| 关联规则 | 您所在的位置:网站首页 › 关联规则挖掘算法r煤炭分析 › 关联规则 |
关联规则
|
一、关联规则简介
关联规则挖掘是一种基于规则的机器学习算法,该算法可以在大数据库中发现感兴趣的关系。它的目的是利用一些度量指标来分辨数据库中存在的强规则。也即是说关联规则挖掘是用于知识发现,而非预测,所以是属于无监督的机器学习方法。 Apriori算法是一种挖掘关联规则的频繁项集算法,其核心思想是通过候选集生成和情节的向下封闭检测两个阶段来挖掘频繁项集。 关联规则的一般步骤: 1、找到频繁集; 2、在频繁集中通过可信度筛选获得关联规则。 关联规则应用: 1、Apriori算法应用广泛,可用于消费市场价格分析,猜测顾客的消费习惯,比如较有名的“尿布和啤酒”的故事; 2、网络安全领域中的入侵检测技术; 3、可用在用于高校管理中,根据挖掘规则可以有效地辅助学校管理部门有针对性的开展贫困助学工作; 4、也可用在移动通信领域中,指导运营商的业务运营和辅助业务提供商的决策制定。 关联规则算法的主要应用是购物篮分析,是为了从大量的订单中发现商品潜在的关联。其中常用的一个算法叫Apriori先验算法。 1、关联规则-概念关联分析(Association Analysis):在大规模数据集中寻找有趣的关系。 频繁项集(Frequent Item Sets):经常出现在一块的物品的集合,即包含0个或者多个项的集合称为项集。 支持度(Support):数据集中包含该项集的记录所占的比例,是针对项集来说的。 1、支持度(Support) 支持度揭示了A与B同时出现的概率。如果A与B同时出现的概率小,说明A与B的关系不大;如果A与B同时出现的非常频繁,则说明A与B总是相关的。 支持度: P(A∪B),即A和B这两个项集在事务集D中同时出现的概率。
首先我们把上面案例中的商品用 ID 来代表,牛奶、面包、尿布、可乐、啤酒、鸡蛋的商品 ID 分别设置为 1-6,上面的数据表可以变为: 首先,我们先计算单个商品的支持度,也就是得到 K=1 项的支持度: 在这个基础上,我们将商品两两组合,得到 k=2 项的支持度: 再筛掉小于最小值支持度的商品组合,可以得到: 通过上面这个过程,我们可以得到 K=3 项的频繁项集{1,2,3},也就是{牛奶、面包、尿布}的组合。 (3) Apriori 算法的递归流程:Apriori 算法的递归流程: 1、K=1,计算 K 项集的支持度; 2、筛选掉小于最小支持度的项集; 3、如果项集为空,则对应 K-1 项集的结果为最终结果。 否则 K=K+1,重复 1-3 步。 Apriori 的改进算法:FP-Growth 算法Apriori 在计算的过程中有以下几个缺点:1、可能产生大量的候选集。因为采用排列组合的方式,把可能的项集都组合出来了;2、每次计算都需要重新扫描数据集,来计算每个项集的支持度。所以 Apriori 算法会浪费很多计算空间和计算时间,为此人们提出了 FP-Growth 算法:1、创建了一棵 FP 树来存储频繁项集。在创建前对不满足最小支持度的项进行删除,减少了存储空间。2、整个生成过程只遍历数据集 2 次,大大减少了计算量。所以在实际工作中,我们常用 FP-Growth 来做频繁项集的挖掘,下面我给你简述下 FP-Growth 的原理。 (1)FP Tree数据结构为了减少I/O次数,FP Tree算法引入了一些数据结构来临时存储数据。这个数据结构包括三部分,如下图所示: 下面我们讲项头表和FP树的建立过程。 (2)项头表的建立FP树的建立需要首先依赖项头表的建立。首先我们看看怎么建立项头表。 我们第一次扫描数据,得到所有频繁一项集的的计数。然后删除支持度低于阈值的项,将1项频繁集放入项头表,并按照支持度降序排列。接着第二次也是最后一次扫描数据,将读到的原始数据剔除非频繁1项集,并按照支持度降序排列。 上面这段话很抽象,我们用下面这个例子来具体讲解。