| Java实现冒泡排序(原理过程+代码实现) | 您所在的位置:网站首页 › 冒泡排序实现原理 › Java实现冒泡排序(原理过程+代码实现) |
Java实现冒泡排序(原理过程+代码实现)
|
一.排序算法的历史:
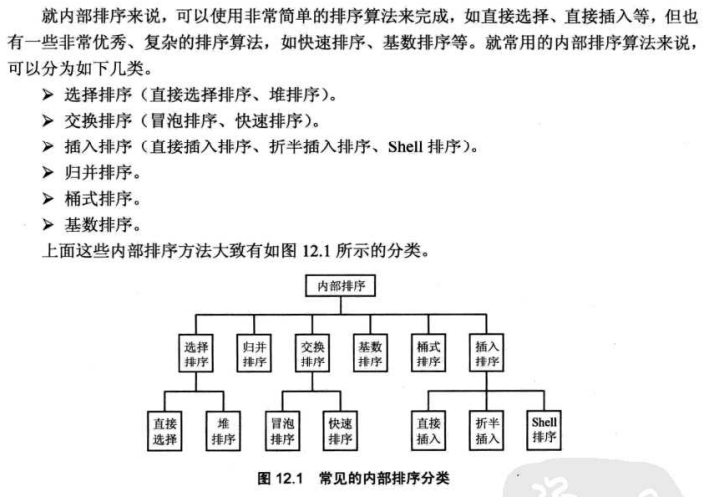
排序算法的发展历史几乎和计算机的发展历史一样悠久,而且直到今天,世界范围内依然有计算机科学家正在研究着排序的算法,由此可见排序算法的强大魅力. 我们现在介绍的排序算法都是前任研究的经典成果,具有极高的学习价值和借鉴意义. 排序算法属于算法的一种,而且是覆盖范围极小的一种,虽然排序算法是计算机科学里古老而且研究人数相当多的一张算法,但千万不要把排序算法和广义的计算机算法等同起来,掌握排序算法对程序开发,程序思维的培养都有很大的帮助,但掌握排序算法绝不等于掌握了计算机编程算法的全部.广义的算法包括客观世界的运行规律. 二.排序的目的是查找 和 衡量排序算法的标准一旦将一组杂乱无章的记录重排成一组有序记录,就能快速的从这组记录中找到目标记录.因此通常来说,排序的目的是快速查找. 对于一个排序算法来说,一般从个如下三个方面来衡量算法的优劣. 1.时间复杂度:主要是分析关键字的比较次数和记录的移动次数. 2.空间复杂度:分析排序算法中需要多少辅助内存. 3.稳定性:若两个记录A和B的关键值相等,但排序后A,B的先后次序保持不变,则称这种排序算法是稳定的,反之,就是不稳定的. 三.排序的分类(内部排序和外部排序)就现有的排序算法来看,排序大致可以分为内部排序和外部排序. 1.外部排序如果参与排序的数据元素非常多,数据量非常大,计算机无法把整个排序过程放在内存中完成,必须借助于外部存储器(如磁盘),这种排序就被称为外部排序. 外部排序最常用的算法是多路归并排序,即将源文件分解成多个能够一次性装入内存的部分,分别把每一部分调入内存完成排序,接下来再对多个有序的子文件进行归并排序. (一)外部排序包括以下两个步骤:1.把要排序的文件中的一组记录读入内存的排序区,对读入的记录按上面讲到的内部排序法进行排序,排序之后输出到外部存储器,不断的重复这个过程,每次读取一组记录,直到源文件的所有记录被处理完毕. 2.将上一步分组排序好的记录两组两组的合并排序,在内存容量允许的条件下,每组中包含的记录越大越好,这样可以减少合并的次数. 对于外部排序来说,程序必须将数据分批调入内存来排序,中间结果还要及时放入外存,显然外部排序要比内部排序更复杂,实际上,也可以认为外部排序是由多次内部排序组成的.常说的排序都是指的内部排序,而不是外部排序. 2.内部排序:如果整个排序过程不需要借助外部存储器(如磁盘),这种排序就被称为内部排序. (一) 内部排序的分类:①选择排序(直接选择排序,堆排序) ②交换排序(冒泡排序,快速排序) ③插入排序(直接插入排序,折半插入排序,Shell排序) ④归并排序 ⑤桶式排序 ⑥基数排序
从图中可以看出,常见的内部排序大致可以分为6大类,具体有10种排序方法. 四.冒泡排序 (一)冒泡排序的过程冒泡排序是最广为人知的交换排序之一,它具有算法思路简单,容易实现的特点. 对于包含n个数据的一组记录,在最坏的情况下,冒泡排序需要进行n-1趟比较. 第1趟:一次比较0和1,1和2,2和3....n-2和n-1索引处的元素,如果发现第一个数据大于后一个数据,则交换它们. 经过第1趟比较,最大的元素排到了最后. 第2趟:一次比较0和1,1和2,2和3....n-3和n-2索引处的元素, 如果发现第一个数据大于后一个数据,则交换它们. 经过第2趟比较,第2大的元素排到了倒数第2位. ........ 第n-1趟:依次比较0和1元素,如果发现第一个数据大于后一个数据,则交换它们. 经过第n-1趟比较,第2小(第n-1大)的元素排到了第2位. 实际上,冒泡排序的每趟交换结束后,不仅能将当前最大值挤出最后面位置,还能部分理顺前面的其他元素,一旦某趟没有交换发生,即可提前结束排序. (二) 冒泡排序具体举例:假设有如下数据序列: 9,16,21*,23,30,49,21,30* 只需要经过如下几趟排序. 第1趟:9,16,21*,23,30,21,30*,49 第2趟:9,16,21*,23,21,30,30*,49 第3趟:9,16,21*,21,23,30,30*,49 第4趟:9,16,21*,21,23,30,30*,49 从上面的排序过程可以看出,虽然该数组包含8个元素,但是采用冒泡排序只需要经过4趟比较.