| 论文阅读 | 您所在的位置:网站首页 › 关于FPGA的论文 › 论文阅读 |
论文阅读
|
论文阅读之FPGA硬件加速Review FPGA-based Accelerators of Deep Learning Networks for Learning and Classification: A Review 时间:2019 本文聚焦于使用FPGA进行CNN的加速,主要总结了近期深度学习框架的FPGA加速器,希望能为深度学习研究者研究有效的硬件加速器指明方向。 关键词主要有:自适应框架、卷积神经网络,深度学习,动态配置,高能效架构,FPGA,硬件加速器,机器学习,神经网络,优化,并行计算,可重构计算 Section I Introduction深度学习关键的一点是网络的权重不是人为设计的,而是通过一系列学习策略获取的。通过基于数据的学习,神经网络可以自己做出决策。 而在深度学习中,网络每一层都被用于探测不同层次的特征,浅层次表征从图像、文本中学习到的具体特征,深层次表征更为抽象的特征。越深层次对应的感受野越大,而深层次特征对于识别以及抑制不相关的扰动更为重要。 目前CNN和DNN可应用于字母识别、手势识别、语言识别(Siri)、文件处理、NLP、视频识别、图像分类、面部识别、机器人导航、实时多目标追踪、投资预测、医学诊断系统等。最近的一些研究领域包括自动驾驶、安防以及电子系统。 Part B介绍DL的起源 Part C简要对比了硬件加速器 随着网络的加深,CNN涉及到大量的参数 实际应用中就是将训练好的网络参数固定下来进行网络的推断 在训练和分类过程中最多用GPU加速,并行化成都很高但GPU能耗大 FPGA和ASIC硬件加速器虽然IO\MEMORY等资源有限,但是能耗低。其中ASIC又不如FPGA灵活,因此本文主要review了CNN的FPGA加速器,强调了现存的问题、未来的方向。 Section II 背景及术语 Part A卷积神经网络相关 CONV卷积CONV:可以看做是原图和一个比原图矩阵更小的矩阵以滑窗的形式做成绩来产生每一个输出神经元,filter的值被称为权重或参数,当filter在特征图上滑过会计算每一个像素的卷积(乘加运算)来禅城最终的一个输出。输入和输出都是一系列特征图的序列。 通常filter的尺寸不会太大(小于11*11)以及不同卷积层的尺寸通常是不一样大小的。 卷积操作涉及到四层循环(参见上一篇博客) Activation总结了tanh relu等,目的是为了实现非线性变换 Normalization侧向抑制Lateral inhibition:邻近细胞间的相互抑制,通过抑制性中间神经元来实现 CNN中通过normalization层实现局部响应归一化,使得高频特征相应更大,因此该激活神经元比邻近神经元更为敏感(主要就是为了让激活的神经元更加突出) 归一化可以在同一特征实现也可以在临近神经元的特征图实现 Pooling也叫做下采样,主要用来减少特征图谱的大小,从而降低网络的参数量和计算量,通常在连续的conv层中插入,最常见的是2*2大小的做大池化,这样可以丢掉75%的参数,常用的池化有最大池化、均值池化及MIN池化 FCs在经过卷积->relu->pooling之后会引入1至多层的全连接层,全连接层做的是内积运算(inner product) 也就是输出的不再是向量而是一个数值,最后一层FC的数目则是分类的类别数目,用以计算分类得分等 PartB 深度学习网络简介AlexNet是2012年提出的神经网络,包含5个卷积层,中间穿插2个归一化层,最后经过3个FC得到输出,每一层conv后都会经过ReLU激活。AlexNet是2012年ILSVRC ImageNet1000分类比赛的冠军(image size =224 * 224) FPGA现场可编程逻辑阵列主要有一系列可编程逻辑单元(CLBs)组成,除此之外还有丰富的嵌入式元件,如DSP(主要做密集运算)、BRAMs、查找表(LUTs)、FlipFlops、时钟管理单元以及高速的IO等。 考虑FPGA用于神经网路加速主要是因为可以实现并行化的密集运算,并且灵活可配置,获得最大化的能效。FPGA可以为卷积运算设计出统一的硬件电路,支持流水线及多线程。现阶段OpenCL等标准使得CNN部署在FPGA上更加高效和方便。 FPGA用于神经网络加速的主要挑战在于:网络的存储、外部存储的尾款以及片上的运算资源。 