我们有10条数据,首先第一次扫描数据并对1项集计数,我们发现F,O,I,L,J,P,M, N都只出现一次,支持度低于20%的阈值,因此他们不会出现在下面的项头表中。剩下的A,C,E,G,B,D,F按照支持度的大小降序排列,组成了我们的项头表。 接着我们第二次扫描数据,对于每条数据剔除非频繁1项集,并按照支持度降序排列。比如数据项ABCEFO,里面O是非频繁1项集,因此被剔除,只剩下了ABCEF。按照支持度的顺序排序,它变成了ACEBF。其他的数据项以此类推。为什么要将原始数据集里的频繁1项数据项进行排序呢?这是为了我们后面的FP树的建立时,可以尽可能的共用祖先节点。 通过两次扫描,项头表已经建立,排序后的数据集也已经得到了,下面我们再看看怎么建立FP树。
有了项头表和排序后的数据集,我们就可以开始FP树的建立了。开始时FP树没有数据,建立FP树时我们一条条的读入排序后的数据集,插入FP树,插入时按照排序后的顺序,插入FP树中,排序靠前的节点是祖先节点,而靠后的是子孙节点。如果有共用的祖先,则对应的公用祖先节点计数加1。插入后,如果有新节点出现,则项头表对应的节点会通过节点链表链接上新节点。直到所有的数据都插入到FP树后,FP树的建立完成。 似乎也很抽象,我们还是用第二节的例子来描述。 首先,我们插入第一条数据ACEBF,如下图所示。此时FP树没有节点,因此ACEBF是一个独立的路径,所有节点计数为1, 项头表通过节点链表链接上对应的新增节点。 我们辛辛苦苦,终于把FP树建立起来了,那么怎么去挖掘频繁项集呢?看着这个FP树,似乎还是不知道怎么下手。下面我们讲如何从FP树里挖掘频繁项集。得到了FP树和项头表以及节点链表,我们首先要从项头表的底部项依次向上挖掘。对于项头表对应于FP树的每一项,我们要找到它的条件模式基。所谓条件模式基是以我们要挖掘的节点作为叶子节点所对应的FP子树。得到这个FP子树,我们将子树中每个节点的的计数设置为叶子节点的计数,并删除计数低于支持度的节点。从这个条件模式基,我们就可以递归挖掘得到频繁项集了。 实在太抽象了,之前我看到这也是一团雾水。还是以上面的例子来讲解。我们看看先从最底下的F节点开始,我们先来寻找F节点的条件模式基,由于F在FP树中只有一个节点,因此候选就只有下图左所示的一条路径,对应{A:8,C:8,E:6,B:2, F:2}。我们接着将所有的祖先节点计数设置为叶子节点的计数,即FP子树变成{A:2,C:2,E:2,B:2, F:2}。一般我们的条件模式基可以不写叶子节点,因此最终的F的条件模式基如下图右所示。 F挖掘完了,我们开始挖掘D节点。D节点比F节点复杂一些,因为它有两个叶子节点,因此首先得到的FP子树如下图左。我们接着将所有的祖先节点计数设置为叶子节点的计数,即变成{A:2, C:2,E:1 G:1,D:1, D:1}此时E节点和G节点由于在条件模式基里面的支持度低于阈值,被我们删除,最终在去除低支持度节点并不包括叶子节点后D的条件模式基为{A:2, C:2}。通过它,我们很容易得到F的频繁2项集为{A:2,D:2}, {C:2,D:2}。递归合并二项集,得到频繁三项集为{A:2,C:2,D:2}。D对应的最大的频繁项集为频繁3项集。
至此我们得到了所有的频繁项集,如果我们只是要最大的频繁K项集,从上面的分析可以看到,最大的频繁项集为5项集。包括{A:2, C:2, E:2,B:2,F:2}。 通过上面的流程,相信对FP Tree的挖掘频繁项集的过程也很熟悉了。 (5)FP Tree算法归纳这里我们对FP Tree算法流程做一个归纳。FP Tree算法包括三步: 1)扫描数据,得到所有频繁一项集的的计数。然后删除支持度低于阈值的项,将1项频繁集放入项头表,并按照支持度降序排列。 2)扫描数据,将读到的原始数据剔除非频繁1项集,并按照支持度降序排列。 3)读入排序后的数据集,插入FP树,插入时按照排序后的顺序,插入FP树中,排序靠前的节点是祖先节点,而靠后的是子孙节点。