|
#include "stdio.h"
struct stu{
char name;
int age;
char sex;
};
struct stu student{'M',20,'f'};
int main()
{
printf("0x%x\n", student);
printf("0x%x\n", &student);
printf("0x%x\n", (&student)[0]);
printf("0x%x\n", (&student)[10]);
printf("0x%x\n", &student.name);
}
输出
0x61fe10
0x403010
0x61fe10
0x61fe10
0x403010
続行するには何かキーを押してください . . .
引用知乎的用户的结论。 https://www.zhihu.com/question/308153975/answer/569076494
作者:匿名用户 链接:https://www.zhihu.com/question/308153975/answer/569076494 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
我来改错啦,之前我说结构体名和数组名一样都是代表数组首元素和结构体第一个成员地址,这是不对的,对于数组可以这样说,但是对于结构体不成立(全是编译器耍的小把戏…)我写了个小程序测试:int main(){
struct stu {
char *name;
char *stunum;
} xiaoming;
xiaoming.name = (char*)0x12345678;
printf("0x%x\n", xiaoming);
printf("0x%x\n", xiaoming.name);
printf("0x%x\n", &xiaoming);
printf("0x%x\n", &xiaoming.name);
printf("0x%x\n", &xiaoming.stunum);
}首先看这个程序输出了什么,重点关注xiaoming的值和xiaoming.name的值以及&xiaoming有什么区别: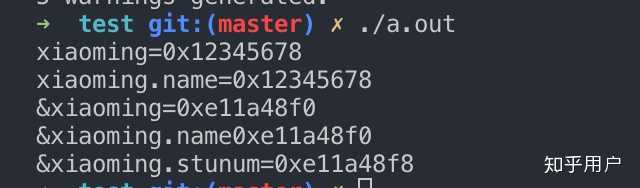 可以看到直接输出结构体的名字xiaoming的值不同于结构体取地址&xiaoming,而是输出的是结构体的第一个元素的值,也就是xiaoming.name这个指针的值。之所以是这样全是编译器的决定: 可以看到直接输出结构体的名字xiaoming的值不同于结构体取地址&xiaoming,而是输出的是结构体的第一个元素的值,也就是xiaoming.name这个指针的值。之所以是这样全是编译器的决定: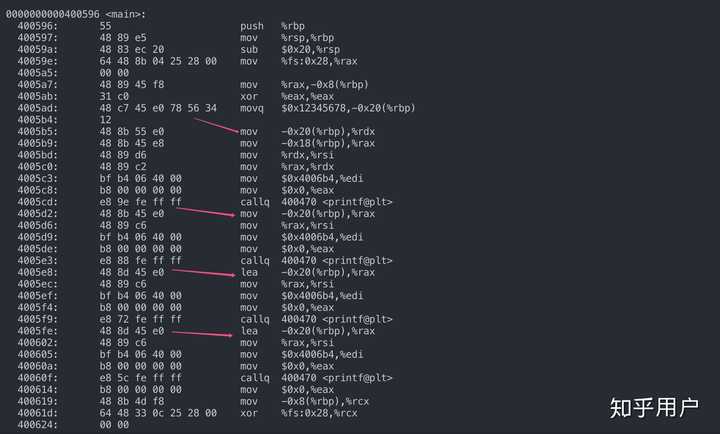 看我上面箭头所指向的四个地方,前两个分别对应 printf(“0x%x\n”, xiaoming); printf(“0x%x\n”, xiaoming.name);这两个,也就是在计算xiaoming的值和xiaoming.name的值,此时编译器使用的都是mov,也就是将xiaoming.name那个地址所放的值移动到rdx和rax寄存器。而后两个分别对应: printf(“0x%x\n”, &xiaoming); printf(“0x%x\n”, &xiaoming.name);注意到这里编译器使用的是lea,这是计算地址的指令,而不会取地址里面的值,所以这两个的输出都是xiaoming.name的地址,而不是xiaoming.name的值。