| 深度学习语义分割篇 | 您所在的位置:网站首页 › 分割图是什么意思 › 深度学习语义分割篇 |
深度学习语义分割篇
|
🍊作者简介:秃头小苏,致力于用最通俗的语言描述问题 🍊专栏推荐:深度学习网络原理与实战 🍊近期目标:写好专栏的每一篇文章 🍊支持小苏:点赞👍🏼、收藏⭐、留言📩 深度学习语义分割篇——DeepLabV1原理详解篇 写在前面 Hello,大家好,我是小苏👦🏽👦🏽👦🏽 之前我已经为大家介绍过最基础的一种语义分割网络——FCN啦🍭🍭🍭,如果你对FCN还不了解的话,可以点击如下链接了解详情,这对你入门语义分割会非常有帮助: 深度学习语义分割篇——FCN原理详解篇🍁🍁🍁深度学习语义分割篇——FCN源码解析篇🍁🍁🍁今天为大家带来的是DeepLab系列的第一篇文章,目前此Deeplab系列的更新计划如下: DeepLabV1原理详解篇,详细介绍DeepLabV1的网络结构和关键创新点。DeepLabV2原理详解篇,详细介绍DeepLabV2的网络结构和关键创新点。DeepLabV3原理详解篇,详细介绍DeepLabV3的网络结构和关键创新点。DeepLabV3源码实战篇,带大家阅读源码,对DeepLabV3有更深入的了解。在此DeepLab系列中没有对DeepLabV1和DeepLabV2做源码解读,我觉得没啥必要,感兴趣的可以去看一看。🥗🥗🥗 论文链接:DeepLabV1论文🍵🍵🍵 语义分割存在的问题及解决方法 在论文中,作者提出了将DCNN运用到语义分割任务中存在的两个技术障碍,如下图所示:
翻译过来什么意思呢,即存在信号下采样和空间不变性这两个问题,那么为什么会出现这样的现象呢?又该怎么解决呢?论文中也给出了相关解释: 为什么?🔐🔐🔐 信号下采样:这是指卷积神经网络重复的使用下采样max-pooling,从而导致图像分辨率不断降低。🍊🍊🍊空间不变性:论文中解释为与从分类器中获得以物体为中心的决策需要空间转换的不变性有关,这本质上限制了DCNN模型的空间精度。说实话,听不懂。🎄🎄🎄其实啊,这里就是说像图像分类、目标检测这些High-Level的视觉任务(以获取图像中物体为核心的任务)需要空间不变性,也就是说对目标检测这类任务而言,对于同一张图片进行空间变换其图像分类的结果是不变的;而像语义分割这些Low-Level视觉任务,对于一张图片进行空间变换后,其结果就会发生变化,这就导致DCNN做语义分割时定位精准度不够。🍉🍉🍉怎么办?🔑🔑🔑 信号下采样:既然重复使用了下采样max-pooling,那么我们自然会想到少使用几次下采样或者降低stride步长,但是这样会使得感受野变小,这是我们不希望看到的。那么是否有什么方法可以既不用不断下采样降低分辨率,又能保持感受野不变呢?这就要我们的空洞卷积上场了,它可以增大我们的感受野。关于空洞卷积的细节不了解的可以阅读我的这篇博客:Dilated Convolution(空洞卷积、膨胀卷积)详解🧨🧨🧨空间不变性:为了解决这个问题,作者采用了fully-connected CRF(全连接条件随机场)方法,对DCNN得到的分割结果进行细节上的调整。这个方法在DeepLabV1和DeepLabV2中都使用了,但是在DeepLabV3中就不在使用了,自己看了看,公式怪多的,有点头大,后面也用不到,就没有深入学习了,大家感兴趣的可以去看一下,也推荐一篇博文叭:DenseCRF🧨🧨🧨DeepLabV1网络优势 论文中给出了DeepLabV1网络的三点优势,如下图所示:
