| 利用python爬取京东华为旗舰店手机信息(价格、型号、颜色、链接等) | 您所在的位置:网站首页 › 华为手机如何查看型号名称和型号大小尺寸图片 › 利用python爬取京东华为旗舰店手机信息(价格、型号、颜色、链接等) |
利用python爬取京东华为旗舰店手机信息(价格、型号、颜色、链接等)
|
目 录
第一章、前言1.1、效果展示1.2、需要用到的库1.3、原理分析
第二章、代码分开讲解2.1、对象的定义及初始化2.1.1、第一至二行2.1.2、第三至四行2.1.3、第五至六行2.1.4、第七至八行2.1.5、最后两行
2.2、对象的方法1、2:获取所有手机详情页链接2.2.1、第一至三行2.2.2、第四至五行
2.3、对象的方法3、4:获取所有手机的各个颜色及内存组合的链接2.3.1、第一至五行2.3.2、第六至八行
2.4、对象的方法5、6:获取所有手机的型号、颜色、内存和链接2.4.1、第一至三行2.4.2、第四至九行
2.5、对象的方法7:获取手机价格2.6、对象的方法8:储存数据2.7、对象的实例化及调用
第三章、完整代码第四章、结语
第一章、前言
本文我们利用python,用面向对象的编程思维爬取京东华为旗舰店手机信息。 1.1、效果展示如下如最终我们将得到一个包含手机型号、颜色、内存、价格及购买链接等的excel表。 前两个不需要多说; 第三个是多线程的一个库; 第四个是标准库用来控制爬取频率和查看程序运行时间的; 最后一个是数据分析必备的库; 最后一行有注释,不多说。 1.3、原理分析这个大部分原理都很简单。 1、观察列表页的链接地址的数学规律,并运用列表生成式生成所有列表页链接。(对象初始化中的部分代码) 2、获取每个列表页的每个手机的链接(对应对象的方法1、2) 3、获取每一款手机的所有颜色和内存的所有组合的链接(对应对象的方法3、4) 这一块因为上一步中的链接的response是非标JSON格式,提取其中个别值有难度。我也是百度了几天才解决的,并且我也不懂其原理,只是把它当一个黑匣子用。具体请看第二章讲解 4、获取所有手机的颜色、型号、内存组合及链接`(对应对象的方法5、6) 这一块我采用的是分别获取其颜色型号内存组合及链接,并运用一个符号将其串成文本,后面要提取的时候直接使用一个split函数即可。 5、获取所有手机的价格(对应对象的方法7) 这一块是耽误我时间最久的,想过了运用selenium控制浏览器,执行购买操作,并获取其价格。但是一个手机通常有4种颜色3中内存组合,合起来就是12种,运用selenium的话大家可以想象这个效率之慢。 最后我在Network中找了很久终于找到一个可以利用的请求,恰好他的response又是标准的JSON格式,漂亮。 当然,这个请求的链接地址很不好组合,需要用到方法3、4中链接地址中的一些文本。 5、最后就是保存数据了,用了pandas中的一些方法(对应对象的方法8) 废话不多说,让我们开始吧 第二章、代码分开讲解 2.1、对象的定义及初始化 class Huawei_Mobile_Phone: #类的初始化,传入想要获取的初始页数和终止页数 def __init__(self,start_page,end_page): headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36', 'cookie': '这个参数和可以理解为一个登陆状态,下面有讲解'} self.sess=requests.session() self.sess.headers.update(headers) start_url = 'https://search.jd.com/Search?keyword=%E5%8D%8E%E4%B8%BA%E6%97%97%E8%88%B0%E5%BA%97&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&bs=1&suggest=1.his.0.0&ev=exbrand_%E5%8D%8E%E4%B8%BA%EF%BC%88HUAWEI%EF%BC%89%5E&page={}&s={}&click=0' self.url_list = [start_url.format(x,int(((x+1)/2)-1)*30+1)for x in range(1,98)] self.start_page = start_page self.end_page = end_page 2.1.1、第一至二行熟悉面相对象的编程的应该很好理解,就是定义一个对象,并进行初始化。