| 龚健雅院士 | 您所在的位置:网站首页 › 凡人专用框架 › 龚健雅院士 |
龚健雅院士
|
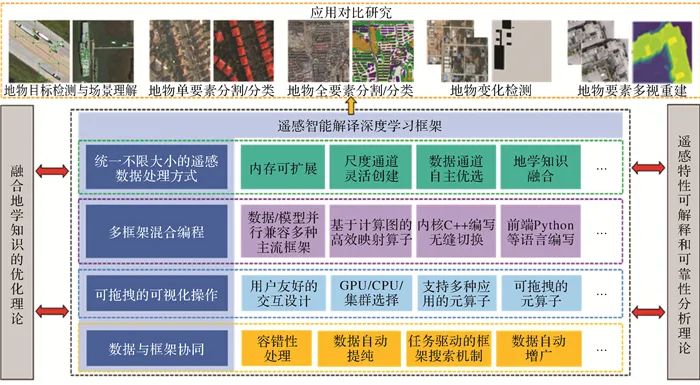
以下文章来源于智绘科服 ,作者测绘学报 智绘科服. 更具学术范儿的地理信息传媒 ↑ 点击上方「中国测绘学会」 可快速关注我们 摘要: 近年来,随着遥感技术的快速发展,遥感对地观测数据获取量与日俱增。在对海量遥感数据的特征提取与表征上,基于深度学习的智能遥感影像解译技术展现出了显著优势。然而,遥感影像智能处理框架和信息服务能力还相对滞后,开源的深度学习框架与模型尚不能满足遥感智能处理的需求。在分析现有深度学习框架和模型的基础上,针对遥感影像幅面大、尺度变化大、数据通道多等问题,本文设计了嵌入遥感特性的专用深度学习框架,并重点讨论了其构建方法,以及地物分类任务的初步试验结果等。本文提出的智能遥感解译框架架构将为构建具备多维时空谱遥感特性的深度学习框架与模型提供有力支撑。 关键词:遥感智能解译;深度学习;专用框架模型;遥感特性 阅读全文:http://xb.sinomaps.com/article/2022/1001-1595/2022-4-475.htm 引 言 遥感对地观测技术的发展与地理国情普查等项目的实施,形成了时效性强、覆盖范围广、信息量丰富的海量数据[1-2]。随着大数据、人工智能等技术的发展,基于深度学习的遥感影像解译与监测技术表现出了一定的优势。但在实际应用中,遥感影像智能处理框架和信息服务能力相对滞后[3-5],仍未形成与人脸识别、车牌识别等类似的可广泛实用化的智能系统。截至目前,开源的深度学习框架与模型尚不能满足遥感影像智能处理的迫切需求。 遥感影像的智能解译涉及场景识别、目标检测、地物分类、变化检测、多视角三维重建等典型任务。在深度学习框架和模型方面,大多由通用图像识别的模型改造而来,一般只考虑可见光波段的图像特征,未顾及更广泛的遥感物理特性和地学知识等重要因素。在可扩展性方面,已有的深度学习框架大多只支持输入小尺寸影像,难以支持大幅面遥感影像整体训练[6]。例如训练语义分割网络,如果直接载入30 000×30 000像素的大幅影像,则会出现内存溢出问题导致训练失败。为保证正常训练,通常需将大幅遥感影像裁剪为512×512像素的固定尺寸作为语义分割网络的输入。然而,在这种处理方式下,现有深度学习框架难以挖掘到影像大范围空间上下文信息,使其扩展性受限;在尺度通道构建方面,普通影像包含场景范围小,尺度有限,而遥感影像受传感器、观测平台影响,分辨率各不相同、地物尺度变化极大,例如水体、植被等[7]。现有深度学习框架缺乏应对如此大尺度变化的优化方法;在数据通道选择方面,普通影像的三通道相关性小,无须复杂的通道选取。遥感影像,尤其是高光谱影像,包含数百个通道,亟须深度学习框架具备优选能力[8-9];在知识融合与建模方面,深度学习过程存在“灾难性遗忘”[10-11],难以同时保有新旧数据处理能力。遥感影像有“同谱异物、同物异谱”现象,仅靠学习的图像特征,难达到理想精度,不能运用先验知识集成地学抽象规则,做出可解释、高可靠的决策。因此,亟须设计嵌入遥感地学先验知识的高效、可靠的智能遥感深度学习框架与模型。 人工智能时代,智能遥感深度学习框架与模型是连通遥感硬件、软件、应用场景的枢纽与关键。由于遥感对地观测与智能处理的战略价值,美国在2020年将基于人工智能的遥感技术列为敏感技术并限制出口,对我国形成新一轮封锁态势。鉴于目前尚无顾及遥感大幅面、多通道、知识融合特性的深度学习框架,研究面向遥感应用、具备自主知识产权的专用深度学习框架与模型,占领遥感人工智能生态链的制高点已显得尤为紧迫。本文针对遥感影像特点以及目标识别与动态监测等应用需求,提出了兼顾遥感影像特性的智能遥感深度学习框架与模型的研究思路(图 1),并基于该研究路线设计了具备多维时空谱遥感特性的遥感专用深度学习框架与模型。
