| 【神经网络第二次作业】多层感知机与卷积网络 | 您所在的位置:网站首页 › 卷积神经网络和多层感知机 › 【神经网络第二次作业】多层感知机与卷积网络 |
【神经网络第二次作业】多层感知机与卷积网络
|
(一)多层感知机用于 MNIST 手写数字数据集分类
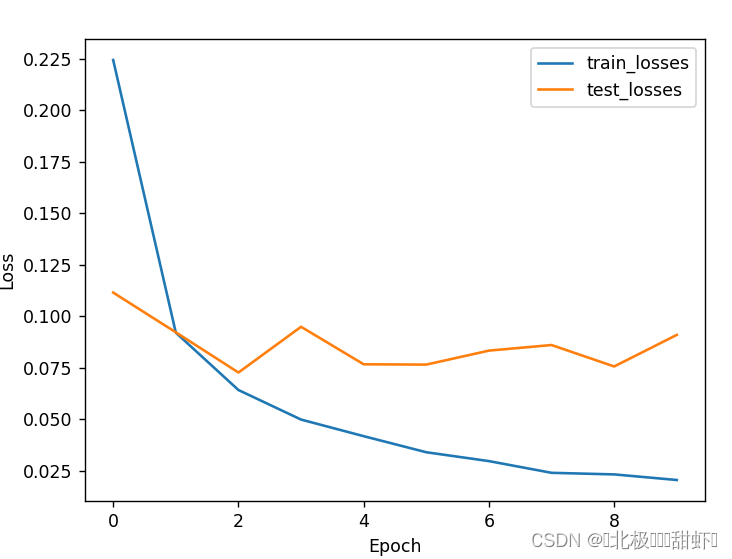
1、获取 MNIST 数据集,每张图片像素为28 × 28 2、模型架构为包含两个隐含层的多层感知机模型 输入层维度:28 × 28 = 784 第一层隐含单元数:256 第二层隐含单元数:256 输出层维度:10(MNIST 数据集类别数,分别为 0 到 9) 3、画出训练和测试过程的准确率随迭代次数变化图,画出训练和测试过程的损失随迭代次数变化图。(ᨀ交最终分类精度、分类损失以及两张变化图) # 构建多层感知机模型 class MLP(nn.Module): def __init__(self): super(MLP, self).__init__() self.fc1 = nn.Linear(784, 256) self.fc2 = nn.Linear(256, 256) self.fc3 = nn.Linear(256, 10) self.relu = nn.ReLU() def forward(self, x): x = x.view(-1, 784) x = self.relu(self.fc1(x)) x = self.relu(self.fc2(x)) x = self.fc3(x) return xPyTorch的nn.Linear()是用于设置网络中的全连接层的,需要注意在二维图像处理的任务中,全连接层的输入与输出一般都设置为二维张量,形状通常为[batch_size, size],不同于卷积层要求输入输出是四维张量。其用法与形参说明如下v loss.item()是从一个只包含一个元素的tensor中提取出标量值。这通常是网络的损失值。 inputs.size(0)返回输入数据的批量大小。 这行代码将每个样本的损失累加到running_loss中。 _, preds = torch.max(outputs, 1)torch.max(outputs, 1)返回每行最大值的索引。在分类任务中,outputs通常是网络的输出,代表每个类别的概率或分数。这行代码获取概率最高的类别作为预测结果。 preds保存了这些预测结果。 running_corrects += torch.sum(preds == labels.data)preds == labels.data返回一个布尔tensor,表示预测是否正确。 torch.sum()计算布尔tensor中True的数量,即预测正确的样本数量。 将这个数量累加到running_corrects中,以跟踪到目前为止预测正确的总数。 train_loss = running_loss / len(train_loader.dataset)计算平均损失值。这是通过将累积的损失除以训练集的总样本数量来完成的。 train_accuracy = running_corrects / len(train_loader.dataset)计算当前的训练准确度。这是通过将累积的预测正确的样本数量除以训练集的总样本数量来完成的。 train_losses.append(train_loss)将当前的训练损失添加到train_losses列表中,以便之后可视化或进一步分析。 train_accuracies.append(train_accuracy)将当前的训练准确度添加到train_accuracies列表中,以便之后可视化或进一步分析。 运行结果:Epoch 1/10 - Loss: 0.2245 - Accuracy: 0.9316 Epoch 1/10 - Loss: 0.1115 - Accuracy: 0.9652 Epoch 2/10 - Loss: 0.0920 - Accuracy: 0.9718 Epoch 2/10 - Loss: 0.0922 - Accuracy: 0.9699 Epoch 3/10 - Loss: 0.0642 - Accuracy: 0.9791 Epoch 3/10 - Loss: 0.0727 - Accuracy: 0.9770 Epoch 4/10 - Loss: 0.0498 - Accuracy: 0.9837 Epoch 4/10 - Loss: 0.0949 - Accuracy: 