| 特稿 | 温忠麟 谢晋艳 王惠惠:潜在类别模型的原理、步骤及程序 | 您所在的位置:网站首页 › 变量要求 › 特稿 | 温忠麟 谢晋艳 王惠惠:潜在类别模型的原理、步骤及程序 |
特稿 | 温忠麟 谢晋艳 王惠惠:潜在类别模型的原理、步骤及程序
|
与LCA类似的是潜在剖面分析(Latent Profile Analysis, LPA; Gibson, 1959),LCA中的外显变量是类别变量,而LPA中的外显变量是连续变量(Lazarsfeld & Henry, 1968)。两者的分析结果都是将个体划分为潜在类别,在教育与心理测验、社会心理调查、心理诊断、人才测评等研究中得到越来越多的应用。例如,儿童心理数线表征方式(臧蓓蕾等, 2017)、小学生时间分配模式(张文明, 陈嘉晟, 2022)、早期代数思维水平(孙思雨等, 2022)、初中生的外化问题行为 (廖友国等, 2021)、家校关系模式(黄菲菲等, 2018)等都存在群体异质性,通过LCA或者LPA分出了潜在类别。LCA和LPA应用于教育学研究领域,一方面可以提高教育研究的量化水平,丰富教育研究内容;另一方面可以更加全面地了解学生以及教师在教育教学过程中的差异化特征,有利于因材施教促进教学。 对于追踪数据,基于LCA和LPA都可以做潜在转变分析(Latent Transition Analysis, LTA; Collins & Lanza, 2010),得到个体在两个时间点的潜在类别归属及跨时间的潜在类别转变模式,可用于评估诸如教育政策、行为干预、心理治疗等的效果。 本文首先从比较宏观的视角介绍LCA和LPA,说明它们是什么样的统计方法。然后提供统计原理涉及的基础知识,主要是概率方面的知识。接着讲述LCA和LPA(以及LTA)的原理、步骤。最后介绍后续分析,并给出主要模型的Mplus (Muthén & Muthén, 1998−2022)程序及其解释。 一、变量为中心的方法与被试为中心的方法 变量为中心的方法(variable-centered)与被试(个体)为中心的方法(person-centered)是当前心理学、教育学、管理学等社科研究领域量化方法的两种主流取向。两者各有特点,并相互补充,为我们更加全面和客观地认识研究对象提供了不同的视角。 变量为中心的方法主要探究变量之间的关系(Muthén & Muthén, 2000; 尹奎等, 2020),其前提假设是研究的群体具有相同的特征,可通过抽样分析样本的特征来推论总体的特征。大家熟知的相关分析、回归分析和因子分析等都属于变量为中心的方法。相关分析可以研究两个或多个变量之间是否存在共变关系,如学生的数学成绩和数学自我概念正相关。回归分析可以研究某个变量的变化在多大程度上可以由其他变量的变化来解释和预测,如员工的工作满意度对薪资水平和工作压力的回归分析显示,薪资水平正向预测工作满意度,工作压力负向预测工作满意度。因子分析是根据相关性大小将变量分组,使得同组变量之间的相关性较高,每组变量对应于一个因子。从测量的角度看,一个题目就是一个变量,因子是用一组题目测量得到的潜在特质。 LCA和LPA是基于统计模型的分类方法,相应的模型统称为潜在类别模型(Lazarsfeld & Henry, 1968; 邱皓政, 2008),它默认有类别潜变量(通常是一个)影响被试在测验题目上的作答反应,因而可以通过作答反应模式反推个体的所属类别,实现对被试的分类。LCA针对类别计分的测验题目,LPA针对连续(或者可以合理视为连续)计分的测验题目。在潜在类别模型中可以纳入协变量,变量类型不受限制,可以是任意尺度的变量或各种尺度变量的混合(Hagenaars & McCutcheon, 2002)。 与潜在类别模型关联较大的一个统计方法是聚类分析,两者的目的都是将个体分类。聚类分析基于距离度量按空间位置进行分类,因而分类结果与使用的尺度单位有关。每个被试都对应于空间中的一个点,通常使用被试之间的距离或相似性进行聚类,将距离相近的个体或者相似性高的个体分在同一类(刘红云, 2019)。与聚类分析相比,潜在类别模型的前提较弱,相对客观,较容易拓展,能实现更多的统计功能。 