其中 start_page和end_page就是在对象实例化时候传入你想要爬取的初始页数和结尾页数。 2.1.2、第三至四行第三行没啥说的就是模拟浏览器的登陆,入门级反反爬技巧。 第四行中的cookie你可以理解为储存着你的账户密码的一串文本,比如有时候登陆某账户,浏览器会弹出是否保存登陆状态,就与这玩意有关 如下图为cookie的获取。 有了 cookie 就等于有了登录账号的通行证。有些网站登录验证比较复杂,或者需要验证码时,我们可以在浏览器里手动登录,然后将登录后的 cookie 复制粘贴到爬虫代码里 headers 参数中的 cookie 字段中,这样就解决了我们的爬虫无法识别验证码的问题。 如下图为User-Agent的获取。 同样Name那一栏也可以随意选一个请求去查看。 这两行是利用request库中的session会话对象来保存登陆状态,其中第五行可以理解为实例化一个session对象。第六行就是将上面两行找到的参数传递进sess。 2.1.4、第七至八行这两行就是找小学的数学规律的题。获取列表页的每页链接。 如下图 page很明显就是页数,而s就是本页的开始的第一个手机的一个编号。 这两行不用多讲,就是将对象实例化时候传入的初始页数和最终页数付给对象的属性,待后面的方法调用。 2.2、对象的方法1、2:获取所有手机详情页链接 #获取每一款手机的详情页链接,过程函数,等待进程调用 def Tmp_get_detail_url(self,url1): res=self.sess.get(url1) res.encoding='utf-8' soup=BeautifulSoup(res.text,'html.parser').select('li.gl-item>div.gl-i-wrap>div.p-img>a') result1=[('https:'+tmp['href']).replace('https:https:','https:') for tmp in soup] return result1 #利用多线程获取每一款手机的详情页链接 def Main_get_detail_url(self): fs = [] for url in self.url_list[self.start_page-1:self.end_page]: # 提交任务到线程池 f = executor.submit(self.Tmp_get_detail_url, url) fs.append(f) # 等待这些任务全部完成 futures.wait(fs) result2=[] for f1 in fs:result2+=f1.result() return result2看过我前一篇文章的都应该很熟悉我的这种结构了吧!先定义一个过程函数,然后运用多线程调用这个过程函数获取一些数据。 第二个Main函数不多说,不懂的看这篇文章: python利用多线程批量下载高清美女图片 当然也要注意那个切片操作,上面一节传入的开始页数和结尾页数就是用到这的。 这里我们只分析这个过程函数。 2.2.1、第一至三行这都不用多说,定义函数并传入url1参数,调用get发起请求,更改编码格式为utf-8,不然得到的数据会各种乱码。 2.2.2、第四至五行解释代码之前先来看下网站的源代码。首先要明白这一块代码是为了获取某一页列表页的所有商品的详情页,也就是获取某列表页中所有超链接(当然得排除一些干扰项) 从这个方法开始往下,一旦启用多线程就会缺失数据,有的甚至用传统的循环,并且加上sleep控制爬取频率也会缺失数据。没法子,谁叫我学艺不精还要选择京东为目标呢。 话不读说,同样的让我们先看下源代码之内的。 python3处理不标准json数据 如下图的位置
第一行控制爬取频率 其中第二三行,和上面一节第一二行一样。 第四行因为我们需要的字典在script标签中,我们将它提取出来再说。 后面的replace是替换个别无用字符,不然,即使用上面那个公式,也会报错。 第五行前面replace前面的应该是废话,主要上一个版本是把response当一个文本,然后提取他的多少行来得到目标数据而遗留下来的。直接soup.replace(。。。)就行,你们可以试试。 后面的replace是替换前面的无用的字符串。如下 第六七行不做解释。咱也不懂,只把他当一个库来用喽。 其中第七行的venderId参数,是后面获取价格时候要用的。 第八行是一个列表推导式,得到所有组合链接加上venderId参数。类似如下的链接。 