DeepLabV1网络结构 前面已经为大家简单介绍了一下DeepLabV1网络的一些模块和优势,下面就来为大家来讲讲DeepLabV1的网络结构。我打算采用总-分结构为大家叙述,先和大家唠唠DeepLabV1中几个关键模块,然后再为大家介绍DeepLabV1的整体网络结构。 LargeFOV模块首先需要说明的是DeepLabV1的框架是基于VGG16实现的,对VGG16不熟悉的可以看一下我的这篇博客:深度学习经典网络模型汇总2——VGGNet🩸🩸🩸,为了方便大家阅读,这里贴出VGG16的网络结构图,如下:
那么这个LargeFOV模块是什么呢?又作用在什么位置呢?其实呀,这个LargeFOV模块就是我们在前面说到的空洞卷积,作者将VGG16的第一个全连接层换成了空洞卷积,保证了网络在mIOU不降低的前提下,减少参数量,加快速度。 全连接层换成了空洞卷积?怎么换的呢?或许你会有这样的疑问,我们一起来学习一下。首先将全连接层换成普通卷积这种操作大家是否了解呢,比如在FCN中就将VGG16的第一个全连接层换成了卷积核大小为7×7,卷积核个数为4096的卷积层,对此不了解的可以点击☞☞☞了解详情。🌱🌱🌱知道了如何将全连接层转换成普通卷积,那剩下的就是将普通卷积变成空洞卷积了,这就没什么好说的了,不了解空洞卷积的点击☞☞☞为自己赋能喔。🥗🥗🥗 论文中也做了一系列不同kernel size和input stride(膨胀因子)的对比实验,如下图所示:
根据实验效果,最终作者选择了采用卷积核大小为3×3,input strede为12的空洞卷积。【最后一行感受野大,参数量小,mean IOU高,速度快🥂🥂🥂】 这里其实我是有一些疑惑的,就是不知道这个感受野224是怎么计算得到的,按照我的理解,怎么算感受野也不是这么多,如果有大佬知道,麻烦告诉小弟一声,不胜感激 !!!🤞🏽🤞🏽🤞🏽 fully-connected CRF模块fully-connected CRF中文翻译为全连接条件随机场,哈哈哈哈,我是一脸懵逼,在前文中我也说到了,这一部分我不会介绍这个模块是怎么实现的,只会说说这个模块的作用。其实啊,这个模块就是让分割更加精细,它相当于我们对得到的粗略的分割图又进行了进一步的细化操作,过程如下: 话不多说,直接上图:
图片来自B站霹雳吧啦Wz 这个结构是基于VGG16的,因此大家需要对比着VGG16来看,让我们来看看它相较于VGG16做了哪些改变叭~~~🍦🍦🍦 VGG16所使用的所有Maxpool采用的keenel_size=2,stride=2,padding=0;🍚🍚🍚而在DeepLabV1中,前三个Maxpool采用的keenel_size=3,stride=2,padding=1,此参数配置的Maxpool同样起到下采样的作用,每次下采样2倍,经过3次Maxpool讲原始图像下采样8倍,在语义分割任务中我们不希望图像被过度的下采样,这样会丢失部分信息,因此后面两次Maxpool不再进行下采样,采用keenel_size=3,stride=1,padding=1的参数配置。此外在第五次Maxpool后DeepLabV1还接了一个keenel_size=3,stride=1,padding=1的Avgpool层,同样这层也没有再进行下采样 。🍪🍪🍪将VGG16模型最后三个卷积层改成了空洞卷积,其中keenel_size=3,r=2,stride=1,padding=2。【r为膨胀因子】【注:什么这里要使用空洞卷积腻,这是因为在DeepLabV1中我们只下采样了8倍,感受野较低,使用空洞卷积能够增大感受野🥝🥝🥝】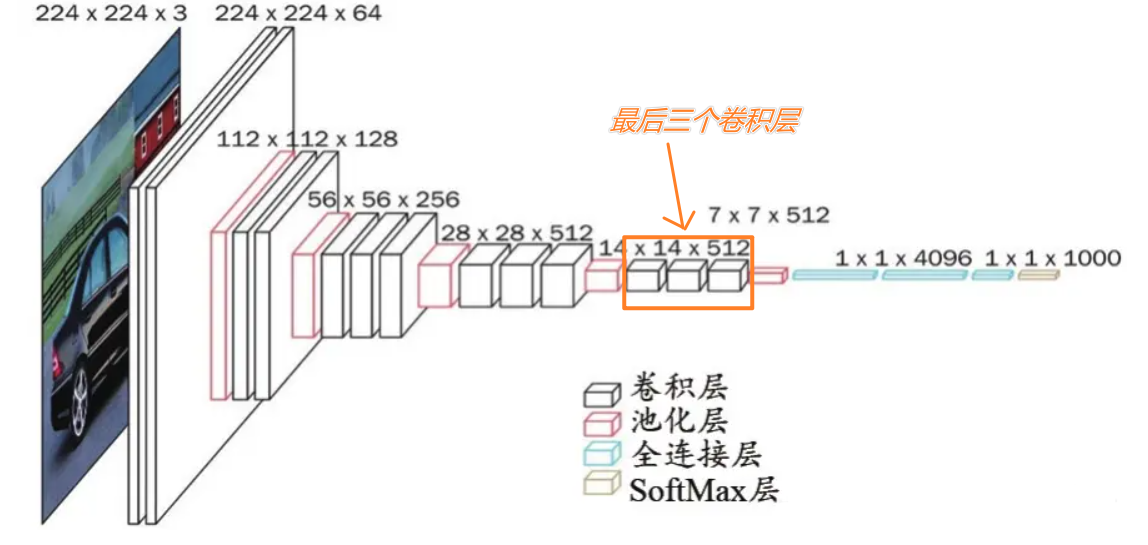 将VGG16模型的第一个全连接层换成空洞卷积,其中keenel_size=3,r=12,stride=1,padding=12,这就是上文提到的LargeFOV模块。🍅🍅🍅将VGG16模型的第二个和第三个全连接层都换成了卷积操作,需要注意一下经过最后一个全连接层(DeepLabV1中的最后一个卷积层)后的输出大小为
28
×
28
×
n
u
m
_
c
l
a
s
s
e
s
28×28×num\_classes
28×28×num_classes。🍀🍀🍀
带Multi-Scale的网络结构 将VGG16模型的第一个全连接层换成空洞卷积,其中keenel_size=3,r=12,stride=1,padding=12,这就是上文提到的LargeFOV模块。🍅🍅🍅将VGG16模型的第二个和第三个全连接层都换成了卷积操作,需要注意一下经过最后一个全连接层(DeepLabV1中的最后一个卷积层)后的输出大小为
28
×
28
×
n
u
m
_
c
l
a
s
s
e
s
28×28×num\_classes
28×28×num_classes。🍀🍀🍀
带Multi-Scale的网络结构
论文中还提到了使用了多尺度(Multi-Scale)的结构,即融合了原始图片和前四个Maxpool层的输出,我们直接看下图会更清晰:
图片来自B站霹雳吧啦Wz 这个结构似乎没什么么好说的,现在看来是比较常规的一个多尺度方法,不过还是需要大家注意一下这里原始图片和前四个Maxpool层的输出尺寸的都是 28 × 28 × n u m _ c l a s s e s 28×28×num\_classes 28×28×num_classes,最后将这些特征图进行ad操作。 我们可以来看看是否添加多尺度实验的对照结果,如下图所示:
第一行为没有添加MSC的效果,第二行为添加了MSC的效果,怎么样,还是挺明显的叭。🍸🍸🍸 DeepLabV1实验对比 其实在上文已经展示了相关的对照实验,这里我们再从直观上来感受一下DeepLabV1和其它算法的比较,如下图所示:
第一行表示原图,第二行为ground truths,第三行是最近提出的模型,左边为FCN-8s,右边为TTI-Zoomout-16,第四行为DeepLabV1。从上图可以很明显的看出DeepLabV1的结果更加精细,对图像边缘的处理效果更好。🍵🍵🍵 小结 DeepLabV1到这里就差不多为大家介绍完啦,希望大家都有所收获喔~~~🌷🌷🌷最后我想在稍微提一下DeepLabV1是怎么计算损失的。我们知道,FCN是用GT和网络输出结果计算交叉熵损失(cross_entropy)的,不知道的点击☞☞☞补课去,里面介绍的很详细。但是在DeepLabV1中我们会先将GT下采样8倍,然后再与 28 × 28 × n u m _ c l a s s e s 28×28×num\_classes 28×28×num_classes【28×28相较于原图224×224下采样了8倍🍡🍡🍡】的输出特征图计算交叉熵损失。论文中也有相关的表述,如下图所示,大家这里注意一下就好。🌼🌼🌼
参考链接 DeepLabV1网络简析🍁🍁🍁 DeepLabV1论文🍁🍁🍁 [论文笔记]DeepLabv1🍁🍁🍁
如若文章对你有所帮助,那就🛴🛴🛴
|



![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-py1kqSVE-1643041241886)(https://media5.datahacker.rs/2019/02/vgg.png)]](https://img-blog.csdnimg.cn/img_convert/681a2f20863b64d68400a7e911fd9894.webp?x-oss-process=image/format,png#pic_center)








【本文地址】