与潜在类别模型关联较大的另一个统计方法是因子分析,两者都属于潜变量的测量模型(measurement model),用少量的潜变量来解释外显指标之间的关联,被潜变量解释后的外显指标间实现局部独立性。因子分析属于变量为中心的方法,分析结果是将外显变量分类,每一类对应于一个因子(连续的潜变量)。潜在类别模型属于被试为中心的方法,分析结果是对个体分类,每一类对应于一个潜在类别,即潜变量是类别变量。两者在外显指标和潜变量的分布形态、性质方面也有不同(王孟成, 毕向阳, 2018 b)。此外,还有研究关注潜在类别分析与因子分析的结合体——因子混合模型的发展及应用(陈宇帅等, 2015)。 总之,变量为中心的方法和被试为中心的方法从不同的角度揭示了研究对象的特征,可以对研究对象有更全面的认识。变量为中心的方法主要是探讨研究对象的群体特征(或者说共性),而被试为中心的方法先考虑研究对象可能存在的异质性(或者说个性),将对象分成若干子群体后再探讨其共性,从而减少误差,提高精确性。 二、潜在类别分析涉及的基础知识 潜在类别分析需要的基础知识主要有:条件概率(conditional probability)、全概率公式、贝叶斯公式、类别变量的联合分布与边际分布、衡量分布拟合程度的卡方统计量。读者对所述基础知识有了解便可,公式的推导可以忽略不看,需要系统学习的读者可阅读概率统计相关教科书(例如, 温忠麟, 2016)。 (一)条件概率 举一个例子来解说概率与条件概率。某市对高三学生(以下简称学生)做数学学业水平测试,测试结果分为及格和不及格。随机抽查一个学生是及格(记为事件A)的概率有多大?这是通常的概率问题,这个概率等于及格学生所占的比例(记为P(A))。具体到LCA中,如果将学生按数学学业水平分成高、中、低三类,每类占比多少?属于通常的概率问题。 如果已知被抽查的学生来自重点中学,及格的概率有多大,这相当于从重点中学随机抽查一个学生,及格的概率有多大。这就是条件概率问题,这个概率等于重点中学及格学生所占的比例。类似的条件概率还有,从普通中学随机抽查一个学生测试及格的概率,等等。一般地,将 “事件B出现的条件下事件A出现的概率”称为条件概率,记为P(A|B)。 上面提到的中学类型(重点中学与普通中学)是显在类别,可以直接观测得到。学生也可以按学业水平分成高、中、低三种类型,这种分类就是潜在类别,不能直接观测得到。具体到LCA中,需要根据学生的答题表现分别估计其属于高、中、低类别的概率(category probability),还要估计高、中、低各种类别学生答对每个题目的条件概率。 一般情况下,条件概率P(A|B)与无条件概率P(A)是不相等的,条件概率可以用下面公式计算:
上面公式容易推广到多个相互独立事件的概率乘法公式。
具体到LCA中,潜在类别(如学业水平高、中、低类别)就构成必然事件U的一种互斥分割。上述的事件A可以是某道题目上的表现(例如,答对得1分)或者整份试题上的表现(例如,前2题答对得1分,其余题目答错得0分)。
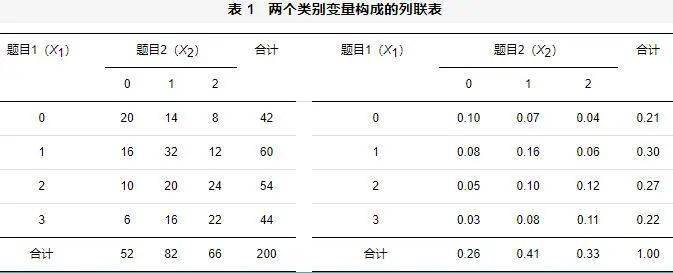
上式就是贝叶斯公式,最后一个等式的分子使用了概率乘法公式(2)、分母使用了全概率公式(4)。 具体到LCA中,高水平(中水平、低水平)学生答对每个题目的概率是先验概率(对于多级计分题目,可以是得到某个分值的概率)。而知道一个学生的答题结果(每个题目上的表现)后,计算其属于高、中、低水平类别的概率,就是后验概率。LCA将学生归入后验概率最大的那个潜在类别。 (四)变量的联合分布与边际分布 在LCA的参数估计过程中,需要利用变量的联合分布和边际分布的概率进行迭代计算。为了方便理解,沿用本文开头的例子,两个类别变量为 X 1 和 X 2 , X 1 有4种可能取值(0, 1, 2, 3), X 2 有3种可能取值(0, 1, 2)。200个学生的得分情况可以整理成表1那样的二维列联表,左表列出的是频数(人数),右表列出的是频率。左右两个表其实是等价的,只相差一个常数因子(左表数据除以总人数便得到右表数据),可以根据需要决定使用频数还是频率,以后称这些频数或频率为样本的数据点(data point)。