https://item.jd.com/100003717481.html__000004259 到时候要用前面的只需要split(__)[0] 用后面的就是 1 就行了。 其实你们会问可以返回两个参数呀?但是观察后发现 ,一个手机只有一个venderId,却会有8个乃至10数个版本和颜色的组合。所有就只有这个办法。 后面那个Main开头的函数,不用多解释。 当然 ,其中url_list=detail_url 中的detail_url是定义对象外调用方法2获取的手机的详情页链接数组。 注意这里我们不采用以前那种在定义对象内部传递参数的方法,是因为有个别方法需要调用两遍,比较费时间,所以就在定义对象外传递参数。这种看着比较啰嗦,但是架不住效率高啊。你们可以试试,将其换成内部传递参数,这样,可能原本200秒就好了。你这样一弄 ,省了4行代码但是却可能致使程序多运行30秒以上(没试过,估计时间) 2.4、对象的方法5、6:获取所有手机的型号、颜色、内存和链接 #获取某手机的所有型号及颜色,过程函数 def Tmp_get_type(self,url3): res4=self.sess.get(url3).text soup=BeautifulSoup(res4,'html.parser') try: title=soup.select_one('div.item.ellipsis').text.split('【')[0] color=soup.select('div.item.selected')[0]['data-value'] type1=soup.select('div.item.selected')[1]['data-value'] res=title+'/'+color+'/'+type1+'/'+url3 except:res='' return res #获取全部手机的型号及颜色,此处一旦调用多线程,将损失大量数据(即使不调用,也要损失至少5%的数据) def Main_get_type(self): result4 ='' for url in item_url: result4 += '_'+self.Tmp_get_type(url.split('__')[0]) return result4.split('_')[1:]同样的这一块代码的后面的一个Main函数和上面一节的差不多。故这里也只讲过程函数。 2.4.1、第一至三行这三行和前面一节的如出一折,不在累述。 2.4.2、第四至九行因为反扒机制,就算不动用多线程,中间try几行代码有时候就出错,如果出错,我们返回空值进行占位。 这里容我废话一下,因为价格的特殊,我们是先爬取其他信息,然后在爬取价格,这中间因为前面说的反扒机制,我们不知道那块会出错,有可能,颜色内存这块是前面出错,价格是后面出错,如果不返回空值占位的话,你们可以想象,中间有一块就错位了。(形如,涂答题卡,涂完了发现,诶!怎么还空一格。) 所以我们就try一下,如果出错就返回空值。 title那一行就是获取手机型号。 这个不用多啰嗦了,静态爬取,简单的很,只是,有的时候回获取到这种文本 华为nova 5 Pro【华为nova 5 Pro】 这时候就需要吧【以后的东西去掉了。当然,这个不去掉也没有多大影响。 color那一行和tyoe1那一行 这两行结构一样。这一块稍微讲下。 如下图: 这一块我们先分析怎么得到这个请求地址,然后在去看怎么组合他。 首先打开一个手机的详情页网址,并看下价格,按F12或者右键检查,打开Network我们刷新下,如下图操作,我们就可以删选出包含2499这个价格的所有请求了。 这个不用多解释,直接逐行解析代码。 ==tmp_data_list ==这一行是将我们对象的方法六得到的形如[a1/b1/c3/d1,a2/b2/c2/d2,a3,b3,c3,d3] 这样的一维列表,变成 [[a1,a2,a3,a4],[a2,b2,c2,d2],[a3,b3,c3,d3]]这样的二位列表。 tmp_data=pd这一行是将上面的二位列表,转化为DataFrame格式。 tmp_data.insert(3,‘价格’,price) 这行代码的意思是将价格插入到倒数第二行,应为倒数第一行是链接,一般情况链接比较长,价格放链接前面,看着舒服些。其中price就是我们在实例化后调用方法7得到的那个结果。 tmp_data.dropna(axis=0, how=‘any’, inplace=True) 这个跟后面的哪一样都是去除有空数据的列。 剩下四行就是基本的保存到excel的操作,没有什么可说的。 