以AlexNet为例,网络参数6千万,以32位浮点数存储需要250MB的memory,每张输入图片涉及到15亿次运算,现有任何一款FPGA都无法完全存储,必须依赖外存的介入,因此完成CNN在FPGA上的部署需要合理的分配资源完成资源利用率的最大化。 而更复杂的网络情况则更为严重,如VGG-16有16层,参数量达到了138million,虽然现在的一种趋势是减少数据位宽,但为了解决海量的数据以及实际问题,神经网络只会越来越复杂。 除此之外,CNN不同层的并行化设计、对内存的访问也不同。主要分为层内并行和层间并行。层内并行主要涉及同一层n个卷积核的输出;层间并行则是并行计算不同的特征图谱。 除此之外CNN不同层的计算量也不同,如VGG卷积层是运算密集层,权重参数量相对较少;而FC层运算不密集但是涉及到大量参数,因此需要针对网络不同层进行硬件设计已达到最优的资源利用率。 随着技术的发展,FPGA的片上资源及算力也获得了提升,但由于计算资源的有限,在部署神经网络的过程中需要复用计算资源,因此数据传输及计算资源的配置就显得尤为重要。通过合理的调度可以有效减少运算次数以及对外存的访问次数;而在不影响精度的前提下尽量缩减权重位宽、对FC层的大量参数使用奇异值分解(SVD)也可有效减少对外存的需求;结合数据复用、片上存储可有效减少访问外存的时间。 Section III Related Works本节主要总结CNN加速的相关研究进展。 Part A CNN Compression对CNN网络的压缩策略主要有: (1)权重矩阵的SVD奇异值分解来降维 (2)通过网络的剪枝来减少网络参数、降低过拟合。通过修剪掉冗余的连接可以在不影响精度的前提下将AlexNet/VGGNet的参数量分别压缩9x/13x。 (3)通过增强权值共享进一步压缩权重 Part B ASIC Accelerator主要加速策略有: (1)减少数据传输 (2)使用更少位数的定点数来表征feature map和权重 (3)使用DaDianNao、PuDianNao等多核为CNN提供足够的片上存储,但ASIC的设计流程长,灵活性差 Part C FPGA Accelerator这也是本文的主要内容,就FPGA加速器进行综述及对比分析。 主要分为: CNN的硬件实现:conv FC CNN的硬件实现工具: CNN的设计方法优化: Farabet:提出卷积网络处理器CNP,使用片上DSP+8路数据读取用于卷积运算的并行化。CNP可以实现2D卷积、pooling以及非线性激活。CNP使用了16bit定点数搭建了LeNet-5用于人脸检测,资源利用率:逻辑单元(90%)/乘法器(28%) DeepBurning是一款FPGA自动设计工具,可以根据片上存储的大小、网络的规模设计出特定网络的最佳硬件实现。 设计方法Zhang:分析了conv层和FC层矩阵乘法的规律,发现VGG16中对于输入的特征图谱复制了25x,因此提出了IMM和WMM的输入/权重匹配策略,IMM会将同一输入的特征图谱们一次灌入在做运算,提成了FC层的数据复用;WMM策略考虑到FC层中权重参数远远多于输入数据因此将input存入weight buffer而降weight存入input buffer,提成了input的复用率。并且验证了WMM比IMM更有效。 并且提出了一个软硬件协同设计的库-Caffeine.通过高级综合的方式完成硬件的配置,如PE的数目,精度,featuremap的尺寸等。也使用了double-buffer的技术来预取下一个PE的数据。 SDF:通过SDF图,每一个节点代表一个硬件实现,数据到来后执行相应的计算,动过DSL处理器将CNN描述转化为DAG图再转变为SDF图,就可以显示出并行的数据流、数据流的位宽等信息。 fpgaConvNet: coarse-grained folding:粗粒度上会将conv\pooling\non-linear等的每一层用多个计算单元展开来提升并行程度 fine-grained folding:细粒度则是决定点乘等操作的流水线级数。 通过调节unroll factor展开系数以及MUX的级数可以平衡性能和所需的硬件资源,最终生成配置好PE和buffer的HLS 硬件描述。 最终fpgaConvNet硬件实现了LeNet-5,比CNP策略加速了1.62x;在labelling CNN中是GPU能效的1.05x. fpgaConvNet_improved:通过调整workload进一步优化了吞吐率和延时。