操作。 六、skiplist(跳跃表)skiplist(跳跃表):有序的数据结构,通过在每个节点中维持多个指向其他节点的指针快速访问某结点。表内数据根据score值有序,从小到大。每一个key value都对应zslnode结构。 随机层数:新插入节点,使用随机算法分配分配一个合理的层数,跳跃表共有64层,可以容纳2的64次幂个元素。期望是 50% 的 Level1,25% 的 Level2,12.5% 的 Level3、、以此类推。晋升概率50%。 内部结构图:
skiplist字段结构说明: struct zslnode { string value; double score; zslnode*[] forwards; // 多层连接指针 zslnode* backward; // 回溯指针 } struct zsl { zslnode* header; // 跳跃列表头指针 int maxLevel; // 跳跃列表当前的最高层 map ht; // hash 结构的所有键值对 }查找过程:从最高层(记录最高层数maxLevel)开始遍历找到第一个节点(最后一个比我小的元素),然后从这个节点开始降一层再遍历找到第二个节点。一直降到最底层进行遍历找到期望的节点。通过一系列的搜索路径找到最新的节点。
插入过程: 创建一个新节点,通过随机算法分配一个层数。通过搜索路径上的节点和这个新接待你通过前后指针关联。如果分配的新节点的高度高于当前跳跃表的最大高度,需要更新maxLevel的值。删除过程:需要先把 搜索路径 找出来然后对于每个层的相关节点都重排一下前向后向指针。需要注意删除最高层需要更新maxLevel。 更新过程:调用zadd方法,value存在,score值发生变化就直接删除再插入,不会判断位置是否需要调整。 参考书籍:Redis开发与运维、Redis深度历险 |

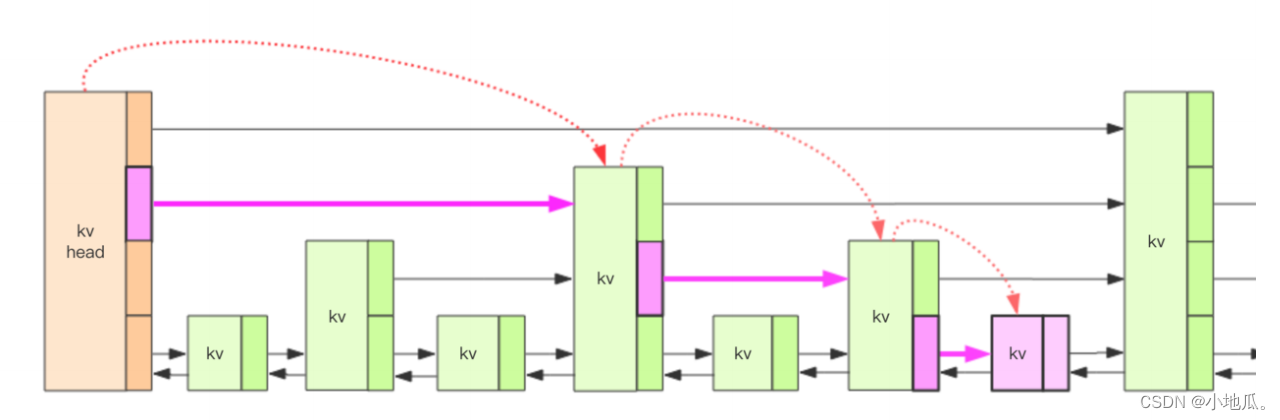
 dict内部有两个hashtable(数组+链表的数据结构),通常情况下只有一个有值。在扩容(2倍)或缩容(元素低于数组长度10%)需要分配新的hashtable,采用渐进式(rehash)搬迁,新、旧hashtable都有值。搬迁结束,旧的删除,保留新的。
dict内部有两个hashtable(数组+链表的数据结构),通常情况下只有一个有值。在扩容(2倍)或缩容(元素低于数组长度10%)需要分配新的hashtable,采用渐进式(rehash)搬迁,新、旧hashtable都有值。搬迁结束,旧的删除,保留新的。





【本文地址】