上述公式可以推广到测验包含多个题目(即有多个变量)、分成多个潜在类别的情况。用文字来描述就是,每个可能的数据点,有一个观测人数,还有一个估计人数,可以计算两者之差的平方除以估计人数,然后对所有数据点求和,就是卡方值了。至于卡方统计量的自由度,不像通常的列联表分析中的卡方那么简单,而与需要估计的参数个数有关(见3.2节)。另一个类似的卡方统计量称为似然比卡方(Likelihood Ratio Chi-Square; Hagenaars & Mccutcheon, 2002): 三、潜在类别分析原理与步骤
在我们的例子中,第一个指标有4个水平,第二个指标有3个水平,共有4×3−1个独立的频率(减去1是因为全部频率之和等于1,所以最后一个频率完全由其余的频率所确定),这是样本提供的全部信息。 一般的LCA分析,需要估计的参数有两种:一是类别概率(即每类个体占总体的比例),共有K−1个类别概率需要估计(因为K个类别概率之和等于1,所以最后一类的概率不用估计);二是每个类别的个体在各个指标上得分的条件概率。条件概率反映了每类个体在各个指标上是如何表现的(例如类别3的个体在第一个指标得2分的概率)。对于指标1,共有4个水平(0—3分),每一类别都要估计取值0, 1, 2, 3的条件概率,有4−1个条件概率需要估计(减去1是因为4个条件概率之和等于1);同样,对于指标2,有3−1个条件概率需要估计。这样,对于每一类别,需要估计的条件概率有(4−1)+(3−1)个,这个数乘上K就是全部K类被试需要估计的条件概率。
(三)参数估计
这样,对每一类,合计需要估计5个条件概率。如果分成3个类别(K=3),共需要估计15个条件概率,连同2个类别概率,一共需要估计17个参数。 与许多其他模型的参数估计一样,LCA的参数估计也需要一个迭代过程:从设定参数初值开始,多次用到条件概率公式、全概率公式和贝叶斯公式,计算得到新的参数估计值;周而复始,不断迭代计算,直到前后两次的估计值差异小于一个指定的数值(Mplus默认10−6)为止,称为模型收敛。如果经过一定的迭代次数(Mplus默认100次),前后两次的估计值差异还是不能小于指定的数值,模型是不收敛的(Muthén & Muthén, 1998−2022)。 参数估计的迭代过程详见附录一,没有兴趣的读者可以略过,不影响理解。 (四)模型比较与模型评价 由于通常不知道有几个潜在类别,一般会从潜在类别数为1的模型开始估计,逐步增加潜在类别数,得到每个模型的参数估计结果和模型拟合指数。 然后是模型比较和选择的过程,就是比较各个模型与样本数据的拟合度,根据模型拟合统计量选择最佳潜在类别数的模型。评价或检验模型拟合度的统计量主要有Pearson卡方和似然比卡方,基于对数似然函数值(loglikelihood, LL)的信息指数AIC(Akaike Information Criterion)、BIC(Baysian Information Criterion)、aBIC(adjusted Baysian Information Criterion),还有熵(entropy)。 Pearson卡方和似然比卡方的定义见2.5节,自由度的计算见(11)。卡方值与其自由度的比值越小,模型拟合越好。但在LCA中,更多的是比较信息指数、熵和模型可解释性(Collins & Lanza, 2010)。信息指数定义如下:
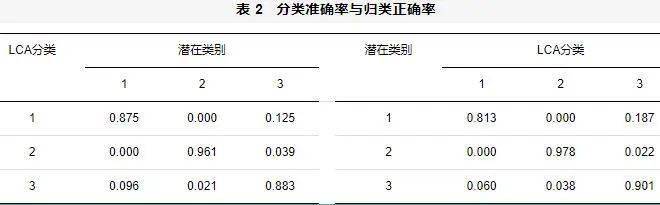
其中LL为对数似然函数值,t为需要估计的参数个数,N为样本容量(即被试人数)。LL可以这样理解:对于估计的参数(类别概率和条件概率)值,样本反应模式出现的概率就是似然函数值,似然函数值越大,说明越可能出现样本反应模式,对应的模型越好。通常假设题目之间是独立的,所以似然函数是各题得分概率的乘积,取自然对数后(成为对数似然函数LL)将乘积转换为加法,方便计算。对数函数是单调上升函数,因而LL也是越大越好。因为概率是小数,因而LL是负值。−2LL是正值,随LL增大而下降,即−2LL越小模型越好,所以信息指数的数值越小表示模型拟合越好。 