由于片上存储资源有限,无法将某一层的全部参数存够,因此引入了一个折叠因子folding factor,将权重分为fin份,每一个subgraph输出一个部分的featuremap.最终实现了Alexnet和VGG-16. FP-DNN:是一个端到端的框架,通过RTL-HLS自动生成DNN优化后的FPGA框架,主要包含model mapper模型匹配器,software generator软件生成器,hardware generator硬件生成器。FPDNN通过片外DRAM存储中间数据、权重以及模型参数和配置。model mapper会尽量减少物理buffer是使用以便最大化复用资源;software gemerator主要完成模型的建立、数据缓存的管理以及配置核;Hardware generator通过配置核核graph;来生成FPGA代码。 FP-DNN中通过将输入向量一批一批合在一起实现FC层,feature maps和权重会按照channel-major的策略在DRAM中重新排布,浮点数和定点数均支持。 FP-DNN测试了VGG-19、ResNet152及LSTM网络的硬件实现,其中这是首次在FPGA上部署实现ResNet152 BNN的FPGA实现 FINN:BNN的FPGA实现。Umuroglu在网络规模和精度之间的平衡做了一系列的尝试。如为了在MNIST手写数据集上达到相似精度,二值神经网络扥参数量往往是一个8bit定点精CNN的2-11倍,但BNN比定点CNN网络要快16x。 因此Umuroglu提出了FINN将训练过的BNN部署在FPGA上。因为二值神经网络将权重及隐藏层激活值二值化为1或-1,因此FINN优化了BNN中的累加、BN、激活和池化操作。比如accumulation通过一个counter来实现减少了LUT的使用,FFs的数量也减半,更无须使用DSP。更多的是采用布尔代数的或、与逻辑。 FINN的核心结构是MVTU(matrix-vector-threshold unit)矩阵向量阈值单元,包括一个输入buffer,P个并行的PE以及一个输出buffer。权重矩阵就存储在PE胖的内存中。PE通过异或门计算输入向量和权重矩阵的点积,然后和预设的阈值进行比较,产生1bit的输出。 FINN通过滑窗单元(sliding window unit,SWU)完成卷积运算。最终在Zynq-7000的板子上验证了CNV用于CIFAR-10的推断。CNV结构快包含两个conv和两次最大池化,以上结构重复3次。 Zhang:通过分析VGG-19硬件实现的瓶颈发现,数据并行过程中OpenCL复制了大量冗余的片上BRAM,因此Zhang的工作主要根据模型的workload设计最佳的内存配置,该核包括一个compute subsystem*(CUs + PEs),memory subsystem以及一个2D dispacher.dispatcher负责主从设备之间的数据传输。亮点在于在PE和BRAM之间设计了一个多映射的连接,一个BRAM与多个PE有连接因此提高了片上BRAM的利用率 表II和表III总结了FPGA加速器的一些加速策略,包括提出的时间,策略的主要特征以及应用到的硬件平台,特征图的精度等信息,以及片上资源(如LUT、BRAMs、DSPs、FFs)的使用情况以及最终的加速比和能效。 Section IV 启发学习目前人们设计FPGA加速器往往需要确定一下事情: 卷积层的数目,FC层的数目,每层featuremap的大小,以及一些其他的操作。 FPGA加速器设计的一些启发:最近也有研究表明将FC层中大量参数去除对网络精度影响并不大。由于CNN的设计是一个NP-hard问题,因此人们尝试通过选择合适的权重、偏置等来提升网络精度以及缩短运行时间,下面总结一下经前人工作得到的一些启发。 Part A:CNN结构优化 Xie等人的工作通过遗传算法,摒弃错误率高的子代来优化网络结构,并在MNIST和CIFAR-10上进行了测试 Part B:CNN权重参数及偏置优化。通过启发式算法优化权重及偏置,实验的算法有:simulated annealing,differential evolution,harmony search。来优化最后一层的weights和bias。 Part C:CNN设计变量的优化。