2.7、对象的实例化及调用 t0=time() huawei=Huawei_Mobile_Phone(1,1) detail_url=huawei.Main_get_detail_url() item_url=huawei.Main_get_item_url() type2=huawei.Main_get_type() price=huawei.Main_get_price() huawei.Main_save_data() t1=time() print('总共花了%0.5f秒'%((t1-t0)))这块没的可说的,就是对象的实例化,并逐个调用对象的方法。 这个可以和我上一篇文章 的参数传递方法做对比。 第三章、完整代码 import requests,json from bs4 import BeautifulSoup from concurrent import futures from time import sleep,time import pandas as pd #初始化一个线程池,最大线程为4 executor = futures.ThreadPoolExecutor(max_workers=4) class Huawei_Mobile_Phone: #类的初始化,传入想要获取的页面,若只输入一个数,就从第一页开始获取,到你传入的这个数为止 def __init__(self,start_page,end_page): headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36', 'cookie': **这一块前面第二章有讲解**'} self.sess=requests.session() self.sess.headers.update(headers) start_url = 'https://search.jd.com/Search?keyword=%E5%8D%8E%E4%B8%BA%E6%97%97%E8%88%B0%E5%BA%97&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&bs=1&suggest=1.his.0.0&ev=exbrand_%E5%8D%8E%E4%B8%BA%EF%BC%88HUAWEI%EF%BC%89%5E&page={}&s={}&click=0' self.url_list = [start_url.format(x,int(((x+1)/2)-1)*30+1)for x in range(1,98)] self.start_page = start_page self.end_page = end_page #获取每一款手机的详情页链接,过程函数,等待进程调用 def Tmp_get_detail_url(self,url1): res=self.sess.get(url1) res.encoding='utf-8' soup=BeautifulSoup(res.text,'html.parser').select('li.gl-item>div.gl-i-wrap>div.p-img>a') result1=[('https:'+tmp['href']).replace('https:https:','https:') for tmp in soup] return result1 #利用多线程获取每一款手机的详情页链接 def Main_get_detail_url(self): fs = [] for url in self.url_list[self.start_page-1:self.end_page]: # 提交任务到线程池 f = executor.submit(self.Tmp_get_detail_url, url) fs.append(f) # 等待这些任务全部完成 futures.wait(fs) result2=[] for f1 in fs:result2+=f1.result() return result2 #获取一款手机的各个版本及颜色的每一种组合的链接,过程函数 def Tmp_get_item_url(self,url2): res=self.sess.get(url2).text soup = BeautifulSoup(res, 'html.parser').select_one('script').text.replace('/**/', '') soup = ('\n'.join(soup.split('\n')).replace('var pageConfig =', '').split('try')[0]).strip()[:-1] colorSize = eval(soup, type('Dummy', (dict,), dict(__getitem__=lambda s, n: n))())['product']['colorSize'] venderId = eval(soup, type('Dummy', (dict,), dict(__getitem__=lambda s, n: n))())['product']['venderId'] result3=[('https://item.jd.com/%s.html__%s' %( tmp['skuId'],venderId )) for tmp in colorSize] return result3 #获取全部手机的各个版本的链接,这块一旦启动多线程,数据就会缺失 def Main_get_item_url(self): sleep(0.2) url_list=detail_url result4 = [] for url in url_list : result4+=self.Tmp_get_item_url(url) return result4 #获取某手机的所有型号及颜色,过程函数 def Tmp_get_type(self,url3): res4=self.sess.get(url3).text soup=BeautifulSoup(res4,'html.parser') try: title=soup.select_one('div.item.ellipsis').text.split('【')[0] color=soup.select('div.item.selected')[0]['data-value'] type1=soup.select('div.item.selected')[1]['data-value'] res=title+'/'+color+'/'+type1+'/'+url3 except:res='' return res #获取全部手机的型号及颜色,此处一旦调用多线程,将损失大量数据(即使不调用,也要损失至少5%的数据) def Main_get_type(self): result4 ='' for url in item_url: result4 += '_'+self.Tmp_get_type(url.split('__')[0]) return result4.split('_')[1:] #获取手机价格 def Main_get_price(self): start_url1='https://c0.3.cn/stock?skuId=first_one&area=21_1827_1828_40900&venderId=second_one&buyNum=1&choseSuitSkuIds=&cat=9987,653,655&extraParam={%22originid%22:%221%22}&fqsp=0&pdpin=&pduid=1585611690213909967754&ch=1' data0=item_url data1=[tmp.replace('https://item.jd.com/','') for tmp in data0] price_url=[start_url1.replace('first_one', tmp.split('.html__')[0]).replace('second_one', tmp.split('.html__')[1])for tmp in data1] result5=[] for tmp in price_url: try: p1=self.sess.get(tmp).json()['stock']['jdPrice']['p'] except:p1='' result5.append(p1) return result5 #存储数据 def Main_save_data(self): tmp_data_list= [(type2[index].split('/',3)) for index in range(len(price))] tmp_data=pd.DataFrame(tmp_data_list,columns=['型号','颜色','内存组合','购买链接']) tmp_data.insert(3,'价格',price) tmp_data.dropna(axis=0, how='any', inplace=True) tmp_data[tmp_data['价格']!