所以这就说明了结构体名的值和结构体取地址是不一样的,前一个是代表结构体首元素的值,后一个是代表结构体首元素的地址。同样,我写了一个关于数组名的值和取数组名地址的验证小程序:int main(){ int num[10]; printf(“num=0x%x\n”, num); printf("&num=0x%x\n", &num); printf(“num[2]=0x%x\n”, num[2]); printf("&num[2]=0x%x\n", &num[2]); }输出: 看我上面箭头所指向的四个地方,前两个分别对应 printf(“0x%x\n”, xiaoming); printf(“0x%x\n”, xiaoming.name);这两个,也就是在计算xiaoming的值和xiaoming.name的值,此时编译器使用的都是mov,也就是将xiaoming.name那个地址所放的值移动到rdx和rax寄存器。而后两个分别对应: printf(“0x%x\n”, &xiaoming); printf(“0x%x\n”, &xiaoming.name);注意到这里编译器使用的是lea,这是计算地址的指令,而不会取地址里面的值,所以这两个的输出都是xiaoming.name的地址,而不是xiaoming.name的值。所以这就说明了结构体名的值和结构体取地址是不一样的,前一个是代表结构体首元素的值,后一个是代表结构体首元素的地址。同样,我写了一个关于数组名的值和取数组名地址的验证小程序:int main(){ int num[10]; printf(“num=0x%x\n”, num); printf("&num=0x%x\n", &num); printf(“num[2]=0x%x\n”, num[2]); printf("&num[2]=0x%x\n", &num[2]); }输出: 符合我们的认知,数组名和数组名取地址都是相同的。那么编译器又是怎么做的呢? 符合我们的认知,数组名和数组名取地址都是相同的。那么编译器又是怎么做的呢?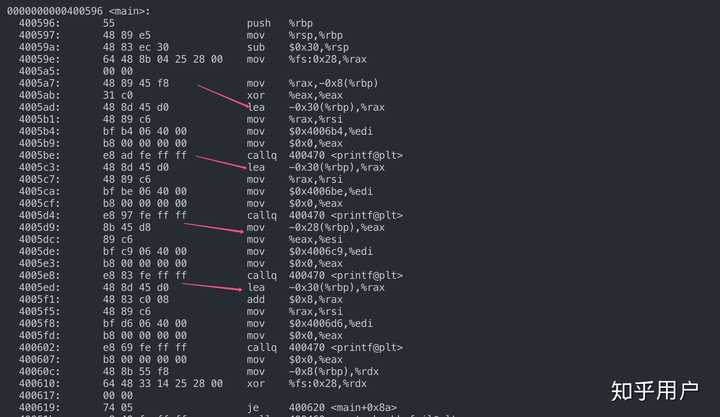 看,编译器对于数组名和数组名取地址的计算方式是一样的都是使用lea指令计算地址。第三个访问num[2]的对应指令使用的是mov。所以,总结下结论吧:数组名和对数组名取地址都是一样的,代表数组首元素的地址,编译器都是使用lea指令结构体名和对结构体名取地址不一样,前者代表结构体首元素的值,后者代表结构体首元素地址,原因在于编译器对结构体名使用的是mov指令,而不是lea现在回答一下题主上面的问题:在我机器ubuntu16.04(小端)上跑了一下: 看,编译器对于数组名和数组名取地址的计算方式是一样的都是使用lea指令计算地址。第三个访问num[2]的对应指令使用的是mov。所以,总结下结论吧:数组名和对数组名取地址都是一样的,代表数组首元素的地址,编译器都是使用lea指令结构体名和对结构体名取地址不一样,前者代表结构体首元素的值,后者代表结构体首元素地址,原因在于编译器对结构体名使用的是mov指令,而不是lea现在回答一下题主上面的问题:在我机器ubuntu16.04(小端)上跑了一下: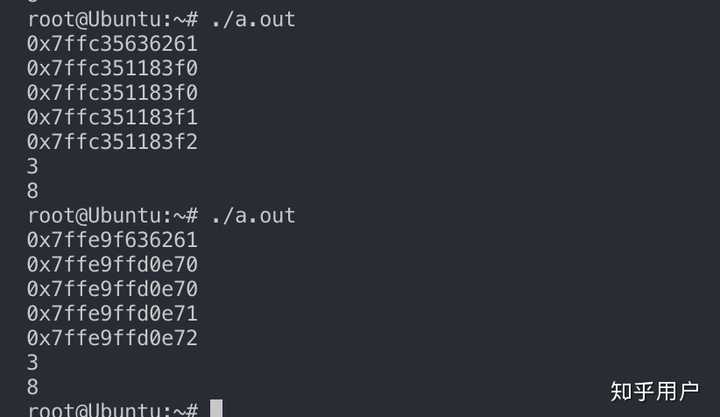 注意到每次运行第一个输出都是不确定的,唯一确定的就是后面那三个字节都是0x636261,为什么呢? 