主要在于寻找最佳的设计变量的组合,如 filter的大小,分块的大小,一次循环中进行Norm的次数、pool的执行次数以及FC进行的次数等 Section V Summary全文总结本节主要强调在FPGA上加速实现CNN的一些关键点以及一些推荐选择。 优化核心是加速卷积运算,因为卷积操作占据了整个计算时间的90%。由于片上有限的计算资源必须提高计算的并行诚笃,除此之外还要尽量减少外部数据的读取时间,尤其是feature map和权重参数的读取,尽量减少外存的访问次数;另一方面还需考虑FC层权重参数的优化。 卷积运算的优化:workload analysis分析并行化,决定 循环的展开因子(unrollingfactor);以及通过循环的流水线划分进一步提升资源利用率;通过Winograd可以降低卷积层计算的复杂度;使用多个CLPs、把FMs分组输入等策略可以提升吞吐率(FC层输入前再合起来) 数据优化:通过DeepBurning工具的分析找出计算需求最大的部分,通过复用on-chip memory、降低位宽来减少数据的重复运算,最大化数据的复用程度;选择合理的量化方法。 存储优化:通过有效的利用double-buffering的策略尽可能较少idle time;确定合适的数据位宽提升on-chip memory的资源利用率 自动化设计工具:通过预先设计好的RTL库可以快速完成优化后的网络搭建,此类工具有:DeepBurning、ALAMO,可以通过网络的代码描述生成硬件描述,通过给定CNN的网络参数就可以完成硬部署;另一个方向是 提供通用CNN的优化工具而不只针对某种网络。 Section VI Conclusion本文主要对CNN的FPGA硬件加速进行综述。文章首先简要回顾了深度学习的起源及发展,重点介绍了卷积神经网络的主要操作及应用,尤其在图像识别及检测领域。由于涉及到大量的密集运算,FPGA天然的特性决定了其可以最大化的并行计算。 随后本文介绍了CNN在软件及硬件层面采用的加速方法,而对FPGA加速的一些核心研究进行了总结,最后对FPGA进行CNN加速策略进行了分析。 PS:历时三天终于看完了这篇review,因为之前没接触过,所以个人认为作为入门级阅读比较适合,可以综合了解该领域的研究现状。当然对于理解不恰当之处还望指出,谢谢! |
 VGG是2014年几何视觉组(visual geometry group)提出的网络框架,ILSVRC竞赛的第二名,第一名是GooGLENet,包含5组卷积层(卷积层内的结构特定),根据层数分为VGG-16,VGG-19等。
VGG是2014年几何视觉组(visual geometry group)提出的网络框架,ILSVRC竞赛的第二名,第一名是GooGLENet,包含5组卷积层(卷积层内的结构特定),根据层数分为VGG-16,VGG-19等。 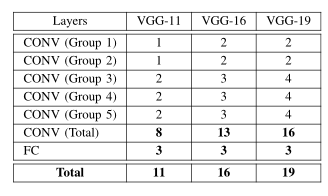 ResNet残差网络于2016年提出,引入了残差连接,层数更深,常用的有ResNet-50,ResNet-152.每一个residual-block包含:CONV->BN->ReLU->POOL
ResNet残差网络于2016年提出,引入了残差连接,层数更深,常用的有ResNet-50,ResNet-152.每一个residual-block包含:CONV->BN->ReLU->POOL Sankaradas:提出了并行向量处理模块VPE,每个VPE包含MAC+register用来实现2D conv+adder+sub_samples计算以及存储权重参数。该工作数据精度低,权重精度高(16bit&20bit)。最终搭建了一个4层卷积无FC的网络用于人脸识别,比软件实现加速6x,缺点是没有对FC进行加速,而实际应用中一定要用到FC。 MAPLE:通过分析数据流发现网络可以并行化为几个数据流因此提出了MAPLE作为向量处理单元,给每个PE配置了一个本地存储来存放矩阵的某一列,这样矩阵乘法通过一个一个乘数流入PE完成MAC;引入的smart memory block用于处理中间数据,比如找出最大的值等