因为第3趟排序之后,这组数据已经处于有序状态.这样,第4趟将不会发生交换,因此可以提前结束循环. (三)冒泡排序的具体代码冒泡排序的示例程序如下: 上代码: 1 package cn.summerchill.sort; 2 3 // 定义一个数据包装类 4 class DataWrap implements Comparable { 5 int data; 6 String flag; 7 8 public DataWrap(int data, String flag) { 9 this.data = data; 10 this.flag = flag; 11 } 12 13 public String toString() { 14 return data + flag; 15 } 16 17 // 根据data实例变量来决定两个DataWrap的大小 18 public int compareTo(DataWrap dw) { 19 return this.data > dw.data ? 1 : (this.data == dw.data ? 0 : -1); 20 } 21 } 22 23 public class BubbleSort { 24 public static void bubbleSort(DataWrap[] data) { 25 System.out.println("开始排序"); 26 int arrayLength = data.length; 27 for (int i = 0; i < arrayLength - 1; i++) { 28 boolean flag = false; 29 for (int j = 0; j < arrayLength - 1 - i; j++) { 30 // 如果j索引处的元素大于j+1索引处的元素 31 if (data[j].compareTo(data[j + 1]) > 0) { 32 // 交换它们 33 DataWrap tmp = data[j + 1]; 34 data[j + 1] = data[j]; 35 data[j] = tmp; 36 flag = true; 37 } 38 } 39 System.out.println(java.util.Arrays.toString(data)); 40 // 如果某趟没有发生交换,则表明已处于有序状态 41 if (!flag) { 42 break; 43 } 44 } 45 } 46 47 public static void main(String[] args) { 48 DataWrap[] data = { new DataWrap(9, ""), new DataWrap(16, ""), 49 new DataWrap(21, "*"), new DataWrap(23, ""), 50 new DataWrap(30, ""), new DataWrap(49, ""), 51 new DataWrap(21, ""), new DataWrap(30, "*") }; 52 System.out.println("排序之前:\n" + java.util.Arrays.toString(data)); 53 bubbleSort(data); 54 System.out.println("排序之后:\n" + java.util.Arrays.toString(data)); 55 } 56 }运行上面的程序,将看到如图所示的排序过程. 排序之前: [9, 16, 21*, 23, 30, 49, 21, 30*] 开始排序 [9, 16, 21*, 23, 30, 21, 30*, 49] [9, 16, 21*, 23, 21, 30, 30*, 49] [9, 16, 21*, 21, 23, 30, 30*, 49] [9, 16, 21*, 21, 23, 30, 30*, 49] 排序之后: [9, 16, 21*, 21, 23, 30, 30*, 49]冒泡排序算法的时间效率是不确定的.在最好的情况下,初始数据序列已经处于有序状态,执行1趟冒泡即可,做n-1次比较.无须进行任何交换. 但在最坏的情况下,初始数据序列处于完全逆序状态,算法要执行n-1趟冒泡,第i趟(1 |
【本文地址】