| 广义线性模型(GLM):理论与Scikit | 您所在的位置:网站首页 › 变量是什么生物学上的 › 广义线性模型(GLM):理论与Scikit |
广义线性模型(GLM):理论与Scikit
|
广义线性模型(GLM)是统计学中的一种模型框架,用于建立和分析多种类型的回归模型,其中因变量不一定需要满足线性关系或正态分布的假设。GLM扩展了传统的线性回归,通过引入链接函数和允许不同的分布,从而更灵活地适用于不同类型的数据。 文章来源: https://towardsdatascience.com/scikit-learns-generalized-linear-models-4899695445fa 正如其名称所示,广义线性模型(Generalized Linear Model)是我们终极喜爱的线性回归算法(Linear Regression algorithm)的扩展。 我相信大家都非常了解线性回归器背后的理论,因此我将在下面只介绍理解GLM所需的细节。 1. 线性回归器实际上预测什么?与所有其他工程学科一样,机器学习是建立在抽象层之上的。我们使用抽象了一些细节的库。甚至我们对底层数学的理解也可以被抽象化,以便在需要时忽略大部分细节。
线性回归 - 实际方程 例如,你肯定熟记上面的方程,但我们很少注意最后一项,代表正态分布的噪声或误差的 。从概念上讲,我们知道预测的线很少会穿过任何实际目标y。这个术语存在是为了解释实际目标( )和预测目标( )之间的差异。 但是,如果我们模型的输出是y-hat,而不是y,那么为什么不花点时间在这里理解带有或不带有误差项的方程代表什么呢?
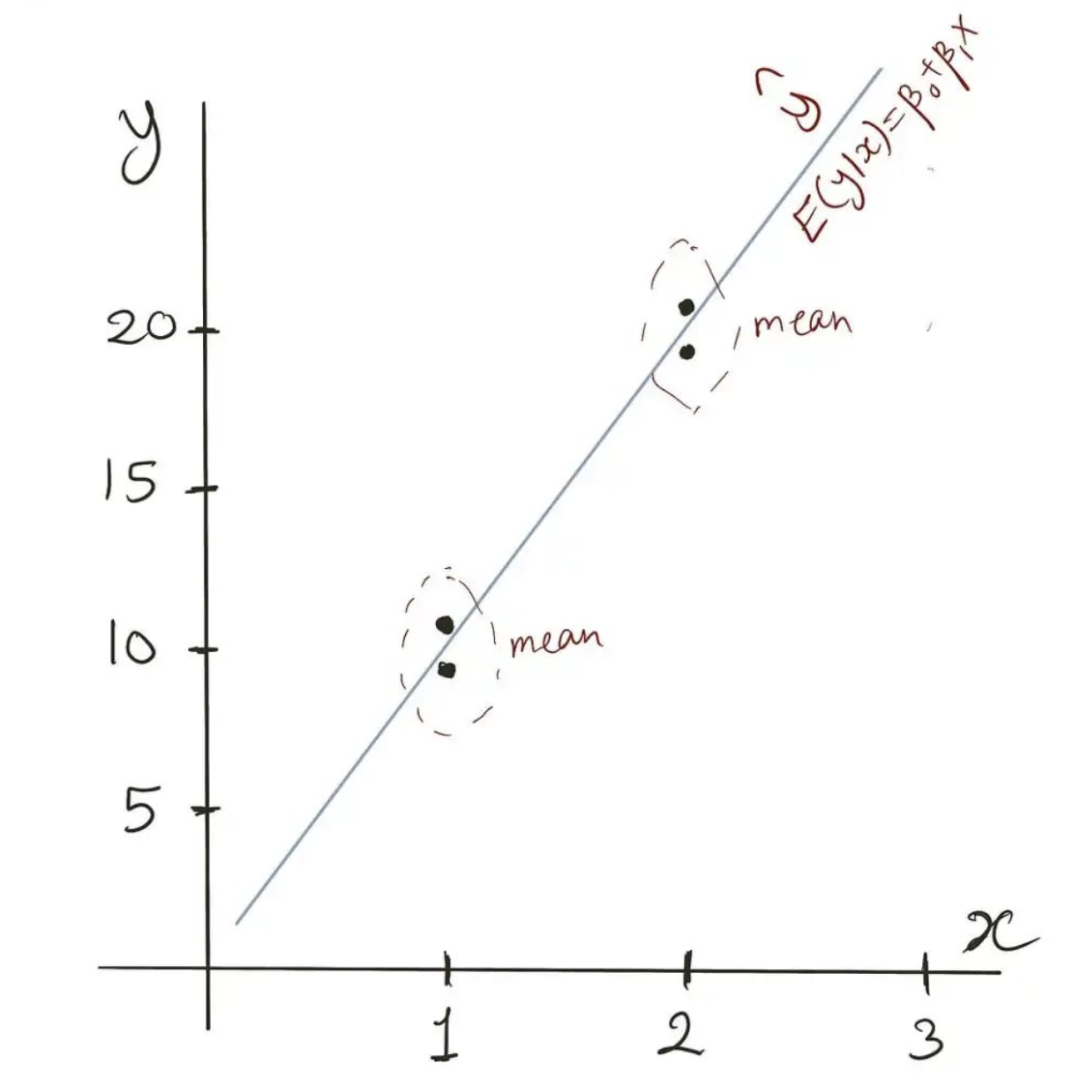
从模型得到的值是给定 的 的均值或期望值,即 。假设我们有大量数据点,那么对于每个 的值,都会有多个 的值。然后,模型将为这些 的每个值预测 的期望值。模型期望其余的 值服从正态分布。这就是为什么线性模型假设误差部分和实际目标都服从正态分布的原因。 注意:对于给定的 , 是常数。因此,当我们说误差服从均值为零的正态分布时,我们暗示实际目标 也服从正态分布,其均值为 。这一点很重要,因为在后面的情况下,我们可能不需要误差项,而需要关注 的分布。 我们可以使用Scikit-Learn来展示 在实践中是如何工作的。在这里,我们为每个 的值创建多个 的值。让我们看看模型拟合后会预测什么。 from sklearn.linear_model import LinearRegression x = [[1], [1], [2], [2]] y = [9, 11, 19, 21] m = LinearRegression() m.fit(x, y) m.predict([[1]]) # 返回 10 m.predict([[2]]) # 返回 20正如你所看到的,对于 ,预测值是 ,即 和 的均值。同样,对于 ,我们得到了 和 的均值,即 。
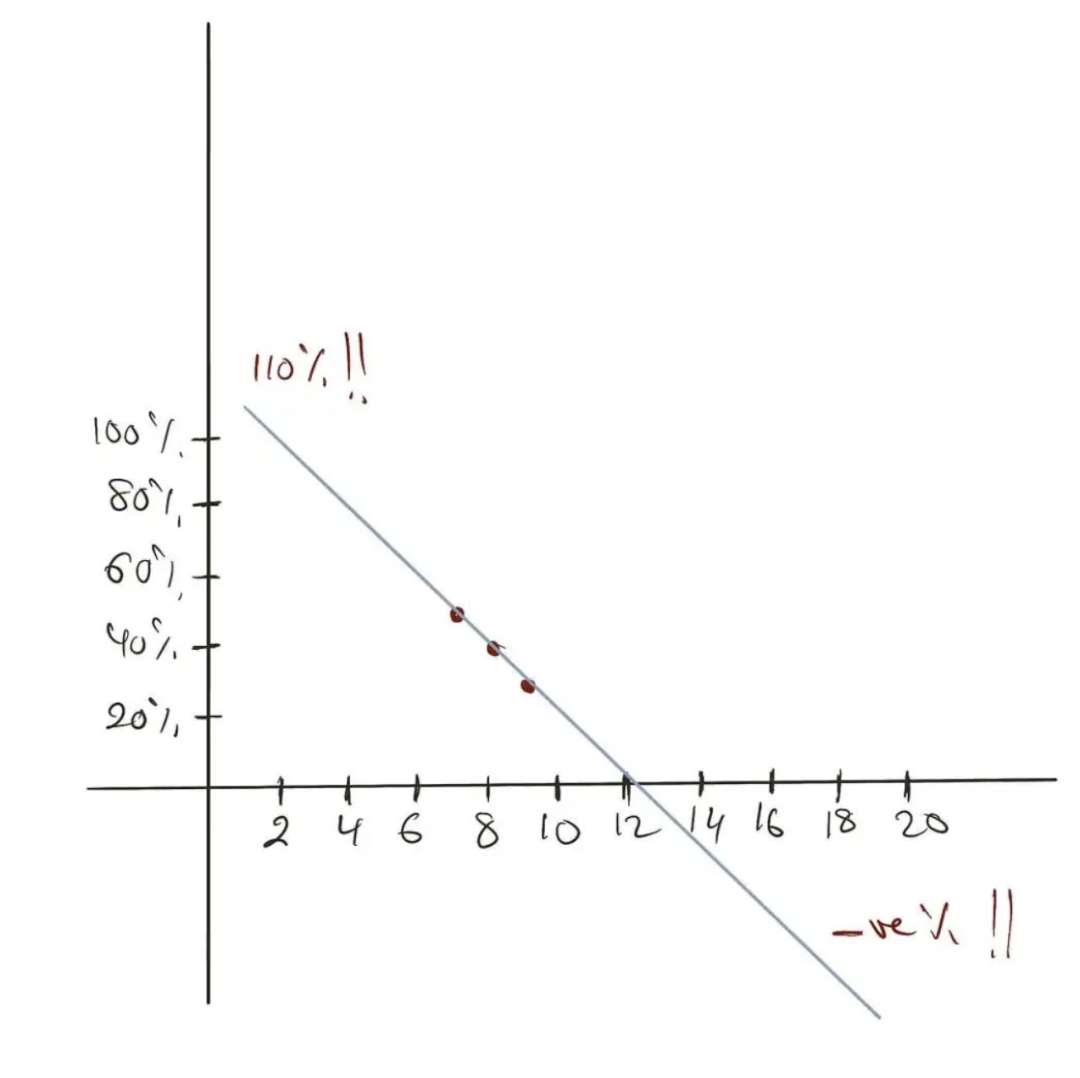
线性回归方程 — 图片由作者提供 注意:此处使用的模型通过最小化均方误差(MSE)进行拟合。当模型通过最小化绝对平均误差(MAE)进行拟合时,得到的y-hat将变为中位数,而不是均值。 到目前为止,一切都很好。但是我们为什么需要再进一步,创建这种线性模型的广义形式呢? 2. 为什么需要广义线性模型?线性模型的预测是直线,当然!或者在多维设置中使用时是超平面。这使得它们擅长外推。这是一些更复杂的算法(例如梯度提升和随机森林)不擅长的事情。 请看下面线性回归如何如预期地进行外推: from sklearn.linear_model import LinearRegression x = [[1], [2], [3]] y = [10, 20, 30] m = LinearRegression() m.fit(x, y) m.predict([[10]]) # 返回 100,如预期然而,基于树的模型无法进行外推: from sklearn.ensemble import GradientBoostingRegressor x = [[1], [2], [3]] y = [10, 20, 30] m = GradientBoostingRegressor() m.fit(x, y) m.predict([[10]]) # 返回 30!尽管如此,外推有时可能是愚蠢的。 以这个例子为例:一个商品被售出的机会取决于其在网站主页上的位置。假设,主页上有 个插槽用于列出商品。我们根据插槽位置计算了商品的销售频率。位于第 位的商品, 的情况下会被售出。位于第 位的商品, 的情况下会被售出,位于第 位的商品, 的情况下会被售出。现在我们使用这些信息来估计第1位和第 位商品的销售机会。
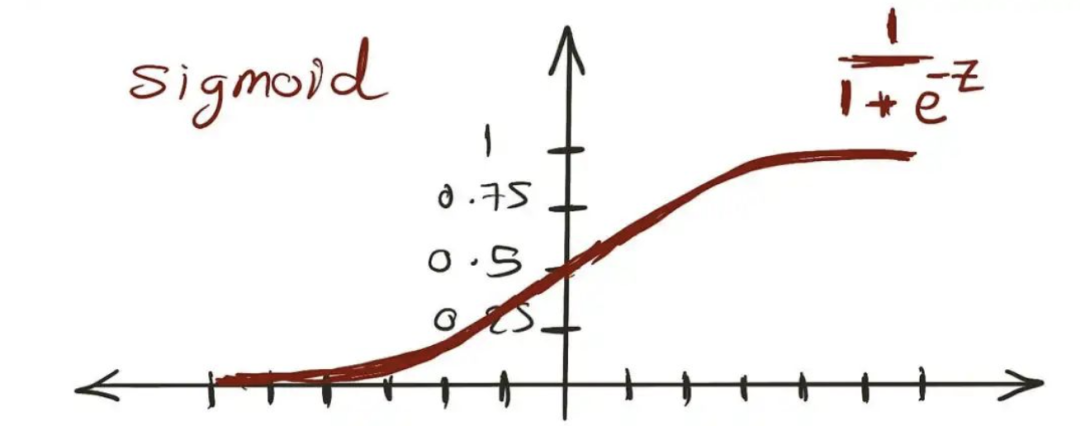
正如你所看到的,我们得到了不现实的预测结果。一个位置导致商品售出的机会为 ,而另一个位置的商品售出机会为负值。我们都知道概率应该在 和 之间。我们该怎么办呢? 所有统计学家的钉子上都有一把锤子:转换。如果你的模型不能很好地拟合数据,就用一些变换来转换模型的输入或输出,比如把数据转换成对数刻度,然后希望你的模型能起作用。 我们将在这里做一些非常类似的事情,但不是转换模型的输入或输出,而是转换其内部线性方程。 3. 相信我,你已经了解了广义线性模型(GLM)我们知道Sigmoid函数的值介于 和 之间,就像概率一样。
现在,如果我们将我们的线性方程代替z,我们可以确保其结果始终保持在0和1之间。
将Sigmoid函数代入我们的线性方程中 我很想称这个转换函数为链接函数,但统计学家的大脑通常安装颠倒了,这就是为什么广义线性模型的创造者决定称它为反链接函数,因此,Sigmoid的反函数,logit或对数几率,实际上是链接函数!
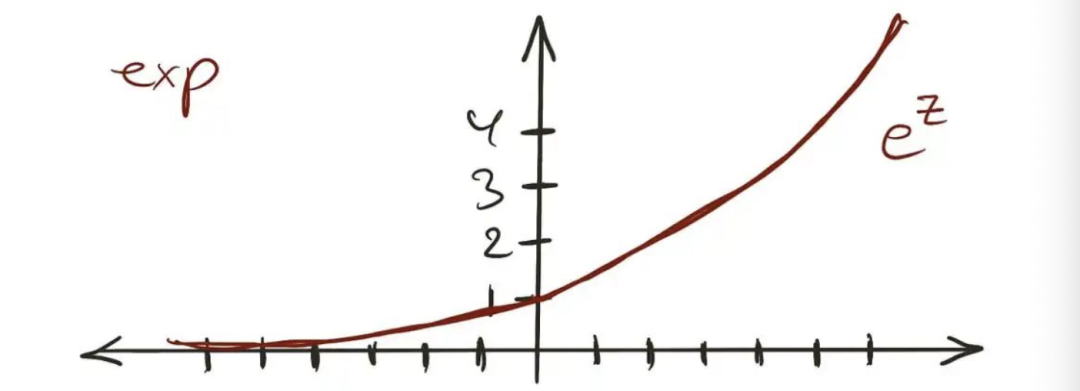
Logit作为GLM(逻辑回归)链接函数 我相信你以不同的名称了解这个模型。没错!就是我们的老朋友,逻辑回归。 除了使用链接函数外,误差项不再被期望服从正态分布。 实际上,逻辑回归并不是唯一的广义线性模型,还有许多其他模型,我们将在下一节中介绍其中的另一个。但目前为止,除了我们从线性模型中借用的线性函数之外,这些是构成广义线性模型的主要组成部分: 链接函数(link function),将 与线性方程关联起来。 目标遵循指数分布。正态分布只是这个指数族中的一个成员。 现在我们可以继续介绍另一个广义线性模型。其中一个最近引入到Scikit-Learn中的模型是泊松回归。 4. 泊松回归这个回归器非常适合预测计数。 一个平方英尺在一年内得到多少雨滴?一个链接在一天内点击多少次?一个拍卖中的商品获得多少竞标? 正如你所看到的,所有这些都是在特定范围、时间、区域等内发生的事件次数。当然,除计数之外的一些用例也可能需要泊松回归。但关键是,我们在预测非负整数。 4.1 为什么它适用于计数?当然,维基百科上的随机贡献者说泊松回归适用于计数,但要理解为什么,我们必须检查模型的工作方式。正如我们之前所见,链接函数和目标分布是理解算法的关键。
指数图——图片来源归作者所有 让我们从反链接函数开始。正如前面提到的,除了怪异的统计学家,没有人关心实际的链接函数,它的反函数才是关键。 在泊松回归模型中,反链接是一个指数函数。如上图所示,无论输入是什么,输出始终是正值。 因此,在这里是有意义的,因为我们肯定不希望出现负计数。通过将指数代入我们模型的方程中,它将变为以下形式:
指数作为GLM(泊松)链接函数 接下来是分布。首先让我们了解与线性模型假定的正态分布相关的问题。然后我们可以讨论泊松回归中使用的分布。 正态分布围绕其均值对称。这意味着,如果 为 ,则实际目标可能同样有可能是 ,也可能是 。这在这里是不可接受的,因为我们不希望出现负计数。我们需要一个偏斜的分布。 另一个问题是线性模型误差的方差在所有 上都是恒定的。这被称为同方差性。 想想看,如果某人的财富估计约为100美元,我可以容忍实际上是104美元或92美元,但是如果实际上是10万美元,我们几乎无法容忍这个错误。另一方面,如果某人的财富预计为1000万美元,我们对在数十万甚至更多的范围内有更大方差的误差更有容忍度。这就是为什么我们需要一个具有变化方差的模型,这是个双关语。 泊松分布在这里满足所有要求。它是偏斜的,其方差与均值相同,这意味着方差与 线性增长。这就是为什么在这里使用泊松分布,也就是模型的名称。 到目前为止,我一直在说话,没有向您展示任何代码。因此,让我们以一些代码结束这篇文章,这样浏览者可以复制粘贴并且结束了一天的学习。在这里,我创建了一个合成数据,其中目标 与 呈指数增长。目标具有非恒定方差,我确保没有 的值是负数。 exp = lambda x: np.exp(x)[0] x = np.array([[i] for i in np.random.choice(range(1,10), 100)]) y = np.array([exp(i) + np.random.normal(0,0.1*exp(i),1)[0] for i in x]) y[y |

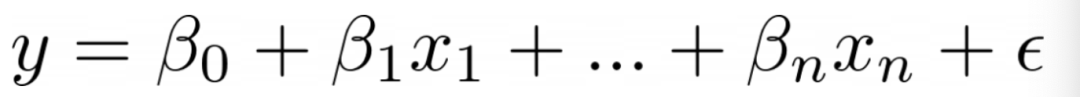
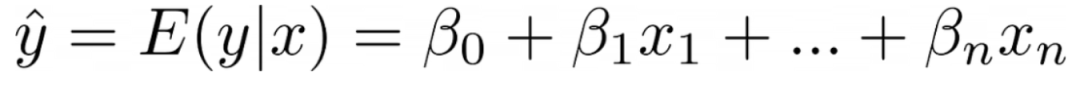
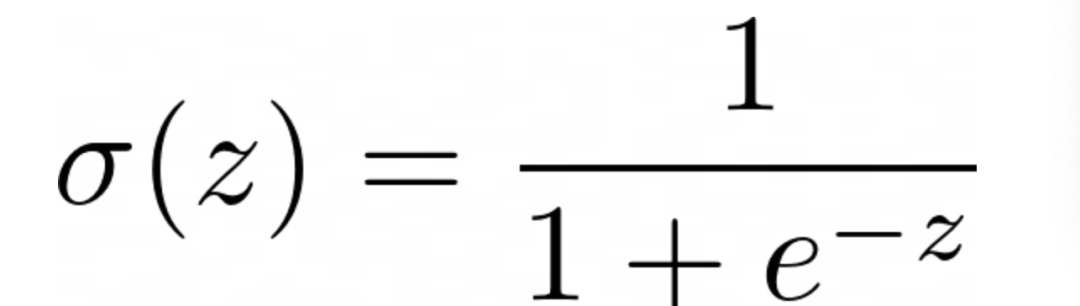
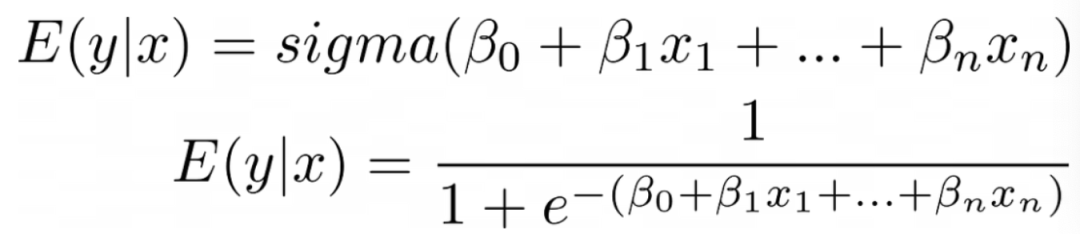
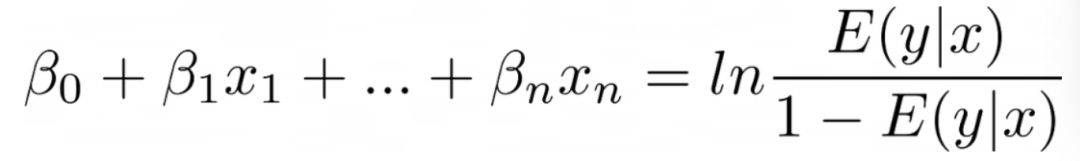
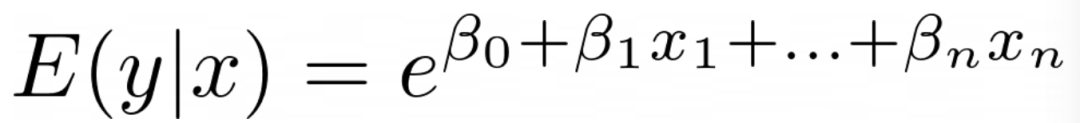
【本文地址】