除了比较信息指数大小,还可以基于Bootstrap的似然比检验(Bootstrapped Likelihood Ratio Test, BLRT; McLachlan, 1987)比较K−1个和K个类别模型之间的拟合差异,若检验显著则表明K个类别的模型优于K−1个类别的模型(Nylund et al., 2007)。 通常认为可以用熵衡量分类准确性。熵的定义如下(Collins & Lanza, 2010): 其中,K为类别个数,N为样本容量,为个体i属于类别k的后验概率。熵的取值范围在0—1之间,越接近1表明分类越准确,超过0.8模型可以接受,有研究发现此时分类准确率超过90% (Lubke & Muthén, 2007)。但也要注意,熵值受到样本量、类别距离和指标个数等因素的影响(王孟成等, 2017)。 更加具体衡量分类准确性的是分类准确性概率和归类正确性概率。在Mplus输出结果中有两个矩阵,应用工作者容易混淆。有一个表标识为“Average Latent Class Probabilities for Most Likely Latent Class Membership (Row) by Latent Class (Column)”[分类后各类(行)成员属于各潜在类别(列)的平均概率],这个就是分类准确率(见表2左表)。例如,P(潜在类别是第3类|分在第1类)=0.125。显然,对角线上的数值越高,分类准确性越高。还有一个表标识为“Classification Probabilities for the Most Likely Latent Class Membership (Column) by Latent Class (Row)”[各潜在类别(行)成员的归类(列)概率],这个就是归类正确率(见表2右表)。例如,P (分在第3类|潜在类别是第1类) = 0.187。显然,对角线上的数值越高,归类正确性越高。
此外,还要看类别概率,即每一类的人数比例,如果某类人数比例过小(如小于5%),说明该类的典型性不足,分类不够合理(Tein et al., 2013)。最后,要看待选的模型的可解释程度,综合考虑潜在类别的理论价值和实际意义,可以合理地给各类别命名。 (五)潜在类别分析步骤及结果报告 通常的潜在类别分析主要包含如下步骤: (1)指定一个潜在类别数。一个类别数对应于一个LCA模型。 (2)写出LCA程序(Mplus程序见附录2.1)。 (3)运行LCA模型,得到各种分析结果,包括模型参数估计、模型拟合指数、被试归属类别等。 重复步骤(1)至(3)。一般会从1类开始,并将相应模型作为比较的基准模型。逐步增加类别,直至研究者认为可以接受的最大类别数(通常不超过6)。 (4)模型比较与选择。通过模型比较决定一个类别数,得到相应的LCA分析结果。 (5)类别命名。根据条件概率反映的每类个体在各个指标上的表现对类别命名。 (6)通常都会进行后续统计分析(见第五节),包括以潜在类别为自变量做差异分析,以潜在类别为因变量做Logistic回归等。 对于LCA分析,通常会报告下面结果: (1)列表报告各类别数的模型拟合指数,通常(但不一定)包括卡方值及其自由度、信息指数、BLRT检验、熵和类别概率等(例见黄声华等,2023,表1)。据此确定一个类别数,后面报告其对应的模型分析结果。 (2)报告类别概率和条件概率(即参数估计结果),可以根据各类别个体在指标上取值的概率作图,以助理解类别命名。 (3)篇幅许可时,建议报告分类准确性概率。 四、潜在剖面分析和潜在转变分析简介 与LCA关系密切的是LPA和LTA。篇幅所限,这里对LPA和LTA只做简单介绍。 (一)潜在剖面分析 与LCA不同的是,LPA是用潜在类别(即LPA中的剖面)来解释外显的连续变量(指标)之间的关联(Mplus程序见附录2.1)。LPA的前提假设(Huang et al., 2011; 王孟成等, 2017):一是潜在类别间的互斥性;二是局部独立性,本来关联的连续显变量在被潜在类别变量解释后相互独立;三是在每个潜在类别内观测指标服从正态分布(但在总体内不要求正态分布)。与LCA相比,LPA多了一条分布假设。 LPA与LCA有同有异,两者的分析步骤大体相同。这里给出基本步骤并说明不同之处:第一步,建立潜在剖面模型,从基准模型(潜在类别数为1的模型)开始逐步增加潜在类别数,用某种方法(如极大似然法)估计模型参数和模型拟合指数。根据被试在连续显变量(指标)上的作答表现,利用后验概率将被试划分到后验概率较大的潜在类别中。因为外显变量是连续变量,需要用到与连续变量的概率分布有关的概念,如密度函数、条件密度函数等。要估计的模型参数是潜在类别概率和条件均值(而不是条件概率),而后验概率的计算也要使用连续显变量(指标)的均值和方差。第二步进行模型比较与选择,确定最佳潜在类别数,做法与LCA一样,不再赘述。第三步进行类别命名。通常也会做后续分析。 结果报告方面,要报告类别概率和条件均值、条件标准差(即各类别在每个指标得分的均值、标准差)。根据个体在外显连续变量上的条件均值作图,以便对潜在类别的特征进行概括并命名。其他与LCA结果报告基本相同。 (二)潜在转变分析 潜在转变分析(LTA),可以同时估计多个时间点的潜在类别,以及个体于不同时间点在潜在类别归属上的转换模式,是LCA或LPA在纵向数据分析中的拓展 (Collins & Lanza, 2010; 王碧瑶等, 2015)。LTA不仅能充分挖掘样本信息进行异质性分类,还能通过转变概率(latent transition probabilities)矩阵,从概率的角度描述不同类别子群体随时间变化的情况。 常用的是做两个时间点的LTA。通过LCA和LPA都可以做LTA,这里以LPA为例。首先要在不同的时间点做LPA,看看两个时间点确定的潜在类别数是否相同。如果不同,要在综合考虑后决定一个类别数。LTA前后的类别数要相同,谈论转变才有意义。不仅如此,各类别在每个指标上的均值和方差都应当有跨时间不变性(即在两个时间点分别相等)。例如,分在类别1的个体在每个指标上的均值,前后时间点要相等,使得两个时间点的类别1有相同的意义。这是写程序的时候要注意的(LTA的Mplus示例程序见附录2.2)。 以类别数3为例,LTA可以理解为类别数为32的LPA,估计出9类的类别概率,就有了一个3行3列的转变概率矩阵(例见何妍等, 2023, 表11)。每一行的概率之和等于1。第一行是在时间点1为类别1的个体,在时间点2的转变概率,例如第一行第二列的数值为类别1转到类别2的概率。其他行可作类似解释。显然,对角线上的数值是保持类别不变的概率,并非越大越好,而是希望“好类别”尽量保持,其他类别往“好类别”转变的概率越大越好。 LTA最重要的功能是报告转变概率矩阵,但也要报告模型拟合指数,才能对模型估计结果有信心。有研究在LTA的基础上,进一步提出了随机截距潜在转变分析(Random Intercept Latent Transition Analysis, RI-LTA; Muthén & Asparouhov, 2022; 温聪聪, 朱红, 2021),将跨时间点的自我转变和个体间的初始差异分离,减少了对保留在初始类别的概率的高估情况。 五、后续分析主要类型及相应的Mplus程序 潜在类别模型的后续分析是纳入协变量(auxiliary variable, 也称为辅助变量),分析协变量与潜在类别变量之间的关系。加入了协变量的模型称为条件(conditional)潜在类别模型,而未加入协变量的模型也称为无条件(unconditional)潜在类别模型。协变量在潜在类别模型中可以充当潜在类别变量的预测变量(predictor)或结果变量(英文文献常用distal outcome的概念,是相对于潜在类别变量的指标而言属于远端结果),也可以进行更复杂的二次建模(secondary model; Asparouhov & Muthén, 2014),以上分析类型统称为回归混合模型(regression mixture modeling)。例如,探讨性别对潜在类别的影响,协变量性别属于预测变量;探讨潜在类别对考试成绩的影响,协变量考试成绩属于结果变量;探讨学习动机对考试成绩的影响在不同潜在类别之间的差异,则是将潜在类别当作调节变量的二次建模。潜在类别模型引入协变量的方式有多种,可以大致划分为单步法和分步法(王孟成, 毕向阳, 2018a, 2018b)。 (一)单步法 单步法(one-step method)在建立带有协变量的潜在类别模型时,一步完成所有参数的估计,包括潜在类别的分组、潜在类别变量与协变量的关系(Bandeen-Roche et al., 1997)。这种方法类似于分析潜变量的结构方程建模,一次性完成测量模型和结构模型的参数估计。例如,某个研究要探讨不同性别的青少年攻击行为类型是否存在差异,可将性别直接纳入潜在类别模型中,一次建模就同时获得了攻击行为的潜在类别和不同攻击类别组的性别差异情况。但单步法存在一些缺陷:当有较多的协变量时,实际操作性差、建模困难、理解上较为抽象、难以满足混合模型的前提假设(王孟成, 毕向阳, 2018b),每次加入或者删除一个协变量,都需要重新估计测量模型(Vermunt, 2010)。 (二)不考虑分类误差的分步法 个体在归入潜在类别时并非概率为1,而是归入概率最大的那个类。不考虑分类误差,就是将归类概率当作1,相当于将个体的潜在类别当作显在类别进行分析。步骤如下: (1)建立测量模型(因子是类别变量):不纳入任何协变量,只根据外显指标,构建并估计潜在类别模型。 (2)得到潜类别变量:在上一步的基础上,将个体划分到后验概率最大的那个潜在类别。 (3)建立协变量模型(auxiliary model):将潜在类别当作通常的类别变量进行后续分析。例如,当协变量为连续的结果变量时,做方差分析检验潜在类别之间的差异(例见何妍等,2023)。又如,当协变量为类别变量时,使用列联表分析其与潜在类别的关系(例见赵雪艳等,2023)。 文献上也将上面的方法称为简单三步法(Vermunt, 2010; 王孟成, 毕向阳, 2018b)。前两步可通过一个Mplus程序同时完成(参见附录2.1),最后一步可使用常规的统计方法和软件(如SPSS)完成。 以差异分析为例,由于没有考虑分类误差,简单三步法分析的结果与潜在类别之间的真实差异可能有出入,特别是当熵的值比较低因而分类准确性比较低时(Asparouhov & Muthén, 2014; Clark & Muthén, 2009)。这种做法相当于将潜变量测量结果当作没有测量误差,使用回归分析代替潜变量的结构方程分析。当测验误差方差小即测验信度高时,回归分析和结构方程分析的结果会相当接近(温忠麟等, 2022)。同样,如果潜在类别的分类准确性高,将潜在类别当作显在类别进行统计分析的结果也会接近潜在类别的结果,否则,应当使用考虑了分类误差的其他后续分析方法。 (三)考虑分类误差的分步法 考虑了分类误差(即个体在归入潜在类别时带有概率水平)的三步法有多种,在文献中名称各异 (Asparouhov & Muthén, 2014; Vermunt, 2010)。王孟成和毕向阳(2018b)将Mplus中的三步法称为稳健三步法,以区别于简单三步法。在Mplus中的三步法中,如果协变量是预测变量X,由命令“AUXILIARY = X (R3STEP)”来设定(参见附录2.3),得到的是Logistic回归模型估计(例见黄声华等, 2023)。如果协变量为连续的结果变量Y,各潜在类别的Y的方差相等时,由命令“AUXILIARY = Y (DE3STEP)”来设定;各潜在类别的Y的方差不等时,由命令“AUXILIARY = Y (DU3STEP)”来设定(Asparouhov & Muthén, 2021;Muthén & Muthén, 1998−2022)。 BCH法(Bolck, Croon, and Hagenaars’s method; Bolck et al., 2004)和修正的BCH法(modied BCH; Vermunt, 2010)也是考虑了分类误差的后续分析方法(例见黄声华等,2023; 吴旻等,2023),适合协变量为结果变量的情形,都是处理连续结果变量的好方法(王孟成, 毕向阳, 2018b)。Mplus程序中的BCH法其实就是修正的BCH法(Asparouhov & Muthén, 2021; Bakk & Vermunt, 2016),由命令“AUXILIARY = Y (BCH)”来设定(见附录2.3),得到的是卡方检验的差异分析(有别于通常方差分析的F检验的差异分析)。BCH法也适合处理分类结果变量,还可用于LTA的后续分析,但在Mplus中需要手动的BCH法,先完成潜在类别的估计,再使用保存的BCH权重的训练数据作为分析数据进行二次建模过程 (Asparouhov & Muthén, 2021),这里从略。 BCH法类似于稳健三步法,区别在于稳健三步法的第三步采用极大似然估计,而BCH法在第三步采用加权方差分析,将分类误差作为权重,这样就不会改变潜在类别的顺序。因为极大似然法求局部最优解,有可能在多次分析中得到潜在类别结果顺序不一致的情况(王孟成, 毕向阳, 2018b)。此外,当不同潜在类别的结果变量的方差存在显著差异时,BCH方法相比稳健三步法更易收敛(Asparouhov & Muthén, 2021)。 LTB法(Lanza, Tan, and Bray’s method; Lanza et al, 2013)起初为两步法,后来结合稳健三步法的思想修正为三步法(Bakk et al, 2016),适合协变量为结果变量的情形,是处理类别结果变量最好的方法之一(王孟成, 毕向阳, 2018b)。在Mplus中的LTB法中(程序见附录2.3),对于类别结果变量Y,由命令“AUXILIARY = Y (DCAT)”来设定; 对于连续结果变量Y,由命令“AUXILIARY = Y (DCON)”来设定(Muthén & Muthén, 1998−2022)。 (四)后续分析方法推荐 当分类准确性高(归类概率超过0.9)时(例见何妍等, 2023, 表5),可以使用简单三步法,往往更容易理解和解释。对于考虑了分类误差的后续分析,根据现有文献推荐如下:当纳入的协变量作为预测变量时使用稳健三步法。当纳入的协变量为分类的结果变量时,使用LTB法。当纳入的协变量为连续的结果变量时,使用BCH法;当结果变量在类别内正态分布时,也可以考虑使用稳健三步法,但要区分方差相等还是不等(Asparouhov & Muthen, 2021; 王孟成, 毕向阳, 2018a, 2018b)。 六、结语 当需要建模分析潜在类别时,根据外显变量(即题目指标)的类型选择是使用LPA还是LCA。如果外显变量是类别变量使用LCA,如果外显变量是连续变量则使用LPA。如果需要同时估计多个时间点的潜在类别及潜在类别在前后时间点的转变情况可以使用LTA。 本文主要论述这些方法的原理、步骤及程序。了解LCA涉及的概率知识,对理解LCA乃至LPA的原理以及阅读结果报告中出现的各个结果有一定的帮助,所以也用了不少篇幅介绍LCA涉及的概率知识。 本文另一个重要内容是潜在类别模型的后续分析,基于LCA和LPA模型介绍了主要类型,并给出了典型的Mplus程序及其解释。然而,对于在LTA模型中如何进行后续分析,虽然有文献已经涉及(Asparouhov & Muthén, 2021; Collins & Lanza, 2010),但目前未见有系统的介绍,有待更多的研究。 (温忠麟工作邮箱:[email protected]) 上期回顾 特稿 李军:论教育改进科学:迈向改进型组织的艺术 基本理论与基本问题 高德胜|沉重的学生负担:角色的过度外溢及其后果 宋岭|教育空间中的身体规训及其改造 邓莉 詹森云|谁更可能成功?中国、美国和芬兰基于核心素养的教育改革比较 乡村振兴教育 侯怀银 原左晔|乡村振兴呼唤乡村教育学 全晓洁 蔡其勇 谢霁月|回归与回应:乡村振兴战略中我国乡村教育建设的未来走向 教育评价 姜勇 底会娟 黄瑾|幼儿园教师质量监测指标体系的构建研究——基于文化存在论教育学视角 孙蔷蔷|幼儿园教师“幼儿学习研究与支持”能力测评工具的研制 中外教育史 孙 杰 |化教育思想为教育理论——以《学记》研究为中心的历史考察 权威发布 哈巍 等|从全球到中国:社会与学校的教育协同创新 我知道你 在看哟 返回搜狐,查看更多 |









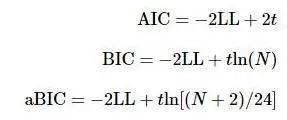
【本文地址】