上面已经说过使用%x %d之类输出结构体名是直接将结构体的首元素的值输出,其实是不准确的,实际上是从首元素开始的四个字节或八个字节一起输出,所以这里不只是输出’a’的ascii的值61, 为什么输出最后三个字节一定是0x636261了,上面已经说了,我是小端机器,‘a’,‘b’, ‘c’的地址递增1,按照小端的特点就是低位放在低地址,所以’a’=61在最低位,'b’其次…还有一个特点其实前面那几个字节的值和下面输出地址的是一样的!!也就是0x7ffc35和0x7ffe9f, 其实这也不是偶然,因为字符’c’存储地址的上面就是ebp所指向的地方,而ebp指向的栈里存的是上一个函数的ebp,栈上相近栈帧的前面几个字节肯定是一样呀。如果看不懂这段话的话,去搜一下函数调用栈帧就明白了。至于题主的第一个问题为什么少了16个字节,我的答案是这是偶然,并且看题主的输出,应该不是小端。第二个问题sizeof(&a)为什么是8,&a是一个指针,对指针应用sizeof其实就是机器的字长,题主应该是64位机。第三个问题多的16个字节是属于结构体吗?已经说了,并不是多16字节,而是偶然又来知乎滑了这么久的水,真是愧疚,我要去复习了,还没期末考呢-----原回答,有错误-----结构体和数组其实差不多,区别就是数组元素大小一样,结构体元素大小可以不一致,而编译器在访问内部元素的时候都是一样的方式: 基址变址。就是数组名和结构体名作为寄地址,然后加上元素相对起始地址的偏移量。我们都知道数组名代表了数组的起始地址,那么结构体也是同样的道理。 注意到每次运行第一个输出都是不确定的,唯一确定的就是后面那三个字节都是0x636261,为什么呢? 上面已经说过使用%x %d之类输出结构体名是直接将结构体的首元素的值输出,其实是不准确的,实际上是从首元素开始的四个字节或八个字节一起输出,所以这里不只是输出’a’的ascii的值61, 为什么输出最后三个字节一定是0x636261了,上面已经说了,我是小端机器,‘a’,‘b’, ‘c’的地址递增1,按照小端的特点就是低位放在低地址,所以’a’=61在最低位,'b’其次…还有一个特点其实前面那几个字节的值和下面输出地址的是一样的!!也就是0x7ffc35和0x7ffe9f, 其实这也不是偶然,因为字符’c’存储地址的上面就是ebp所指向的地方,而ebp指向的栈里存的是上一个函数的ebp,栈上相近栈帧的前面几个字节肯定是一样呀。如果看不懂这段话的话,去搜一下函数调用栈帧就明白了。至于题主的第一个问题为什么少了16个字节,我的答案是这是偶然,并且看题主的输出,应该不是小端。第二个问题sizeof(&a)为什么是8,&a是一个指针,对指针应用sizeof其实就是机器的字长,题主应该是64位机。第三个问题多的16个字节是属于结构体吗?已经说了,并不是多16字节,而是偶然又来知乎滑了这么久的水,真是愧疚,我要去复习了,还没期末考呢-----原回答,有错误-----结构体和数组其实差不多,区别就是数组元素大小一样,结构体元素大小可以不一致,而编译器在访问内部元素的时候都是一样的方式: 基址变址。就是数组名和结构体名作为寄地址,然后加上元素相对起始地址的偏移量。我们都知道数组名代表了数组的起始地址,那么结构体也是同样的道理。
—————————————————————————————— 另一个非常有意思的结论就是 (&结构体名)[n] 无论n取什么值其结果都和 结构体名 的含义相同。原因未知。
|