| 二手房房源信息数据分析项目完整流程 | 您所在的位置:网站首页 › 发布二手房的标题怎么写 › 二手房房源信息数据分析项目完整流程 |
二手房房源信息数据分析项目完整流程
|
(一)项目背景
”学习的价值不在于记住多少,而在于应用多少”,这是几天前笔者在《数据分析——企业的贤内助》这本书中看到的一句话。笔者由此联想到了在数据分析这个领域里踽踽独行的自己。七、八月份的时候,笔者看完了《Python for Data Analysis》和另外一本《Python 数据分析实战》,当时就想着接下来做一个数据分析项目来练练手,但由于种种原因,最终没能及时付诸行动,后面又因为要学习其他方面的东西,项目始终没能做起来,这一耽搁就到了现在。前段时间,笔者把《Python for Data Analysis》这本书又看了一遍,在写完了Python实现常用图表的绘制这一系列博客之后,笔者决定趁热打铁,把前面所学的东西都真正的应用起来,做一个小项目来检验一下自己的学习成果,于是便有了这篇文章。 (二)项目简介本项目主要是对苏州市所辖工业园区、高新区、姑苏区、吴中区、吴江区和相城区这六区范围内二手房的房源信息进行分析,不考虑苏州市代管的常熟、张家港、昆山、太仓这四个县级市。整个项目分为项目目的的确定、数据的采集、数据的预处理、对数据的分析和项目总结这五个部分。在整个项目流程中主要用到了八爪鱼采集器、Excel 和Python这三样工具。 (三)项目完整流程 (1)项目目的本项目旨在解决以下三个问题: (a)苏州市所辖六区范围内,二手房房源的整体特点是什么? (b)影响苏州市所辖六区范围内的二手房价格的主要因素有哪些? (c)在苏州市所辖六区范围内,容易受到人们青睐的二手房具有什么样的特点? (2)数据的采集在采集的过程中,由于链家网默认只显示3000条数据,为了采集到所有的目标数据,笔者是在链家网开始页面上设置了筛选条件后,用八爪鱼采集器分批次对链家网上所有的目标数据进行的采集,最终一共采集到了20027条数据。 (3)数据的预处理笔者是用Excel 2010这个工具对八爪鱼采集器采集到的脏数据进行的清洗,为避免在数据清洗的过程出现对数据的误操作,笔者分批次对采集到的数据进行了清洗,最后再对数据进行汇总。清洗过程中,主要用到了Excel的分列、筛选、删除重复项、查找与替换等功能,逻辑函数if,文本函数clean、trim、len、right、left等以及数组公式。清洗结束后,还剩下17709条数据。 (4)对数据的分析这一过程中用到的工具是Python,涉及到matplotlib、pandas、seaborn等Python库,个别地方用到了scipy库。同时,流程中的所有代码都运行于jupyter notebook。 分析流程如下: # 导入整个分析过程中可能要用到的库 %matplotlib notebook import numpy as np import pandas as pd import matplotlib import matplotlib.pyplot as plt import seaborn as sns sns.set_style() # 恢复seaborn包绘图的默认主题 # 导入二手房数据 data = pd.read_excel('二手房数据.xlsx','Sheet1',encoding='UTF8') data.info() # 查看data的信息data的信息如下图所示:
new_data的信息如下图所示:
new_data的前五条数据如下图所示: 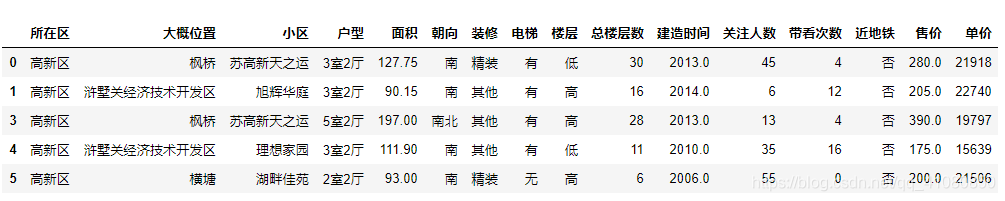 1)二手房源房源整体特点分析:
# 防止绘制的图形中出现中文乱码问题,进行如下设置
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['FangSong'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
# 构造一个自动绘制并保存饼形图的函数:
def pie_plot(data,title,x):
# pie_plot函数参数说明
# data是绘制饼图的数据,title是饼图的标题,x是保存饼图图片时图片的名字
fig,axes=plt.subplots(2,2)
data[0].plot(kind='pie',ax=axes[0,0],autopct='%.1f%%',startangle=90,label='')
data[1].plot(kind='pie',ax=axes[0,1],autopct='%.1f%%',startangle=90,label='')
data[2].plot(kind='pie',ax=axes[1,0],autopct='%.1f%%',startangle=90,label='')
data[3].plot(kind='pie',ax=axes[1,1],autopct='%.1f%%',startangle=90,label='')
# autopct参数的作用是指定饼形图中数据标签的显示方式
# '%.1f%%'表示数据标签的格式是保留一位小数的百分数
# startangle=90表示饼图的起始绘制角度是偏离x轴90度,并按逆时针绘制
# label=''后,饼形图的左边便不会再显示Series对象的名字
axes[0,0].set_aspect('equal') # 设置饼图1的纵横比相等
axes[0,0].set_title('{}'.format(title[0])) # 设置饼图1的标题
axes[0,1].set_aspect('equal') # 设置饼图2的纵横比相等
axes[0,1].set_title('{}'.format(title[1])) # 设置饼图2的标题
axes[1,0].set_aspect('equal') # 设置饼图3的纵横比相等
axes[1,0].set_title('{}'.format(title[2])) # 设置饼图3的标题
axes[1,1].set_aspect('equal') # 设置饼图4的纵横比相等
axes[1,1].set_title('{}'.format(title[3])) # 设置饼图4的标题
plt.subplots_adjust(wspace=0.2,hspace=0.2) # 设置figure对象中子图的间距
plt.rc('figure', figsize=(8, 6)) # 设置图片的大小
plt.savefig('{}.png'.format(x)) # 保存图片
1)二手房源房源整体特点分析:
# 防止绘制的图形中出现中文乱码问题,进行如下设置
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['FangSong'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
# 构造一个自动绘制并保存饼形图的函数:
def pie_plot(data,title,x):
# pie_plot函数参数说明
# data是绘制饼图的数据,title是饼图的标题,x是保存饼图图片时图片的名字
fig,axes=plt.subplots(2,2)
data[0].plot(kind='pie',ax=axes[0,0],autopct='%.1f%%',startangle=90,label='')
data[1].plot(kind='pie',ax=axes[0,1],autopct='%.1f%%',startangle=90,label='')
data[2].plot(kind='pie',ax=axes[1,0],autopct='%.1f%%',startangle=90,label='')
data[3].plot(kind='pie',ax=axes[1,1],autopct='%.1f%%',startangle=90,label='')
# autopct参数的作用是指定饼形图中数据标签的显示方式
# '%.1f%%'表示数据标签的格式是保留一位小数的百分数
# startangle=90表示饼图的起始绘制角度是偏离x轴90度,并按逆时针绘制
# label=''后,饼形图的左边便不会再显示Series对象的名字
axes[0,0].set_aspect('equal') # 设置饼图1的纵横比相等
axes[0,0].set_title('{}'.format(title[0])) # 设置饼图1的标题
axes[0,1].set_aspect('equal') # 设置饼图2的纵横比相等
axes[0,1].set_title('{}'.format(title[1])) # 设置饼图2的标题
axes[1,0].set_aspect('equal') # 设置饼图3的纵横比相等
axes[1,0].set_title('{}'.format(title[2])) # 设置饼图3的标题
axes[1,1].set_aspect('equal') # 设置饼图4的纵横比相等
axes[1,1].set_title('{}'.format(title[3])) # 设置饼图4的标题
plt.subplots_adjust(wspace=0.2,hspace=0.2) # 设置figure对象中子图的间距
plt.rc('figure', figsize=(8, 6)) # 设置图片的大小
plt.savefig('{}.png'.format(x)) # 保存图片
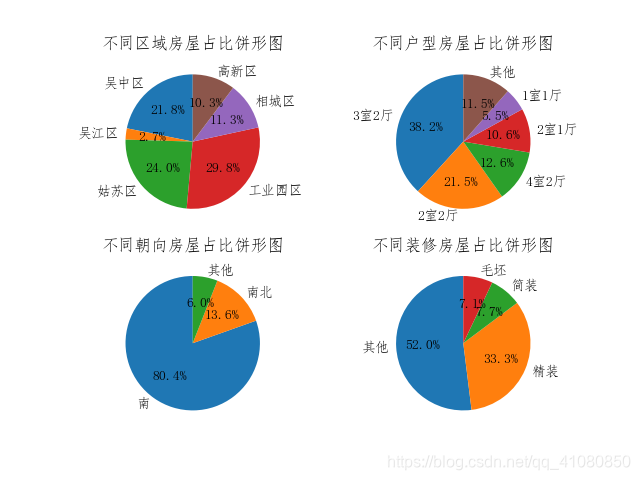
分别统计二手房 的所在区域、户型、朝向、装修情况: # 处理不同区域的房屋数据: count_by_region = new_data['所在区'].groupby(new_data['所在区']).count() # 对不同区域中的房屋进行分组统计: # 处理房屋的户型数据: count_by_house_type = new_data['户型'].groupby(new_data['户型']).count()# 对不同户型的房屋进行分组统计: count_by_house_type.sort_values(ascending=False,inplace=True) # 将不同户型房屋的计数结果按降序排序 # 将总数在800以下的户型统一归为其他类: new_count_by_house_type = count_by_house_type[count_by_house_type > 800] new_count_by_house_type['其他'] = count_by_house_type[count_by_house_type < 800].sum() # 处理房屋的朝向数据: count_by_orientation = data['朝向'].groupby(data['朝向']).count() # 对不同朝向的房屋进行分组统计: count_by_orientation.sort_values(ascending=False,inplace=True) # 将不同朝向房屋的计数结果按降序排序 # 将总数在500以下的朝向统一归类为其他: new_count_by_orientation = count_by_orientation[count_by_orientation > 500] new_count_by_orientation['其他'] = count_by_orientation[count_by_orientation < 500].sum() # 处理房屋装修情况的数据: count_by_decoration = new_data['装修'].groupby(new_data['装修']).count() # 对不同装修的房屋进行分组统计: count_by_decoration.sort_values(ascending=False,inplace=True) # 将不同装修房屋的计数结果按降序排序 # 调用pie_plot函数绘制不同区域、不同户型、不同朝向和不同装修的饼形图: d1 = [count_by_region,new_count_by_house_type,new_count_by_orientation,count_by_decoration] t1 = ['不同区域房屋占比饼形图','不同户型房屋占比饼形图','不同朝向房屋占比饼形图','不同装修房屋占比饼形图'] x1 = 'p1' pie_plot(d1,t1,x1)结果如下图所示:
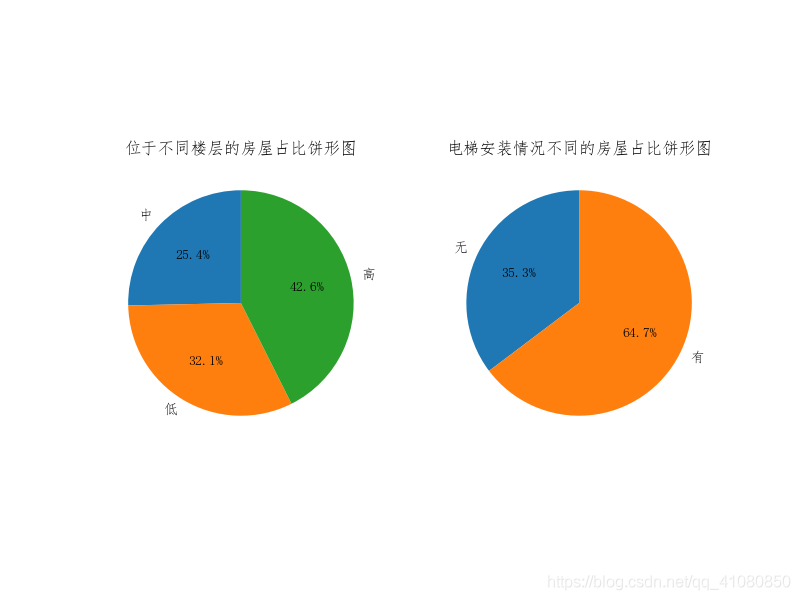
从此图中我们可以看到: (1)在苏州市所辖的六个区中,工业园区的房源数量最多接近30%,其次便是占比24%的姑苏区和占比接近22%的吴中区,而吴江区的房源数量最少,仅占不到3%。 (2)在所有的户型中,三室两厅的户型占比最多达到38%,其次是两室两厅达到了21%。 (3)所有房源里,房屋朝向为南北朝向的房子占据了90%以上,由此可见相比其他朝向,人们更加喜欢南北朝向的房子。 (4)在所有清晰表明了装修情况的二手房中,超过一半的二手房是精装修的,毛坯房与简装房的占比则相差不多,都在7%左右。 分别统计二手房的楼层位置和电梯安装情况: # 处理房屋的楼层位置数据: count_by_floor_position = new_data['楼层'].groupby(new_data['楼层']).count() # 对位于不同楼层的房屋数量进行分组统计 # 处理房屋电梯安装情况的数据: count_by_elevator = new_data['电梯'].groupby(new_data['电梯']).count() # 对电梯安装情况不同的房屋进行分组统计 # 绘制处于不同楼层位置和电梯安装情况不同的房屋占比饼形图: fig,axes = plt.subplots(1,2) count_by_floor_position.plot(kind='pie',ax=axes[0],autopct='%.1f%%',startangle=90,label='') count_by_elevator.plot(kind='pie',ax=axes[1],autopct='%.1f%%',startangle=90,label='') # autopct参数的作用是指定饼形图中数据标签的显示方式 # '%.1f%%'表示数据标签的格式是保留一位小数的百分数 # startangle=90表示饼图的起始绘制角度是偏离x轴90度,并按逆时针绘制 # label=''后,饼形图的左边便不会再显示Series对象的名字 axes[0].set_aspect('equal') # 设置饼形图的纵横比相等 axes[0].set_title('位于不同楼层的房屋占比饼形图') # 设置饼形图的标题 axes[1].set_aspect('equal') axes[1].set_title('电梯安装情况不同的房屋占比饼形图') plt.savefig('p2.png') # 保存图片结果如下图所示:
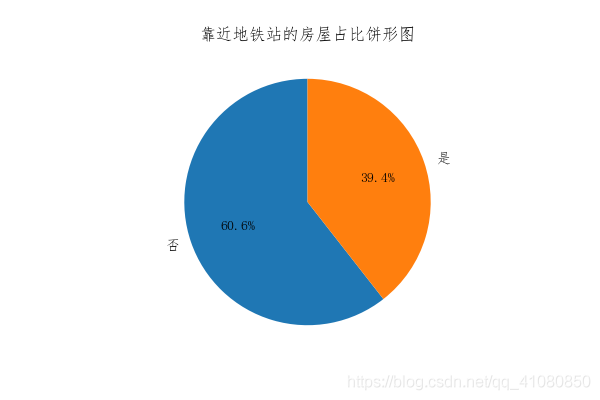
从此图我们可以看到: (1)位于高楼层的二手房数量最多达到了43%,其次是中楼层有32%,位于低楼层二手房数量最少为25%,但三者差别不是特别大. (2)在所有的二手房中,安装了电梯的二手房数量接近没安装电梯的二手房数量的两倍。 统计靠近地铁站的二手房占比情况: # 处理房屋是否近地铁的数据: count_by_subway = new_data['近地铁'].groupby(new_data['近地铁']).count() # 对房屋是否靠近地铁站进行分组统计 # 绘制靠近地铁站的房屋占比饼形图: fig,axes = plt.subplots(figsize=(6,4)) # figsize参数指定生成图片的大小 count_by_subway.plot(kind='pie',ax=axes,autopct='%.1f%%',startangle=90,label='') # autopct参数的作用是指定饼形图中数据标签的显示方式 # '%.1f%%'表示数据标签的格式是保留一位小数的百分数 # startangle=90表示饼图的起始绘制角度是偏离x轴90度,并按逆时针绘制 # label=''后,饼形图的左边便不会再显示Series对象的名字 axes.set_aspect('equal') # 设置饼形图的纵横比相等 axes.set_title('靠近地铁站的房屋占比饼形图') # 设置饼形图的标题 plt.savefig('p3.png') # 保存图片结果如下图所示:
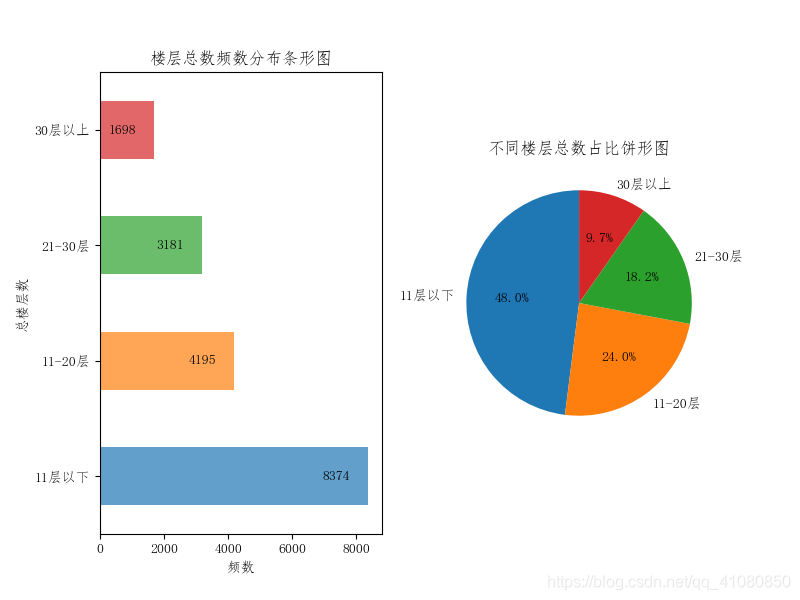
统计二手房所在楼总楼层数的分布情况: # 处理房源所在楼总楼层位置数据: count_by_floor_number = new_data['总楼层数'].groupby(new_data['总楼层数']).count() # 根据不同总楼层数进行分组计数 count_by_floor_number.sort_index(inplace=True) # 按照索引值的大小将分组计数的结果升序排序 # 根据count_by_floor_number的索引值将数据分成11层以下、11-20层、20-30层和30层以上四组,并分组计数 count_by_floor_number1 = count_by_floor_number.loc[1:10].sum() count_by_floor_number2 = count_by_floor_number.loc[10:20].sum() count_by_floor_number3 = count_by_floor_number.loc[20:30].sum() count_by_floor_number4 = count_by_floor_number.loc[30:].sum() new_count_by_floor_number = pd.Series([count_by_floor_number1,count_by_floor_number2, count_by_floor_number3,count_by_floor_number4], index=['11层以下','11-20层','21-30层','30层以上']) # 绘制房源所在楼不同楼层总数占比饼形图和不同楼层总数频数分布条形图: # 绘制条形图 fig,axes = plt.subplots(1,2) new_count_by_floor_number.plot.barh(ax=axes[0],alpha=0.7) # alpha参数指定图像的透明度 axes[0].set(xlabel='频数',ylabel='总楼层数',title='楼层总数频数分布条形图') # 设置条形图的标题和坐标轴标签 # 给条形图添加数值标签 x = np.arange(len(new_count_by_floor_number)) y = new_count_by_floor_number.values for a,b in zip(x,y): axes[0].text(x=b-1000,y=a,s=b,ha='center', va= 'center') # ha参数和va参数分别指定数值标签水平对齐与垂直对齐的方式 # 绘制饼形图 new_count_by_floor_number.plot(kind='pie',ax=axes[1],autopct='%.1f%%',startangle=90,label='') # autopct参数的作用是指定饼形图中数据标签的显示方式 # '%.1f%%'表示数据标签的格式是保留一位小数的百分数 # startangle=90表示饼图的起始绘制角度是偏离x轴90度,并按逆时针绘制 # label=''后,饼形图的左边便不会再显示Series对象的名字 axes[1].set_title('不同楼层总数占比饼形图') # 设置饼图的标题 axes[1].set_aspect('equal') # 设置饼形图的纵横比相等 plt.savefig('p4.png') # 保存图片结果如下图所示:
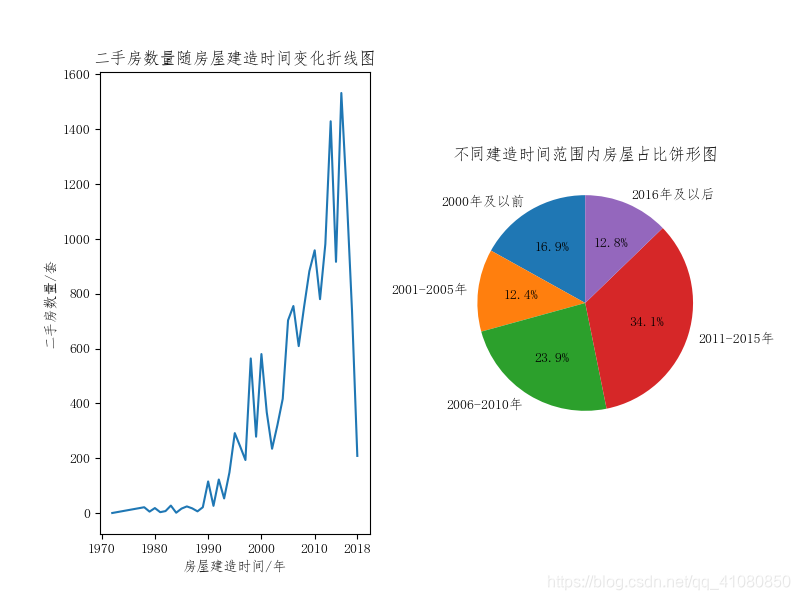
从此图我们可以看到,在所有的二手房中,有接近50%的房子所在楼的总楼层数是11层以下,其次是11层-20层之间,占比24%,而所在楼的楼层总数超过20层的二手房占比大约28%。 绘制二手房的数量随其建造时间变化的折线图,并统计二手房建造时间的分布: new_data['建造时间'].unique() # 查看房屋建造时间中的非重复值 # 输出结果: # array([2013., 2014., 2010., 2006., 2018., 2017., 2002., 2015., 2004., # 2011., 2005., 2016., 2001., 2007., 2012., 1995., 1998., 2008., # 2003., 2009., 2000., 1993., 1999., 1996., 1997., 1994., 1992., # 1988., 1990., 1991., 1989., 1980., 1986., 1982., 1985., 1983., # 1978., 1984., 1979., 1981., 1987., 1972.]) # 处理房屋的建造时间数据: count_by_create_time = new_data['建造时间'].groupby(new_data['建造时间']).count() # 对不同时间建造的房屋进行分组统计 # 将房屋建造时间分成2000年及以前、2001-2005年、2006-2010年、2011-2015年、2016年及以后这五组数据,并分组计数 count_by_create_time1 = count_by_create_time.loc[:2000].sum() count_by_create_time2 = count_by_create_time.loc[2001:2005].sum() count_by_create_time3 = count_by_create_time.loc[2006:2010].sum() count_by_create_time4 = count_by_create_time.loc[2011:2015].sum() count_by_create_time5 = count_by_create_time.loc[2016:].sum() new_count_by_create_time = pd.Series([count_by_create_time1,count_by_create_time2,count_by_create_time3, count_by_create_time4,count_by_create_time5], index=['2000年及以前','2001-2005年','2006-2010年','2011-2015年','2016年及以后']) # 绘制房屋的数量随着建造时间变化而变化的折线图和不同建造时间范围内房屋占比饼形图: # 绘制折线图 fig,axes = plt.subplots(1,2) count_by_create_time.plot(kind='line',ax=axes[0]) axes[0].set(xlabel='房屋建造时间/年',ylabel='二手房数量/套', title='二手房数量随房屋建造时间变化折线图', xticks=[1970,1980,1990,2000,2010,2018]) # 设置折线图标题、坐标轴标签和x轴上的数值标签 # 绘制饼形图 new_count_by_create_time.plot(kind='pie',ax=axes[1],autopct='%.1f%%',startangle=90,label='') # autopct参数的作用是指定饼形图中数据标签的显示方式 # '%.1f%%'表示数据标签的格式是保留一位小数的百分数 # startangle=90表示饼图的起始绘制角度是偏离x轴90度,并按逆时针绘制 # label=''后,饼形图的左边便不会再显示Series对象的名字 axes[1].set_title('不同建造时间范围内房屋占比饼形图') # 设置饼形图的标题 axes[1].set_aspect('equal') # 设置饼形图的纵横比相等 plt.subplots_adjust(wspace=0.3) # 设置figure对象中子图的间距 plt.savefig('p5.png') # 保存图片结果如下图所示:
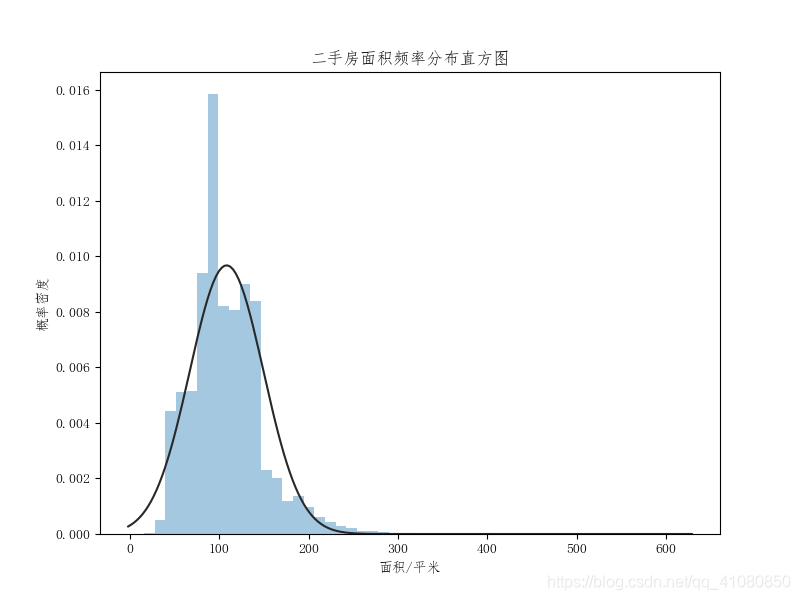
由此图我们可以看到: (1)总体趋势上,随着建造时间距离现在越来越近,二手房的数量逐年增加。 (2)在所有的二手房中,建造时间在2011-2015年这个范围内的二手房占比最大,达到了34%,其次便是2006-2010年。70%左右的二手房的建造时间距今不超过12年。 查看二手房面积的分布特点: new_data['面积'].describe() # 查看房屋面积的统计信息 # 输出结果为: # count 16548.000000 # mean 108.057752 # std 41.223922 # min 15.600000 # 25% 83.600000 # 50% 100.440000 # 75% 130.115000 # max 611.000000 # Name: 面积, dtype: float64 # 绘制整体房源面积的频率分布直方图: from scipy.stats import norm fig,axes = plt.subplots() sns.distplot(new_data['面积'],bins=50,kde=False,fit=norm,ax=axes) # fit=norm意味着用正态分布密度函数拟合频率分布直方图 axes.set(xlabel='面积/平米',ylabel='概率密度',title='二手房面积频率分布直方图') # 设置直方图的x轴标签、y轴标签以及直方图的标题 plt.savefig('p6.png') # 指定图片的分辨率并保存图片结果如下图所示:
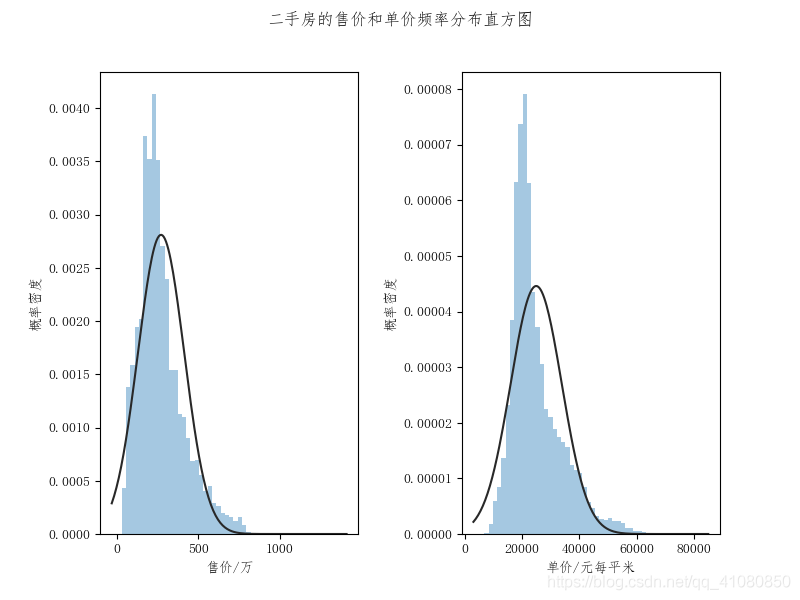
从此图上我们可以看到,二手房的面积分布大致符合正态分布。根据经验法则,对于具有钟形分布的数据,大约有%68的数据值与平均数的距离在一个标准差以内, 据此可计算这%68数据值的范围: min_area = new_data['面积'].mean() - new_data['面积'].std() max_area = new_data['面积'].mean() + new_data['面积'].std() print(min_area,max_area) # 输出结果为: # 66.83382998449979 149.2816740038976由此可以大概推断,苏州市所辖六区范围内,70%上的二手房房屋面积在50-150平米之间,30%以下的二手房房屋面积小于50平米或者大于150平米。 查看二手房价格的分布特点: new_data['售价'].describe() # 查看二手房售价的统计信息 # 输出结果为: # count 16548.000000 # mean 271.881526 # std 141.929135 # min 30.000000 # 25% 178.000000 # 50% 245.000000 # 75% 337.000000 # max 1350.000000 # Name: 售价, dtype: float64 new_data['单价'].describe() # 查看二手房单价的统计信息 # 输出结果为: # count 16548.000000 # mean 24870.346447 # std 8945.916620 # min 6742.000000 # 25% 18939.750000 # 50% 22265.000000 # 75% 28961.500000 # max 81250.000000 # Name: 单价, dtype: float64 # 绘制整体房源的售价分布直方图和单价分布直方图: fig,axes = plt.subplots(1,2) sns.distplot(new_data['售价'],bins=50,kde=False,fit=norm,ax=axes[0]) sns.distplot(new_data['单价'],bins=50,kde=False,fit=norm,ax=axes[1]) # 设置直方图的x轴标签、y轴标签以及直方图的标题 axes[0].set(xlabel='售价/万',ylabel='概率密度') axes[1].set(xlabel='单价/元每平米',ylabel='概率密度') fig.suptitle('二手房的售价和单价频率分布直方图') plt.subplots_adjust(wspace=0.4) # 设置figure对象中两子图的间距 plt.savefig('p7.png') # 保存图片结果如下图所示:
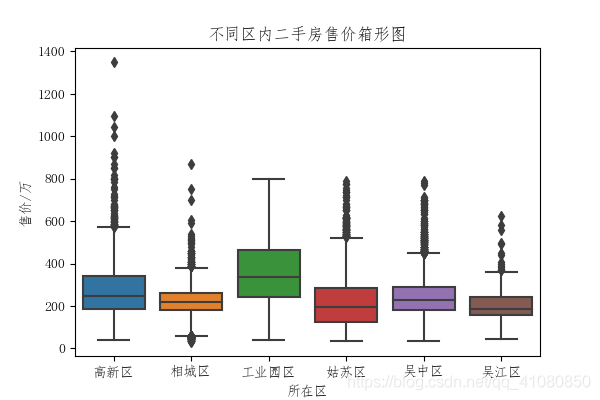
同样,从此图上我们可以看到,二手房的售价分布和单价分布大致符合正态分布。根据经验法则,对于具有钟形分布的数据,大约有%68的数据值与平均数的距离在一个标准差以内, 据此可计算这%68数据值的范围: min_price = new_data['售价'].mean() - new_data['售价'].std() max_price = new_data['售价'].mean() + new_data['售价'].std() print(min_price,max_price) # 输出结果为: # 129.95239171070799 413.8106612262028 min_average_price = new_data['单价'].mean() - new_data['单价'].std() max_average_price = new_data['单价'].mean() + new_data['单价'].std() print(min_average_price,max_average_price) # 输出结果为: # 15924.429826650296 33816.26306675072由此可以推断,苏州市所辖六区范围内70%以上的二手房的售价在100-450万之间,30%以下的二手房售价在小于100万或者大于450万,65%以上的二手房的单价在15000-35000每平米之间,35%以下的二手房的单价小于15000每平米或者大于35000每平米。 2)探究影响二手房价格的主要因素有哪些?查看房源所处地区对其价格的影响: 首先比较不同区域内二手房的售价: fig,axes = plt.subplots(figsize=(6,4)) sns.boxplot(x='所在区',y='售价',data=new_data,orient='v',ax=axes) axes.set(ylabel='售价/万',title='不同区内二手房售价箱形图') plt.savefig('p8.png') # 保存图片结果如下图所示:
由此图我们可以看到,六区中,工业园区的二手房售价明显比其他五个区的高,除此之外,除了工业园区,其他五区中二手房的售价都出现了高出正常值范围的异常值,相城区还出现了售价过低的二手房。 再比较不同区域内二手房的单价: fig,axes = plt.subplots(figsize=(6,4)) sns.boxplot(x='所在区',y='单价',data=new_data,orient='v',ax=axes) axes.set(ylabel='单价/元没平米',title='不同区内二手房单价箱形图') plt.savefig('p9.png') # 保存图片结果如下图所示:
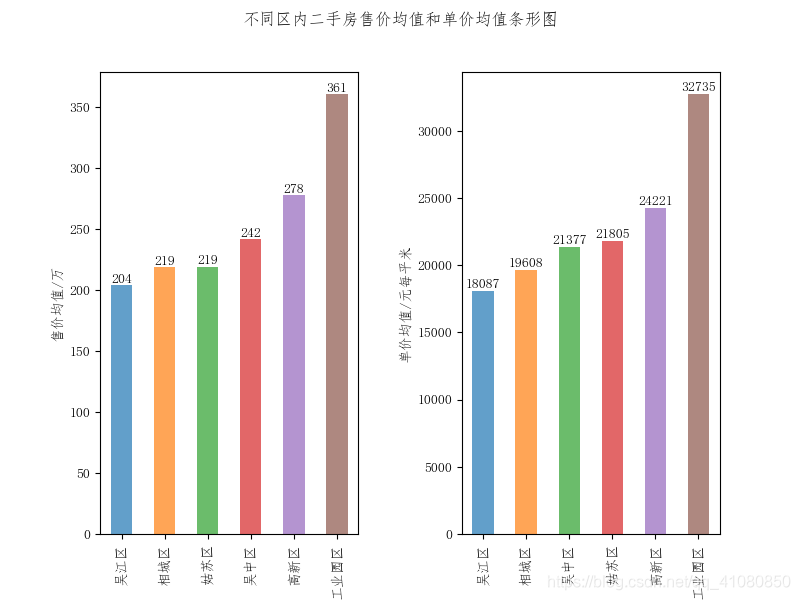
从此图中我们可以看到工业园区内的二手房单价明显比其他五个区的高,吴江区整体上的二手房单价在六个区中是最低的。在所有的六个区中,都出现了单价过高或者过低的二手房。 下面用另一幅更具体的图来描述各区之间二手房价格的差异: # 计算处于不同区的二手房售价的均值: average_price_grouped_by_region = new_data['售价'].groupby(new_data['所在区']).mean() # 计算处于不同区的二手房售价的均值 average_price_grouped_by_region.sort_values(ascending=True,inplace=True) # 将计算结果按照升序排序 # 计算处于不同区的二手房单价的均值: average_unit_price_grouped_by_region = new_data['单价'].groupby(new_data['所在区']).mean() # 计算处于不同区的二手房售价的均值 average_unit_price_grouped_by_region.sort_values(ascending=True,inplace=True) # 将计算结果按照升序排序 # 绘制不同区的二手房售价均值和单价均值条形图: fig,axes = plt.subplots(1,2) # 绘制售价均值条形图1 average_price_grouped_by_region.plot.bar(ax=axes[0],alpha=0.7) axes[0].set(ylabel='售价均值/万') # 给条形图1添加数值标签 x1 = np.arange(len(average_price_grouped_by_region)) y1 = average_price_grouped_by_region.values for a,b in zip(x1,y1): axes[0].text(x=a,y=b+5,s='%.f'%b,ha='center', va= 'center') # ha参数和va参数分别指定数值标签水平对齐与垂直对齐的方式 # 绘制单价均值条形图2 average_unit_price_grouped_by_region.plot.bar(ax=axes[1],alpha=0.7) axes[1].set(ylabel='单价均值/元每平米') # 给条形图2添加数值标签 x2 = np.arange(len(average_unit_price_grouped_by_region)) y2 = average_unit_price_grouped_by_region.values for c,d in zip(x2,y2): axes[1].text(x=c,y=d+500,s='%.f'%d,ha='center', va= 'center') fig.suptitle('不同区内二手房售价均值和单价均值条形图') plt.subplots_adjust(wspace=0.4) # 设置figure对象中两子图的间距 plt.savefig('p10.png',dpi=300) # 指定生成图片的分辨率并保存图片结果如下图所示:
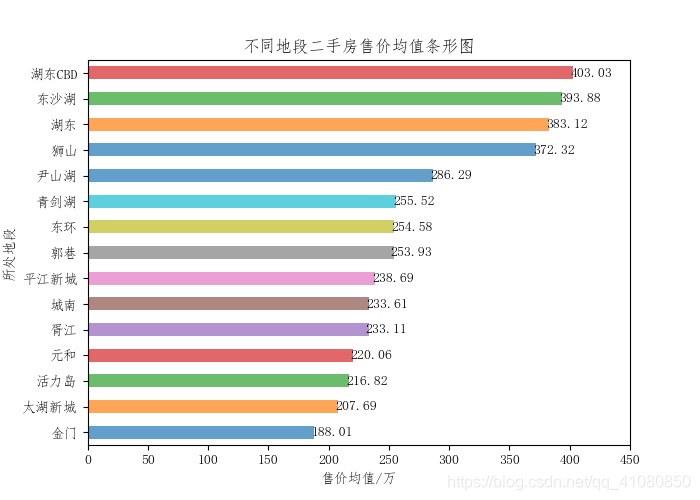