如果有共用的祖先,则对应的公用祖先节点计数加1。插入后,如果有新节点出现,则项头表对应的节点会通过节点链表链接上新节点。直到所有的数据都插入到FP树后,FP树的建立完成。 4)从项头表的底部项依次向上找到项头表项对应的条件模式基。从条件模式基递归挖掘得到项头表项项的频繁项集。 5)如果不限制频繁项集的项数,则返回步骤4所有的频繁项集,否则只返回满足项数要求的频繁项集。 (6)FP tree算法总结FP Tree算法改进了Apriori算法的I/O瓶颈,巧妙的利用了树结构,这让我们想起了BIRCH聚类,BIRCH聚类也是巧妙的利用了树结构来提高算法运行速度。利用内存数据结构以空间换时间是常用的提高算法运行时间瓶颈的办法。 在实践中,FP Tree算法是可以用于生产环境的关联算法,而Apriori算法则做为先驱,起着关联算法指明灯的作用。除了FP Tree,像GSP,CBA之类的算法都是Apriori派系的。 |

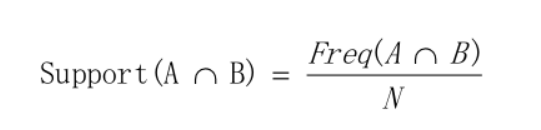 置信度(Confidence):出现某些物品时,另外一些物品必定出现的概率,针对规则而言。 关联规则(Association Rules):暗示两个物品之间可能存在很强的关系。形如A->B的表达式,规则A->B的度量包括支持度和置信度 项集支持度:一个项集出现的次数与数据集所有事物数的百分比称为项集的支持度
置信度(Confidence):出现某些物品时,另外一些物品必定出现的概率,针对规则而言。 关联规则(Association Rules):暗示两个物品之间可能存在很强的关系。形如A->B的表达式,规则A->B的度量包括支持度和置信度 项集支持度:一个项集出现的次数与数据集所有事物数的百分比称为项集的支持度 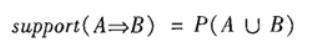 支持度反映了A和B同时出现的概率,关联规则的支持度等于频繁集的支持度。 项集置信度:包含A的数据集中包含B的百分比
支持度反映了A和B同时出现的概率,关联规则的支持度等于频繁集的支持度。 项集置信度:包含A的数据集中包含B的百分比 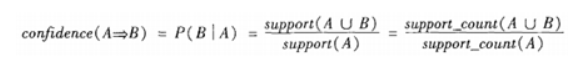 置信度反映了如果交易中包含A,则交易包含B的概率。也可以称为在A发生的条件下,发生B的概率,成为条件概率。 只有支持度和置信度(可信度)较高的关联规则才是用户感兴趣的。 提升度 (Lift):提升度表示先购买A对购买B的概率的提升作用,用来判断规则是否有实际价值,即使用规则后商品在购物车中出现的次数是否高于商品单独出现在购物车中的频率。如果大于1说明规则有效,小于1则无效。公式:
置信度反映了如果交易中包含A,则交易包含B的概率。也可以称为在A发生的条件下,发生B的概率,成为条件概率。 只有支持度和置信度(可信度)较高的关联规则才是用户感兴趣的。 提升度 (Lift):提升度表示先购买A对购买B的概率的提升作用,用来判断规则是否有实际价值,即使用规则后商品在购物车中出现的次数是否高于商品单独出现在购物车中的频率。如果大于1说明规则有效,小于1则无效。公式: 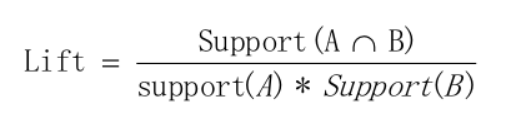
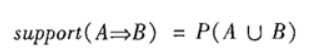 2、可信度(Confidence) 置信度揭示了A出现时,B是否也会出现或有多大概率出现。如果置信度度为100%,则A和B可以捆绑销售了。如果置信度太低,则说明A的出现与B是否出现关系不大。 置信度: P(B|A),即在出现项集A的事务集D中,项集B也同时出现的概率。
