| GMM、GMM | 您所在的位置:网站首页 › 和m说话 › GMM、GMM |
GMM、GMM
|
说话人识别流程
一个说话人识别系统通常包括:声学特征提取、说话人编码器、说话人注册数据库、说话人验证/辨认等,如下图所示(图源:语音之家)。 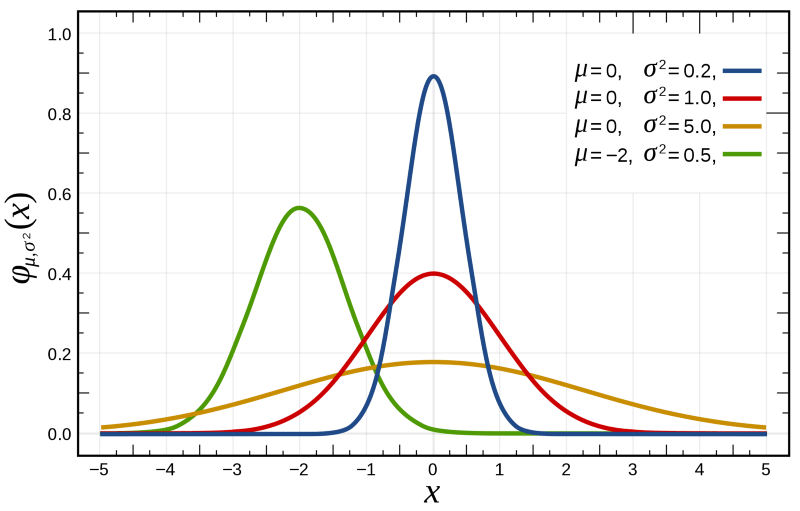 注意:均值只影响高斯分布的位置,方差只影响高斯分布的形状(方差越大,随机变量的概率密度越集中)。
多元高斯分布
记作
x
∼
N
(
x
∣
μ
,
Σ
)
x \sim N(x| \mu , \Sigma)
x∼N(x∣μ,Σ),其中
μ
\mu
μ表示 K 维均值向量
Σ
\Sigma
Σ表示
K
×
K
K \times K
K×K 维协方差矩阵,其元素
σ
i
j
2
\sigma_{ij}^2
σij2 表示随机变量 i 和 j 的协方差,对角线上的元素
σ
i
i
2
\sigma_{ii}^2
σii2 表示随机变量 i 的方差,由此可知:协方差矩阵是对称矩阵。 多元(指自变量x是高维的)高斯分布概率密度函数:
p
(
x
)
=
(
(
2
π
)
K
∣
Σ
∣
)
−
1
/
2
exp
{
−
1
2
(
x
−
μ
)
T
Σ
−
1
(
x
−
μ
)
}
p(x) = ((2 \pi)^K | \Sigma |)^{-1 / 2} \exp\left \{- \frac{1}{2} (x-\mu)^T \Sigma^{-1} (x-\mu) \right \}
p(x)=((2π)K∣Σ∣)−1/2exp{−21(x−μ)TΣ−1(x−μ)}
∣
Σ
∣
|\Sigma|
∣Σ∣ 表示协方差矩阵的行列式
中心极限定理(Central Limit Theorem,CLT)
中心极限定理(也叫大数定律):在适当的条件下,大量相互独立随机变量的均值经适当标准化后依分布收敛于标准正态分布。等价于,大量相互独立随机变量的和,以其均值为中心,呈现正态分布,这组定理是数理统计学和误差分析的理论基础,指出了大量随机变量之和近似服从正态分布的条件。在说话人识别领域,对大量的语音进行随机采样,其中,下列物理量会呈现正态分布:
基频共振峰声强信噪比持续时间
GMM(Gaussian Mixture Model,高斯混合模型)
动机:使用 M 个高斯分布的线性组合,模拟复杂的分布高斯混合模型的概率密度函数:
p
(
x
)
=
∑
i
=
1
M
c
i
⋅
N
i
(
x
)
p(x) = \sum_{i=1}^{M} c_i \cdot N_i (x)
p(x)=i=1∑Mci⋅Ni(x) 其中,
c
i
≥
0
c_i \ge 0
ci≥0 是第 i 个高斯分量的权重
∑
i
=
1
M
c
i
=
1
\sum_{i=1}^{M} c_i = 1
∑i=1Mci=1
N
i
(
x
)
=
(
(
2
π
)
K
∣
Σ
i
∣
)
−
1
/
2
exp
{
−
1
2
(
x
−
μ
i
)
T
Σ
i
−
1
(
x
−
μ
i
)
}
N_i (x) = ((2 \pi)^K | \Sigma_i |)^{-1 / 2} \exp\left \{- \frac{1}{2} (x-\mu_i)^T \Sigma_i^{-1} (x-\mu_i) \right \}
Ni(x)=((2π)K∣Σi∣)−1/2exp{−21(x−μi)TΣi−1(x−μi)} 高斯混合模型的参数表示为:
λ
=
{
c
i
,
μ
i
,
Σ
i
;
i
=
1
,
2
,
.