Sankaradas:提出了并行向量处理模块VPE,每个VPE包含MAC+register用来实现2D conv+adder+sub_samples计算以及存储权重参数。该工作数据精度低,权重精度高(16bit&20bit)。最终搭建了一个4层卷积无FC的网络用于人脸识别,比软件实现加速6x,缺点是没有对FC进行加速,而实际应用中一定要用到FC。 MAPLE:通过分析数据流发现网络可以并行化为几个数据流因此提出了MAPLE作为向量处理单元,给每个PE配置了一个本地存储来存放矩阵的某一列,这样矩阵乘法通过一个一个乘数流入PE完成MAC;引入的smart memory block用于处理中间数据,比如找出最大的值等  Chakradhar:提出了动态配置FPGA,系统包括:1个处理器,一个动态配置核(DC-CNN)+3列存储系统。DC-CNN共有m组计算单元用以计算n个卷积+pool+activation。通过因数分解的方法确定(m,n)的最佳组合。加速后可以达到实时处理视频流的水平,但也没有加速FC层因此不适用于现在的分类。
Chakradhar:提出了动态配置FPGA,系统包括:1个处理器,一个动态配置核(DC-CNN)+3列存储系统。DC-CNN共有m组计算单元用以计算n个卷积+pool+activation。通过因数分解的方法确定(m,n)的最佳组合。加速后可以达到实时处理视频流的水平,但也没有加速FC层因此不适用于现在的分类。  CNP_improved: (1)第二代CNP卷积网络处理单元将并行的向量处理单元取代原来的硬件卷积器,并取名为ALU。一个ALU包括:4 local router+1 global router+1streaming operator完成数据的分配;此外NCP_v2还是用了直接内存读取技术(DMA),可达到30fps的帧率 (2)neuFlow:ALU->PT+control unit+DMA;使用luaFlow(数据编译器完成code到HDL的转换
CNP_improved: (1)第二代CNP卷积网络处理单元将并行的向量处理单元取代原来的硬件卷积器,并取名为ALU。一个ALU包括:4 local router+1 global router+1streaming operator完成数据的分配;此外NCP_v2还是用了直接内存读取技术(DMA),可达到30fps的帧率 (2)neuFlow:ALU->PT+control unit+DMA;使用luaFlow(数据编译器完成code到HDL的转换  以上均只加速了卷积层,没有优化全连接层。 Qiu:该工作对conv和fc均进行了加速,首先卷积通过特殊设计的硬件卷积器完成,而对FC的权重矩阵使用SVD进行降维;本文还是用了动态数据量化的方式,在loss损失最小的情况下对每层确定最佳的量化位数;以及对conv,fc层访问外存时的突发长度(burst length)进行了优化来减少不必要的延时 最终本文实现了VGG-16-SVD的16bit定点硬件实现
以上均只加速了卷积层,没有优化全连接层。 Qiu:该工作对conv和fc均进行了加速,首先卷积通过特殊设计的硬件卷积器完成,而对FC的权重矩阵使用SVD进行降维;本文还是用了动态数据量化的方式,在loss损失最小的情况下对每层确定最佳的量化位数;以及对conv,fc层访问外存时的突发长度(burst length)进行了优化来减少不必要的延时 最终本文实现了VGG-16-SVD的16bit定点硬件实现 
 ALAMO:提出了CNN的一般框架,data router负责将数据分配给各个模块(如卷积、池化等);feature buffer使用片上RAM存储特征图谱,weight buffer用于存储conv或FC操作会用到的权重参数;CONV模块包括控制逻辑,adder trees,relu,而控制逻辑主要负责循环展开的参数设置,relu部分则是会检查输入数据的符号位,决定输出0还是数据本身;pool池化模块包括累加器或比较器完成均值池化或最大池化;NORM归一化模块主要是通过查找表来实现响应的归一化;FC模块则是共用CONV模块的硬件资源来实现矩阵向量乘法。 ALAMO编译器测试了两种网络的硬件实现:AlexNet和NiN,生成的RTL描述经综合后进行了板级验证。与OpenCL综合后的结果进行了比较,最终NiN的吞吐率比Alexnet更高,因为conv层更多。