从上图我们可以看到工业园区的二手房,其售价比其他区的二手房都要高100万左右,而单价则比其他区的二手房要高10000元左右。 接下来,找出六区范围内房价最高的前十个具体地段与工业园区范围内房价最高的前十个具体地段,然后对两者进行比较: # 找出六个区范围内二手房单价均值最高的前十个地段 ten_highest_unit_price_all = new_data['单价'].groupby(new_data['大概位置']).mean().sort_values(ascending=False).iloc[:10] # 找出工业园区范围内二手房单价最高的前是个地段 changed_data = new_data.set_index(['所在区']) # 将new_data中的所在区这一列指定为新数据的索引 data_of_gongyeyuanqu = changed_data.loc['工业园区'] # 筛选出工业园区的数据 # 筛选出房价最高的前是个地段 ten_highest_unit_price_gongyeyuanqu = data_of_gongyeyuanqu['单价'].groupby(data_of_gongyeyuanqu['大概位置']).mean().sort_values(ascending=False).iloc[:10] print(list(ten_highest_unit_price_all.index)) print(list(ten_highest_unit_price_gongyeyuanqu.index)) # 输出结果为: # ['玲珑', '白塘', '湖西CBD', '双湖', '东沙湖', '湖东', '湖东CBD', '独墅湖高教区', '平江路', '十全街'] # ['玲珑', '白塘', '湖西CBD', '双湖', '东沙湖', '湖东', '湖东CBD', '独墅湖高教区', '斜塘', '青剑湖']从输出结果我们可以发现,在所有区范围内找出的二手房单价均值最高的前十个地段,其中前八个地段是位于工业园区的。 查看具体地段对价格的影响: 先看具体地段对售价的影响: count_by_location = new_data['大概位置'].groupby(new_data['大概位置']).count() # 按照房源所处地段进行分组计数 count_by_location.sort_values(ascending=True,inplace=True) # 把计数结果按照升序排序 new_count_by_location = count_by_location[count_by_location > 400] # 选出房源数量在400套以上的大概位置数据 # 计算不同地段二手房售价的均值 locations1 = list(new_count_by_location.index) # locations1代表的是房源数量在400套以上的地段 average_price_grouped_by_location = new_data['售价'].groupby(new_data['大概位置']).mean() # 计算不同位置的二手房售价的平均值 new_average_price_grouped_by_location = average_price_grouped_by_location[locations1] # 筛选出数量在400套以上的房屋售价的均值 new_average_price_grouped_by_location.sort_values(ascending=True,inplace=True) # 将筛选出来的数据按照升序排序 # 绘制不同地段二手房售价均值的条形分布图: fig,axes = plt.subplots(figsize=(7,5) new_average_price_grouped_by_location.plot.barh(ax=axes,alpha=0.7) axes.set(xlabel='售价均值/万',ylabel='所处地段',title='不同地段二手房售价均值条形图', xticks=[0,50,100,150,200,250,300,350,400,450]) # 给条形图添加数值标签 x = np.arange(len(new_average_price_grouped_by_location)) y = new_average_price_grouped_by_location.values for a,b in zip(x,y): axes.text(x=b+15,y=a,s='%.2f'%b,ha='center', va= 'center') # ha参数和va参数分别指定数值标签水平对齐与垂直对齐的方式 plt.savefig('p11.png') # 保存图片结果如下图所示:
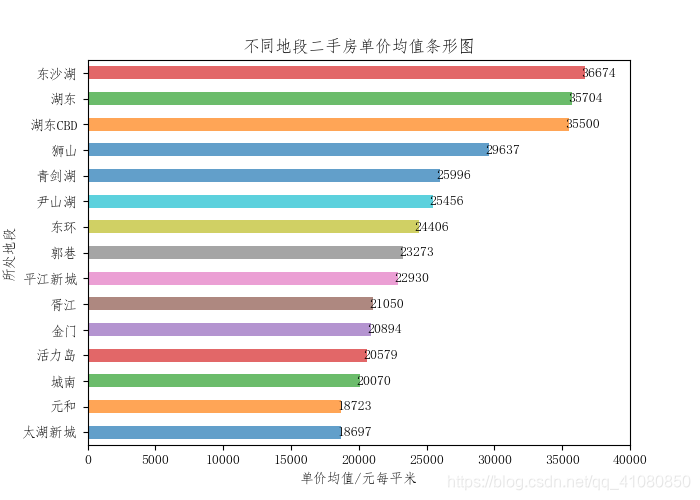
再看具体地段对单价的影响: # 计算不同地段二手房单价的均值: average_unit_price_grouped_by_location = new_data['单价'].groupby(new_data['大概位置']).mean() # 计算不同位置的二手房单价的平均值 new_average_unit_price_grouped_by_location = average_unit_price_grouped_by_location[locations1] # 筛选出数量在400套以上的房屋单价的均值 new_average_unit_price_grouped_by_location.sort_values(ascending=True,inplace=True) # 将筛选出来的数据按照升序排序 # 绘制不同地段二手房单价均值的条形图: fig,axes = plt.subplots(figsize=(7,5)) new_average_unit_price_grouped_by_location.plot.barh(ax=axes,alpha=0.7) axes.set(xlabel='单价均值/元每平米',ylabel='所处地段',title='不同地段二手房单价均值条形图', xticks=[0,5000,10000,15000,20000,25000,30000,35000,40000]) # 设置条形图的标题、坐标轴标签和x轴上的数值标记 # 给条形图添加数值标签 x = np.arange(len(new_average_unit_price_grouped_by_location)) y = new_average_unit_price_grouped_by_location.values for a,b in zip(x,y): axes.text(x=b+1000,y=a,s='%.f'%b,ha='center', va= 'center') # ha参数和va参数分别指定数值标签水平对齐与垂直对齐的方式 plt.savefig('p12.png') # 保存图片结果如下图所示:
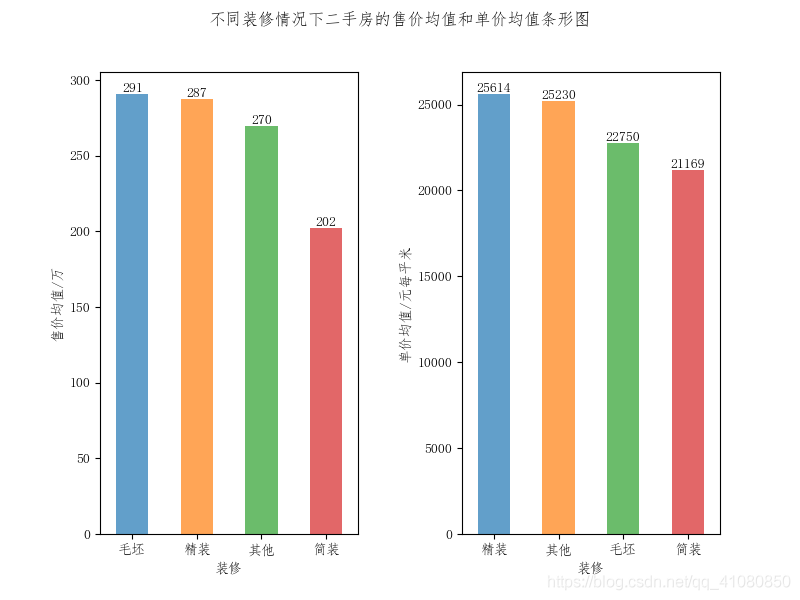
从上面两幅图中可以看到,在房源数量较多的十个地段中,湖东、湖东CBD和东沙湖这三个地段上二手房的售价和单价,明显比其他七个地段上的要高。 查看房屋朝向对价格的影响: new_count_by_orientation # 输出结果为: # 朝向 # 南 13379 # 南北 2259 # 其他 994 # Name: 朝向, dtype: int64由上文中不同朝向房屋占比饼形图可知,朝向为南北的房屋占据了所分析数据集的90%以上, 而其他朝向的房屋数量太少。因此,此处不做房屋朝向对房屋价格影响分析。 查看房屋的装修情况对价格的影响: average_price_grouped_by_decoration = new_data['售价'].groupby(new_data['装修']).mean() # 计算不同装修二手房的售价均值 average_price_grouped_by_decoration.sort_values(ascending=False,inplace=True) average_unit_price_grouped_by_decoration = new_data['单价'].groupby(new_data['装修']).mean() # 计算不同装修二手房的单价均值 average_unit_price_grouped_by_decoration.sort_values(ascending=False,inplace=True) # 绘制不同装修情况房屋售价均值与单价均值的条形图: fig,axes = plt.subplots(1,2) # 绘制售价均值条形图 average_price_grouped_by_decoration.plot.bar(ax=axes[0],alpha=0.7,rot=0) axes[0].set(ylabel='售价均值/万') # 绘制单价均值条形分布图 average_unit_price_grouped_by_decoration.plot.bar(ax=axes[1],alpha=0.7,rot=0) axes[1].set(ylabel='单价均值/元每平米') # 写一个给条形图添加数据标签的函数 def add_data_label(data_name,axes): x = np.arange(len(data_name)) y = data_name.values for a,b in zip(x,y): axes.text(x=a,y=b,s='%.f'%b,ha='center',va= 'bottom') # ha和va参数分别指定数据标签的水平对齐和垂直对其方式 # 给条形图添加数据标签 add_data_label(average_price_grouped_by_decoration,axes[0]) add_data_label(average_unit_price_grouped_by_decoration,axes[1]) fig.suptitle('不同装修情况下二手房的售价均值和单价均值条形图') plt.subplots_adjust(wspace=0.4) # 设置figure对象中两子图的间距 plt.savefig('p13.png') # 保存图片结果如下图所示:
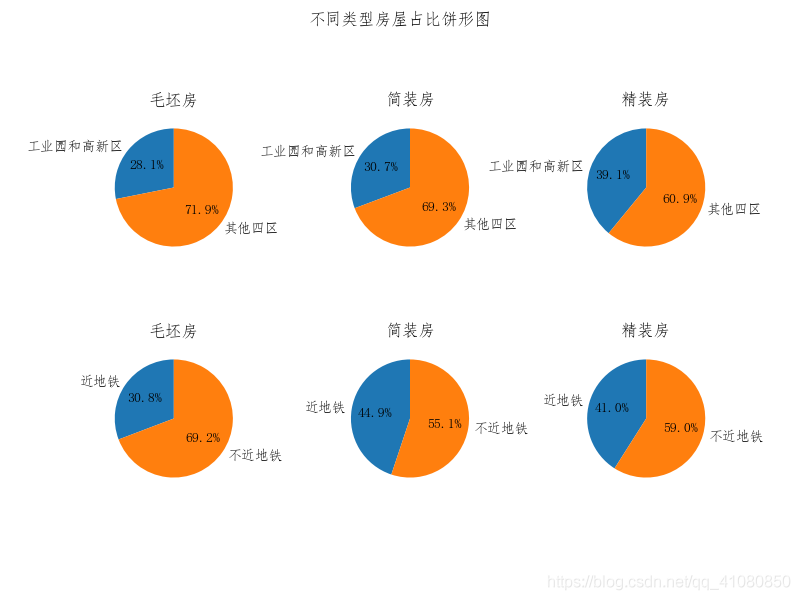
上图中出现了奇怪的现象:毛坯房的售价均值竟然比精装房和简装房还要高,且毛坯房的单价均值高于简装房的单价均值。 对于毛坯房售价均值大于精装房和简装房售价均值的现象,做出如下猜测: 一是数据集中位于好地段的毛坯房占比相对较大; 二是数据集中所有毛坯房的面积均值相对较大; 三是数据集中建造时间离现在较近的毛坯房的占比相对较大; 四是数据集中靠近地铁的毛坯房的占比相对较大。 对于毛坯房的单价均值高于简装房的单价均值,做如下猜测: 一是数据集中位于好地段的毛坯房占比相对较大; 二是数据集中建造时间离现在较近的毛坯房的占比相对较大; 三数据集中靠近地铁的毛坯房的占比相对较大。 下面对上述猜测进行检验: count_by_region_and_decoration = new_data.pivot_table('售价',index='所在区',columns='装修',aggfunc='count') data1 = count_by_region_and_decoration # 分别统计工业园区和高新区内毛坯房、简装房和精装房的数量 roughcast_gongyeyuan_gaoxin = data1.loc['工业园区']['毛坯'] + data1.loc['高新区']['毛坯'] # 统计工业园区和高新区内毛坯房的数量 brief_gongyeyuan_gaoxin = data1.loc['工业园区']['简装'] + data1.loc['高新区']['简装'] # 统计工业园区和高新区内简装房的数量 refined_gongyeyuan_gaoxin = data1.loc['工业园区']['精装'] + data1.loc['高新区']['精装'] # 统计工业园区和高新区内精装房的数量 #分别统计除了工业园区和高新区之外其他四区内毛坯房、简装房和精装房的数量 roughcast_other = data1['毛坯'].sum() - roughcast_gongyeyuan_gaoxin brief_other = data1['简装'].sum() - brief_gongyeyuan_gaoxin refined_other = data1['精装'].sum() - refined_gongyeyuan_gaoxin count_by_subway_and_decoration = new_data.pivot_table('售价',index='近地铁',columns='装修',aggfunc='count') data2 = count_by_subway_and_decoration # 分别统计毛坯房、简装房和精装房中近地铁与不近地铁的房子的数量 