0.9700 Epoch 5/10 - Loss: 0.0417 - Accuracy: 0.9861 Epoch 5/10 - Loss: 0.0767 - Accuracy: 0.9774 Epoch 6/10 - Loss: 0.0339 - Accuracy: 0.9892 Epoch 6/10 - Loss: 0.0765 - Accuracy: 0.9790 Epoch 7/10 - Loss: 0.0296 - Accuracy: 0.9905 Epoch 7/10 - Loss: 0.0833 - Accuracy: 0.9785 Epoch 8/10 - Loss: 0.0240 - Accuracy: 0.9922 Epoch 8/10 - Loss: 0.0860 - Accuracy: 0.9787poch 9/10 - Loss: 0.0232 - Accuracy: 0.9921 Epoch 9/10 - Loss: 0.0756 - Accuracy: 0.9806 Epoch 10/10 - Loss: 0.0205 - Accuracy: 0.9935 Epoch 10/10 - Loss: 0.0910 - Accuracy: 0.9797 准确率从0.93–0.99,损失值从0.21–0.02
面要求ᨀ交的结果) 1、获取 MNIST 数据集,每张图片像素为28 × 28 2、模型架构: 输入层维度:28 × 28 (卷积层和池化层的 padding 都是用‘SAME’) 卷积层 1:卷积核大小为5 × 5,卷积核个数为 32(输出维度为28 × 28 × 32) 池化层 1:使用最大池化,核大小的2 × 2,stride 为 2(输出维度为14 × 14 × 32) 卷积层 2:卷积核大小为5 × 5,卷积核个数为 64(输出维度为14 × 14 × 64) 池化层 2:使用最大池化,核大小的2 × 2,stride 为 2(输出维度为7 × 7 × 64) (将池化层 2 的输出展平作为全连接层的输入,输入维度为7 × 7 × 64 = 3136) 全连接层:隐含单元数为 1024 Dropout 层:Dropout 率为 0.25 输出层维度:10(MNIST 数据集类别数,分别为 0 到 9) 3、画出训练和测试过程的准确率随迭代次数变化图,画出训练和测试过程的损失随迭代次数变化图。 模型: # 构建卷积神经网络模型 class ConvNet(nn.Module): def __init__(self): super(ConvNet, self).__init__() self.conv1 = nn.Conv2d(1, 32, 5,padding='same') self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(32, 64, 5,padding='same') self.fc1 = nn.Linear(7 * 7 * 64, 1024) self.dropout = nn.Dropout(0.25) self.fc2 = nn.Linear(1024, 10) def forward(self, x): x =F.relu(self.conv1(x)) x=self.pool(x) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 7 * 7 * 64) x = F.relu(self.fc1(x)) x = self.dropout(x) x = self.fc2(x) return x输入层维度要求:28 × 28。这个不要用管,设置网络不需要用到它。 (卷积层和池化层的 padding 都是用‘SAME’) 卷积层 1:卷积核大小为5 × 5,卷积核个数为 32(输出维度为28 × 28 × 32)。卷积核数= = 输出通道数 = =滤波器数 池化层 1:使用最大池化,核大小的2 × 2,stride 为 2(输出维度为14 × 14 × 32) 卷积层 2:卷积核大小为5 × 5,卷积核个数为 64(输出维度为14 × 14 × 64) 池化层 2:使用最大池化,核大小的2 × 2,stride 为 2(输出维度为7 × 7 × 64) (将池化层 2 的输出展平作为全连接层的输入,输入维度为7 × 7 × 64 = 3136) 上面都是根据参数传入值就好,注意输入通道是上次的输出通道 全连接层:隐含单元数为 1024 (nn.linear Dropout 层:Dropout 率为 0.25 输出层维度:10(MNIST 数据集类别数,分别为 0 到 9) 上conv2d的参数表!(这周为了比赛看了无数遍的表