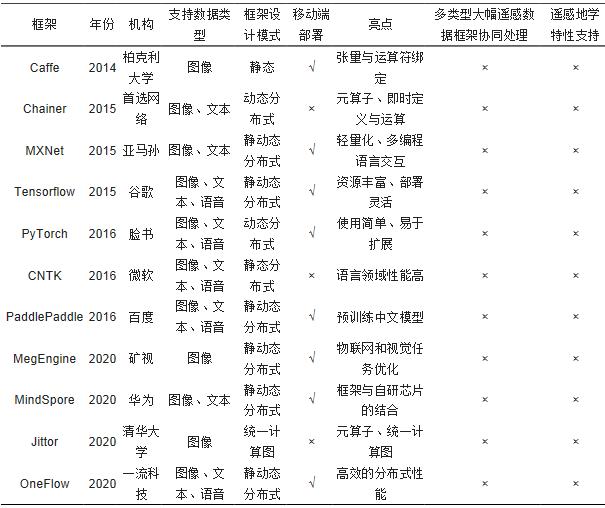
图1 智能遥感深度学习框架与模型技术研究路线 遥感专用深度学习框架具备不限制遥感影像大小特点,具有多框架混合编程、可拖拽的可视化操作及数据与框架协同等功能,使其能够与样本库紧密结合,自动适应多类型、多尺度、多级别的大规模遥感影像样本的训练与测试。同时,该框架能够构建顾及遥感特性的优化分析方法,为模型结构优化提供了科学依据。本文方法将形成尺度通道可灵活创建、数据通道可自适应优选、多层级联合优化的遥感专用深度学习框架与模型,能为遥感影像智能处理新理论、新技术和新成果的验证奠定基础。 遥感智能解译框架与模型现状 自2012年ImageNet挑战赛以来,面向通用图像处理的深度学习框架和模型迅猛发展。而现有的遥感领域影像处理模型,多由普通影像预训练模型迁移获得,并不具备遥感影像解译所需特性。 目前开源深度学习框架种类繁多(表 1)。国内中国科学院计算所推出了人脸识别深度学习框架Dragon[12],清华大学发布了计图(Jittor),百度、华为、旷世、一流科技等企业相继开源了PaddlePaddle、MindSpore、MegEngine及OneFlow等框架。在国外,早期蒙特利尔理工学院开源了Theano[13]、伯克利大学研发了Caffe[14],日本首选网络研发了Chainer框架, Google、Facebook、Amazon等先后开源了Tensorflow[15]、PyTorch[16]、MXNet[17]等框架。虽然通用深度学习框架数目众多,但构建框架的核心技术呈收敛态势,包括:控制流与数据流及操作符与张量;计算图优化与自动梯度计算;执行引擎、编程接口、部署运维及分布式训练等。 表1 国内外主要开源深度学习框架对比
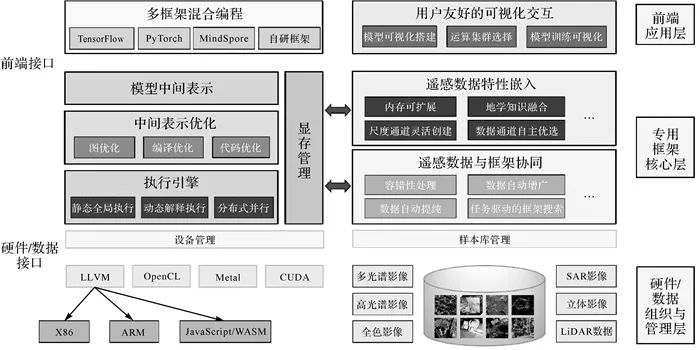
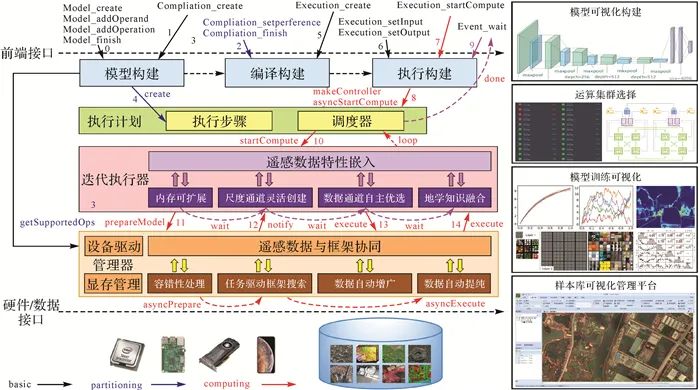
在控制流与数据流方面,神经网络依赖关系表示为有向无环图。随着并发处理需求增多,函数式编程的框架正占据主流。Tensorflow、PyTorch、MindSpore等框架侧重计算图的函数式求解方式,对完整模型一次性求解。在操作符与张量表达方面,Caffe等传统框架使用层(Layer)粗粒度的双向执行逻辑。在前向传播时,程序执行递增循环;在反向传播时,程序逆向做递减循环。 Tensorflow将有向无环图的操作符和张量分开表示,其细粒度表示的开发灵活性更强。由于细粒度表示对编译器要求较高,多数框架也支持粗粒度操作符,例如卷积、池化等操作符。因此,粗细结合算子是深度学习框架的发展趋势。此外,对张量计算的支持,可通过C++模板元编程提高效率。例如Tensorflow框架使用Eigen库,MXNet采用Mshadow库。 在计算图优化方面,深度学习框架利用编译器技术对有向无环图优化重写。计算图优化包括编译器优化、无用代码与公共子表达式消除、操作符融合、类型/形状推导及内存优化等。