2、可信度(Confidence) 置信度揭示了A出现时,B是否也会出现或有多大概率出现。如果置信度度为100%,则A和B可以捆绑销售了。如果置信度太低,则说明A的出现与B是否出现关系不大。 置信度: P(B|A),即在出现项集A的事务集D中,项集B也同时出现的概率。 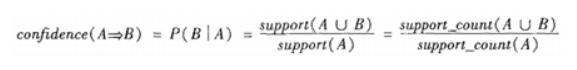 3、设定合理的支持度和置信度 对于某条规则:(A = a)−>(B = b)(support=30%,confident=60%);其中support=30%表示在所有的数据记录中,同时出现A=a和B=b的概率为30%;confident=60%表示在所有的数据记录中,在出现A=a的情况下出现B=b的概率为60%,也就是条件概率。支持度揭示了A=a和B=b同时出现的概率,置信度揭示了当A=a出现时,B=b是否会一定出现的概率。 (1)如果支持度和置信度闭值设置的过高,虽然可以减少挖掘时间,但是容易造成一些隐含在数据中非频繁特征项被忽略掉,难以发现足够有用的规则; (2)如果支持度和置信度闭值设置的过低,又有可能产生过多的规则,甚至产生大量冗余和无效的规则,同时由于算法存在的固有问题,会导致高负荷的计算量,大大增加挖掘时间。
3、设定合理的支持度和置信度 对于某条规则:(A = a)−>(B = b)(support=30%,confident=60%);其中support=30%表示在所有的数据记录中,同时出现A=a和B=b的概率为30%;confident=60%表示在所有的数据记录中,在出现A=a的情况下出现B=b的概率为60%,也就是条件概率。支持度揭示了A=a和B=b同时出现的概率,置信度揭示了当A=a出现时,B=b是否会一定出现的概率。 (1)如果支持度和置信度闭值设置的过高,虽然可以减少挖掘时间,但是容易造成一些隐含在数据中非频繁特征项被忽略掉,难以发现足够有用的规则; (2)如果支持度和置信度闭值设置的过低,又有可能产生过多的规则,甚至产生大量冗余和无效的规则,同时由于算法存在的固有问题,会导致高负荷的计算量,大大增加挖掘时间。
 Apriori 算法其实就是查找频繁项集 (frequent itemset) 的过程,所以首先我们需要定义什么是频繁项集。频繁项集就是支持度大于等于最小支持度 (Min Support) 阈值的项集,所以小于最小值支持度的项目就是非频繁项集,而大于等于最小支持度的的项集就是频繁项集。项集这个概念,英文叫做 itemset,它可以是单个的商品,也可以是商品的组合。我们再来看下这个例子,假设我随机指定最小支持度是 50%,也就是 0.5。
Apriori 算法其实就是查找频繁项集 (frequent itemset) 的过程,所以首先我们需要定义什么是频繁项集。频繁项集就是支持度大于等于最小支持度 (Min Support) 阈值的项集,所以小于最小值支持度的项目就是非频繁项集,而大于等于最小支持度的的项集就是频繁项集。项集这个概念,英文叫做 itemset,它可以是单个的商品,也可以是商品的组合。我们再来看下这个例子,假设我随机指定最小支持度是 50%,也就是 0.5。 因为最小支持度是 0.5,所以你能看到商品 4、6 是不符合最小支持度的,不属于频繁项集,于是经过筛选商品的频繁项集就变成:
因为最小支持度是 0.5,所以你能看到商品 4、6 是不符合最小支持度的,不属于频繁项集,于是经过筛选商品的频繁项集就变成: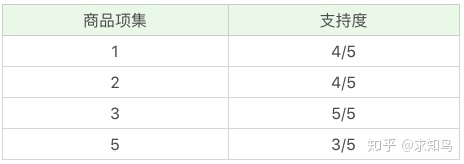
 我们再筛掉小于最小值支持度的商品组合,可以得到:
我们再筛掉小于最小值支持度的商品组合,可以得到: 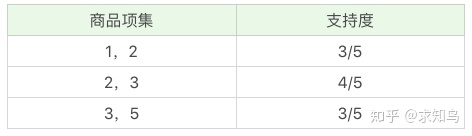 我们再将商品进行 K=3 项的商品组合,可以得到:
我们再将商品进行 K=3 项的商品组合,可以得到: 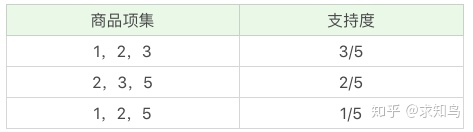