sigmoid(x): 这是一个sigmoid激活函数,它将输入值转换到0到1之间。sigmoid函数常用于神经网络中,特别是在二元分类问题中。 公式为:σ(x)=11+e−xσ(x) = \frac{1}{1 + e^{-x}}σ(x)=1+e−x1 sigmoid_derivative(x): 这是sigmoid函数的导数。在神经网络的反向传播中,我们需要知道激活函数的导数来更新权重。 公式为:σ′(x)=σ(x)⋅(1−σ(x))σ’(x) = σ(x) · (1 - σ(x))σ′(x)=σ(x)⋅(1−σ(x)) 注意: 这里的sigmoid_derivative函数直接使用了输入值x进行计算,但实际上我们应该先使用sigmoid(x)得到输出值,再基于这个输出值计算导数。 初始化参数:这些参数是用于初始化神经网络的权重和偏置的。 input_size: 输入层的大小,这里是2。 hidden_size: 隐藏层的大小,这里也是2。 output_size: 输出层的大小,这里是1。对于二元分类问题,输出层通常只有一个节点。 hidden_weights: 隐藏层的权重矩阵。大小是(input_size, hidden_size),这意味着每个隐藏节点都有input_size个权重与输入节点连接。 hidden_bias: 隐藏层的偏置向量。大小为(1, hidden_size),这意味着每个隐藏节点都有一个偏置值。 output_weights: 输出层的权重矩阵。大小是(hidden_size, output_size),这意味着每个输出节点都有hidden_size个权重与隐藏节点连接。 output_bias: 输出层的偏置向量。大小为(1, output_size),这意味着每个输出节点都有一个偏置值。 训练模型 # 训练数据 training_data = np.array([[0, 0], [0, 1], [1, 0], [1, 1]]) target_output = np.array([[0], [1], [1], [0]]) # 训练模型 for epoch in range(10000): # 前向传播 hidden_layer_input = np.dot(training_data, hidden_weights) + hidden_bias #按照矩阵乘法计算 hidden_layer_output = sigmoid(hidden_layer_input) output_layer_input = np.dot(hidden_layer_output, output_weights) + output_bias predicted_output = sigmoid(output_layer_input) # 计算误差 error = target_output - predicted_output mse = np.mean(error ** 2) if epoch % 1000 == 0: print('Epoch:', epoch, 'MSE:', mse) # 反向传播 output_delta = error * sigmoid_derivative(predicted_output) hidden_delta = np.dot(output_delta, output_weights.T) * sigmoid_derivative(hidden_layer_output) # 更新权重和偏置 output_weights += hidden_layer_output.T.dot(output_delta) * learning_rate output_bias += np.sum(output_delta, axis=0, keepdims=True) * learning_rate hidden_weights += training_data.T.dot(hidden_delta) * learning_rate hidden_bias += np.sum(hidden_delta, axis=0, keepdims=True) * learning_rate 测试模型 def convert_output_to_binary(output): return (output >= 