在自动梯度计算方面,深度学习框架有两种构建方式,一种是静态图,例如Caffe和Tensorflow;另一种是Chainer等框架推出的动态图。静态图计算效率高、易优化,但灵活性、易用性不如动态图。无论基于静态图还是动态图的框架,自动逆拓扑序推导链式法则的反向传播计算图已成标配。用户只需描述前向传播,反向传播由框架自动推导完成。 在执行引擎、编程接口、分布式训练与迁移部署方面,Tensorflow、PyTorch等通过协调CPU和GPU设备提高计算效率。底层基于C++开发,同时提供Python等前端接口。从开发到部署遵从“离线训练、在线识别”原则。其训练依赖分布式平台,使用数据并行的策略扩大处理规模。然而,设备数量不断增加会导致通信开销增长,出现模型效率损失等缺陷。因此,将计算矩阵分块的模型并行策略以及GPU接力训练的流水线并行策略受到了重视。目前,主流开源框架都支持数据并行,但对模型并行和流水线并行的支持仍较困难。在框架部署与运维方面,普遍用Docker和Kubernetess结合方案。同时,随着开放神经网络交换标准(ONNX)的推出,极大方便了网络模型在不同框架之间进行切换。例如,主流的Tensorflow、PyTorch等框架都支持ONNX标准。 在基础模型设计方面,蒙特利尔大学率先在GPU上实现AlexNet[18],并在ImageNet[19]取得超过第2名10%的精度;牛津大学设计了VGG-Net[20]使top5错误率降至7.5%;谷歌推出的GoogleNet[21],使识别精度大幅提升;文献[22]提出ResNet,使top5错误率降低至4.5%;康奈尔大学与Facebook FAIR实验室等推出DenseNet[23],使相同精度下计算量降低;中国科学技术大学与MSRA开源了HRNet[24],刷新了MS-COCO数据集[25]3项纪录。在模型结构自动搜索(NAS)方面,数据驱动的搜索主要包含基于强化学习[26]、演化计算[27]与基于梯度的方法[28]。基于强化学习方法通过代理模型指导搜索方向,常用代理模型有循环神经网络[29]与近端策略优化等[30]。基于演化计算方法将模型结构编码为字符序列,生成新的结构。其中网络架构与模型参数分别基于演化与随机梯度下降方法迭代更新[31]。基于强化学习和演化计算方法具有出色性能,但对计算要求很高;基于梯度的方法能提升效率,利用概率平滑使搜索空间可微。目前,遥感影像智能处理涉及的应用模型大多由计算机视觉领域的基础模型及搜索方法改造而来,例如在遥感目标分类任务中,大量研究者使用了基于ResNet和空洞卷积结构的DeepLab系列模型[32-33]。基于这些基础模型及搜索方法的应用模型,在遥感目标检索与场景分类[34-35]、遥感目标检测[36-37]、遥感地物要素分类[38-39]、遥感变化检测[40-41]、多视三维重建[42-43]等任务均有广泛应用,但针对小尺寸影像搜索的模型,未顾及大幅遥感影像“像素-目标-场景”多层级要素提取、变化发现等任务的特性。 通过对比国内外开源深度学习框架和模型可以发现,为平衡计算和灵活性需求,主流深度学习框架各有其优缺点。然而,主流深度学习框架与模型针对的是普通影像,即小像幅室内/外影像。现有遥感解译模型大多由通用图像识别的深度神经网络改造,一般只考虑了影像的可见光影像特征,未顾及遥感光谱特性、地学先验知识、数据与框架协同等因素,导致支持遥感地学特性的框架仍是空白。 遥感智能解译专用框架设计 面向幅面大、数据通道多的遥感影像,遥感专用的解译框架与模型应具备内存可扩展、尺度与通道的自适应优选机制,其总体架构如图 2所示。