| Halcon OCR | 您所在的位置:网站首页 › 卷积神经网络字符识别 › Halcon OCR |
Halcon OCR
|
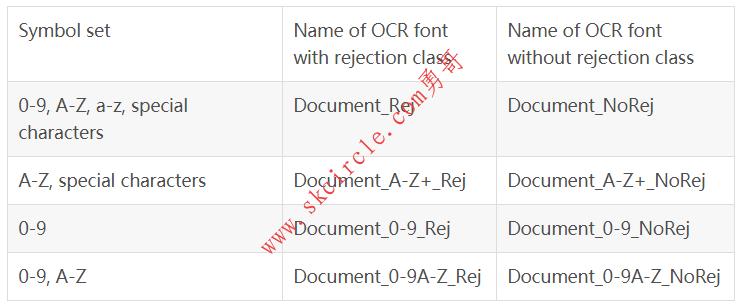
OCR(Optical Character Recongnition)即我们通常意义上讲的光学字符识别。在HALCON中,OCR常被用来分割区域及读取识别图像中的字符含义。 HALCON中提供了一组预先训练好的字体(在安装目录下的ocr文件夹中),这些字体来源于各个领域的大量训练数据,可识别文档、制药、工业产品或点打印,甚至手写数字文本。此外,HALCON还包括用于OCR-A和OCR-N的预训练字体,以及基于卷积神经网络(CNN)的通用字体。 18.1 OCR字符识别 使用HALCON提供的一种预训练字体读取图中的数字。
18.2 图像分割 对于图像分割,可以使用的方法很多。常用的有Blob分析、自动文本阅读器、手动文本阅读器、通用字符分割等。 18.2.1 Blob分析 Blob分析包括设定有效ROI、图像滤波 (mean_image、gauss_filter、binomial_filter、median_image)、点状打印字符增强(dots_image)、灰度形态等。 (1)Example: hdevelop/Applications/OCR/engraved.hdev 此示例读取图中所示的金属表面上的雕刻文本。
通过使用Blob分析来分割图像:不能通过简单的阈值分割来提取字符。相反,简单的分割只能得到部分字符和产生大量噪声。使用灰度形态学预处理图像可以分割出真实字符。 gray_range_rect (Image, ImageResult, 7, 7) * 图像取反,字符识别默认为白色背景黑色字体 invert_image (ImageResult, ImageInvert) threshold (ImageResult, Region, 128, 255) connection (Region, ConnectedRegions) select_shape (ConnectedRegions, SelectedRegions, 'area', 'and', 1000,99999) sort_region (SelectedRegions, SortedRegions,'first_point','true','column') * 最后识别分割的区域结果 read_ocr_class_mlp (FontName, OCRHandle) for I := 1 to Number by 1 select_obj (SortedRegions, ObjectSelected, I) do_ocr_single_class_mlp (ObjectSelected, ImageInvert, OCRHandle, 1, Class, Confidence) endfor clear_ocr_class_mlp (OCRHandle)(2)Example: hdevelop/Applications/OCR/ocrcolor.hdev 此示例提取表单中的字符。一个典型的问题是字符没有打印在正确的位置,如图所示。
由于字符打印在线上,不能简单的通过阈值分割来提取。因此这里通过字符颜色与表单颜色不同来分割图像,这里仅需考虑红色和绿色通道强度的差异。 threshold (Green, ForegroundRaw, 0, 220) sub_image (RedReduced, GreenReduced, ImageSub, 2, 128) mean_image (ImageSub, ImageMean, 3, 3) binary_threshold (ImageMean, Cluster1, 'smooth_histo', 'dark', UsedThreshold) difference (Foreground, Cluster1, Cluster2) concat_obj (Cluster1, Cluster2, Cluster) opening_circle (Cluster, Opening, 2.5) * 使用形态学对所选像素进行处理 closing_rectangle1 (NumberRegion, NumberCand, 1, 20) difference (Image, NumberCand, NoNumbers) connection (NumberRegion, NumberParts) intensity (NumberParts, Green, MeanIntensity, Deviation) expand_gray_ref (NumberParts, Green, NoNumbers, Numbers, 20, 'image', MeanIntensity, 48) union1 (Numbers, NumberRegion) connection (NumberRegion, Numbers) * 由于颜色的变化,因此不能使用背景的灰度值。人为生成一幅图像,将字符区域灰度值设为0,背景区域灰度值设为255。 paint_region (NoNumbers, Green, ImageOCRRaw, 255, 'fill') paint_region (NumberRegion, ImageOCRRaw, ImageOCR, 0, 'fill') * 在人工图像中执行实际的字符分类。 read_ocr_class_mlp ('Industrial_0-9_NoRej', OCRHandle) do_ocr_multi_class_mlp (FinalNumbers, ImageOCR, OCRHandle, RecChar, Confidence) clear_ocr_class_mlp (OCRHandle)18.2.2 自动文本阅读器 自动文本阅读器非常易于使用,它将分割和识别两个步骤组合成find_text的一个调用,且无需进行大量的参数调整。simple_reading.hdev和bottle.hdev为熟悉自动文本阅读器提供了一个很好的起点。 要使用自动文本阅读器,必须使用create_text_model_reader创建模型,并将参数Mode设置为'auto'。在这里,必须传递OCR分类器参数。然后可以使用set_text_model_param指定分割参数,并可以使用get_text_model_param查询。完成后,可以使用find_text读取文本。该算子根据区域和灰度值特征选择候选字符,并使用给定的OCR分类器对其进行验证。 如果文本必须匹配某个模式或结构,则可以设置运算符set_text_model_param的参数'text_line_structure',它确定结构,即要检测的文本的每个字符块的字符数。 自动文本阅读器假定文本方向大致水平。如果文本未水平对齐,则可以在使用find_text之前使用text_line_orientation和rotate_image矫正方向。 find_text的结果在TextResultID中返回,可以分别使用get_text_result和get_text_object查询。get_text_result返回分类结果。get_text_object返回自动文本阅读器分割的字符区域。要删除结果和文本模型,需分别使用clear_text_result和clear_text_model。 (1)Example: solution_guide/basics/simple_reading.hdev 此示例程序演示了如何使用预训练的OCR字体使用自动文本阅读器识别简单字符。 * 使用create_text_model_reader创建模型,并将参数Mode设置为'auto'。 create_text_model_reader('auto','Document_09_NoRej',TextModel) find_text (Image, TextModel, TextResultID) get_text_result (TextResultID, 'class', Classes)(2)Example: hdevelop/Applications/OCR/bottle.hdev 这个例子读取图中瓶子上的日期。