.
.
,
M
}
\lambda = \left \{ c_i , \mu_i , \Sigma_i ;i=1,2,...,M \right \}
λ={ci,μi,Σi;i=1,2,...,M} 即总共有
M
⋅
(
1
+
K
+
K
2
)
M \cdot (1+K+K^2)
M⋅(1+K+K2) 个参数GMM的问题在于:参数量随着 K 的平方增大,这容易导致过拟合GMM的参数主要集中在协方差矩阵上,因此有两个减少协方差矩阵参数的办法:
共享参数
第一层:每个GMM的每个高斯分量都有独立的协方差矩阵第二层:每个GMM的所有高斯分量都共享协方差矩阵第三层:所有GMM的所有高斯分量都共享协方差矩阵 简化矩阵
第一层:方阵上每个元素都有参数,表示随机变量的任意两个维度都相关第二层:方阵上只有对角线上元素有参数,表示随机变量的任意两个维度都不相关第三层:方阵上只有对角线上元素有参数,且对角线上元素相同,可表示为
α
I
\alpha I
αI,
I
I
I 为单位矩阵,表示随机变量的任意两个维度都不相关,且各维度方差相同 注意:符合高斯分布的随机变量,不相关等价于独立。说话人识别领域最佳实践:每个GMM的每个高斯分量都有独立的对角协方差矩阵。从而,参数量变为:
M
⋅
(
1
+
2
K
)
M \cdot (1+2K)
M⋅(1+2K),新的第 i 个高斯分量的概率密度函数可表示为:
N
i
(
x
)
=
Π
k
=
1
K
(
2
π
σ
i
k
2
)
−
1
/
2
e
x
p
{
−
1
2
(
x
k
−
μ
i
k
σ
i
k
)
2
}
N_i (x) = \Pi_{k=1}^{K} (2 \pi \sigma_{ik}^2)^{-1/2} exp\left \{ -\frac{1}{2} (\frac{x_k-\mu_{ik}}{\sigma_{ik}})^2 \right \}
Ni(x)=Πk=1K(2πσik2)−1/2exp{−21(σikxk−μik)2} 这个形式类似于 K 个一维高斯分布连乘。
GMM用于说话人识别
对于每个说话人,都用一个GMM去表征,从而GMM成为一个映射:
声学特征
→
说话人
声学特征 \rightarrow 说话人
声学特征→说话人常用最大似然估计(Maximum Likelihood Estimation,MLE)对GMM进行参数估计,即最大化:
p
(
X
∣
λ
)
=
Π
n
=
1
N
p
(
x
n
∣
λ
)
p(X|\lambda) = \Pi_{n=1}^{N} p(x_n|\lambda)
p(X∣λ)=Πn=1Np(xn∣λ)
其中,
λ
\lambda
λ是GMM的参数,GMM的总数与说话人的个数相同;
X
=
{
x
n
∣
n
=
1
,
2
,
.
.
.
