| RTX 4090的TPP总计算能力究竟应该怎么算? – 笔记本电脑评测 | 您所在的位置:网站首页 › 口径是怎么计算的呢 › RTX 4090的TPP总计算能力究竟应该怎么算? – 笔记本电脑评测 |
RTX 4090的TPP总计算能力究竟应该怎么算? – 笔记本电脑评测
|
RTX 4090可能受到管制这个说法,来自于英伟达提交给SEC的文件当中,提到了这么一句。 
integrated circuits exceeding certain performance thresholds (including but not limited to the A100, A800, H100, H800, L40, L40S, and RTX 4090) 集成电路超过了特定的性能标准(包括但不限于A100, A800, H100, H800, L40, L40S, and RTX 4090)。 换而言之,NVIDIA确认了RTX 4090是超过了一个特定的性能标准。超过标准不等于禁售,因为BIS针对的是数据中心类。 这里面提到的“新的性能标准”,主要是指BIS新增了一个TPP计算能力的概念。传送门:https://www.bis.doc.gov/index.php/documents/federal-register-notices-1/3353-2023-10-16-advanced-computing-supercomputing-ifr/file BIS原文有295页,没有人能完整读下来。我们只能通过搜索关键词的方式,找到了对于TPP,total processing performance,总计算能力的定义。 
TPP = 2 * MacTOPS * bit length of the operation 所谓的MacTOPS,是指最大的相乘累加操作的能力,也就是D=A*B+C,算作一次操作。 前面要乘一次2,是因为乘和加,一次操作实际上是两次运算。 而采用了该操作的比特长度,我看有很多媒体误解为什么显存位宽了,这是错误的。这意思是说处理的数据比特长度作为一个系数相乘,例如FP32就要乘上32,FP16就乘以16,INT 8就乘以8。 如果一个集成电路当中有不同的处理单元,需要将每一个处理单元的TPP累加。但是对于同一个单元,取最大TPP。TPP这个概念的提出,主要针对的是市面上的算力统计口径繁多。比如说OPPO在手机上的NPU,算力是18TOPS,但口径是INT 8。用TPP计算你就会发现,这玩意是18*8 = 144。 
现在有了TPP这个概念,相当于建立起了不同的操作比特长度统计口径算力下的统一化比较标准。 回到这边说的RTX 4090,网络上广为流传的中信证券PPT截图,计算应该是错误的。 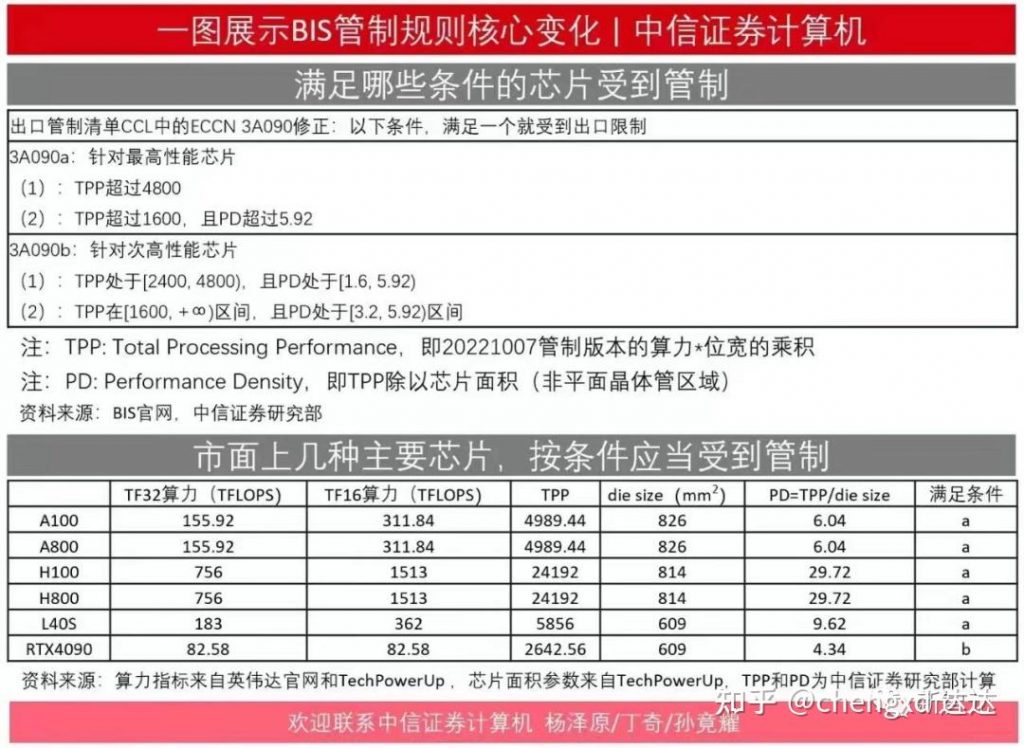
首先是所谓的TFLOPS,不等于MacTOPS。一般而言,市面上的TFLOPS作为宣传口径,是已经乘2之后的结果。BIS文件当中提到的这一句就是这个意思—— Therefore, 2 x MacTOPS may correspond to the reported TOPS or FLOPS on a datasheet. A100作为专业卡,英伟达则提供了官方的算力表,所以所有的算力统计口径都是一目了然的。 
英伟达官网从未提供过官方的参数表来标注RTX 4090的算力,所以这份研报只能引述TechPowerUP的数据,是一个二手数据,并不准确。 关于RTX 4090的算力水平,可以从英伟达的新品发布新闻稿里面有一个语焉不详的解释。 这款猛兽级 GPU 由 24GB 的 G6X VRAM(运行速度为 21Gbps)支持,提供 16,384 个 CUDA 核心,以及高达 1,321 Tensor-TFLOPS、191 RT-TFLOPS 和 83 Shader-TFLOPS 的性能。 Ada 架构采用了全新的第四代 Tensor Core ,它采用全新的 8 位浮点 (FP8) Tensor Engine ,使得吞吐量相较之前提高到令人难以置信的 5 倍之多,在 GeForce RTX 4090 上可达 1.32 Tensor-petaFLOPS! 当然,这个1321是稀疏化矩阵口径下,用传统方式下计算是660 TFLOPS。于是,FP8的口径下有660 T * 8,妥妥的超过了4800的标准。 性能超过标准的同时,究竟是不是视作数据中心卡,还是仅仅当作一个消费级显卡,这就有操作空间了。 |
【本文地址】