前端接口和硬件/数据接口将其分为3层:前端接口之上为应用层,包含多框架混合编程和可视化交互模块;硬件/数据接口之下为硬件后端和遥感数据层,由设备和样本库管理模块组织与管理;两大接口间的专用框架核心层,包括中间表示与优化、执行引擎、显存管理、遥感数据特性嵌入及遥感数据与框架协同模块。本节首先介绍专用框架前端应用层、硬件/数据组织与管理层、框架核心层,随后详细介绍框架核心层中嵌入遥感特性的方法,最后介绍专用框架的执行流程。
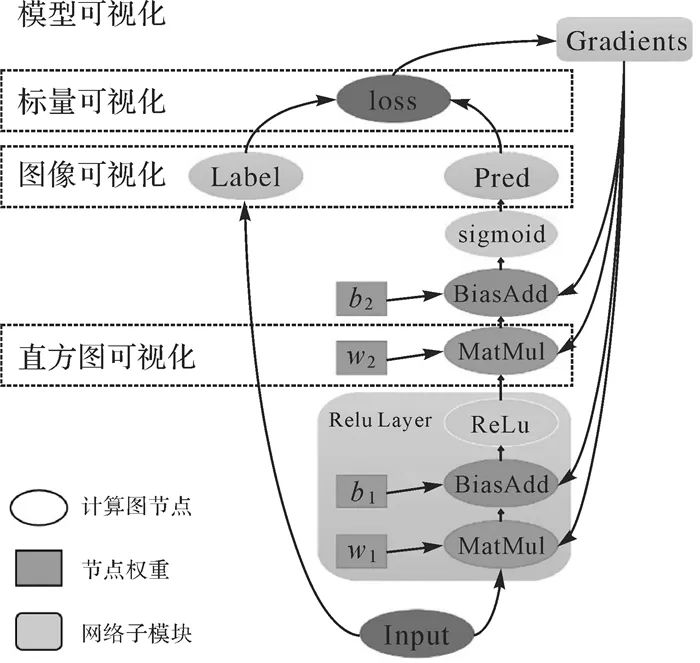
图2 遥感专用深度学习框架总体架构 1 专用框架构建 (1) 前端应用层。用于兼容已有框架,提供交互式模型搭建界面,包括:①多框架混合编程模块。使用中间表示(IR)和虚拟机(VM)技术,将Tensorflow、PyTorch、MindSpore等框架的模型翻译成本框架的中间格式,在后端实现部署。用户可使用本框架的编程接口、数据读取接口、网络执行接口等,利用Python环境和遥感影像特性优化算子,实现模型创建与运行。②可视化交互模块。前端提供图形用户界面接口(GUI)。如图 3所示,使用GUI拖拽构建网络模型,利用图标展示梯度、损失等信息,直观地查看训练过程的标量、图像、直方图等。网络模型由可拖拽的算子组成,能提供算子关键内容;对于算子记录输入、输出参数;对于网络模型记录算子、超参数信息等。GUI可一键拖拽算子,并展示属性、数据流向信息。
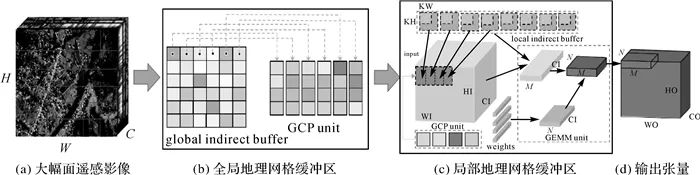
图3 网络结构可视化交互模块 (2) 硬件/数据组织与管理层。用于屏蔽硬件设备差异,管理遥感影像样本库,实现高效读写与存储管理,包括:①设备管理模块。硬件接口下是硬件后端,包含X86、ARM、CUDA等设备,由设备管理模块负责并对设备抽象,内容包括抹除硬件版本差异等。②样本库管理模块。数据接口下是遥感影像样本库。同时,样本库管理模块也负责框架与数据协同组织,包括对上衔接样本自动增广、容错与提纯等任务,对下调度样本库索引。 (3) 框架核心层。用于构建有向无环计算图,通过中间层表示优化,并围绕数据流和控制流嵌入遥感特性执行计算。包括:①模型中间表示模块。对Tensorflow、PyTorch等框架和本框架实现的算法模型,组成有向无环计算图(节点代表张量,节点间代表张量间依赖)。②中间表示优化模块。该模块引入3种优化策略,一种是层融合(layer fusion),例如对卷积与激活的连续层合为一层,减少读写次数。另一种是张量融合(tensor fusing),通过寻址将不同分支结果填入合适位置,减少内存搬运。第3种是无用层消除(dead layer elimination)。通过解析模型消除无用层以减少计算量。③执行引擎模块。该模块根据计算图的算子计算顺序执行。执行引擎迭代训练时,根据程序和显卡数量构建静态单流赋值图(static single assignment graph, SSA graph),多卡间只在聚合梯度时同步。同时,结合静动态图,以增强静态图模式的调试功能与动态图模式的运行效率。④显存管理模块。该模块采用3种显存优化策略。一种是显存预分配机制。若分配需求requested_size不超过显存池chunk_size,则从显存池分出requested_size的块;若requested_size大于chunk_size,则调用cudaMalloc分配requested_size的显存。