0.5).astype(int)s # 测试模型并输出结果 def test_model(): test_input = np.array([[0, 0], [0, 1], [1, 0], [1, 1]]) # 这里可以替换为你想要测试的输入数据 hidden_layer_input = np.dot(test_input, hidden_weights) + hidden_bias hidden_layer_output = sigmoid(hidden_layer_input) output_layer_input = np.dot(hidden_layer_output, output_weights) + output_bias predicted_output = sigmoid(output_layer_input) print("Model output:") print(predicted_output) print("after convertion:") print(convert_output_to_binary(predicted_output)) test_model() 输出结果Epoch: 0 MSE: 0.25815987867523305 Epoch: 1000 MSE: 0.24916303532983097 Epoch: 2000 MSE: 0.24293440079638062 Epoch: 3000 MSE: 0.20745956985519898 Epoch: 4000 MSE: 0.16903234519165228 Epoch: 5000 MSE: 0.13708747947090372 Epoch: 6000 MSE: 0.03481954589155661 Epoch: 7000 MSE: 0.013160781669528823 Epoch: 8000 MSE: 0.00751474020913937 Epoch: 9000 MSE: 0.005132114103563797 Model output: [[0.0635107 ] [0.93999345] [0.94079449] [0.06538105]] after convertion:s [[0] [1] [1] [0]] |
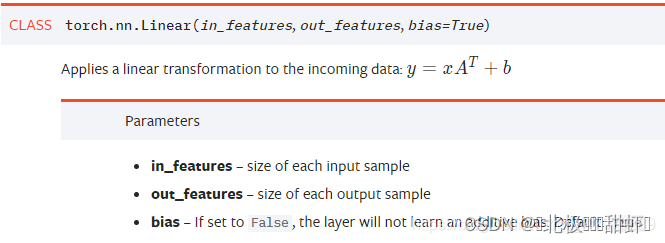 in_features指的是输入的二维张量的大小,即输入的[batch_size, size]中的size。 out_features指的是输出的二维张量的大小,即输出的二维张量的形状为[batch_size,output_size],当然,它也代表了该全连接层的神经元个数。 从输入输出的张量的shape角度来理解,相当于一个输入为[batch_size, in_features]的张量变换成了[batch_size, out_features]的输出张量。 ———————————————— 版权声明:本文为CSDN博主「风雪夜归人o」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/qq_42079689/article/details/102873766 (相当于是温故了,上次作业已经做过它的解析了。值得一说的是:(平时说的)隐层单元数==(pytorch)out_features输出通道数==(tensorflow)过滤器个数fillters)
in_features指的是输入的二维张量的大小,即输入的[batch_size, size]中的size。 out_features指的是输出的二维张量的大小,即输出的二维张量的形状为[batch_size,output_size],当然,它也代表了该全连接层的神经元个数。 从输入输出的张量的shape角度来理解,相当于一个输入为[batch_size, in_features]的张量变换成了[batch_size, out_features]的输出张量。 ———————————————— 版权声明:本文为CSDN博主「风雪夜归人o」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/qq_42079689/article/details/102873766 (相当于是温故了,上次作业已经做过它的解析了。值得一说的是:(平时说的)隐层单元数==(pytorch)out_features输出通道数==(tensorflow)过滤器个数fillters)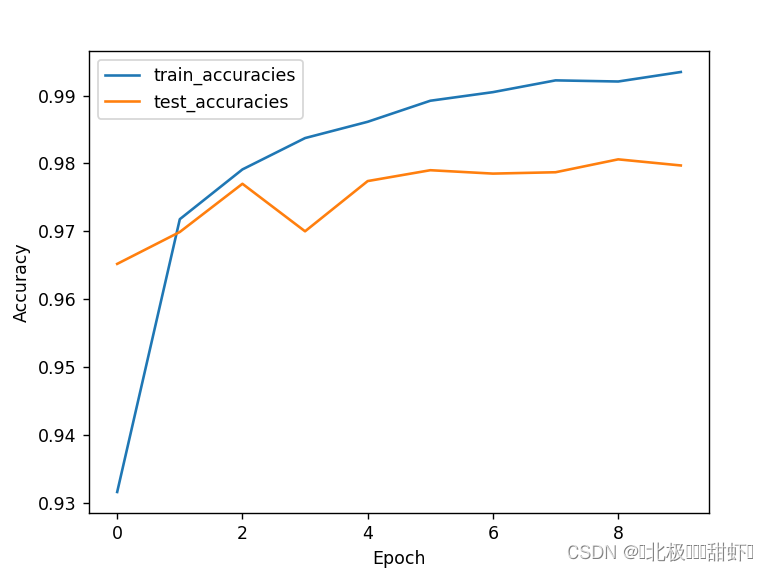