ALAMO:提出了CNN的一般框架,data router负责将数据分配给各个模块(如卷积、池化等);feature buffer使用片上RAM存储特征图谱,weight buffer用于存储conv或FC操作会用到的权重参数;CONV模块包括控制逻辑,adder trees,relu,而控制逻辑主要负责循环展开的参数设置,relu部分则是会检查输入数据的符号位,决定输出0还是数据本身;pool池化模块包括累加器或比较器完成均值池化或最大池化;NORM归一化模块主要是通过查找表来实现响应的归一化;FC模块则是共用CONV模块的硬件资源来实现矩阵向量乘法。 ALAMO编译器测试了两种网络的硬件实现:AlexNet和NiN,生成的RTL描述经综合后进行了板级验证。与OpenCL综合后的结果进行了比较,最终NiN的吞吐率比Alexnet更高,因为conv层更多。  Lin:提出了FPGA并行框架,将神经网络分成了4级并行:task level,layer level,loop level,operator level. Task level:同时执行不同任务的推断 Layer level:同时计算不同输入图像的所有层 Loop level:进行卷积计算时涉及到的循环并行 Operator level:即卷积计算时使用多少个MAC以及FC层使用多少个MAC来达到并行计算
Lin:提出了FPGA并行框架,将神经网络分成了4级并行:task level,layer level,loop level,operator level. Task level:同时执行不同任务的推断 Layer level:同时计算不同输入图像的所有层 Loop level:进行卷积计算时涉及到的循环并行 Operator level:即卷积计算时使用多少个MAC以及FC层使用多少个MAC来达到并行计算  本文硬件实现了LeNet,AlexNet,VGG-S
本文硬件实现了LeNet,AlexNet,VGG-S
 VGG-16的FPGA实现 对于循环的优化: 通过合理的设计循环变量来减少计算时延(unrolling factors等); 优化硬件上的部分和存储、片上内存的访问以及片外存储的访问; 最终设计了适用于VGG-16所有CONV层的加速器,包括3163个MAC以及14个输入buffer,buffer的引入可以复用输入数据。
VGG-16的FPGA实现 对于循环的优化: 通过合理的设计循环变量来减少计算时延(unrolling factors等); 优化硬件上的部分和存储、片上内存的访问以及片外存储的访问; 最终设计了适用于VGG-16所有CONV层的加速器,包括3163个MAC以及14个输入buffer,buffer的引入可以复用输入数据。  DLA:deep learning architecture是一个基于OpenCL的深度学习框架,DLA通过对卷积层和池化层的层次化管理减少了外存所需的带宽。通过将所有中间的特征图谱存在片上buffer完成,Winograd算法可以有效减少FC层涉及到的乘加运算,浮点到定点的转换用16bit浮点数。 DLA的框架如下图所示,每一个PE包括一个点乘单元、一乐累加器以及一个cache用于参数的存储。也使用了double-buffering来减少idel cycle.sequencer则会根据CNN的借口产生控制不同block的信号,因此不同的网络只需更改sequencere的配置即可。 通过DLA部署AlexNet在FPGA可以媲美GPU的能效。
DLA:deep learning architecture是一个基于OpenCL的深度学习框架,DLA通过对卷积层和池化层的层次化管理减少了外存所需的带宽。通过将所有中间的特征图谱存在片上buffer完成,Winograd算法可以有效减少FC层涉及到的乘加运算,浮点到定点的转换用16bit浮点数。 DLA的框架如下图所示,每一个PE包括一个点乘单元、一乐累加器以及一个cache用于参数的存储。也使用了double-buffering来减少idel cycle.sequencer则会根据CNN的借口产生控制不同block的信号,因此不同的网络只需更改sequencere的配置即可。 通过DLA部署AlexNet在FPGA可以媲美GPU的能效。  Lu:使用了2D Winograd算法加速CNN,主要使用了line buffer和Winograd PE engine,line buffer使得输入连续循环进行,PE engine分成了4级:transformation, element-wise matrix multiplication,additional transformation,accumulation of output tiles.