由于图像中可见大量文本,因此需要设置文本模型的一些参数以适当地限制读取结果。 FontName := 'Universal_0-9_NoRej' create_text_model_reader ('auto', FontName, TextModel) * 增加最小笔划宽度以排除日期周围可见的所有文本 set_text_model_param (TextModel, 'min_stroke_width', 6) * 设置日期的已知结构以确保仅读取与该结构匹配的文本 set_text_model_param (TextModel, 'text_line_structure', '2 2 2') * find_text (Bottle, TextModel, TextResultID) * 显示分割结果 get_text_object (Characters, TextResultID, 'all_lines') * 显示读取结果 get_text_result (TextResultID, 'class', Classes)18.2.3 手动文本阅读器 如果要分割雕刻文本或者不能提供合适的OCR分类器,则不能使用自动文本阅读器。相反,可以在这些情况下使用手动文本阅读器。 要使用手动文本阅读器,必须使用create_text_model_reader创建模型,并将参数Mode设置为'manual'。需注意,在这种情况下,不能传递OCR分类器。可以与Manual Text Finder一起使用的所有参数的名称都以'manual_'开头。 (1)Example: hdevelop/Applications/OCR/find_text_dongle.hdev 此示例演示如何在执行OCR之前使用find_text对加密狗上的点打印字符进行分割。
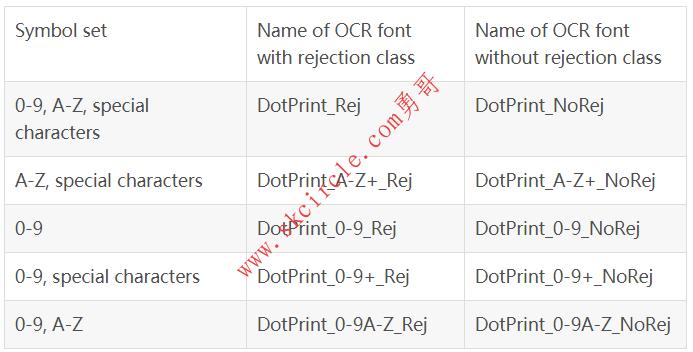
18.5.4 预训练字体 ’DotPrint’ ‘DotPrint’可用于读取用点式打印机打印的字符。它不包含小写字符。 可用的特殊字符:- / . * :
18.5.5 预训练字体 ’HandWritten_0-9’ ‘HandWritten_0-9’可用于读取手写数字。它包含数字0-9。 可用的特殊字符:无
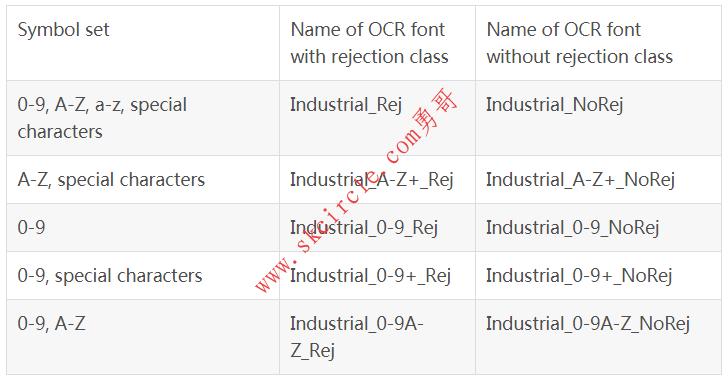
18.5.6 预训练字体 ’Industrial’ ‘Industrial’可用于读取以Arial,OCR-B或其他sans-serif字体等打印的字符。例如,这些字体通常用于打印标签。 可用的特殊字符:- / + . $ % * e £ ¥
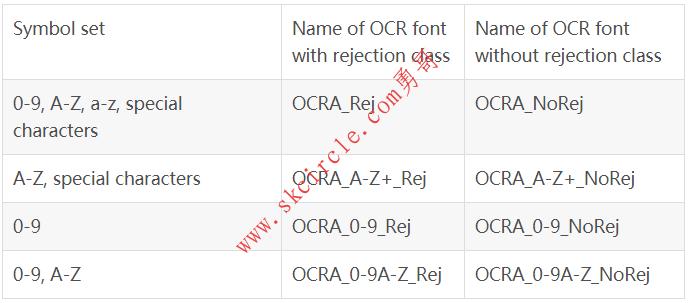
18.5.7 预训练字体 ’OCR-A’ ‘OCR-A’可用于读取以字体OCR-A打印的字符。 可用的特殊字符: - ? ! / \{} = + < > . # $ % & ( ) @ * e £ ¥
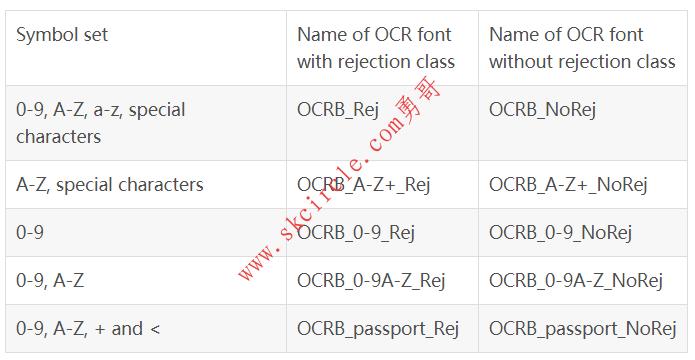
18.5.8 预训练字体 ’OCR-B’ ‘OCR-B’可用于读取以字体OCR-B打印的字符。 可用的特殊字符:- ? ! / \{} = + < > . # $ % & ( ) @ * e £ ¥
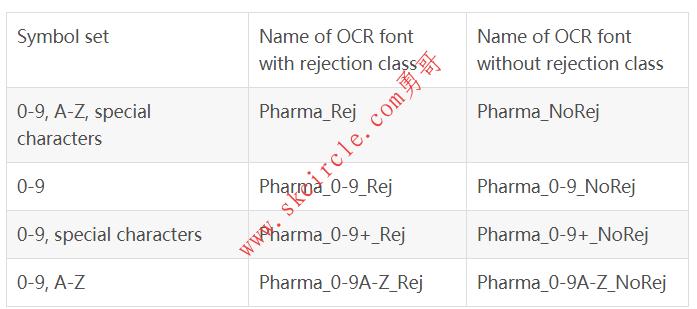
18.5.9 预训练字体 ’Pharma’ ‘Pharma’可用于读取以Arial,OCR-B等字体打印的字符,以及制药行业通常使用的其它字体(见图18.18)。此OCR字体不包含小写字符。 可用的特殊字符: - / . ( ) :
18.5.10 预训练字体 ’SEMI’ ‘SEMI’可用于读取以SEMI字体打印的字符,该字体由易于彼此区分的字符组成。它有一组有限的字符,可以在图18.19中看到。此OCR字体不包含小写字符。 可用的特殊字符: - .
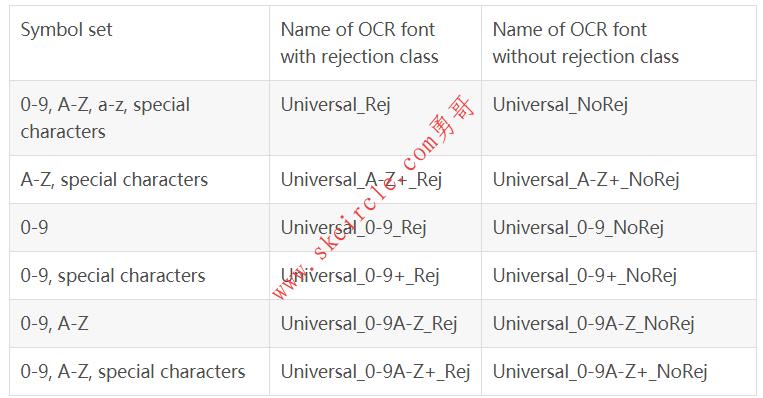
18.5.11 预训练字体 ’Universal’ ‘Universal’可用于读取各种不同的字符。这种基于CNN训练的字体的基于 ‘’Document’,“DotPrint”,“SEMI”和“Industrial’”等字符。 可用的特殊字符:- / = + : < > . # $ % & ( ) @ * e £ ¥
———————————————— 版权声明:本文为CSDN博主「Mr.Devin」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/IntegralforLove/article/details/83756956 本文出自勇哥的网站《少有人走的路》wwww.skcircle.com,转载请注明出处!讨论可扫码加群: 
|















【本文地址】