 第一部分是一个项头表。里面记录了所有的1项频繁集出现的次数,按照次数降序排列。比如上图中B在所有10组数据中出现了8次,因此排在第一位,这部分好理解。第二部分是FP Tree,它将我们的原始数据集映射到了内存中的一颗FP树,这个FP树比较难理解,它是怎么建立的呢?这个我们后面再讲。第三部分是节点链表。所有项头表里的1项频繁集都是一个节点链表的头,它依次指向FP树中该1项频繁集出现的位置。这样做主要是方便项头表和FP Tree之间的联系查找和更新,也好理解。
第一部分是一个项头表。里面记录了所有的1项频繁集出现的次数,按照次数降序排列。比如上图中B在所有10组数据中出现了8次,因此排在第一位,这部分好理解。第二部分是FP Tree,它将我们的原始数据集映射到了内存中的一颗FP树,这个FP树比较难理解,它是怎么建立的呢?这个我们后面再讲。第三部分是节点链表。所有项头表里的1项频繁集都是一个节点链表的头,它依次指向FP树中该1项频繁集出现的位置。这样做主要是方便项头表和FP Tree之间的联系查找和更新,也好理解。
 接着我们插入数据ACG,如下图所示。由于ACG和现有的FP树可以有共有的祖先节点序列AC,因此只需要增加一个新节点G,将新节点G的计数记为1。同时A和C的计数加1成为2。当然,对应的G节点的节点链表要更新
接着我们插入数据ACG,如下图所示。由于ACG和现有的FP树可以有共有的祖先节点序列AC,因此只需要增加一个新节点G,将新节点G的计数记为1。同时A和C的计数加1成为2。当然,对应的G节点的节点链表要更新  同样的办法可以更新后面8条数据,如下8张图。由于原理类似,这里就不多文字讲解了,大家可以自己去尝试插入并进行理解对比。相信如果大家自己可以独立的插入这10条数据,那么FP树建立的过程就没有什么难度了。
同样的办法可以更新后面8条数据,如下8张图。由于原理类似,这里就不多文字讲解了,大家可以自己去尝试插入并进行理解对比。相信如果大家自己可以独立的插入这10条数据,那么FP树建立的过程就没有什么难度了。







 通过它,我们很容易得到F的频繁2项集为{A:2,F:2}, {C:2,F:2}, {E:2,F:2}, {B:2,F:2}。递归合并二项集,得到频繁三项集为{A:2,C:2,F:2},{A:2,E:2,F:2},…还有一些频繁三项集,就不写了。当然一直递归下去,最大的频繁项集为频繁5项集,为{A:2,C:2,E:2,B:2,F:2}
通过它,我们很容易得到F的频繁2项集为{A:2,F:2}, {C:2,F:2}, {E:2,F:2}, {B:2,F:2}。递归合并二项集,得到频繁三项集为{A:2,C:2,F:2},{A:2,E:2,F:2},…还有一些频繁三项集,就不写了。当然一直递归下去,最大的频繁项集为频繁5项集,为{A:2,C:2,E:2,B:2,F:2} 同样的方法可以得到B的条件模式基如下图右边,递归挖掘到B的最大频繁项集为频繁4项集{A:2, C:2, E:2,B:2}。
同样的方法可以得到B的条件模式基如下图右边,递归挖掘到B的最大频繁项集为频繁4项集{A:2, C:2, E:2,B:2}。 继续挖掘G的频繁项集,挖掘到的G的条件模式基如下图右边,递归挖掘到G的最大频繁项集为频繁4项集{A:5, C:5, E:4,G:4}。
继续挖掘G的频繁项集,挖掘到的G的条件模式基如下图右边,递归挖掘到G的最大频繁项集为频繁4项集{A:5, C:5, E:4,G:4}。 E的条件模式基如下图右边,递归挖掘到E的最大频繁项集为频繁3项集{A:6, C:6, E:6}。
E的条件模式基如下图右边,递归挖掘到E的最大频繁项集为频繁3项集{A:6, C:6, E:6}。 C的条件模式基如下图右边,递归挖掘到C的最大频繁项集为频繁2项集{A:8, C:8}。
C的条件模式基如下图右边,递归挖掘到C的最大频繁项集为频繁2项集{A:8, C:8}。 至于A,由于它的条件模式基为空,因此可以不用去挖掘了。
至于A,由于它的条件模式基为空,因此可以不用去挖掘了。【本文地址】