,
N
}
X=\left \{ x_n|n=1,2,...,N \right \}
X={xn∣n=1,2,...,N} 为GMM对应说话人的所有话语。注意:不要与最大后验估计(Maximum A Posteriori Estimation,MAP)混淆,最大后验估计要求最大化
p
(
λ
∣
X
)
p(\lambda|X)
p(λ∣X) 常用EM算法(Expectation-Maximization algorithm)解决最大似然估计问题,在此不深究EM算法的本质,只给出步骤EM算法步骤 注意:均值只影响高斯分布的位置,方差只影响高斯分布的形状(方差越大,随机变量的概率密度越集中)。
多元高斯分布
记作
x
∼
N
(
x
∣
μ
,
Σ
)
x \sim N(x| \mu , \Sigma)
x∼N(x∣μ,Σ),其中
μ
\mu
μ表示 K 维均值向量
Σ
\Sigma
Σ表示
K
×
K
K \times K
K×K 维协方差矩阵,其元素
σ
i
j
2
\sigma_{ij}^2
σij2 表示随机变量 i 和 j 的协方差,对角线上的元素
σ
i
i
2
\sigma_{ii}^2
σii2 表示随机变量 i 的方差,由此可知:协方差矩阵是对称矩阵。 多元(指自变量x是高维的)高斯分布概率密度函数:
p
(
x
)
=
(
(
2
π
)
K
∣
Σ
∣
)
−
1
/
2
exp
{
−
1
2
(
x
−
μ
)
T
Σ
−
1
(
x
−
μ
)
}
p(x) = ((2 \pi)^K | \Sigma |)^{-1 / 2} \exp\left \{- \frac{1}{2} (x-\mu)^T \Sigma^{-1} (x-\mu) \right \}
p(x)=((2π)K∣Σ∣)−1/2exp{−21(x−μ)TΣ−1(x−μ)}
∣
Σ
∣
|\Sigma|
∣Σ∣ 表示协方差矩阵的行列式
中心极限定理(Central Limit Theorem,CLT)
中心极限定理(也叫大数定律):在适当的条件下,大量相互独立随机变量的均值经适当标准化后依分布收敛于标准正态分布。等价于,大量相互独立随机变量的和,以其均值为中心,呈现正态分布,这组定理是数理统计学和误差分析的理论基础,指出了大量随机变量之和近似服从正态分布的条件。在说话人识别领域,对大量的语音进行随机采样,其中,下列物理量会呈现正态分布:
基频共振峰声强信噪比持续时间
GMM(Gaussian Mixture Model,高斯混合模型)
动机:使用 M 个高斯分布的线性组合,模拟复杂的分布高斯混合模型的概率密度函数:
p
(
x
)
=
∑
i
=
1
M
c
i
⋅
N
i
(
x
)
p(x) = \sum_{i=1}^{M} c_i \cdot N_i (x)
p(x)=i=1∑Mci⋅Ni(x) 其中,
c
i
≥
0
c_i \ge 0
ci≥0 是第 i 个高斯分量的权重
∑
i
=
1
M
c
i
=
1
\sum_{i=1}^{M} c_i = 1
∑i=1Mci=1
N
i
(
x
)
=
(
(
2
π
)
K
∣
Σ
i
∣
)
−
1
/
2
exp
{
−
1
2
(
x
−
μ
i
)
T
Σ
i
−
1
(
x
−
μ
i
)
}
N_i (x) = ((2 \pi)^K | \Sigma_i |)^{-1 / 2} \exp\left \{- \frac{1}{2} (x-\mu_i)^T \Sigma_i^{-1} (x-\mu_i) \right \}
Ni(x)=((2π)K∣Σi∣)−1/2exp{−21(x−μi)TΣi−1(x−μi)} 高斯混合模型的参数表示为:
λ
=
{
c
i
,
μ
i
,
Σ
i
;
i
=
1
,
2
,
.
.
.