Lu:使用了2D Winograd算法加速CNN,主要使用了line buffer和Winograd PE engine,line buffer使得输入连续循环进行,PE engine分成了4级:transformation, element-wise matrix multiplication,additional transformation,accumulation of output tiles. 
 Multi CLP:本文作者Sheng注意到当conv层维度大于CLP维度时需要重复使用CLP这样会导致资源利用率的下降。在SqueezeNet和AlexNet中均有该种现象,AlexNet中idle现象更严重。因此本文提出了multi-CLP加速系统,每个CLP的尺度更小用来匹配CONV的子集,这样可以提高资源的整体利用率,比如将CLP划分为更小尺度的CLP1+CLP2的组合,这样进一步减少硬件idle的时间,实现AlexNet是sigle-CLP的1.3x/1.54x的加速比。
Multi CLP:本文作者Sheng注意到当conv层维度大于CLP维度时需要重复使用CLP这样会导致资源利用率的下降。在SqueezeNet和AlexNet中均有该种现象,AlexNet中idle现象更严重。因此本文提出了multi-CLP加速系统,每个CLP的尺度更小用来匹配CONV的子集,这样可以提高资源的整体利用率,比如将CLP划分为更小尺度的CLP1+CLP2的组合,这样进一步减少硬件idle的时间,实现AlexNet是sigle-CLP的1.3x/1.54x的加速比。  Systolic Architecture:Wei提出了脉动模型systolic architecture,每一个PE会将权重和输入数据向水平和垂直两个方向脉动出去,这样可以减少布线的复杂度同时可以达到时间要求。这样可以很方便的完成CNN到PE的映射,还可以灵活配置PE的大小,最终该策略加速了AlexNet和VGG。
Systolic Architecture:Wei提出了脉动模型systolic architecture,每一个PE会将权重和输入数据向水平和垂直两个方向脉动出去,这样可以减少布线的复杂度同时可以达到时间要求。这样可以很方便的完成CNN到PE的映射,还可以灵活配置PE的大小,最终该策略加速了AlexNet和VGG。  DLAU:Wang研究的是可扩展CNN的FPGA硬件实现,由于卷积和FC占据了绝大部分的时间,本文设计了一个嵌入式核+memory controller+DMA+DLAU的架构,其中DLAU深度学习加速单元采用了3级流水线架构,分别进行:TMMU不分居真诚达,PASU部分和,AFAU激活函数加速。 最终实现了MNIST手写数字的推断,加速比为36.1x。
DLAU:Wang研究的是可扩展CNN的FPGA硬件实现,由于卷积和FC占据了绝大部分的时间,本文设计了一个嵌入式核+memory controller+DMA+DLAU的架构,其中DLAU深度学习加速单元采用了3级流水线架构,分别进行:TMMU不分居真诚达,PASU部分和,AFAU激活函数加速。 最终实现了MNIST手写数字的推断,加速比为36.1x。  Overall Architecture and Dataflow: 一个通用的端到端的CNN实现框架, 不仅支持某种特定的CNN而是支持通用的CNN设计。作者将CNN的层次进行了划分,关键层:CONV/POOL/FC;附属层:ReLU,BNorm,EltWise以及其它层。一个combo包括1个关键层+几个附属层,然后连接不同的combo搭建最后的网络,每一个combo的处理流程是这样的:从片外DRAM读入输入像素->通过控制逻辑完成各combo的计算->配置各模块。 本文创新之二在于对输入像素和权重使用了特殊的存储模式,以便最大化资源利用最小化外存访问;最终成功在StratixV上部署了NiN,VGG-16,ResNet-50,ResNet-152