roughcast_near_subway = data2.loc['是']['毛坯'] # 近地铁的毛坯房的数量 roughcast_away_from_subway = data2.loc['否']['毛坯'] # 不近地铁的毛坯房的数量 brief_near_subway = data2.loc['是']['简装'] # 近地铁的简装房的数量 brief_away_from_subway = data2.loc['否']['简装'] # 不近地铁的简装房的数量 refined_near_subway = data2.loc['是']['精装'] # 近地铁的精装房的数量 refined_away_from_subway = data2.loc['否']['精装'] # 不地铁的简装房的数量 # 绘制不同情况下的饼形图 fig,axes = plt.subplots(2,3) # 分别绘制毛坯房、简装房和精装房中位于不同区域的房子的占比饼形图 labels1 = ['工业园和高新区','其他四区'] axes[0,0].pie([roughcast_gongyeyuan_gaoxin,roughcast_other],labels=labels1,autopct='%1.1f%%',startangle=90) axes[0,1].pie([brief_gongyeyuan_gaoxin,brief_other],labels=labels1,autopct='%1.1f%%',startangle=90) axes[0,2].pie([refined_gongyeyuan_gaoxin,refined_other],labels=labels1,autopct='%1.1f%%',startangle=90) # 分别绘制毛坯房、简装房和精装房中与地铁站距离不同的房子的占比饼形图 labels2 = ['近地铁','不近地铁'] axes[1,0].pie([roughcast_near_subway,roughcast_away_from_subway],labels=labels2,autopct='%1.1f%%',startangle=90) axes[1,1].pie([brief_near_subway,brief_away_from_subway],labels=labels2,autopct='%1.1f%%',startangle=90) axes[1,2].pie([refined_near_subway,refined_away_from_subway],labels=labels2,autopct='%1.1f%%',startangle=90) # 分别设置子图的标题以及子图中的饼图的纵横比相等 axes[0,0].set(title='毛坯房',aspect='equal') axes[0,1].set(title='简装房',aspect='equal') axes[0,2].set(title='精装房',aspect='equal') axes[1,0].set(title='毛坯房',aspect='equal') axes[1,1].set(title='简装房',aspect='equal') axes[1,2].set(title='精装房',aspect='equal') plt.subplots_adjust(wspace=0.6,hspace=0) # 设置figure对象中子图的间距 fig.suptitle('不同类型房屋占比饼形图') # 设置figure对象的标题 plt.savefig('p14.png') # 保存图片结果如下图所示:
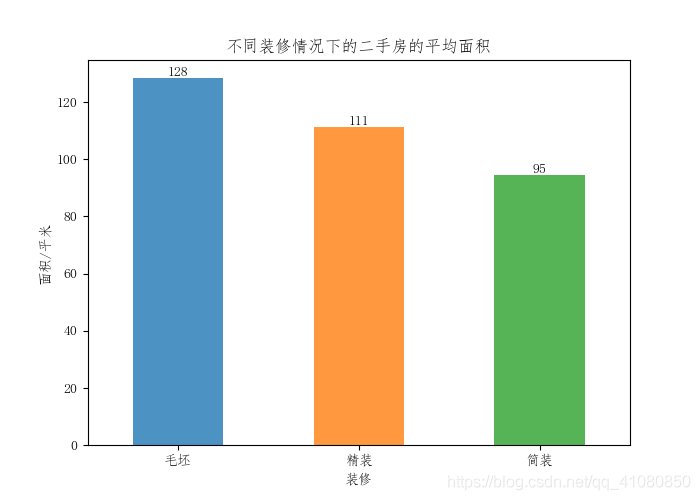
# 绘制毛坯房、简装房和精装房的面积均值条形图 # 准备数据 average_area_grouped_by_decoration1 = new_data['面积'].groupby(new_data['装修']).mean() average_area_grouped_by_decoration2 = average_area_grouped_by_decoration1[1:] # 筛选出毛坯房、简装房和精装房这三者的数据 average_area_grouped_by_decoration3 = average_area_grouped_by_decoration2.sort_values(ascending=False) # 将筛选出来的数据按照降序排序 new_average_area_grouped_by_decoration = average_area_grouped_by_decoration3 # 绘制条形图 fig,axes = plt.subplots(figsize=(7,5) new_average_area_grouped_by_decoration.plot.bar(ax=axes,alpha=0.8,rot=0) axes.set(ylabel='面积/平米',title='不同装修情况下的二手房的平均面积') # 调用add_data_label函数给条形图添加数据标签 add_data_label(new_average_area_grouped_by_decoration,axes) plt.savefig('p15.png') # 保存图片 结果如下图所示:
由以上信息可以判断,与精装房相比,处于房价较高区域的毛坯房占总体的比例和靠近地铁的毛坯房占总体的比例,都小于精装房中相对应的比例;但是毛坯房的整体平均面积要比精装房的整体平均面积大 17平米。这可以合理的解释为什么毛坯房的售价均值稍稍大于精装房,但其单价均值却小于精装房。 与简装房相比,处于房价较高区域的毛坯房占总体的比例略小于简装房中对应的比例,而且靠近地铁站的毛坯房占总体的比例也明显小于简装房中对应的比例,但是为什么毛坯房的售价均值和单价均值都要比简装房的大呢? 我们已经知道,毛坯房的整体平均面积超出简装房的整体平均面积30平米以上,因此毛坯房的单价均值比简装房的单价均值大一定会导致毛坯房的售价均值比简装房的售价均值大。对于毛坯房的单价均值大于简装房的单价均值,进一步猜测是因为建造时间离现在较近的毛坯房占总体的比例高于简装房中对应的比例,从而导致毛坯房的单价均值高于简装房的单价均值。 接下来对上述猜测结果做进一步检验: decoration_and_create_time1 = new_data.pivot_table('售价',index='建造时间',columns='装修',aggfunc='count') decoration_and_create_time2 = decoration_and_create_time1.sort_index(ascending=False) # 按照索引对decoration_and_create_time2进行降序排序 decoration_and_create_time2.fillna(0,inplace=True) # 将数据中的NAN值替换为0 decoration_and_create_time3 = decoration_and_create_time2[['毛坯','简装']] # 筛选出毛坯房与简装房的数据 decoration_and_create_time4 = decoration_and_create_time3.cumsum(axis=0) # 对new_decoration_and_create_time4中的每列数据进行累计求和操作 decoration_and_create_time4 N1 = decoration_and_create_time4['毛坯'][2010] # N1是建造时间为2010年以后的毛坯二手房的数量(包括2010年) N2 = decoration_and_create_time4['毛坯'][1972] - N1 # N2是建造时间为2010年以前的毛坯二手房的数量 N3 = decoration_and_create_time4['简装'][2010] # N3是建造时间为2010年以后的简装二手房的数量(包括2010年) N4 = decoration_and_create_time4['简装'][1972] - N3 # N4是建造时间为2010年以前的简装二手房的数量 roughcast_grouped_by_create_time = pd.Series([N1,N2],index=['2010年以后建造','2010年以前建造']) brief_outfit_grouped_by_create_time = pd.Series([N3,N4],index=['2010年以后建造','2010年以前建造']) # 分别绘制毛坯房与简装房在不同建造时间范围内的占比图 fig,axes = plt.subplots(1,2) roughcast_grouped_by_create_time.plot(kind='pie',ax=axes[0],autopct='%.1f%%',startangle=90,label='') brief_outfit_grouped_by_create_time.plot(kind='pie',ax=axes[1],autopct='%.1f%%',startangle=90,label='') # autopct参数的作用是指定饼形图中数据标签的显示方式 # '%.1f%%'表示数据标签的格式是保留一位小数的百分数 # startangle=90表示饼图的起始绘制角度是偏离x轴90度,并按逆时针绘制 # label=''后,饼形图的左边便不会再显示Series对象的名字 axes[0].set_title('毛坯房') axes[0].set_aspect('equal') # 设置饼图的纵横比相等 axes[1].set_title('简装房') axes[1].set_aspect('equal') fig.suptitle('毛坯房和简装房中建造时间不同的房屋占比饼形图') plt.subplots_adjust(wspace=0.4) # 设置figure对象中两子图的间距 plt.savefig('p16.png') # 保存图片结果如下图所示:
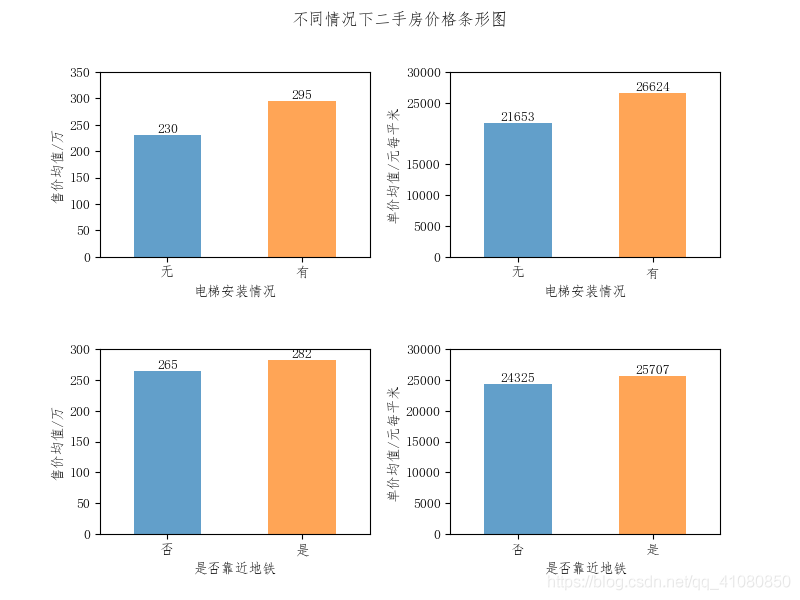
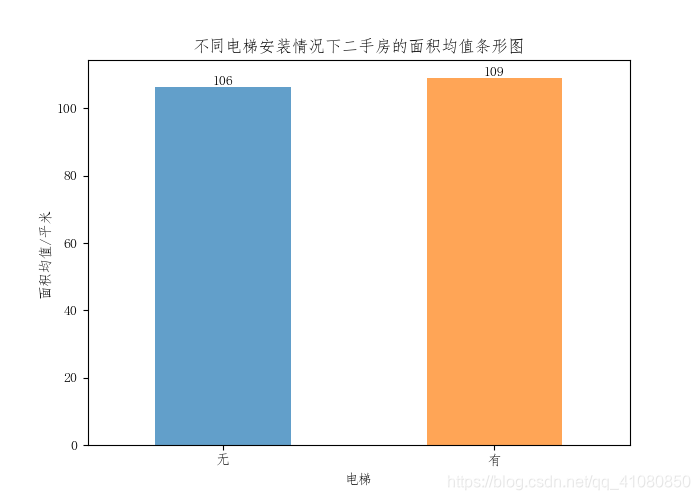