,
M
}
\lambda = \left \{ c_i , \mu_i , \Sigma_i ;i=1,2,...,M \right \}
λ={ci,μi,Σi;i=1,2,...,M} 即总共有
M
⋅
(
1
+
K
+
K
2
)
M \cdot (1+K+K^2)
M⋅(1+K+K2) 个参数GMM的问题在于:参数量随着 K 的平方增大,这容易导致过拟合GMM的参数主要集中在协方差矩阵上,因此有两个减少协方差矩阵参数的办法:
共享参数
第一层:每个GMM的每个高斯分量都有独立的协方差矩阵第二层:每个GMM的所有高斯分量都共享协方差矩阵第三层:所有GMM的所有高斯分量都共享协方差矩阵 简化矩阵
第一层:方阵上每个元素都有参数,表示随机变量的任意两个维度都相关第二层:方阵上只有对角线上元素有参数,表示随机变量的任意两个维度都不相关第三层:方阵上只有对角线上元素有参数,且对角线上元素相同,可表示为
α
I
\alpha I
αI,
I
I
I 为单位矩阵,表示随机变量的任意两个维度都不相关,且各维度方差相同 注意:符合高斯分布的随机变量,不相关等价于独立。说话人识别领域最佳实践:每个GMM的每个高斯分量都有独立的对角协方差矩阵。从而,参数量变为:
M
⋅
(
1
+
2
K
)
M \cdot (1+2K)
M⋅(1+2K),新的第 i 个高斯分量的概率密度函数可表示为:
N
i
(
x
)
=
Π
k
=
1
K
(
2
π
σ
i
k
2
)
−
1
/
2
e
x
p
{
−
1
2
(
x
k
−
μ
i
k
σ
i
k
)
2
}
N_i (x) = \Pi_{k=1}^{K} (2 \pi \sigma_{ik}^2)^{-1/2} exp\left \{ -\frac{1}{2} (\frac{x_k-\mu_{ik}}{\sigma_{ik}})^2 \right \}
Ni(x)=Πk=1K(2πσik2)−1/2exp{−21(σikxk−μik)2} 这个形式类似于 K 个一维高斯分布连乘。
GMM用于说话人识别
对于每个说话人,都用一个GMM去表征,从而GMM成为一个映射:
声学特征
→
说话人
声学特征 \rightarrow 说话人
声学特征→说话人常用最大似然估计(Maximum Likelihood Estimation,MLE)对GMM进行参数估计,即最大化:
p
(
X
∣
λ
)
=
Π
n
=
1
N
p
(
x
n
∣
λ
)
p(X|\lambda) = \Pi_{n=1}^{N} p(x_n|\lambda)
p(X∣λ)=Πn=1Np(xn∣λ)
其中,
λ
\lambda
λ是GMM的参数,GMM的总数与说话人的个数相同;
X
=
{
x
n
∣
n
=
1
,
2
,
.
.
.
,
N
}
X=\left \{ x_n|n=1,2,...,N \right \}
X={xn∣n=1,2,...,N} 为GMM对应说话人的所有话语。注意:不要与最大后验估计(Maximum A Posteriori Estimation,MAP)混淆,最大后验估计要求最大化
p
(
λ
∣
X
)
p(\lambda|X)
p(λ∣X) 常用EM算法(Expectation-Maximization algorithm)解决最大似然估计问题,在此不深究EM算法的本质,只给出步骤EM算法步骤
设置初始化参数 λ 0 \lambda_0 λ0 可以随机初始化也可以用K-means先对样本进行聚类,然后用多元高斯分布,初步表征每个类E步骤:计算每个样本,到每个高斯分量上的概率,由于高斯分量已经有参数,所以此时的概率是在具有先验知识的前提下得到的,因此是后验概率 假设当前是第 t 个迭代参数未更新,记为 λ ( t − 1 ) \lambda^{(t-1)} λ(t−1)计算样本对GMM的第 i 个高斯分量的后验概率 p ( i ∣ x n , λ ( t − 1 ) ) = c i ( t − 1 ) ⋅ N i ( t − 1 ) ( x n ) ∑ j = 1 M c j ( t − 1 ) ⋅ N j ( t − 1 ) ( x n ) p(i|x_n,\lambda^{(t-1)})=\frac{c_i^{(t-1)} \cdot N_i^{(t-1)} (x_n)}{\sum_{j=1}^{M} c_j^{(t-1)} \cdot N_j^{(t-1)} (x_n)} p(i∣xn,λ(t−1))=∑j=1Mcj(t−1)⋅Nj(t−1)(xn)ci(t−1)⋅Ni(t−1)(xn)M步骤:根据E步骤得到的后验概率,更新参数 更新权重 c i ( t ) = 1 N ∑ n = 1 N p ( i ∣ x n , λ ( t − 1 ) ) c_i^{(t)} = \frac{1}{N} \sum_{n=1}^{N} p(i|x_n,\lambda^{(t-1)}) ci(t)=N1n=1∑Np(i∣xn,λ(t−1))更新均值和协方差矩阵 μ i ( t ) = ∑ n = 1 N p ( i ∣ x n , λ ( t − 1 ) ) ⋅ x n ∑ n = 1 N p ( i ∣ x n , λ ( t − 1 ) ) σ i k 2 ( t ) = ∑ n = 1 N p ( i ∣ x n , λ ( t − 1 ) ) ⋅ ( x n k − μ i k ) 2 ∑ n = 1 N p ( i ∣ x n , λ ( t − 1 ) ) \begin{aligned} \mu_i^{(t)} &= \frac{\sum_{n=1}^{N} p(i|x_n,\lambda^{(t-1)}) \cdot x_n}{\sum_{n=1}^{N} p(i|x_n,\lambda^{(t-1)})} \\ {\sigma_{ik}^{2}}^{(t)} &= \frac{\sum_{n=1}^{N} p(i|x_n,\lambda^{(t-1)}) \cdot (x_{nk}-\mu_{ik})^2}{\sum_{n=1}^{N} p(i|x_n,\lambda^{(t-1)})} \end{aligned} μi(t)σik2(t)=∑n=1Np(i∣xn,λ(t−1))∑n=1Np(i∣xn,λ(t−1))⋅xn=∑n=1Np(i∣xn,λ(t−1))∑n=1Np(i∣xn,λ(t−1))⋅(xnk−μik)2交替重复E步骤和M步骤,直到达成特定条件为止 可以是达到最大迭代次数也可以是更新后的参数几乎没有太大变化 EM算法注意事项:协方差矩阵位于分母的位置,且常常会变得很小,计算E步骤时容易出现数值计算错误,可以给协方差矩阵的值设置下限来稳定计算GMM用于说话人辨认的过程(假设被辨认的每个说话人的先验概率都是一样的) 对于 S 个说话人,经过参数估计后,得到 S 组参数 { λ s ∣ s = 1 , 2 , . . . , S } \left \{ \lambda_s|s=1,2,...,S \right \} {λs∣s=1,2,...,S}输入一组声学特征 X = { x n ∣ n = 1 , 2 , . . . , N } X=\left \{ x_n|n=1,2,...,N \right \} X={xn∣n=1,2,...,N},N可以等于1对应这组声学特征的最可能的说话人为 s ∗ = arg max 1 ≤ s ≤ S ln [ p ( X ∣ λ s ) ] = arg max 1 ≤ s ≤ S ∑ n = 1 N ln [ p ( x n ∣ λ s ) ] \begin{aligned} s^* &= \arg\max_{1 \le s \le S} \ln[p(X|\lambda_s)] \\ &= \arg\max_{1 \le s \le S} \sum_{n=1}^{N} \ln[p(x_n|\lambda_s)] \end{aligned} s∗=arg1≤s≤Smaxln[p(X∣λs)]=arg1≤s≤Smaxn=1∑Nln[p(xn∣λs)] 取对数是为计算简便 GMM的缺点 GMM假设被辨认的每个说话人的先验概率都是一样的,这其实上限制了GMM只能用于闭集的说话人辨认问题,GMM不能用于区分仿冒说话人和注册说话人,对于开集说话人辨认问题,GMM效果并不好由于每个说话人对应于一个GMM,所以当说话人的话语样本非常少时,GMM的参数估计非常不可靠,很容易过拟合,如果要求用户提供大量的话语用于注册,则会显著降低用户体验 GMM-UBM(Universal Background Model,通用背景模型)对于GMM的上述缺点,研究人员提出了另一个GMM模型,称为UBM。 UBM是说话人无关(Speaker-independent)的GMM模型,用于表示区分仿冒说话人和注册说话人GMM-UBM基于假设检验 假设 H 0 H_0 H0:当前话语来自于假设的注册说话人假设 H 1 H_1 H1:当前话语来自于仿冒说话人 两个假设的对数似然比: L ( X ) = ln p ( X ∣ λ ) − ln p ( X ∣ λ H 1 ) L(X) = \ln p(X|\lambda) - \ln p(X|\lambda_{H_1}) L(X)=lnp(X∣λ)−lnp(X∣λH1) 其中, ln p ( X ∣ λ ) \ln p(X|\lambda) lnp(X∣λ) 为假设的注册说话人的GMM对数似然概率 ln p ( X ∣ λ H 1 ) \ln p(X|\lambda_{H_1}) lnp(X∣λH1) 为UBM的对数似然概率若 L ( X ) > 0 L(X) > 0 L(X)>0,则接受假设 H 0 H_0 H0;否则,接受假设 