另一种是垃圾回收机制,其作用是在运行阶段释放无用变量空间,以节省显存。第3种是显存复用机制(inplace),使算子输出复用输入显存空间。例如,数据整形(reshape)操作的输出和输入可复用同一显存空间。 2 遥感特性嵌入层构建 遥感特性嵌入层,主要支持框架核心层对大幅面、多尺度、多通道遥感数据的处理。其中基于间接缓冲区分组映射的内存可扩展方法,用于处理大幅面影像整体载入问题;基于记忆池的尺度通道灵活创建方法,用于处理框架中尺度通道创建问题;嵌入场景知识的数据通道自适应优选方法,用于处理数据通道的优选问题。这3部分相互独立,通过迭代执行器(图 9)迭代调用并优化。 (1) 基于间接缓冲区分组映射的内存可扩展方法。基于空间上下文结构的间接缓冲区分组映射方法可以构建全局与局部地理网格缓冲区,实现大幅面遥感影像整体载入、内存映射与空间上下文学习。 全局地理网格缓冲区构建。如图 4所示,全局地理网格对大幅影像整体拆分,以合理利用内存空间。网格中保留适于内存的指针区域,即全局间接缓冲区(global indirect buffer)。同时间接缓冲区指针,指向存储全局空间上下文处理单元(global context processing unit, GCP unit),以保留大范围上下文。全局间接缓冲区是指向尺寸为H×W×C的指针,其大小Gbuf如下 (1)
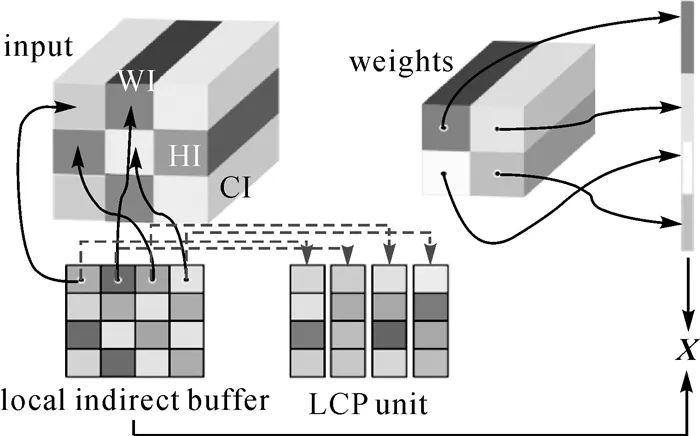
图4 内存可扩展的间接缓冲区分组映射方法 式中,KM、KN是地理网格行列数,取值为1时,退化与Caffe等框架的im2col一致;MaxMem是最大内存空间;r为指定的内存利用率;p、fdim表示GCP单元的全局特征个数与维度。 局部地理网格缓冲区构建。如图 4(b)、(c)所示,局部地理网格缓冲区是将全局地理网格中影像瓦片和标注映射至GPU设备的转换单元。其整合了GCP unit特征,同时利用局部间接缓冲区(local indirect buffer)检索瓦片指针,搜集局部瓦片影像上下文(local context processing unit, LCP unit)。通过GEMM单元为空间上下文加权,实现“全局-局部”上下文学习。如图 4(b)、(c)与图 5所示,局部间接缓冲区是大小为KH×KW的区域,共有HO×WO个。框架运行时,由该缓冲区取出瓦片影像及全局上下文特征指针,通过GEMM加权计算M×N规模的输出X。局部缓冲区大小Lbuf计算如下 (2)
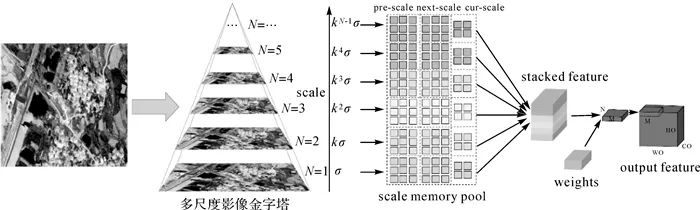
图5 局部间接缓冲区 式中,KH×KW为缓冲区大小;HO×WO为输出维度;q、ldim分别为LCP单元的特征个数与维度。 由式(1)和式(2)可知,利用“全局-局部”地理网格缓冲区的指针,通过指针搜寻能降低CPU-GPU计算所需存储空间,使大幅面遥感影像可整体载入训练,同时融入全局与局部空间的上下文信息。 (2) 基于记忆池的尺度通道可灵活创建方法。如图 6所示,尺度记忆池(scale memory pool)在框架载入遥感影像时,自适应学习和选择各尺度堆叠特征(stacked feature)。其包含的关键技术有:①多尺度影像金字塔构建。引入高阶金字塔表示,降低尺度变化损失。②尺度记忆池构建。当前尺度(cur-scale)、前一尺度(pre-scale)以及下一尺度(next-scale)的邻域形成尺度记忆池,通过池中的指针,快速检索形成堆叠的尺度特征。
