| 《利用python进行数据分析第二版》学习(二) | 您所在的位置:网站首页 › 利用Python进行数据分析第二版 › 《利用python进行数据分析第二版》学习(二) |
《利用python进行数据分析第二版》学习(二)
|
接此博客继续《利用python进行数据分析第二版》学习(一) 不重要的内容直接略过了 2.2.1.8鸭子类型 验证一个对象如果实现了迭代器协议,那它就一定是迭代的。对于很多对象来说它包含了一个__iter__魔术方法,但使用iter函数是另一个更好的检测方法: 在相同路径下的其他文件访问some_module.py里的变量与函数,可以进行如下操作: from some_module.py import f,g,PI result=g(5,PI)2.3.1.10二元运算符和比较运算 要注意is和==是不同的,如下:
2.3.3控制流 2.3.3.1 if、elif和else 注意or的使用会导致“短路”的发生,只进行ad。 a = 5 ; b = 7 c = 8 ; d = 4 if ad : print("谢谢你的阅读!") 谢谢你的阅读!2.3.3.3 while循环 3.1数据结构和序列 3.1.1元组 3.1.1.1元组拆包 也就是在这里增加了我对format的认识: 3.1.2 列表 3.1.3.1enumerate 将索引值映射到索引位置上: 今天先写到66页。 《利用python进行数据分析第二版》学习(三) |
 2.3.1.9导入 对于函数:
2.3.1.9导入 对于函数: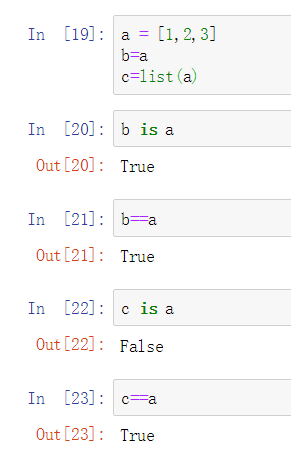 我的理解是c is a,代表b与a是地址相同的,a和b只是两个指针 c==a,代表的是c与a在数值上相同。验证如下:
我的理解是c is a,代表b与a是地址相同的,a和b只是两个指针 c==a,代表的是c与a在数值上相同。验证如下: 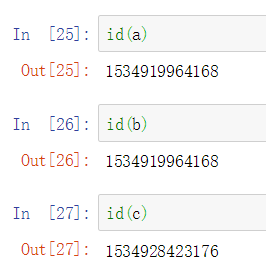 2.3.1.11可变对象和不可变对象 列表、字典、Numpy数组都是可变对象。 字符串、元组为不可变对象。 ** 2.3.2标量类型 ** 2.3.2.2字符串 字符串格式化方式的一种:
2.3.1.11可变对象和不可变对象 列表、字典、Numpy数组都是可变对象。 字符串、元组为不可变对象。 ** 2.3.2标量类型 ** 2.3.2.2字符串 字符串格式化方式的一种: 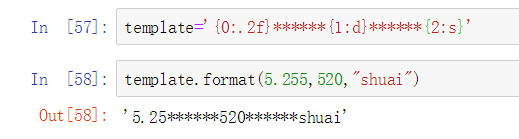 2.3.2.3字节与Uicode 转码和解码过程:
2.3.2.3字节与Uicode 转码和解码过程:  2.3.2.7日期和时间 产生时间及加减法:
2.3.2.7日期和时间 产生时间及加减法:  看来我已经出生7600天了,哈哈。
看来我已经出生7600天了,哈哈。 2.3.3.6三元表达式 语法如下图所示:
2.3.3.6三元表达式 语法如下图所示:  在if-else代码块中,是按顺序逐个执行的。因此,三元表达式的“if”侧和“else”侧可能会包含计算消耗,但是只有真分支才会被采用。当判断条件和真假表达式复杂时会牺牲可读性。
在if-else代码块中,是按顺序逐个执行的。因此,三元表达式的“if”侧和“else”侧可能会包含计算消耗,但是只有真分支才会被采用。当判断条件和真假表达式复杂时会牺牲可读性。 3.1.1.2 元组方法
3.1.1.2 元组方法 3.1.3.3 zip zip将列表、元组或其他序列的元素配对,新建一个元祖构成的列表:
3.1.3.3 zip zip将列表、元组或其他序列的元素配对,新建一个元祖构成的列表: 
 zip可以处理任意长度的序列,它生成列表长度由最短的序列决定:
zip可以处理任意长度的序列,它生成列表长度由最短的序列决定:  zip函数有一种机智的方式去“拆分”序列,这种方式的另一种思路就是将行的列表转换为列的列表。语法看上去略显魔幻:
zip函数有一种机智的方式去“拆分”序列,这种方式的另一种思路就是将行的列表转换为列的列表。语法看上去略显魔幻: 
【本文地址】