| 算法:BeamSearch算法【贪心、维特比的折中方案】【贪心算法:每次只选择概率最大的结果,作为当前时间步的输出】【维特比算法:利用动态规划得到最优解,但时间复杂度太大;O(N*V^2)】 | 您所在的位置:网站首页 › 各大算法的时间复杂度 › 算法:BeamSearch算法【贪心、维特比的折中方案】【贪心算法:每次只选择概率最大的结果,作为当前时间步的输出】【维特比算法:利用动态规划得到最优解,但时间复杂度太大;O(N*V^2)】 |
算法:BeamSearch算法【贪心、维特比的折中方案】【贪心算法:每次只选择概率最大的结果,作为当前时间步的输出】【维特比算法:利用动态规划得到最优解,但时间复杂度太大;O(N*V^2)】
|
Beam Search 是一种受限的宽度优先搜索方法,经常用在各种 NLP 生成类任务中,例如机器翻译、对话系统、文本摘要。 一、概述在生成文本的时候,通常需要进行解码操作,贪心搜索 (Greedy Search) 是比较简单的解码。假设要把句子 “I love you” 翻译成 “我爱你”。则贪心搜索的解码过程如下: Beam Search 对贪心搜索进行了改进,扩大了搜索空间,更容易得到全局最优解。Beam Search 包含一个参数 beam size k,表示每一时刻均保留得分最高的 k 个序列,然后下一时刻用这 k 个序列继续生成。下图展示了 Beam Search 的过程,对应的 k=2: 在第一个时刻,“我” 和 “你” 的预测分数最高,因此 Beam Search 会保留 “我” 和 “你”;在第二个时刻的解码过程中,会分别利用 “我” 和 “你” 生成序列,其中 “我爱” 和 “你爱” 的得分最高,因此 Beam Search 会保留 “我爱” 和 “你爱”;以此类推。 Beam Search 的伪代码如下: 伪代码中的 score 是得分函数,通常是对数似然概率值。
在进行模型评估的过程中,每次我们选择概率最大的token id作为输出,那么整个输出的句子的概率就是最大的么?
例如:传统的获取解码器输出的过程中,每次只选择概率最大的那个结果,作为当前时间步的输出,等到输出结束,我们会发现,整个句子可能并不通顺。虽然在每一个时间步上的输出确实是概率最大的,但是整体的概率确不一定最大的,我们经常把它叫做greedy search[贪心算法] 为了解决上述的问题,可以考虑计算全部的输出的概率乘积,选择最大概率的路径,这样可以达到全局最优解。但是这样的话,意味着如果句子很长,候选词很多,那么需要保存的数据就会非常大,需要计算的数据量就很大 那么Beam Search 就是介于上述两种方法的一个这种的方法,假设Beam width=2,表示每次保存的最大的概率的个数,这里每次保存两个,在下一个时间步骤一样,也是保留两个,这样就可以达到约束搜索空间大小的目的,从而提高算法的效率。Beam Search也不是全局最优。【维特比算法是全局最优】 beam width 是一个超参数。 beam width =1 时,就是贪心算法,beam width=候选词的时候,就是计算全部的概率。比如在下图中: 使用一个树状图来表示每个time step的可能输出,其中的数字表示是条件概率 黄色的箭头表示的是一种greedy search,概率并不是最大的 如果把beam width设置为2,那么后续可以找到绿色路径的结果,这个结果是最大的
下图是要给beam width=3的例子 首先输入start token ,然后得到四个输出(这里假设一个就四个输出:X,Y,Z,),选择概率最大三个,X,Y,W然后分别把X,Y,W放到下一个time step中作为输入,分别得到三组不同的输出(一共12个输出序列:XX, XY, XZ, X,YX, YY, YZ, Y,WX, WY, WZ, W),这12个输出中找到三个输出概率最大的三个(如下图:XX,XY,WY )保存到Beam中。然后分别把XX,XY,WY放到下一个time step中作为输入,分别得到三组不同的输出(一共12个输出序列:XXX, XXY, XXZ, XX,XYX, XYY, XYZ, XY,WYX, WYY, WYZ, WY),这12个输出中找到三个输出概率最大的三个(如下图:XXX,XYX,WYX )保存到Beam中。然后分别把XXX,XYX,WYX放到下一个time step中作为输入,分别得到三组不同的输出(一共12个输出序列:XXXX, XXXY, XXXZ, XXX,XYXX, XYXY, XYXZ, XYX,WYXX, WYXY, WYXZ, WYX),这12个输出中找到三个输出概率最大的三个(如下图:XYXW,XYXX,WYX )保存到Beam中。然后分别把XYXW,XYXX,WYX放到下一个time step中作为输入,分别得到三组不同的输出(一共12个输出序列:XYXWX, XYXWY, XYXWZ, XYXW,XYXXX, XYXXY, XYXXZ, XYXX,WYXX, WYXY, WYXZ, WYX),这12个输出中找到三个输出概率最大的三个(如下图:XYXW,XYXWY,XYXX)保存到Beam中。继续重复上述步骤,直到获得结束符时的序列概率最大或者是达到句子的最大长度max_len,结束循环。此时选择概率乘积最大的一个路径。拼接整个路径上概率最大的所有结果,比如这里可能是,X,Y,X,W,
