| 【机器学习】 | 您所在的位置:网站首页 › 函数有收敛性吗为什么 › 【机器学习】 |
【机器学习】
|
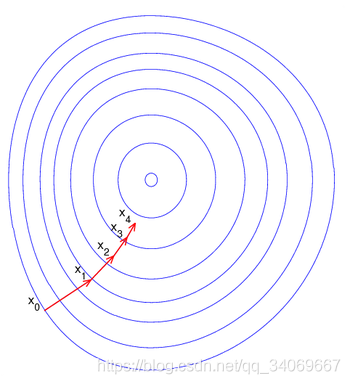
阅读之前看这里👉:博主是一名正在学习数据类知识的学生,在每个领域我们都应当是学生的心态,也不应该拥有身份标签来限制自己学习的范围,所以博客记录的是在学习过程中一些总结,也希望和大家一起进步,在记录之时,未免存在很多疏漏和不全,如有问题,还请私聊博主指正。 博客地址:天阑之蓝的博客,学习过程中不免有困难和迷茫,希望大家都能在这学习的过程中肯定自己,超越自己,最终创造自己。 目录 1.梯度下降法的原理和作用 2.为什么梯度下降可以收敛? 1.泰勒级数 2.如何利用泰勒公式求损失函数最小值为什么要写这篇博客呢?因为博主在面试的时候遇到了面试官问了这个问题,但是没有回答上来。而且博主也在网上去搜了很多解答,关于梯度下降法为什么收敛,很多解释都不够清晰,要么涉及到最优化或者凸优化的公式证明,确实比较复杂。博主又去看了李宏毅的2020版机器学习视频,发现在里面解释的很清楚,所以借花献佛,写一篇博客,既是解答自己的疑惑,也是解决大家的疑惑。 关于梯度下降法,博主之前已经在两篇文章中提及了,分别是: 1.数据分析面试【面试经验】-----总结和归纳 2.【机器学习】—各类梯度下降算法 简要介绍 不过上面只有基础的原理部分,大家如果只需要了解梯度下降法的作用,有兴趣可以看看这两篇博客。 1.梯度下降法的原理和作用梯度下降法简单来说就是一种寻找目标函数最小化的方法。 梯度下降法的优化思想是用当前位置负梯度方向作为搜索方向,因为该方向为当前位置的最快下降方向,所以也被称为是”最速下降法“。最速下降法越接近目标值,步长越小,前进越慢。梯度下降法的搜索迭代示意图如下图所示: 在机器学习中,我们需要解决的问题一般是求使得损失函数最小的参数问题: θ ∗ = a r g m i n θ L ( θ ) L : l o s s f u n c t i o n θ : p a r a m e t e r s \theta^* = arg\mathop{min}\limits_{\theta} L(\theta) \\ L:loss function \\ \theta:parameters θ∗=argθminL(θ)L:lossfunctionθ:parameters
通过上面的方程,或者算法,有一个疑问?就是每次梯度更新得到的新的值一定比原来的小吗?也就是梯度下降为何一定是收敛的呢?
|
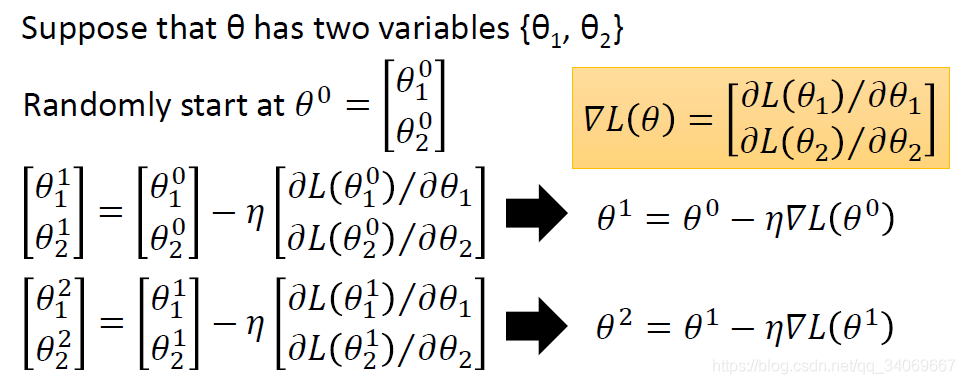 假设 θ \theta θ包含两个变量{
θ 1 , θ 2 \theta_1,\theta_2 θ1,θ2},初始值为 θ 0 \theta^0 θ0,设为 [ θ 1 0 θ 2 0 ] \begin{bmatrix} \theta_1^0 \\\theta_2^0\end{bmatrix} [θ10θ20],所以可以按照梯度下降公式得到更新的参数,然后进行不断迭代。
假设 θ \theta θ包含两个变量{
θ 1 , θ 2 \theta_1,\theta_2 θ1,θ2},初始值为 θ 0 \theta^0 θ0,设为 [ θ 1 0 θ 2 0 ] \begin{bmatrix} \theta_1^0 \\\theta_2^0\end{bmatrix} [θ10θ20],所以可以按照梯度下降公式得到更新的参数,然后进行不断迭代。 相信很多人知道,不一定更小,在这里我没有介绍学习率步长的知识,大家可以自行查阅,这不是本文章的重点内容。若学习率设置很大,步长太大,可能导致并不能收敛,也就是会导致损失函数很大,如下图所示:
相信很多人知道,不一定更小,在这里我没有介绍学习率步长的知识,大家可以自行查阅,这不是本文章的重点内容。若学习率设置很大,步长太大,可能导致并不能收敛,也就是会导致损失函数很大,如下图所示: 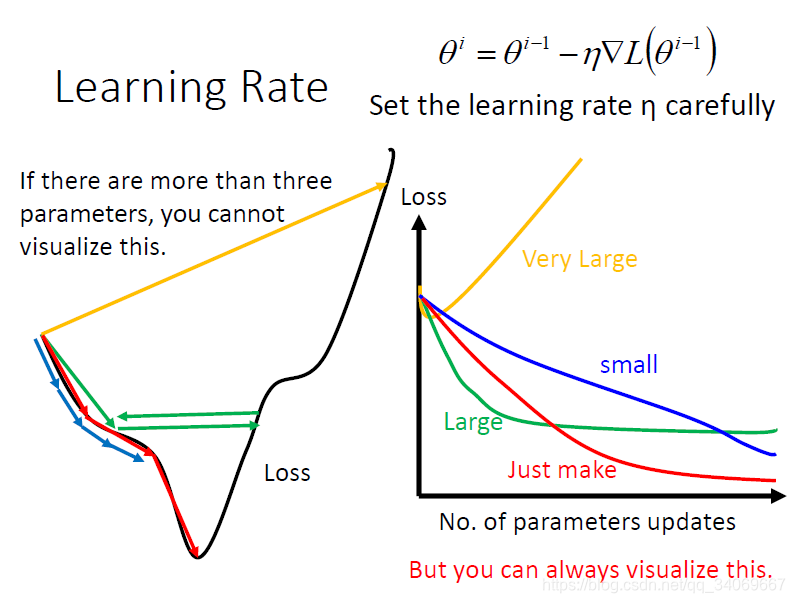 那么如何去找到收敛的最低点,也就是找到使得损失函数最小的参数的值。
那么如何去找到收敛的最低点,也就是找到使得损失函数最小的参数的值。 通过初始值 θ 0 \theta_0 θ
通过初始值 θ 0 \theta_0 θ【本文地址】