从上图中可以发现,毛坯房中大约80%的房子是2010年以后建造的,而简装房中有大约70%的房子是2010年以前建造的。因此,可以判断毛坯房的单价均值之所以比简装房的单价均值高,很大可能是因为与简装房相比,数据集中的毛坯房大部分都是比较新的房子,在一定程度上提高了其单价均值。 查看电梯安装情况和房源是否靠近地铁站对二手房价格的影响: # 电梯安装情况对二手房价格的影响 average_price_grouped_by_elevator = new_data['售价'].groupby(new_data['电梯']).mean() average_unit_price_grouped_by_elevator = new_data['单价'].groupby(new_data['电梯']).mean() # 房源是否靠近地铁对价格的影响 average_price_grouped_by_subway = new_data['售价'].groupby(new_data['近地铁']).mean() average_unit_price_grouped_by_subway = new_data['单价'].groupby(new_data['近地铁']).mean() # 绘制描述电梯房源所在楼的安装情况与房源是否靠近地铁对房价影响的价格分布条形图 fig,axes = plt.subplots(2,2) # 绘制关于电梯安装情况的房价条形分布图 average_price_grouped_by_elevator.plot.bar(ax=axes[0,0],alpha=0.7,rot=0) average_unit_price_grouped_by_elevator.plot.bar(ax=axes[0,1],alpha=0.7,rot=0) axes[0,0].set(xlabel='电梯安装情况',ylabel='售价均值/万',yticks=[0,50,100,150,200,250,300,350]) axes[0,1].set(xlabel='电梯安装情况',ylabel='单价均值/元每平米',yticks=[0,5000,10000,15000,25000,30000]) # 绘制关于房源是否靠近地铁的房价条形分布图 average_price_grouped_by_subway.plot.bar(ax=axes[1,0],alpha=0.7,rot=0) average_unit_price_grouped_by_subway.plot.bar(ax=axes[1,1],alpha=0.7,rot=0) axes[1,0].set(xlabel='是否靠近地铁',ylabel='售价均值/万',yticks=[0,50,100,150,200,250,300]) axes[1,1].set(xlabel='是否靠近地铁',ylabel='单价均值/元每平米',yticks=[0,5000,10000,15000,20000,25000,30000]) # 依次给四个条形图添加上数据标签 add_data_label(average_price_grouped_by_elevator,axes[0,0]) add_data_label(average_unit_price_grouped_by_elevator,axes[0,1]) add_data_label(average_price_grouped_by_subway,axes[1,0]) add_data_label(average_unit_price_grouped_by_subway,axes[1,1]) fig.suptitle('不同情况下二手房价格条形图') plt.subplots_adjust(wspace=0.3,hspace=0.5) # 设置子图的间距 plt.savefig('p17.png') # 保存图片结果如下图所示:
上图表明与不靠近地铁站的二手房相比,靠近地铁站的二手房其单价均值要高1382。一套100平米的二手房,在其他条件相同的情况下,是否靠近地铁站会造成二手房的价格相差10万以上。而从不同电梯安装情况下的二手房价格条形图中可以看到,对于安装了电梯的房子,其售价均值上比没有安装电梯的房子要贵65万左右,单价均值比没有安装电梯的房子每平米要贵5000左右。为什么一部电梯会对房子的价格产生这么大的影响? 对于有无安装电梯的房子,猜测两者售价均值出现较大差异的原因如下: 猜测一:有电梯的房子的平均面积较大; 猜测一:有电梯的房子中处于房价较高的区的比较多,而没电梯的房子中只有少部分处于房价较高的区; 猜测三:有电梯的房子中靠近地铁站的比较多,而没电梯的房子中只有少部分靠近地铁站; 猜测四:有电梯的房子中建造时间离现在比较近的房子占总体的比例较大。 对于有无安装电梯房子,猜测两者单价均值出现较大差异的原因如下: 猜测一:有电梯的房子中处于房价较高的区域的比较多,而没电梯的房子中只有少部分处于房价较高的区; 猜测二:有电梯的房子中靠近地铁站的比较多,而没电梯的房子中只有少部分靠近地铁站; 猜测三:有电梯的房子中建造时间离现在比较近的房子占总体的比例较大。 下面对上述猜测进行检验: #绘制不同电梯安装情况下二手房的面积均值条形图 # 准备数据 average_area_grouped_by_elevator = new_data['面积'].groupby(new_data['电梯']).mean() # 绘制条形图 fig,axes = plt.subplots(figsize=(7,5)) average_area_grouped_by_elevator.plot.bar(ax=axes,alpha=0.7,rot=0) axes.set(ylabel='面积均值/平米',title='不同电梯安装情况下二手房的面积均值条形图') # 调用add_data_label函数给条形图添加数据标签 add_data_label(average_area_grouped_by_elevator,axes) plt.savefig('p18.png')结果如下图所示:
由上图可以看出,面积不是造成有无电梯的二手房售价出现巨大差异的主要原因。 count_by_region_and_elevator = new_data.pivot_table('售价',index='所在区',columns='电梯',aggfunc='count') count_by_subway_and_elevator = new_data.pivot_table('售价',index='近地铁',columns='电梯',aggfunc='count') count_by_create_time_and_elevator = new_data.pivot_table('售价',index='建造时间',columns='电梯',aggfunc='count') # 分别统计不同分类标准下,有电梯和无电梯的二手房中属于不同类别的房子的数量: # 因为工业园区与高新区单位房价较高,所以无论是装有电梯的二手房还是没装电梯的二手房都被分成位于工业园区或高新区和位于其他四区这两类 # 以房子所在区为分类标准 # 工业园区和高新区中装有电梯的二手房数量 gongyeyuan_gaoxin_with_elevator = count_by_region_and_elevator.loc['工业园区']['有'] + count_by_region_and_elevator.loc['高新区']['有'] # 其他四区中装有电梯的二手房数量 other_region_with_elevator = count_by_region_and_elevator['有'].sum() - gongyeyuan_gaoxin_with_elevator # 工业园区和高新区中没装电梯的二手房数量 gongyeyuan_gaoxin_without_elevator = count_by_region_and_elevator.loc['工业园区']['无'] + count_by_region_and_elevator.loc['高新区']['无'] # 其他四区中没装电梯的二手房数量 other_region_without_elevator = count_by_region_and_elevator['无'].sum() - gongyeyuan_gaoxin_without_elevator # 以房源是否靠近地铁为分类标准 near_subway_with_elevator = count_by_subway_and_elevator.loc['是']['有'] # 装有电梯的二手房中靠近地铁站的房子数量 far_from_subway_with_elevator = count_by_subway_and_elevator.loc['否']['有'] # 装有电梯的二手房中远离地铁站的房子数量 near_subway_without_elevator = count_by_subway_and_elevator.loc['是']['无'] # 没装电梯的二手房中靠近地铁站的房子数量 far_from_subway_without_elevator = count_by_subway_and_elevator.loc['否']['无'] # 没装电梯的二手房中远离地铁站的房子数量 # 绘制以所在区和是否靠近地铁为分类标准的饼形图 fig,axes = plt.subplots(2,2) labels1 = ['工业园区和高新区','其他四区'] # 饼图的标签 axes[0,0].pie([gongyeyuan_gaoxin_with_elevator,other_region_with_elevator],labels=labels1,autopct='%1.1f%%',startangle=90) axes[0,1].pie([gongyeyuan_gaoxin_without_elevator,other_region_without_elevator],labels=labels1,autopct='%1.1f%%',startangle=90) labels2 = ['靠近地铁站','不靠近地铁站'] # 饼图的标签 axes[1,0].pie([near_subway_with_elevator,far_from_subway_with_elevator],labels=labels2,autopct='%1.1f%%',startangle=90) axes[1,1].pie([near_subway_without_elevator,far_from_subway_without_elevator],labels=labels2,autopct='%1.1f%%',startangle=90) # 设置子图的标题,并设置饼图的纵横比相等 axes[0,0].set(title='装有电梯',aspect='equal') axes[0,1].set(title='没装电梯',aspect='equal') axes[1,0].set(title='装有电梯',aspect='equal') axes[1,1].set(title='没装电梯',aspect='equal') fig.suptitle('不同分类标准下各类二手房占比饼形图') # 设置figure对象的标题 plt.savefig('p19.png') # 保存图片结果如下图所示:
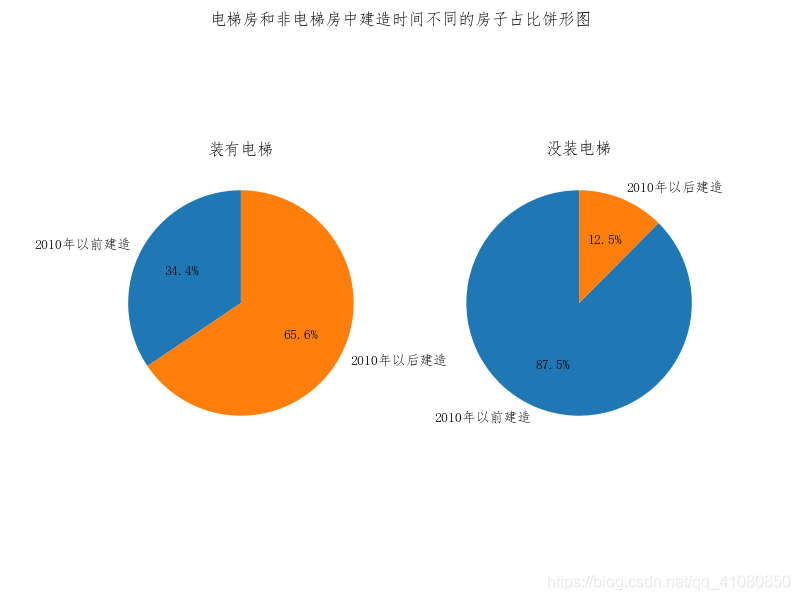
上图表明装有电梯二手房中,位于房价较高的区域的比例远高于没装电梯的二手房中对应的比例。而装有电梯的二手房中,靠近地铁站的房子的占比明显低于没装电梯的二手房中对应的比例。 # 绘制建造时间为分类标准的饼形图 # 准备数据 before_2010_with_elevator = count_by_create_time_and_elevator.loc[:2010]['有'].sum() # 装有电梯的房子中建造时间在2010年以前的数量 after_2010_with_elevator = count_by_create_time_and_elevator.loc[2011:]['有'].sum() # 装有电梯的房子中建造时间在2010年以后的数量 before_2010_without_elevator = count_by_create_time_and_elevator.loc[:2010]['无'].sum() # 没装电梯的房子中建造时间在2010年以前的数量 after_2010_without_elevator = count_by_create_time_and_elevator.loc[2011:]['无'].sum() # 没装电梯的房子中建造时间在2010年以后的数量 # 绘制饼形图 fig,axes = plt.subplots(1,2,figsize=(8,6)) labels3 = ['2010年以前建造','2010年以后建造'] # 指定饼图标签 axes[0].pie([before_2010_with_elevator,after_2010_with_elevator],labels=labels3,autopct='%1.1f%%',startangle=90) axes[1].pie([before_2010_without_elevator,after_2010_without_elevator],labels=labels3,autopct='%1.1f%%',startangle=90) # 设置子图的标题,并设置饼图的纵横比相等 axes[0].set(title='装有电梯',aspect='equal') axes[1].set(title='没装电梯',aspect='equal') fig.suptitle('电梯房和非电梯房中建造时间不同的房子占比饼形图') # 设置figure对象的标题 plt.savefig('p20.png') # 保存图片结果如下图所示:
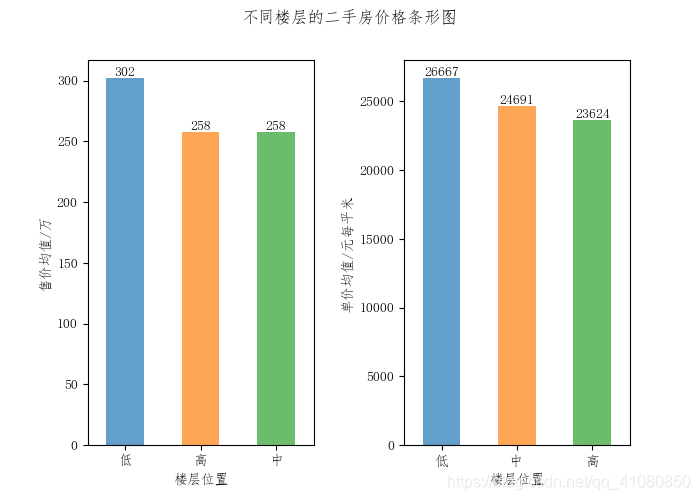
由以上信息,判断装有电梯的二手房之所以比没装电梯的二手房售价要高出65万左右,很大可能是因为装有电梯的二手房中,位于房价较高区域的房子的占比和建造时间距离现在不超过八年的房子的占比都比没装电梯的二手房中对应的比例要高。 查看房屋所处的楼层位置对价格的影响: average_price_groued_by_floor_location = new_data['售价'].groupby(new_data['楼层']).mean() # 计算位于不同楼层的二手房的售价均值 average_price_groued_by_floor_location.sort_values(ascending=False,inplace=True) average_unit_price_groued_by_floor_location = new_data['单价'].groupby(new_data['楼层']).mean() # 房屋所处的楼层位置对价格的影响 average_unit_price_groued_by_floor_location.sort_values(ascending=False,inplace=True) # 绘制处于不同楼层的二手房价格的条形分布图 fig,axes = plt.subplots(1,2,figsize=(7,5)) average_price_groued_by_floor_location.plot.bar(ax=axes[0],alpha=0.7,rot=0) average_unit_price_groued_by_floor_location.plot.bar(ax=axes[1],alpha=0.7,rot=0) axes[0].set(xlabel='楼层位置',ylabel='售价均值/万') axes[1].set(xlabel='楼层位置',ylabel='单价均值/元每平米') # 调用add_data_label函数给条形图添加数据标签 add_data_label(average_price_groued_by_floor_location,axes[0]) add_data_label(average_unit_price_groued_by_floor_location,axes[1]) fig.suptitle('不同楼层的二手房价格条形图') # 设置figure对象的标题 plt.subplots_adjust(wspace=0.4) # 设置figure对象中子图的间距 plt.savefig('p21.png') # 保存图片结果如下图所示:
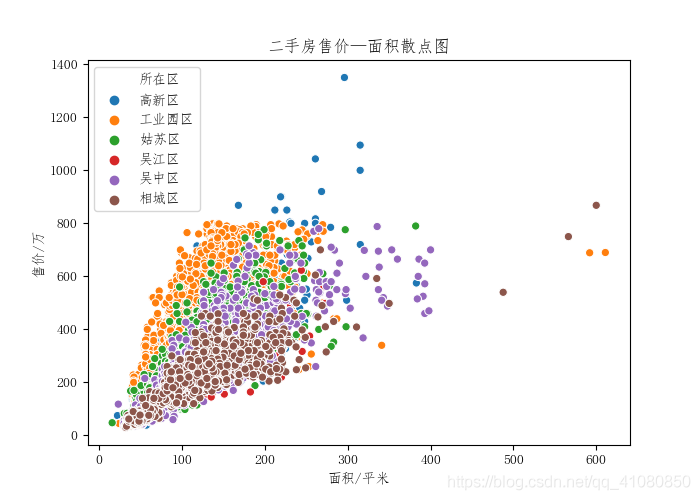
上图表明,对于位于低楼层的二手房,其售价和单价都比位于高楼层和低楼层的二手房明显要高。 查看房屋的面积对价格的影响: 先看整体范围内,二手房面积与价格的关系: # 绘制六个区汇总后的房屋面积——售价散点图 fig,axes = plt.subplots(figsize=(7,5)) sns.scatterplot(x='面积',y='售价',hue='所在区',data=new_data,ax=axes) axes.set(xlabel='面积/平米',ylabel='售价/万',title='二手房售价—面积散点图') plt.savefig('p22.png') # 保存图片结果如下图所示:
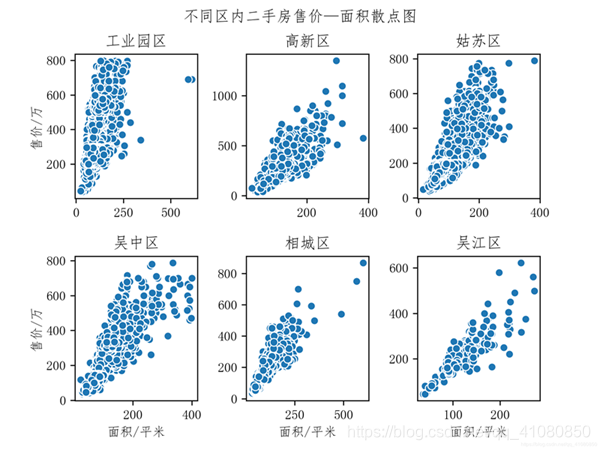
由以上信息可知整体范围内二手房的售价与面积的相关性为较强,达到了0.685,整体来说,随着的单面积的增加,二手房的售价也随之增加;而二手房的单价与面积几乎不相关。 再看每个区内,二手房售价与面积的关系: # 分别绘制六个区内二手房售价——面积散点图 df = new_data.set_index(['所在区']) # 将new_data中的所在区这一列指定为索引 # 根据索引筛选出六个不同区的售价与面积数据 gongyeyuanqu = df.loc['工业园区'][['售价','单价','面积']] gaoxinqu = df.loc['高新区'][['售价','单价','面积']] gusuqu = df.loc['姑苏区'][['售价','单价','面积']] wuzhongqu = df.loc['吴中区'][['售价','单价','面积']] xiangchengqu = df.loc['相城区'][['售价','单价','面积']] wujiangqu = df.loc['吴江区'][['售价','单价','面积']] # 绘制售价——面积散点图 fig,axes = plt.subplots(2,3) sns.scatterplot(x='面积',y='售价',data=gongyeyuanqu,ax=axes[0,0]) sns.scatterplot(x='面积',y='售价',data=gaoxinqu,ax=axes[0,1]) sns.scatterplot(x='面积',y='售价',data=gusuqu,ax=axes[0,2]) sns.scatterplot(x='面积',y='售价',data=wuzhongqu,ax=axes[1,0]) sns.scatterplot(x='面积',y='售价',data=xiangchengqu,ax=axes[1,1]) sns.scatterplot(x='面积',y='售价',data=wujiangqu,ax=axes[1,2]) fig.suptitle('不同区内二手房售价—面积散点图') # 设置figure对象的标题 # 设置子图的坐标轴标签和标题 axes[0,0].set(xlabel='',ylabel='售价/万',title='工业园区') axes[0,1].set(xlabel='',ylabel='',title='高新区') axes[0,2].set(xlabel='',ylabel='',title='姑苏区') axes[1,0].set(xlabel='面积/平米',ylabel='售价/万',title='吴中区') axes[1,1].set(xlabel='面积/平米',ylabel='',title='相城区') axes[1,2].set(xlabel='面积/平米',ylabel='',title='吴江区') plt.subplots_adjust(wspace=0.4,hspace=0.4) # 设置figure对象中子图的间距 plt.savefig('p23.png') # 保存图片结果如下图所示:
计算各区内二手房售价与面积的相关系数: # 分别计算不同区内二手房售价/单价与面积的相关系数 gongyeyuanqu_correlation_coefficient_between_price_and_area = gongyeyuanqu['售价'].corr(gongyeyuanqu['面积']) gaoxinqu_correlation_coefficient_between_price_and_area = gaoxinqu['售价'].corr(gaoxinqu['面积']) gusuqu_correlation_coefficient_between_price_and_area = gusuqu['售价'].corr(gusuqu['面积']) wuzhongqu_correlation_coefficient_between_price_and_area = wuzhongqu['售价'].corr(wuzhongqu['面积']) xiangchengqu_correlation_coefficient_between_price_and_area = xiangchengqu['售价'].corr(xiangchengqu['面积']) wujiangqu_correlation_coefficient_between_price_and_area = wujiangqu['售价'].corr(wujiangqu['面积']) corr1 = gongyeyuanqu_correlation_coefficient_between_price_and_area corr2 = gaoxinqu_correlation_coefficient_between_price_and_area corr3 = gusuqu_correlation_coefficient_between_price_and_area corr4 = wuzhongqu_correlation_coefficient_between_price_and_area corr5 = xiangchengqu_correlation_coefficient_between_price_and_area corr6 = wujiangqu_correlation_coefficient_between_price_and_area print(corr1,corr2,corr3,corr4,corr5,corr6) # 输出结果为: # 0.6841568087167097 0.7454465461851735 0.8464407898530029 0.8390072605746044 0.829712023546309 0.8608067483548217由以上信息可知:工业园区和高新区内二手房的售价与面积的相关系数明显比其他四区内的小。这说明,工业园区和高新区内二手房的售价受其他因素的影响比其他区内二手房售价受其他因素的影响更大。 查看房屋的建造时间对价格的影响: # 绘制二手房价格随建造时间变化的折线图 fig,axes = plt.subplots(1,2,figsize=(7,5)) average_price_affected_by_create_time = new_data['售价'].groupby(new_data['建造时间']).mean() average_unit_price_affected_by_create_time = new_data['单价'].groupby(new_data['建造时间']).mean() average_price_affected_by_create_time.plot(kind='line',ax=axes[0]) average_unit_price_affected_by_create_time.plot(kind='line',ax=axes[1]) axes[0].set(ylabel='售价均值/万') axes[1].set(ylabel='单价均值/元每平米') fig.suptitle('二手房价格随建造时间变化折线图') plt.subplots_adjust(wspace=0.5) # 设置figure对象中子图的间距 plt.savefig('p24') # 保存图片结果如下图所示:
从上图可以看到,随着建造时间的接近,无论是二手房的售价还是单价,整体上都呈上升趋势。而在建造时间的局部范围内,二手房的售价和单价都有上下波动的现象。 3)探究更容易受到人们青睐的二手房具有什么特点? updated_data = new_data.copy() # 深度复制一份new_data数据,copy中的deep参数默认是True。 # 将分别加一后房源的关注人数和带看次数做乘积,用以表示房源的受欢迎程度,简记为受欢迎度 updated_data['受欢迎度']= (updated_data['关注人数'] + 1) * (updated_data['带看次数'] + 1) updated_data.head() # 查看updated_data的前五条数据输出结果如下图所示:
输出结果如下图所示:
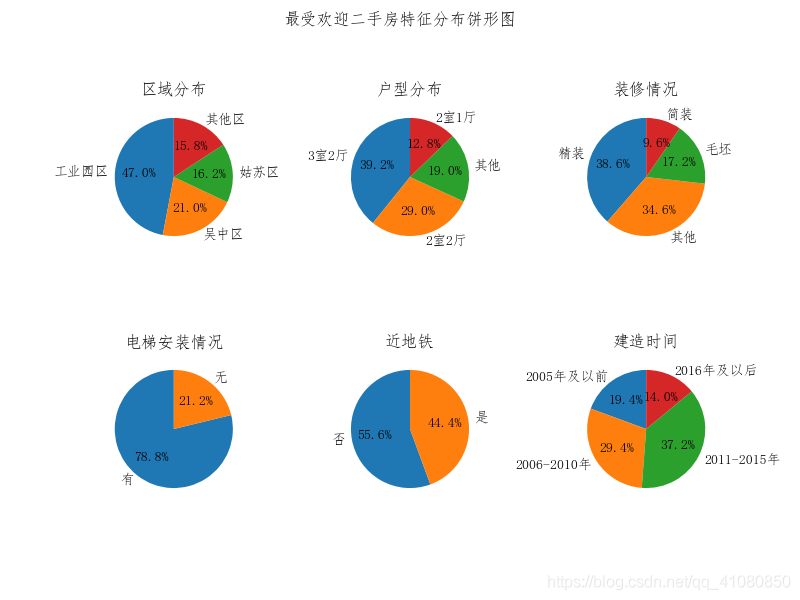