对于MLE算法训练的模型,beam search只在预测的时候需要。训练的时候因为知道正确答案,并不需要再进行这个搜索。 预测的时候,假设词表大小为3,内容为a,b,c。beam size是2,decoder解码的时候: 生成第1个词的时候,选择概率最大的2个词,假设为a,c,那么当前的2个序列就是a、c。生成第2个词的时候,我们将当前序列a和c,分别与词表中的所有词进行组合,得到新的6个序列aa ab ac ca cb cc,计算每个序列的得分并选择得分最高2个序列,作为新的当前序列,假如为aa、cb。后面会不断重复这个过程,直到遇到结束符或者达到最大长度为止。最终输出得分最高的2个序列。 三、Beam serach的实现在上述描述的思路中,我们需要注意以下几个内容: 数据该如何保存,每一次的输出的最大的beam width个结果,和之后之前的结果该如何保存保存了之后的概率应该如何比较大小,保留下概率最大的三个不能够仅仅只保存当前概率最大的信息,还需要有当前概率最大的三个中,前面的路径的输出结果 1、数据结构-堆-的认识对于上面所说的,保留有限个数据,同时需要根据大小来保留,可以使用一种带有优先级的数据结构来实现,这里我们可以使用堆这种数据结构 堆是一种优先级的队列,但是他其实并不是队列 队列都是先进先出或者是先进后出,堆只根据优先级的高低来取出数据。栈是一种先进后出的数据结构,有入栈和出栈的操作在python自带的模块中,有一个叫做heapq的模块,提供了堆所有的方法。通过下面的代码我们来了解下heapq的使用方法 my_heap = [] #使用列表保存数据 #往列表中插入数据,优先级使用插入的内容来表示,就是一个比较大小的操作,越大优先级越高 heapq.heappush(my_heap,[29,True,"xiaohong"]) heapq.heappush(my_heap,[28,False,"xiaowang"]) heapq.heappush(my_heap,[29,False,"xiaogang"]) for i in range(3): ret= heapq.heappop(my_heap) #pop操作,优先级最小的数据 print(ret) #输出如下: [28, False, 'xiaowang'] [29, False, 'xiaogang'] [29, True, 'xiaohong']可以发现,输出的顺序并不是数据插入的顺序,而是根据其优先级,从小往大pop(Falseself.beam_width: heapq.heappop(self.heap) def __iter__(self):#让该beam能够被迭代 return iter(self.heap) 实现方法,完成模型eval过程中的beam search搜索 思路: 构造开始符号等第一次输入的信息,保存在堆中取出堆中的数据,进行forward_step的操作,获得当前时间步的output,hidden从output中选择topk(k=beam width)个输出,作为下一次的input把下一个时间步骤需要的输入等数据保存在一个新的堆中获取新的堆中的优先级最高(概率最大)的数据,判断数据是否是EOS结尾或者是否达到最大长度,如果是,停止迭代如果不是,则重新遍历新的堆中的数据代码如下 # decoder中的新方法 def evaluatoin_beamsearch_heapq(self, encoder_outputs, encoder_hidden): """使用 堆 来完成beam search,对是一种优先级的队列,按照优先级顺序存取数据""" batch_size = encoder_hidden.size(1) # 1. 构造第一次需要的输入数据,保存在堆中 decoder_input = torch.LongTensor([[word_sequence.SOS] * batch_size]).to(config.device) decoder_hidden = encoder_hidden # 需要输入的hidden(初始化Decoder的hidden为Encoder的最终的hidden) prev_beam = Beam() prev_beam.add(1, False, [decoder_input], decoder_input, decoder_hidden) while True: cur_beam = Beam() # 2. 取出堆中的数据,进行forward_step的操作,获得当前时间步的output,hidden【这里使用下划线进行区分】 for _probility, _complete, _seq, _decoder_input, _decoder_hidden in prev_beam: # 判断前一次的_complete是否为True,如果是,则不需要forward【有可能为True,但是概率并不是最大】 if _complete == True: cur_beam.add(_probility, _complete, _seq, _decoder_input, _decoder_hidden) else: decoder_output_t, decoder_hidden, _ = self.forward_step(_decoder_input, _decoder_hidden, encoder_outputs) value, index = torch.topk(decoder_output_t, config.beam_width) # [batch_size=1,beam_widht=3] # 3. 从output中选择topk(k=beam width)个输出,作为下一次的input for m, n in zip(value[0], index[0]): decoder_input = torch.LongTensor([[n]]).to(config.device) seq = _seq + [n] probility = _probility * m if n.item() == word_sequence.EOS: complete = True else: complete = False # 4. 