=''] writer = pd.ExcelWriter('A.xlsx') tmp_data.to_excel(writer, 'page1', float_format='%.5f',index=False) writer.save() writer.close() t0=time() huawei=Huawei_Mobile_Phone(1,1) detail_url=huawei.Main_get_detail_url() item_url=huawei.Main_get_item_url() type2=huawei.Main_get_type() price=huawei.Main_get_price() huawei.Main_save_data() t1=time() print('总共花了%0.5f秒'%((t1-t0))) 第四章、结语终于完成了这篇文章,前前后后包括想代码,写文章,差不多有20天。 当然也来总结几点要注意的。 由于学艺不精而目标又是京东,方法2后面的所有的不能并发,一旦并发就会导致数据缺失。(当然可能有其他并发方式吧)其中方法6不用并发也会导致数据缺失,我想的话应该是其过程函数也就是方法5没有用sleep控制爬取频率有关吧。你们可以试着sleep(0.2)什么的,看一下。方法3应该可以用正则表达式来获取那个字典,这样就不用我把于python相关的处理字符串的函数挨个来一遍了(苦笑)。价格能够获取,那么评论呢,我想评论的获取应该比价格要简单些吧。你可试试,用相似的方法获取评论,剔除无关词语,然后生成词云,看看用户对华为官方旗舰店的评价中出现最多的词语有哪些?当然有了这个数据,你也可以干些事情了,比如我们在excel中对名称筛选5G对价格升序,就能找到最便宜的5G手机了。如下图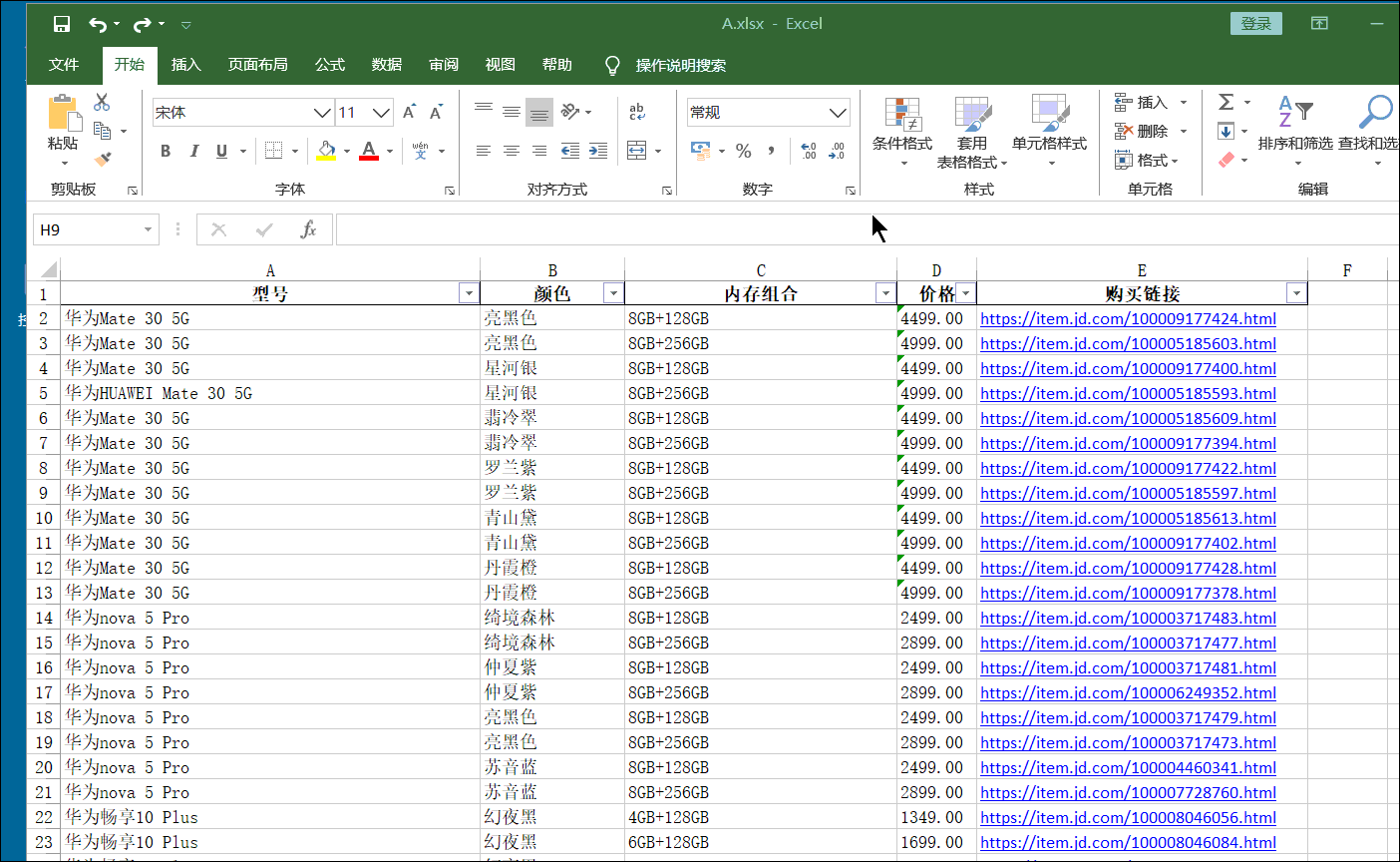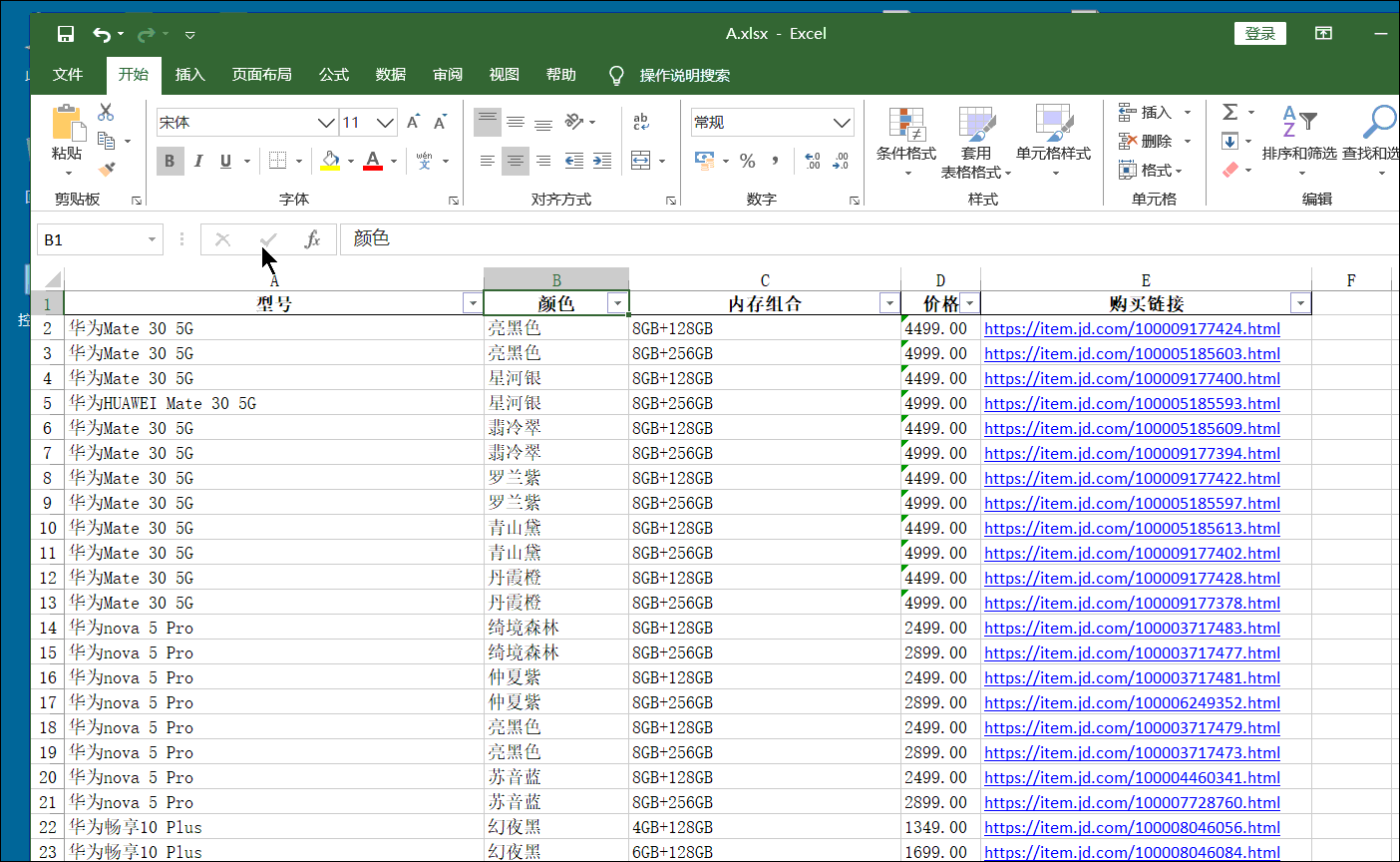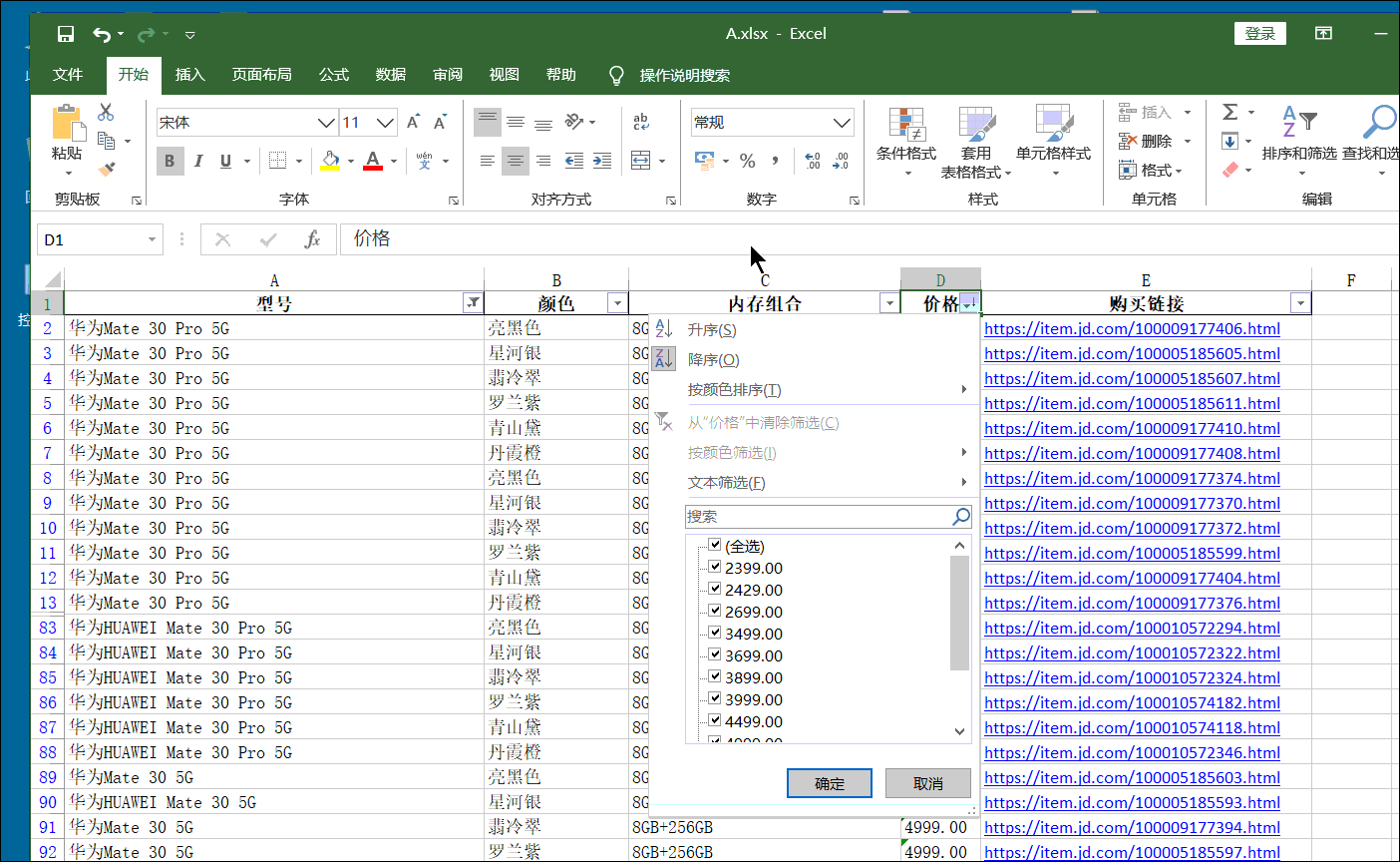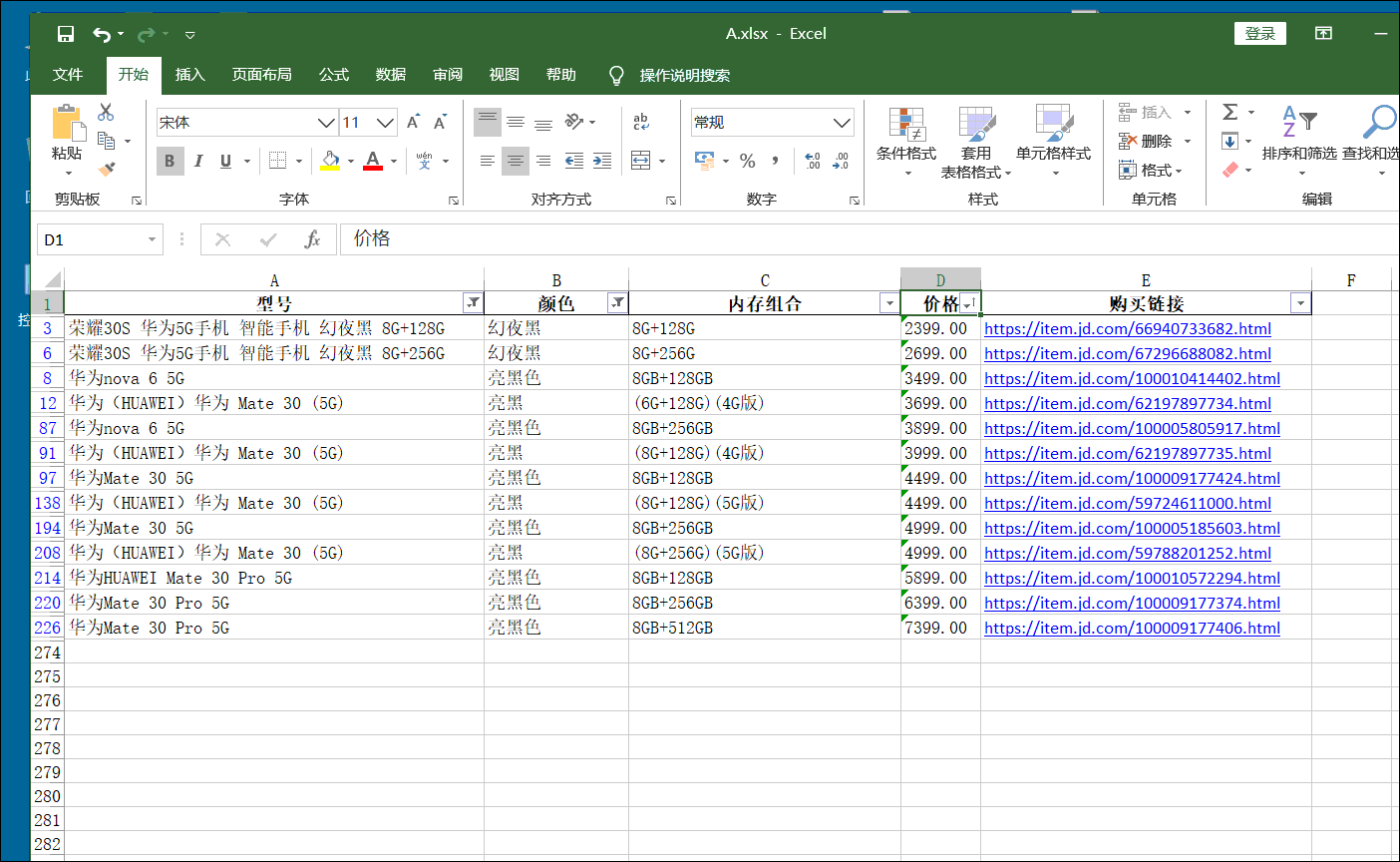 当然有了还有很多东西,不至于玩法等你探索。这个程序由于不能并发,效率非常低,爬一页300左右的商品信息就得200秒左右。你们可以试着改下,让其效率变高点。(据说京东每双11双12这样的活动都会临时性关闭反扒机制,不知真假)好了不啰嗦了,在啰嗦破2万字了。还是老习惯,若有任何问题欢迎私信评论加好友,谢谢。 当然有了还有很多东西,不至于玩法等你探索。这个程序由于不能并发,效率非常低,爬一页300左右的商品信息就得200秒左右。你们可以试着改下,让其效率变高点。(据说京东每双11双12这样的活动都会临时性关闭反扒机制,不知真假)好了不啰嗦了,在啰嗦破2万字了。还是老习惯,若有任何问题欢迎私信评论加好友,谢谢。
Title:the 8th blog By:P&p Time:2020-04-15 17:03 (学python的第75天) |

 其实在这里应该可以不必保存登陆状态,也就是不用传入cookie。用这个主要是考虑到,爬取有些网站的前面内容不需要登录,但是爬取后面的页数时候就需要登陆了。
其实在这里应该可以不必保存登陆状态,也就是不用传入cookie。用这个主要是考虑到,爬取有些网站的前面内容不需要登录,但是爬取后面的页数时候就需要登陆了。
 并且可以看到,page是1 3 5 7 这样的数列,并且每一页是60个商品。但是我们下面的页数却是1234连续数列。由此,我们可以猜想,其实每页显示的是‘’真实‘’的两页内容,‘’真实‘’的每页有30个商品。试了一下,果然可以,如下:
并且可以看到,page是1 3 5 7 这样的数列,并且每一页是60个商品。但是我们下面的页数却是1234连续数列。由此,我们可以猜想,其实每页显示的是‘’真实‘’的两页内容,‘’真实‘’的每页有30个商品。试了一下,果然可以,如下:  这样一解释那么第七行第八行的代码就不难理解了吧。当然因为链接过长,我们单独定义一个变量,将这两个参数用大括号代替,方便下一行直接用format进行格式化。 当然你们可能会问,链接过长为什么不用字典形式将参数传入进去,因为这样可以用很方便的运用列表推导式。并且可以不用请求就得到所有商品列表页链接。如果是字典传入参数需要用get。比较耗时间。