Overall Architecture and Dataflow: 一个通用的端到端的CNN实现框架, 不仅支持某种特定的CNN而是支持通用的CNN设计。作者将CNN的层次进行了划分,关键层:CONV/POOL/FC;附属层:ReLU,BNorm,EltWise以及其它层。一个combo包括1个关键层+几个附属层,然后连接不同的combo搭建最后的网络,每一个combo的处理流程是这样的:从片外DRAM读入输入像素->通过控制逻辑完成各combo的计算->配置各模块。 本文创新之二在于对输入像素和权重使用了特殊的存储模式,以便最大化资源利用最小化外存访问;最终成功在StratixV上部署了NiN,VGG-16,ResNet-50,ResNet-152  DLA:Intel的深度学习加速器支持网络参数的动态配置,因此适合不同神经网络的硬件实现。DLA每个PE均使用了double-buffer的结构这样可以预加载下一次卷积要用的参数,stream buffer也用了double_buffer便于存储输入和中检结果。XBar连接可以方便的实现各种网络。 编译使用的是graph complier的方式来匹配网络,完成硬件的映射,因此编译会把网络分成子图(subgraph)的形式,但对这一部分进行优化,比如1CONV+POOL就可以看做一个子图,随即编译器会对该部分进行优化,包括配置buffer、PE等。
DLA:Intel的深度学习加速器支持网络参数的动态配置,因此适合不同神经网络的硬件实现。DLA每个PE均使用了double-buffer的结构这样可以预加载下一次卷积要用的参数,stream buffer也用了double_buffer便于存储输入和中检结果。XBar连接可以方便的实现各种网络。 编译使用的是graph complier的方式来匹配网络,完成硬件的映射,因此编译会把网络分成子图(subgraph)的形式,但对这一部分进行优化,比如1CONV+POOL就可以看做一个子图,随即编译器会对该部分进行优化,包括配置buffer、PE等。  Design Flow: Kaiyuan则是提出了CNN映射到FPGA实现的完成设计流程,包括数据量化策略以及动态配置硬件参数完成不同CNN的部署,设计流程如下图所示。
Design Flow: Kaiyuan则是提出了CNN映射到FPGA实现的完成设计流程,包括数据量化策略以及动态配置硬件参数完成不同CNN的部署,设计流程如下图所示。  对于数据量化部分回味每一层设定最佳的位宽,该框架可以在几乎没有精度损失的前提下以8bit表示目前主流的CNN,层的中检结果先表示为24bit随后量化为8bit数据;支持3种指令:LOAD/SAVE/CALC 整个架构被分成了4部分,分别是:PE阵列、片上buffer、外存以及控制器。其中PE阵列实施并行化的卷积运算,固定使用的是33的卷积核,也是目前比较通用的规格。但通过33的堆叠可以实现更大的卷积核;片上buffer的使用可以使得数据的输入输出和卷积计算并行进行;控制器则负责接收指令,并将指令下发给各个部件。
对于数据量化部分回味每一层设定最佳的位宽,该框架可以在几乎没有精度损失的前提下以8bit表示目前主流的CNN,层的中检结果先表示为24bit随后量化为8bit数据;支持3种指令:LOAD/SAVE/CALC 整个架构被分成了4部分,分别是:PE阵列、片上buffer、外存以及控制器。其中PE阵列实施并行化的卷积运算,固定使用的是33的卷积核,也是目前比较通用的规格。但通过33的堆叠可以实现更大的卷积核;片上buffer的使用可以使得数据的输入输出和卷积计算并行进行;控制器则负责接收指令,并将指令下发给各个部件。 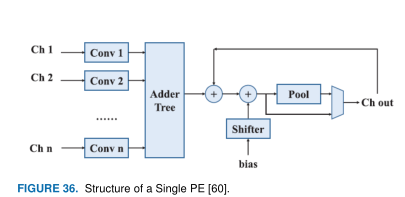
【本文地址】