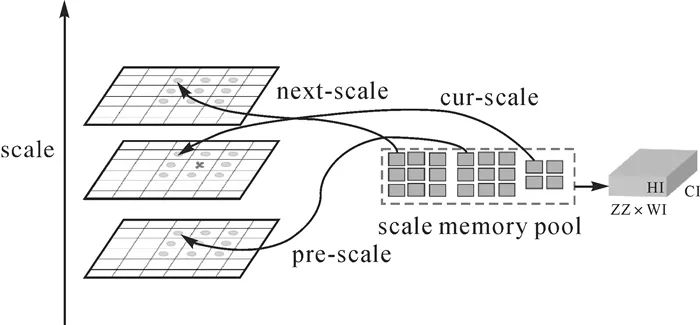
图6 尺度通道灵活创建的记忆池自适应优化方法 多尺度影像金字塔构建。类似拉普拉斯尺度空间构建,多尺度影像金字塔的尺度空间编码集表达如下 (3) 式中, Li=I(x/2i-1)-I(x/2i)是拉普拉斯金字塔的第i层;I为经尺度参数ki-1σ降采样的影像;L1为精细尺度;LN为较粗尺度;G表示低通残差;Mi=|Li|是梯度幅值。通过计算各尺度编码Li(x)/Mi(x /2),多尺度高阶金字塔由如下编码集迭代定义 (4) (5) 由式(4)与式(5)的高阶编码集,可重建任意尺度的金字塔影像 (6) (7) 式中,H1, i为式(4)的编码集;H2, i表示式(5)的编码集;H(i)-1表示重建的第i层尺度空间影像。 尺度记忆池构建。为快速从堆叠特征中检索对应尺度参数,本文使用尺度记忆池构造方法(图 7)。首先,在当前尺度(cur-scale)以2×2的网格邻域形成缓冲区,存储指向当前尺度重构的金字塔影像区域指针。然后,变换尺度参数,获取前一尺度及下一尺度的3×3邻域网格,存储前一尺度和下一尺度重构的影像区域指针,形成两个3×3缓冲池。此时,前一尺度、下一尺度与当前尺度缓冲池,共同构成了22个间接存储的记忆缓冲池,随后可通过缓冲池指针检索相应尺度的重构影像区域。最后,经过堆叠的重构特征加权学习,实现尺度通道自适应创建。
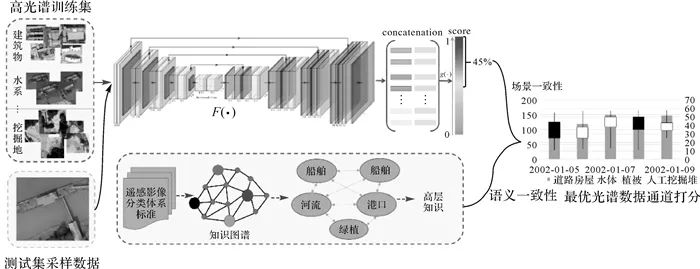
图7 尺度记忆池构建方法 (3) 嵌入场景知识的数据通道自适应优选方法。本文采用嵌入知识图谱和场景一致性策略,实现数据通道优选。如图 8所示,该优选策略由两部分组成:其一是场景嵌入单元,训练集按场景划分,与测试集的采样数据由编码-解码网络连接,计算采样与训练数据的场景相似度与损失。其二是知识嵌入单元,利用样本库分类体系,构建知识图谱,得到预测结果相关的高层知识保持结果一致性,选择最优数据通道。
图8 嵌入场景知识的数据通道自主选优策略 场景嵌入单元。假设训练集为ϕ={ϕi}i=1N,N是场景类别;测试集为T={Ti}i=1K,M=C(F(Tk), F(ϕi))表示经编码-解码网络F(·)的特征。通过打分函数G(·),得到场景优化表达式 (8) 相应场景类别i的损失为 (9) 式中, 为前45%场景类别预测值;y*为场景类别真值,取标签占比最大的类别。 知识嵌入单元。用建立的地学知识图谱,获得概念类别(高层知识)集合L={l1, l2, …, lN}。元素li至lj间的相关度,采用随机游走方法确定 (10) 式中,α为重新游走的概率。语义一致性损失如下 (11) 式中,χ2(·)表示Pearson卡方散度;yh为softmax函数计算的概率;P为由pij组成的相似度对称矩阵。最终LC与LH构成通道选择损失 (12) 式中,λ是知识嵌入损失的调整系数。通过通道损失的整体调整,获取最优光谱数据通道打分,实现通道自动优选。 3 专用框架执行流程 遥感专用框架执行流程如图 9所示,图中以数字索引为任务执行顺序。黑色文字和箭头表示常规流程;蓝色文字和箭头表示的划分阶段;红色文字和箭头表示执行阶段。完整执行流程分为3个阶段:
图9 遥感专用深度学习框架执行流程 (1) 网络模型准备阶段(步骤0—步骤1)。用户通过框架前端自定义算子和操作数,构建初始网络模型,为模型编译和优化做好相应准备。 (2) 网络模型编译阶段(步骤2—步骤4)。得到初始计算图描述后,编译阶段根据用户设置,使用编译构建模块对初始计算图进行图优化、张量优化等编译优化,完成模型的编译构建。 (3) 网络模型执行阶段(步骤5—步骤14)。编译阶段构建的计算图,在执行阶段通过围绕数据流和控制流的执行构建模块具体落实。分以下子步骤:①模型的输入与输出配置(步骤5—步骤6)。框架根据接收参数配置网络模型描述信息,为计算启动与执行做好配置与准备;②模型的启动与执行(步骤7—步骤9)。框架执行构建模块,将调度器模块的回调结果返回上层应用,上层应用使用回调结果等待计算结束。同时执行可视化分析模块,监测迭代损失、影像特征等;③异步计算的启动与结束(步骤10—步骤14)。模型启动与执行时,步骤8的命令(asyncStartCompute)通过循环调用迭代执行器完成。管理器通过设备驱动模块的信息,调用硬件设备支持模型计算。管理器中显存管理模块、遥感数据与框架协同模块反馈的内存和数据信息,通过遥感数据特性嵌入模块,无缝融合遥感特性。此外,框架将计算信息通过遥感数据与框架协同模块反馈给样本库,以实现容错性处理、自动增广与提纯,使样本库具有协同精化能力。管理器执行完所有模块之后,发送命令通知迭代执行器。当迭代步骤完毕,asyncStartCompute线程会自动退出,最终结束计算并返回结果。 初步试验结果与分析 以地物要素分类任务为例,本文使用ISPRS Potsdam、广东地区实际生产数据与高光谱影像数据集AVIRIS Indian Pines来验证专用框架的内存可扩展、尺度与通道自适应优选的可行性。本文将PyTorch作为与本框架进行对比的基准框架,基于全卷积神经网络(FCN),对三通道Potsdam数据、实际生产数据进行裁切与整幅载入处理分析,以对比框架的大幅面遥感影像处理特性。此外,本文还对四通道Potsdam数据、200通道AVIRIS Indian Pines高光谱数据进行了尺度与数据通道优选的对比分析。FCN网络模型在Potsdam、实际生产数据集下的训练参数如下:epoch=40, base_lr=0.001, decay=0.000 5, momentum=0.9, batchsize=2。AVIRIS Indian Pines高光谱数据的训练参数为:epoch=200, base_lr=0.1, decay=0.000 5, momentum=0.9, batchsize=100。 1 大幅面处理特性试验结果 表 2和表 3是包含6类不同地物的ISPRS Potsdam、广东地区生产数据集的测试结果。在PyTorch框架下,原始影像被统一裁剪为513×513像素;在本文框架下,原始影像保持整幅载入训练。由表 2可知,引入大幅面影像处理机制,使本框架在Potsdam数据上的平均交并比(mIoU)提升了2.71%,总体精度(OA)提升了2.77%。在实测数据上,本文框架的提取精度提升了3%~5%。图 10为两种数据预测结果。试验表明,使用大幅面影像的整体载入训练的方式,可使神经网络具备处理更大范围的空间上下文的能力, 同时有效缓解了“分块效应”。 表2 ISPRS Potsdam数据(分辨率0.5 m)处理结果 处理策略对比(Backbone:ResNet101) mIoU OA PyTorch裁切处理(1×3×6000×6000→N×3×513×513) 80.25 82.26 本框架大幅面整体载入(1×3×6000×6000→1×3×6000×6000) 82.96 85.03 表3 广东地区生产数据(分辨率0.8 m)处理结果 处理策略对比(Backbone:ResNet101) mIoU OA PyTorch裁切处理(1×4×36072×36312→N×4×513×513) 42.25 58.26 本框架大幅面整体载入(1×4×36072×36312→1×4×36072×36312) 46.06 63.03