H 1 H_1 H1 由于UBM本身也是一个GMM,所以可以用上述的方法进行参数估计,参数估计所用的数据为所有说话人的话语样本得到UBM之后,还需要得到每个说话人对应的GMM在GMM-UBM中,不去直接对GMM进行参数估计,而是根据UBM的参数,利用贝叶斯自适应(Bayesian Adaptation)方法,得到每个说话人对应的GMM参数贝叶斯自适应方法非常复杂,本文不去深究,而是给出贝叶斯自适应方法的优点 所有的说话人对应的GMM,都从UBM自适应而来,使这些GMM具有可比性由于UBM是基于大量说话人数据训练的,所以自适应到少样本说话人的GMM时,不会发生严重的过拟合实验表明,贝叶斯自适应方法能提升性能 贝叶斯自适应方法有不同的自适应策略 第一层:自适应所有参数,包括权重、均值和协方差矩阵第二层:自适应权重、冻结均值和协方差矩阵第三层:自适应均值,冻结权重和协方差矩阵 说话人识别领域最佳实践:自适应均值,冻结权重和协方差矩阵。对于这一策略: 如果将GMM的每个高斯分量的均值串联(Concatenate)起来,将得到一个较长的向量,称为 supervector 超向量超向量就是最早的声纹嵌入码(Speaker Embedding),每个说话人都对应于一个超向量 GMM-SVM(Support Vector Machine,支持向量机)在GMM-UBM框架下,每个说话人都可以被一个超向量表征,因此利用非线性支持向量机来对这些超向量进行分类,下面简述GMM-SVM方法(以后可能会出一期深入理解SVM) 线性SVM决策函数形式: w x − b wx-b wx−b。但在实际应用中,原始的样本点所在的空间,常常不具有线性可分性非线性SVM的步骤 先对原始样本点作非线性变换 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅),非线性变换后,得到一个新的样本空间新的样本空间应该具有线性可分性使用线性SVM进行分类 非线性SVM的核技巧(Kernel Trick)实际上,并不需要直接寻找非线性变换 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅)只需要对两个不同的样本应用核函数K(Kernel Function),使得核函数满足: K ( x 1 , x 2 ) = ϕ ( x 1 ) T ϕ ( x 2 ) K(x_1,x_2) = \phi(x_1)^T\phi(x_2) K(x1,x2)=ϕ(x1)Tϕ(x2)从而非线性SVM的决策函数就可以被定义为: g ( x ) = ∑ i = 1 N [ α i y i K ( x , x i ) ] + b g(x) = \sum_{i=1}^{N} [\alpha_iy_iK(x,x_i)] +b g(x)=i=1∑N[αiyiK(x,xi)]+b 其中, α i ≥ 0 \alpha_i \ge 0 αi≥0,需要从训练数据中得到对于非线性SVM,大部分 α i = 0 \alpha_i = 0 αi=0大于0的 α i \alpha_i αi 所对应的样本点,被称为非线性SVM的支持向量(也叫支持点)注意,核函数的运算结果是一个标量 常用核函数 非齐次多项式: K ( x 1 , x 2 ) = ( x 1 ⋅ x 2 + 1 ) d K(x_1,x_2)=(x_1 \cdot x_2 +1)^d K(x1,x2)=(x1⋅x2+1)d齐次多项式: K ( x 1 , x 2 ) = ( x 1 ⋅ x 2 ) d K(x_1,x_2)=(x_1 \cdot x_2)^d K(x1,x2)=(x1⋅x2)d高斯径向基核函数(Radial Basis Function Kenel,RBF Kernel): K ( x 1 , x 2 ) = exp ( − γ ∥ x 1 − x 2 ∥ 2 ) K(x_1,x_2)=\exp(-\gamma \left \| x_1 - x_2 \right \| ^2) K(x1,x2)=exp(−γ∥x1−x2∥2),其中 γ > 0 \gamma > 0 γ>0双曲正切: K ( x 1 , x 2 ) = tanh ( − κ x 1 ⋅ x 2 + c ) K(x_1,x_2)= \tanh (-\kappa x_1 \cdot x_2 +c) K(x1,x2)=tanh(−κx1⋅x2+c),其中 κ > 0 , c < 0 \kappa > 0, c0,c |
 本文要介绍的GMM、GMM-UBM、GMM-SVM就属于说话人编码器的范畴。
本文要介绍的GMM、GMM-UBM、GMM-SVM就属于说话人编码器的范畴。【本文地址】
公司简介
联系我们
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |