| 精彩!字节跳动团队夺得NTIRE 2022 ESR挑战赛主赛道冠军 | 您所在的位置:网站首页 › 冠军模型是什么 › 精彩!字节跳动团队夺得NTIRE 2022 ESR挑战赛主赛道冠军 |
精彩!字节跳动团队夺得NTIRE 2022 ESR挑战赛主赛道冠军
|
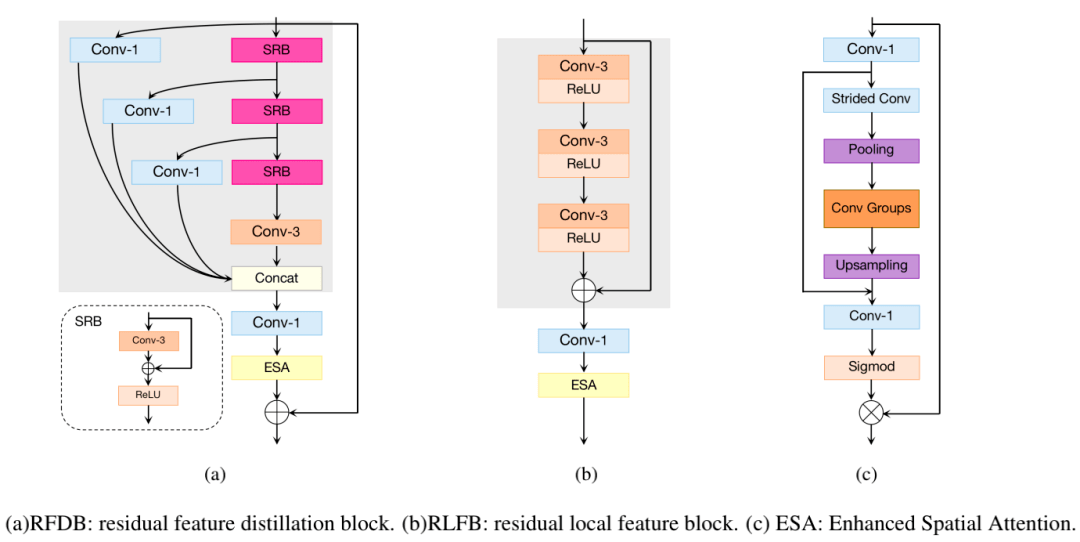
图 1 NTIRE2022 ESR 排行榜 NTIRE 已发布官方比赛报告:https://arxiv.org/abs/2205.05675。 参赛方案 ByteESR参赛方案论文:http://arxiv.org/abs/2205.07514 基于 Convolutional Neural Network(CNN)的方法已经在图像超分领域取得了极大的进展,为了解决模型在端侧设备部署的性能问题,各种不同的快速且轻量型的 CNN 模型被提出,IMDN 和 RFDN 是其中的佼佼者。 作为前两届的冠军方案,为了在有限的计算量下获得更好的表现,两者均使用了复杂的多路信息蒸馏,然而从推理加速的角度来看,多分支结构远不如单通路结构友好,一般来说分支越多对加速越不利。 ByteESR 队伍在 RFDN 的基础上从多方面提出了改进: 模型结构 Residual Local Feature Network 的整体框架采用图片超分领域的基础结构,主要改进点在于核心模块 RLFB 的设计,下图 2(b)给出了 RLFB 的详细结构,它由 RFDN 中的 RFDB 模块演化而来。
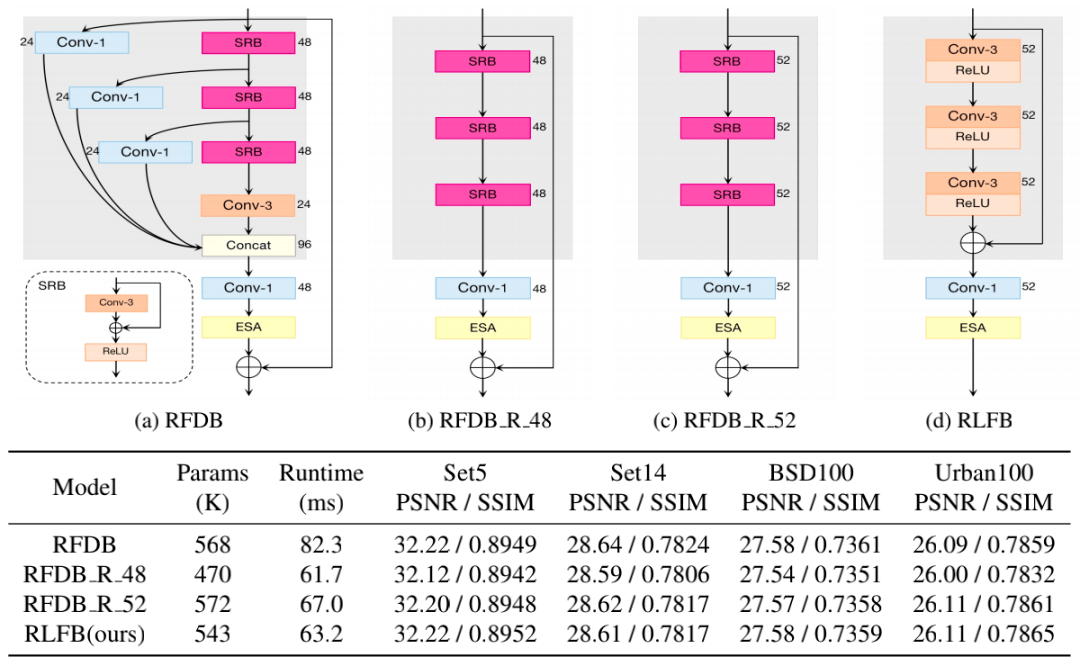
图 2 RFDB 和 RLFB 结构对比 RFDB 采用一种多阶段渐进式的蒸馏和细化策略。如图 2(a)中灰色背景区域所示,对于每个阶段 RFDB 采用一个 SRB 模块得到细化特征,然后用一个 1x1 卷积进行特征蒸馏,最后所有的蒸馏特征通过 Concat 进行融合。 假设输入特征表示为 F_in,DM_j 和 RM_j 分别表示第 j 个蒸馏和细化模块,该过程可以描述为: 尽管 1x1 卷积和 Concat 操作组成的特征蒸馏分支可以有效提升模型表现,但这些操作严重影响了运行时间。 为了进一步分析 RFDB 的耗时,ByteESR 队伍设计了图 3 所示的消融实验。 首先移除 RFDB 中蒸馏分支相关的层得到 RFDB_R_48,从图 3 表中可以看出 RFDB_R_48 和原始的 RFDB 相比减少了 25%的运行时间。 然后通过增大通道数的方式来提升模型表现,RFDB_R_52 的 PSNR 大幅超过 RFDB_R_48 但运行时间只是小幅增长。在 RFDB_R_52 的基础上,RLFB 中删除了 SRB 的密集加法操作并替换为普通的 CONV+RELU,进一步减少了运行时间。 最后将 Add 操作提前,用一个局部特征的残差学习进行特征细化。该过程可以描述为:
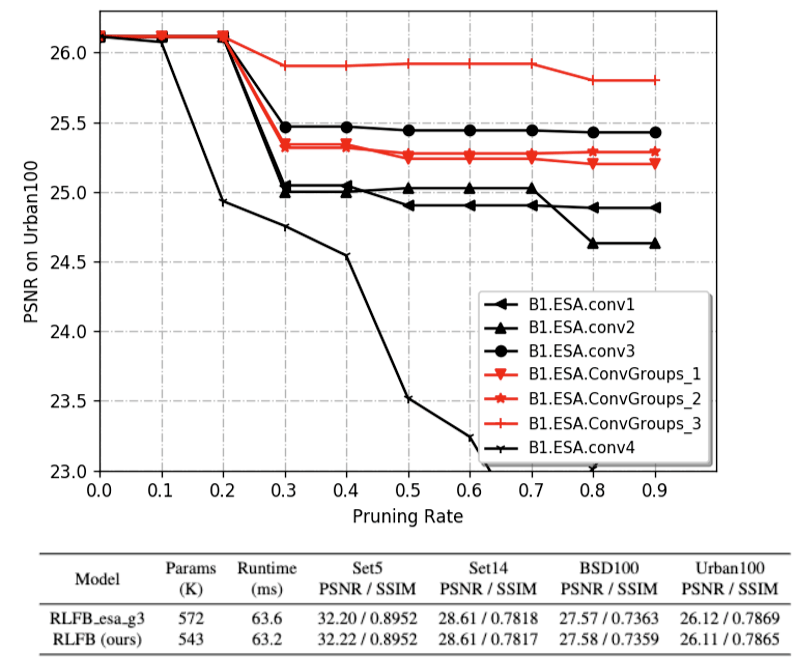
图 3 模型结构的消融实验结果 RFDB 中采用的注意力模块 Enhanced Spatial Attention(ESA)通过建模空间依赖关系使网络关注更为重要的空间特征,显示了优异的性能。 基于内部自研的模型压缩框架 NNcompression,ByteESR 队伍分析了 ESA 模块的参数冗余性。在图 4 中,曲线越平坦表明对应模块的参数冗余度越高。 由于 ConvGroups 中的三个卷积层在冗余度排序中均处于靠前的位置 ,因此我们可以在没有明显效果损失的情况下将 ESA 中 ConvGroups 减少到一个 Conv 层。
图 4 基于 one-shot 结构化剪枝算法的的参数冗余度分析 总结来说,RLFB 对特征细化分支进行重新设计并减少 ESA 中的冗余层,最终在相同参数量下,RLFB 得到和 RFDB 相近的 PSNR,并且有明显的速度优势。 在竞赛中,因为 Loss 函数和训练策略的加持,ByteESR 队伍采用了更小的模型结构。参赛的 RLFN 模型采用 4 个 RLFB 模块,模型通道数设为 48,同时 ESA 中间特征通道数设置为 16。 在训练的最后阶段,ByteESR 队伍使用 NNcompression 中集成的通道依赖 SFP 算法来压缩模型,将部分层剪枝为 46 通道。 Loss 函数 损失函数在模型训练中是非常重要的一环,设计优秀的损失函数能够大幅度提高模型的效果,同时不增加额外的推理耗时。ByteESR 队伍详细分析了被广泛应用的 contrastive loss,并对 contrastive loss 进行了优化。 Contrastive loss 首先通过特征提取器提取 anchor,postive,negative 的特征,然后计算这三部分特征在 latent space 中的距离损失。 一般在超分辨率任务中,anchor,positive,negative 分别指网络重建图像,高分辨率图像,以及低分辨率图像通过 bicubic 上采样的结果。 ByteESR 队伍详细分析了特征提取器(以 VGG-19 为例)提取到的各层特征,发现:提取的浅层特征具有非常精确的空间信息,而深层特征虽然具有丰富的语意信息,但是它的空间信息由于 max_pooling 等原因变得非常模糊。 图 5 对提取到特征进行了可视化,可以发现浅层特征具有非常精确的空间信息 基于以上结论,ByteESR 队伍重新构建了一个两层卷积组成的浅层特征提取器,同时使用 Tanh激活函数代替了 Relu激活函数。 可以发现重新构建的特征提取器能够提取到更加精确的空间信息,同时激活响应也更加强烈。
图 6 特征图可视化,左侧为 VGG19 特征提取器,右侧为 ByteESR 设计的特征提取器 ByteESR 队伍在多个 benchmark 数据集上验证了重新设计的 contrastive loss 的有效性,可以有效提高 PSNR 约 0.01 ~ 0.02db。 训练策略 为了进一步提高模型的效果,ByteESR 队伍对模型的训练策略进行了进一步优化。 以 x4 超分任务为例,通常情况下,会使用 x2 的超分模型的权重,作为 x4 超分模型的初始化权重。使用预训练权重可以提供一个更加精确的初始化效果,同时加快模型的收敛速度,提升最终效果。 ByteESR 队伍在此基础上提出了一种 multi-stage warm-start 的训练策略。以 x4 超分任务为例,在第一个阶段,不使用任何预训练权重,模型从 0 开始进行训练至收敛。从第二个阶段开始,每次都使用 warm-start 策略,即用前一个阶段的模型权重进行初始化。 Multi-stage warm-start 训练策略相比于一般训练策略有两个主要优势: 在 DIV2K Val 数据集上,使用两次 warm-start 策略可以提高 PSNR 约 0.03db。 总结 我们提出了一个更高效的网络结构 RLFN,在推理速度和效果之间取得良好的平衡,并且重新思考 contrastive loss 的使用,设计了一个更适合超分任务的浅层特征提取器,此外我们还提出了更有效的多阶段 warm-start 训练策略,最终在 NTIRE 2022 Efficient Super-Resolution 中获得冠军。 团队介绍 字节跳动智能创作团队是字节跳动音视频创新技术和业务中台,覆盖了计算机视觉、图形学、语音、拍摄编辑、特效、客户端、服务端工程等技术领域,在部门内部实现了前沿算法-工程系统-产品全链路的闭环,旨在以多种形式向公司内部各业务线以及外部合作客户提供业界最前沿的内容理解、内容创作、互动体验与消费的能力和行业解决方案。 目前,智能创作团队已通过字节跳动旗下的火山引擎向企业开放技术能力和服务。 火山引擎联系方式: 业务咨询:[email protected] 市场合作:[email protected] 欢迎通过下方链接或二维码进行简历投递,加入我们,让我们一起做图像视频算法的领军者! 图像算法研发方向:北京/上海/杭州/深圳职位开放, https://job.toutiao.com/s/8evt3VN 高性能计算架构:北京/上海/杭州/深圳职位开放,https://job.toutiao.com/s/8eckuNQ参考资料: [1] Yawei Li, Kai Zhang, Luc Van Gool, Radu Timofte, et al. Ntire 2022 challenge on efficient super-resolution: Methods and results. In IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2022. [2] Zheng Hui, Xinbo Gao, Yunchu Yang, and Xiumei Wang. Lightweight image super-resolution with information multi-distillation network. In Proceedings of the ACM International Conference on Multimedia, pages 2024–2032, 2019. [3] Jie Liu, Jie Tang, and Gangshan Wu. Residual feature distillation network for lightweight image super-resolution. In European Conference on Computer Vision Workshops, pages41–55. Springer, 2020. [4] Yanbo Wang, Shaohui Lin, Yanyun Qu, Haiyan Wu, Zhizhong Zhang, Yuan Xie, and Angela Yao. Towards compact single image super-resolution via contrastive self-distillation. In Zhi-Hua Zhou, editor, Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI 2021, Virtual Event / Montreal, Canada, 19-27 August 2021, pages 1122–1128. 2021. [5] Haiyan Wu, Yanyun Qu, Shaohui Lin, Jian Zhou, Ruizhi Qiao, Zhizhong Zhang, Yuan Xie, and Lizhuang Ma. Contrastive learning for compact single image dehazing. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021, pages 10551–10560. Computer Vision Foundation / IEEE, 2021.返回搜狐,查看更多 |

【本文地址】