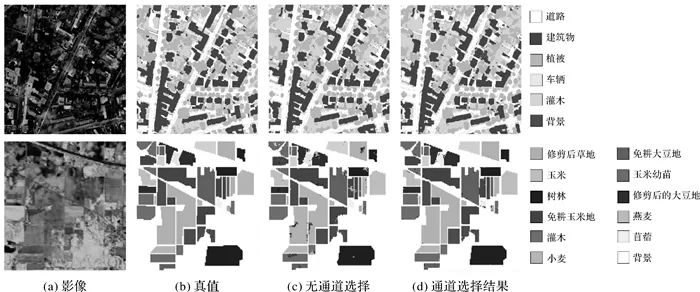
图10 Potsdom数据与广东数据局部预测结果 2 多通道处理特性试验结果 表 4和表 5是基于Potsdam数据和AVIRIS Indian Pines数据(包含16类地物)的测试结果。图 11的第1列为影像,第2列为真值,第3列为基线模型处理结果,第4列第1行为数据与尺度通道优选结果,第4列第2行为数据通道优选结果。由于AVIRIS数据幅面较小,本文在试验中未引入尺度通道优选方法。从本文框架的处理结果推断,框架引入数据通道与尺度通道优选模块之后,在Potsdam数据上比基线方法性能提升约2%,在AVIRIS高光谱影像上的Kappa与OA可达99%以上。上述结果表明本框架在融合尺度与数据通道的优选模块后,能够有效提升预测结果的精度和可靠性。 表4 ISPRS Potsdam数据(分辨率0.5 m)处理结果 处理模型 mIoU OA Baseline(DeepLabV2)(Input=3×512×512) 85.06 86.24 +数据通道优选(每一个类优选出1×256维度特征) 86.24 87.03 +数据通道优选+尺度通道优选(1, 0.75, 0.5) 87.20 87.88 表5 AVIRIS Indian Pines数据处理结果 处理模型 Kappa OA Baseline(ResNet18)(Input=200×11×11) 97.25 97.81 +数据通道优选(每一个类优选出1×256维度特征) 99.20 99.40
图11 Potsdom数据与AVIRIS数据局部预测结果 结论 本文在分析目前遥感智能解译框架和模型现状的基础上,提出了顾及多维时空谱遥感特性的专用深度学习框架和模型,构建了遥感专用深度学习框架与模型的在线服务平台,初步实现了模型的在线可视化编辑、模型训练及测试功能等功能。此外,本文针对全要素地物分类任务,使用了不同的遥感数据集开展了初步试验验证。试验结果表明,本文提出的专用框架具有内存可扩展、尺度和数据通道灵活优选的优势。 然而,本文构建的遥感专用深度学习框架在大幅面影像加载和运行效率、基于网络计算图中间层表示的编译优化、对多类遥感任务的相关模型支持以及与在线开源共享服务平台前后端集成等方面还需要进一步提高和完善。因此,下一阶段将研究遥感特性的中间表示、算子分解与编译优化、大幅面特征的分布式计算方法、框架模型协同的自进化机制、交互式前端组件扩充及与后端神经网络接口集成功能,将全面分析相关框架在遥感影像处理方面的性能,为面向遥感测图任务的实时解译机制提供有力的底层框架和应用模型支撑。 END 引文格式:龚健雅,张觅,胡翔云,等.智能遥感深度学习框架与模型设计[J].测绘学报,2022,51(4):475-487.DOI:10.11947/j.AGCS.2022.20220027. 作者简介:龚健雅(1957—),男,博士,教授,中国科学院院士,长期从事地理信息理论和摄影测量与遥感基础研究 原标题:《龚健雅院士 | 智能遥感深度学习框架与模型设计》 |

【本文地址】