把下一个实践步骤需要的输入等数据保存在一个新的堆中 cur_beam.add(probility, complete, seq, decoder_input, decoder_hidden) # 5. 获取新的堆中的优先级最高(概率最大)的数据,判断数据是否是EOS结尾或者是否达到最大长度,如果是,停止迭代 best_prob, best_complete, best_seq, _, _ = max(cur_beam) if best_complete == True or len(best_seq) - 1 == config.max_len: # 减去sos return self._prepar_seq(best_seq) else: # 6. 则重新遍历新的堆中的数据 prev_beam = cur_beam def _prepar_seq(self, seq): # 对结果进行基础的处理,共后续转化为文字使用 if seq[0].item() == word_sequence.SOS: seq = seq[1:] if seq[-1].item() == word_sequence.EOS: seq = seq[:-1] seq = [i.item() for i in seq] return seq 四、Beam Search得分函数优化对数似然得分函数: 这个方法是论文《Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation》中提出的。包含两个部分: length normalization;coverage penalty。在采用对数似然作为得分函数时,Beam Search 通常会倾向于更短的序列。 因为对数似然是负数,越长的序列在计算 score 时得分越低 (加的负数越多)。在得分函数中引入 length normalization 对长度进行归一化可以解决这一问题。coverage penalty 主要用于使用 Attention 的场合,通过 coverage penalty 可以让 Decoder 均匀地关注于输入序列 x 的每一个 token,防止一些 token 获得过多的 Attention。把对数似然、length normalization 和 coverage penalty 结合在一起,可以得到新的得分函数,如下面的公式所示: 在对话模型中解码器通常会生成一些过于通用的回复,回复多样性不足。例如不管用户问什么,都回复 “我不知道”。为了解决对话模型多样性的问题,论文《A Diversity-Promoting Objective Function for Neural Conversation Models》中提出了采用最大化互信息 MMI (Maximum Mutual Information) 作为目标函数。其也可以作为 Beam Search 的得分函数,如下面的公式所示。 互信息得分函数: 论文《Best-First Beam Search》关注于提升 Beam Search 的搜索效率,提出了 Best-First Beam Search 算法,Best-First Beam Search 可以在更短时间内得到和 Beam Search 相同的搜索结果。论文中提到 Beam Search 的时间和得分函数调用次数成正比,如下图所示,因此作者希望通过减少得分函数的调用次数,从而提升 Beam Search 效率。 参考资料: [L2]seq2seq中Beam search~贪心与维特比 Beam Search快速理解及代码解析(上) 详细介绍 Beam Search 及其优化方法 【RNN】深扒能提高预测准确率的beam search |
 贪心搜索每一时刻只选择当前最有可能的单词,例如在预测第一个单词时,“我” 的概率最大,则第一个单词预测为 “我”;预测第二个单词时,“爱” 的概率最大,则预测为 “爱”。贪心搜索具有比较高的运行效率,但是每一步考虑的均是局部最优,有时候不能得到全局最优解。
贪心搜索每一时刻只选择当前最有可能的单词,例如在预测第一个单词时,“我” 的概率最大,则第一个单词预测为 “我”;预测第二个单词时,“爱” 的概率最大,则预测为 “爱”。贪心搜索具有比较高的运行效率,但是每一步考虑的均是局部最优,有时候不能得到全局最优解。
 每一步 Beam Search 都会维护一个 k-最大堆 (即伪代码中的 B),然后用上一步的 k 个最高得分的序列生成新序列,放入最大堆 B 里面,选出当前得分最高的 k 个序列。
每一步 Beam Search 都会维护一个 k-最大堆 (即伪代码中的 B),然后用上一步的 k 个最高得分的序列生成新序列,放入最大堆 B 里面,选出当前得分最高的 k 个序列。
 Beam search的又被称作束集搜索,是一种seq2seq中用来优化输出结果的算法(不在训练过程中使用,而是在评估或预测时使用)。
Beam search的又被称作束集搜索,是一种seq2seq中用来优化输出结果的算法(不在训练过程中使用,而是在评估或预测时使用)。
 其中:
其中: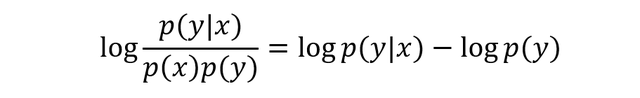 最大化上面的得分函数可以提高模型回复的多样性,即需要时 p(y|x) 远远大于 p(y)。这样子可以为每一个输入 x 找到一个专属的回复,而不是通用的回复。
最大化上面的得分函数可以提高模型回复的多样性,即需要时 p(y|x) 远远大于 p(y)。这样子可以为每一个输入 x 找到一个专属的回复,而不是通用的回复。【本文地址】