这样一解释那么第七行第八行的代码就不难理解了吧。当然因为链接过长,我们单独定义一个变量,将这两个参数用大括号代替,方便下一行直接用format进行格式化。 当然你们可能会问,链接过长为什么不用字典形式将参数传入进去,因为这样可以用很方便的运用列表推导式。并且可以不用请求就得到所有商品列表页链接。如果是字典传入参数需要用get。比较耗时间。 如上图可以看到 每一个li class=“gl-item” 的标签代表一个商品 用css表示就是 li.gl-item 接下来我们看 li.gl-item标签下的a在哪。
如上图可以看到 每一个li class=“gl-item” 的标签代表一个商品 用css表示就是 li.gl-item 接下来我们看 li.gl-item标签下的a在哪。  如下,一级一级分别是div class=“gl-i-wrap” div class=“p-img” a 用css表达就是就是div.gl-i-wrap>div.p-img>a 加上刚开始一级就是 li.gl-item>div.gl-i-wrap>div.p-img>a 这也就是第五行最后select的参数。 至于前面的Beautifulsoup这个就不用多说了,基础用法,用的默认的解析器。 第六行就是一个列表推导式,从上图大家也可以看出 a 标签中的href属性有的是网址的一部分,需要加上一点凑齐。至于后面的replace,因为有的上图中没有展示出来的网址是全的,加了之后就变成两个https需要替换。
如下,一级一级分别是div class=“gl-i-wrap” div class=“p-img” a 用css表达就是就是div.gl-i-wrap>div.p-img>a 加上刚开始一级就是 li.gl-item>div.gl-i-wrap>div.p-img>a 这也就是第五行最后select的参数。 至于前面的Beautifulsoup这个就不用多说了,基础用法,用的默认的解析器。 第六行就是一个列表推导式,从上图大家也可以看出 a 标签中的href属性有的是网址的一部分,需要加上一点凑齐。至于后面的replace,因为有的上图中没有展示出来的网址是全的,加了之后就变成两个https需要替换。 如上图我们可以看到,有四种颜色和两种版本的组合,也就是总共有4*2=8个网址需要爬取,如果用selenium控制浏览器每点击一次获取一个网址,让后储存,这样的效率想想就慢的恐怖。 还好功夫不负有心人,我在详情页的response中的某个地方得到了答案,如下图:
如上图我们可以看到,有四种颜色和两种版本的组合,也就是总共有4*2=8个网址需要爬取,如果用selenium控制浏览器每点击一次获取一个网址,让后储存,这样的效率想想就慢的恐怖。 还好功夫不负有心人,我在详情页的response中的某个地方得到了答案,如下图:  我们可以看到 左上角的数据和右下角的数据是不是基本一样的,有个别数字不一样就是因为颜色和版本的组合不一样呗。 但是正如上面显示的,他是非标JSON格式。不能直接.json转化为字典。后来准备将他当成text 然后提取多少行的数据,结果发现,有的不是在这一行,还有多个结果。便放弃了这种方法。最后几经百度才发现了一位大佬写的一个东西 ,不是很明白原理,文章链接在下面:
我们可以看到 左上角的数据和右下角的数据是不是基本一样的,有个别数字不一样就是因为颜色和版本的组合不一样呗。 但是正如上面显示的,他是非标JSON格式。不能直接.json转化为字典。后来准备将他当成text 然后提取多少行的数据,结果发现,有的不是在这一行,还有多个结果。便放弃了这种方法。最后几经百度才发现了一位大佬写的一个东西 ,不是很明白原理,文章链接在下面: 当然你们肯定还有更多方法,比如正则表达式,我还没系统学,应该会很简单。分析的差不多了,我们来逐行代码的分析。
当然你们肯定还有更多方法,比如正则表达式,我还没系统学,应该会很简单。分析的差不多了,我们来逐行代码的分析。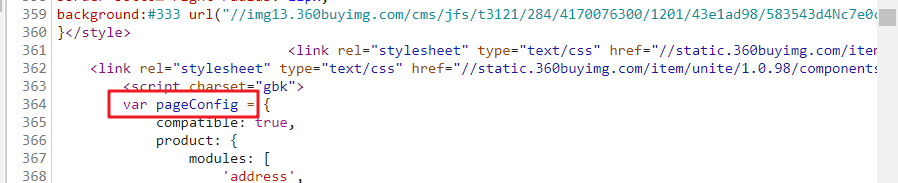 接着split(‘try’)[0]是因为在script标签中try前面是我们需要的字典。所以以try分割字符串并提取第一分。
接着split(‘try’)[0]是因为在script标签中try前面是我们需要的字典。所以以try分割字符串并提取第一分。  strip()不用多说,就是去除收尾的空格。 最后那个[:-1]是排除上图try前面那个分号的。
strip()不用多说,就是去除收尾的空格。 最后那个[:-1]是排除上图try前面那个分号的。 当我们选中 ==‘仲夏紫’==的时候, 其颜色标签为class=“item selected” 而其他颜色便签的为class=“item” 版本信息同样如此,那么我们就查找所有的div.item.selected 其中第一个的文本就是color,第二个的文本就是type1喽。 res那一行 这个就是把上面几行得到的数据组合为文本以 / 隔开来,方便后面调用,和上一节一样的,只是分割符号不同而已。