分析这500套房子有什么特点: # 区域分布数据 count_by_region_500_one = new_sort_by_popularity['所在区'].groupby(new_sort_by_popularity['所在区']).count() count_by_region_500_two =count_by_region_500_one[count_by_region_500_one > 50] count_by_region_500_two['其他区'] = count_by_region_500_one[count_by_region_500_one < 51].sum() new_count_by_region_500 = count_by_region_500_two.sort_values(ascending=False) # 户型分布数据 # 对不同户型的房子进行统计计数 count_by_house_type_500_one = new_sort_by_popularity['户型'].groupby(new_sort_by_popularity['户型']).count() # 筛选出总数大于50套的户型 count_by_house_type_500_two = count_by_house_type_500_one[count_by_house_type_500_one > 60] # 将总数小于50套的户型统一归为其他类 count_by_house_type_500_two['其他'] = count_by_house_type_500_one[count_by_house_type_500_one < 60].sum() new_count_by_house_type_500 = count_by_house_type_500_two.sort_values(ascending=False) # 装修情况分布数据 count_by_decoration_500 = new_sort_by_popularity['装修'].groupby(new_sort_by_popularity['装修']).count() # count_by_decoration_500_two = count_by_decoration_500_one[['毛坯','简装','精装']] new_count_by_decoration_500 = count_by_decoration_500.sort_values(ascending=False) # 电梯安装情况分布数据 count_by_elevator_500 = new_sort_by_popularity['电梯'].groupby(new_sort_by_popularity['电梯']).count() new_count_by_elevator_500 = count_by_elevator_500.sort_values(ascending=False) # 距离地铁站远近情况分布数据 count_by_subway_500 = new_sort_by_popularity['近地铁'].groupby(new_sort_by_popularity['近地铁']).count() new_count_by_subway_500 = count_by_subway_500.sort_values(ascending=False) # 建造时间分布数据 # 先对不同时间建造的房屋进行分组统计 count_by_create_time_500 = new_sort_by_popularity['建造时间'].groupby(new_sort_by_popularity['建造时间']).count() # 将房屋建造时间分成2000年及以前、2001-2005年、2006-2010年、2011-2015年、2016年及以后这五组数据,并分组计数 count_by_create_time1_500 = count_by_create_time_500.loc[:2005].sum() count_by_create_time2_500 = count_by_create_time_500.loc[2006:2010].sum() count_by_create_time3_500 = count_by_create_time_500.loc[2011:2015].sum() count_by_create_time4_500 = count_by_create_time_500.loc[2016:].sum() # 创建一个Series对象用于存储不同建造时间建造的二手房的数据 new_count_by_create_time_500 = pd.Series([count_by_create_time1_500,count_by_create_time2_500,count_by_create_time3_500, count_by_create_time4_500], index=['2005年及以前','2006-2010年','2011-2015年','2016年及以后']) # 绘制饼形图 fig,axes = plt.subplots(2,3,figsize=(8,6)) new_count_by_region_500.plot(kind='pie',ax=axes[0,0],autopct='%.1f%%',startangle=90,label='') new_count_by_house_type_500.plot(kind='pie',ax=axes[0,1],autopct='%.1f%%',startangle=90,label='') new_count_by_decoration_500.plot(kind='pie',ax=axes[0,2],autopct='%.1f%%',startangle=90,label='') new_count_by_elevator_500.plot(kind='pie',ax=axes[1,0],autopct='%.1f%%',startangle=90,label='') new_count_by_subway_500.plot(kind='pie',ax=axes[1,1],autopct='%.1f%%',startangle=90,label='') new_count_by_create_time_500.plot(kind='pie',ax=axes[1,2],autopct='%.1f%%',startangle=90,label='') # autopct参数的作用是指定饼形图中数据标签的显示方式 # '%.1f%%'表示数据标签的格式是保留一位小数的百分数 # startangle=90表示饼图的起始绘制角度是偏离x轴90度,并按逆时针绘制 # label=''后,饼形图的左边便不会再显示Series对象的名字 # 设置子图的标题以及设置饼形图的纵横比相等 axes[0,0].set(title='区域分布',aspect='equal') axes[0,1].set(title='户型分布',aspect='equal') axes[0,2].set(title='装修情况',aspect='equal') axes[1,0].set(title='电梯安装情况',aspect='equal') axes[1,1].set(title='近地铁',aspect='equal') axes[1,2].set(title='建造时间',aspect='equal') plt.subplots_adjust(wspace=0.6) fig.suptitle('最受欢迎二手房特征分布饼形图') # 设置figure对象的标题 plt.savefig('p25.png') # 保存图片结果如下图所示:
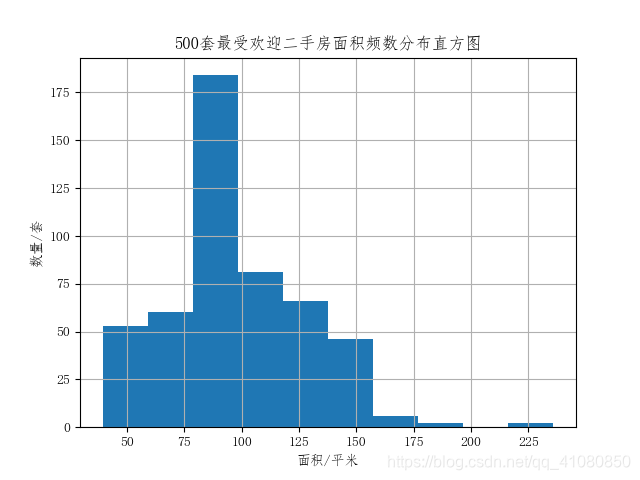
查看这500套二手房面积的分布特点: fig,axes = plt.subplots(figsize=(7,5)) new_sort_by_popularity['面积'].hist(ax=axes,bins=10) axes.set(xlabel='面积/平米',ylabel='数量/套',title='500套最受欢迎二手房面积频数分布直方图') plt.savefig('p26.png') # 保存图片结果如下图所示:
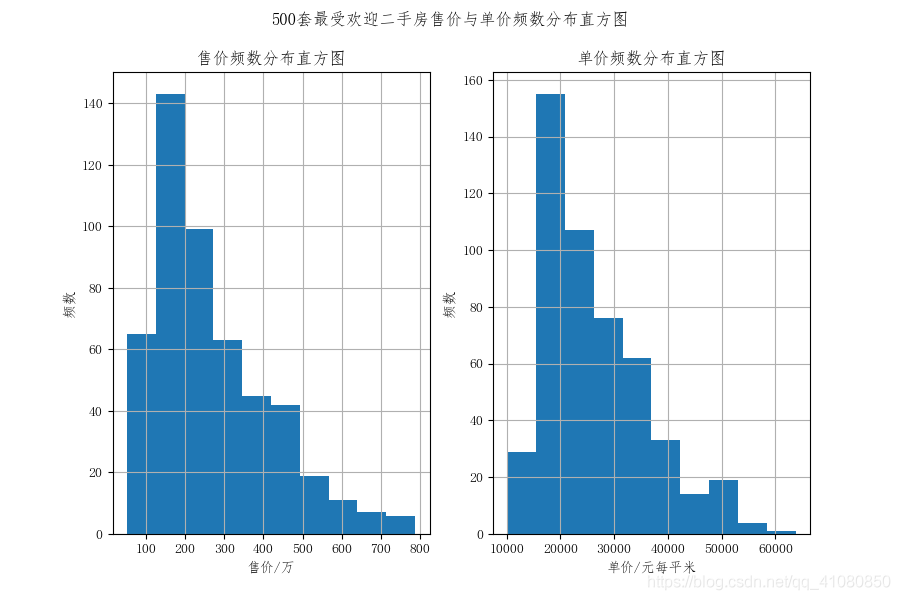
接下来查看这500套二手房的售价与单价的分布特点: fig,axes = plt.subplots(1,2,figsize=(9,6)) new_sort_by_popularity['售价'].hist(ax=axes[0],bins=10) axes[0].set(xlabel='售价/万',ylabel='频数',title='售价频数分布直方图',xticks=[100,200,300,400,500,600,700,800]) new_sort_by_popularity['单价'].hist(ax=axes[1],bins=10) axes[1].set(xlabel='单价/元每平米',ylabel='频数',title='单价频数分布直方图') plt.suptitle('500套最受欢迎二手房售价与单价频数分布直方图') plt.savefig('p27.png') # 保存图片结果如下图所示:
至此,可以回答在项目初期确立的三个问题。 (a)苏州市所辖六区范围内的二手房中:房源分布方面,工业园区、姑苏区和吴中区这三个区的房子占比超过了70%,其中又以工业园区内的二手房数量为最多;户型方面,占比最多的户型是三室两厅接近40%,其次是两室两厅达到了21%,也就是说这两种户型的房子的需求量最大;值得注意的是,在房屋朝向方面,90%以上的二手房的朝向都是南北朝向;装修方面,在所有清晰表明装修情况的二手房中,精装房的占比超过了60%;楼层位置方面,位于高中低三种不同楼层位置的二手房占比差别不是太大;不过总楼层数方面,将近50%的二手房位于总楼层数不超过10层的楼;电梯方面,60%的二手房都安装了电梯;交通方面,接近40%的二手房靠近地铁站;建造时间方面,随着建造时间距离现在越来越近,二手房的数量整体呈增加趋势,具体来说,2011年及其以后建造的二手房占比接近50%;面积方面,70%以上的二手房的面积在50-150平米之间,30%以下的二手房的面积小于50平米或者大于150平米。价格方面,70%以上的二手房的售价在100-450万之间,30%以下的二手房售价在小于100万或者大于450万。同时,65%以上的二手房的单价在15000-35000每平米之间,35%以下的二手房的单价小于15000每平米或者大于35000每平米。 (b)影响二手房价格最主要的因素是房源的地理位置,具体来说就是房源所处的区域、房源是否靠近地铁站,其他影响较大的因素还包括二手房的装修情况、建造时间以及楼层位置。 (c)更容易受到人们青睐的二手房具有如下特点:一方面,房源位于工业园区、户型为三室两厅或者两室两厅、装有电梯且建造时间离现在较近;另一方面,面积大致在75-100平米这个范围内、售价在150-250万这个范围内。 参考资料: 《数据分析——企业的贤内助》 《商务与经济统计》第十三版 《Python for Data Analysis》第二版 https://www.cnblogs.com/Detector/p/8850280.html http://seaborn.pydata.org/generated/seaborn.distplot.html#seaborn.distplot http://seaborn.pydata.org/generated/seaborn.barplot.html#seaborn.barplot https://blog.csdn.net/weixin_41789707/article/details/81035997 https://www.jianshu.com/p/5ae17ace7984 https://zhuanlan.zhihu.com/p/37087556 https://wenku.baidu.com/view/036fea38aef8941ea66e052f.html
|








【本文地址】