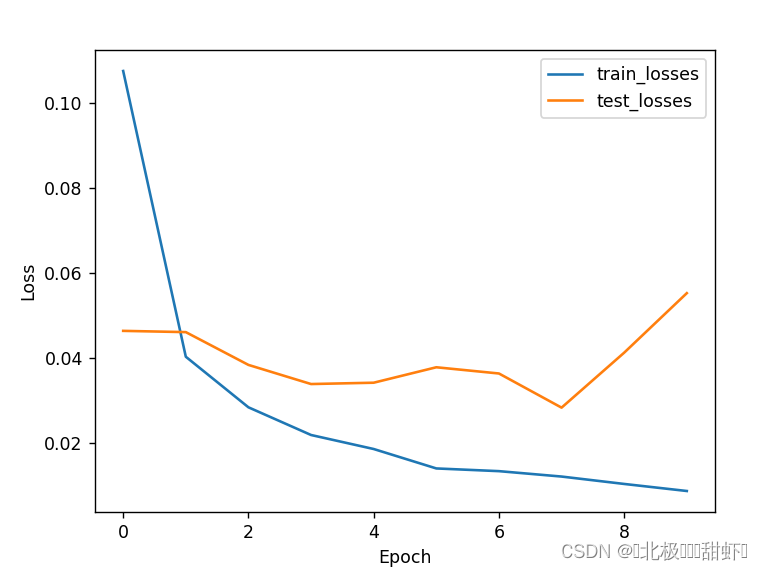
 Epoch 1/10 - Loss: 0.1075 - Accuracy: 0.9658 Epoch 1/10 - Loss: 0.0464 - Accuracy: 0.9857 Epoch 2/10 - Loss: 0.0403 - Accuracy: 0.9874 Epoch 2/10 - Loss: 0.0461 - Accuracy: 0.9858 Epoch 3/10 - Loss: 0.0284 - Accuracy: 0.9908 Epoch 3/10 - Loss: 0.0384 - Accuracy: 0.9883 Epoch 4/10 - Loss: 0.0219 - Accuracy: 0.9932 Epoch 4/10 - Loss: 0.0339 - Accuracy: 0.9910 Epoch 5/10 - Loss: 0.0186 - Accuracy: 0.9940 Epoch 5/10 - Loss: 0.0342 - Accuracy: 0.9903 Epoch 6/10 - Loss: 0.0140 - Accuracy: 0.9956 Epoch 6/10 - Loss: 0.0378 - Accuracy: 0.9907 Epoch 7/10 - Loss: 0.0134 - Accuracy: 0.9956 Epoch 7/10 - Loss: 0.0364 - Accuracy: 0.9907 Epoch 8/10 - Loss: 0.0121 - Accuracy: 0.9961 Epoch 8/10 - Loss: 0.0283 - Accuracy: 0.9920 Epoch 9/10 - Loss: 0.0104 - Accuracy: 0.9967 Epoch 9/10 - Loss: 0.0413 - Accuracy: 0.9890 Epoch 10/10 - Loss: 0.0087 - Accuracy: 0.9973 Epoch 10/10 - Loss: 0.0553 - Accuracy: 0.9874
Epoch 1/10 - Loss: 0.1075 - Accuracy: 0.9658 Epoch 1/10 - Loss: 0.0464 - Accuracy: 0.9857 Epoch 2/10 - Loss: 0.0403 - Accuracy: 0.9874 Epoch 2/10 - Loss: 0.0461 - Accuracy: 0.9858 Epoch 3/10 - Loss: 0.0284 - Accuracy: 0.9908 Epoch 3/10 - Loss: 0.0384 - Accuracy: 0.9883 Epoch 4/10 - Loss: 0.0219 - Accuracy: 0.9932 Epoch 4/10 - Loss: 0.0339 - Accuracy: 0.9910 Epoch 5/10 - Loss: 0.0186 - Accuracy: 0.9940 Epoch 5/10 - Loss: 0.0342 - Accuracy: 0.9903 Epoch 6/10 - Loss: 0.0140 - Accuracy: 0.9956 Epoch 6/10 - Loss: 0.0378 - Accuracy: 0.9907 Epoch 7/10 - Loss: 0.0134 - Accuracy: 0.9956 Epoch 7/10 - Loss: 0.0364 - Accuracy: 0.9907 Epoch 8/10 - Loss: 0.0121 - Accuracy: 0.9961 Epoch 8/10 - Loss: 0.0283 - Accuracy: 0.9920 Epoch 9/10 - Loss: 0.0104 - Accuracy: 0.9967 Epoch 9/10 - Loss: 0.0413 - Accuracy: 0.9890 Epoch 10/10 - Loss: 0.0087 - Accuracy: 0.9973 Epoch 10/10 - Loss: 0.0553 - Accuracy: 0.9874 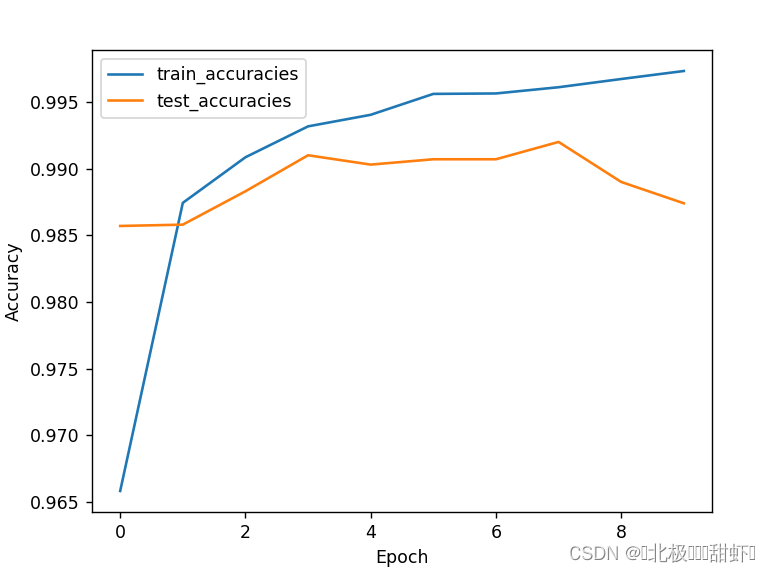
【本文地址】