当我们选中 ==‘仲夏紫’==的时候, 其颜色标签为class=“item selected” 而其他颜色便签的为class=“item” 版本信息同样如此,那么我们就查找所有的div.item.selected 其中第一个的文本就是color,第二个的文本就是type1喽。 res那一行 这个就是把上面几行得到的数据组合为文本以 / 隔开来,方便后面调用,和上一节一样的,只是分割符号不同而已。 当然,大家看到,包含2499的请求,依然有那么10来个,但这个总比那些动辄30 40 的请求好点吧。接下来我们就来排除。 首先我们应该排除请求的链接本身中就包含2499的。 比如这个:
当然,大家看到,包含2499的请求,依然有那么10来个,但这个总比那些动辄30 40 的请求好点吧。接下来我们就来排除。 首先我们应该排除请求的链接本身中就包含2499的。 比如这个:  接着排除一下无意义的2499,或者容易错的。 比如下面这个:
接着排除一下无意义的2499,或者容易错的。 比如下面这个:  这里面一看就很多价格,有可能是历史价格。但是历史价格,我们不太清楚他改变了几次,这样,有可能这个商品的目前价格是在这一行的某个地方,下一个商品就在另外的地方了。 最终进过几轮删选我选定了一个网址,如下。
这里面一看就很多价格,有可能是历史价格。但是历史价格,我们不太清楚他改变了几次,这样,有可能这个商品的目前价格是在这一行的某个地方,下一个商品就在另外的地方了。 最终进过几轮删选我选定了一个网址,如下。  然后,我们浏览三个以上的商品的这个请求的到EXCEL利用分列将各个参数进行对比,如下图。
然后,我们浏览三个以上的商品的这个请求的到EXCEL利用分列将各个参数进行对比,如下图。  绿色部分就是完全一样的参数。而不一样的就两个,都是在方法4的结果中提取的 前面的是网址中的一串数字。后面的则是__后面的那一部分数字。 这样一来 start_url1及price_url这一行就很好解释了,就是把那两个未知的地方空出来,利用格式化填入。但是那样会出错,所以迫不得已就使用first_one 和second_one填之,然后用replace进行替换,这样,我们就得到了我们要的网址。 data0和data1这一行 data0就是赋值操作,将实例化后运行对象的方法4得到的结果赋值给data0 data1就是将方法4得到的网址加数据中网址的前半部分去掉。 比如我们方法4获取的形如下面样式的网址: https://item.jd.com/100003717481.html__000004259 我们只要中间的两串数字样字符串。 data1之后,我们就得到了形如下面这样的字符串 100003717481.html__000004259。 这样一来就好弄了,直接split 然后 将start_url1 中的first__one和second_one分别替换就可以了。 后面的循环就不用多说了,发起请求,并转化为字典,然后得到字典中的值。 至此手机的价格和颜色、版本、链接、型号就都得到了。下面一块就是储存了。
绿色部分就是完全一样的参数。而不一样的就两个,都是在方法4的结果中提取的 前面的是网址中的一串数字。后面的则是__后面的那一部分数字。 这样一来 start_url1及price_url这一行就很好解释了,就是把那两个未知的地方空出来,利用格式化填入。但是那样会出错,所以迫不得已就使用first_one 和second_one填之,然后用replace进行替换,这样,我们就得到了我们要的网址。 data0和data1这一行 data0就是赋值操作,将实例化后运行对象的方法4得到的结果赋值给data0 data1就是将方法4得到的网址加数据中网址的前半部分去掉。 比如我们方法4获取的形如下面样式的网址: https://item.jd.com/100003717481.html__000004259 我们只要中间的两串数字样字符串。 data1之后,我们就得到了形如下面这样的字符串 100003717481.html__000004259。 这样一来就好弄了,直接split 然后 将start_url1 中的first__one和second_one分别替换就可以了。 后面的循环就不用多说了,发起请求,并转化为字典,然后得到字典中的值。 至此手机的价格和颜色、版本、链接、型号就都得到了。下面一块就是储存了。【本文地址】