| scrapy爬取微信公众号内容,多管道储存,orm数据储存 | 您所在的位置:网站首页 › 公众号数据爬虫 › scrapy爬取微信公众号内容,多管道储存,orm数据储存 |
scrapy爬取微信公众号内容,多管道储存,orm数据储存
|
scrapy基本操作
基本介绍:基于异步爬虫的框架。高性能的数据解析,高性能的持久化存储,全站数据爬取,增量式,分布式…环境的安装:
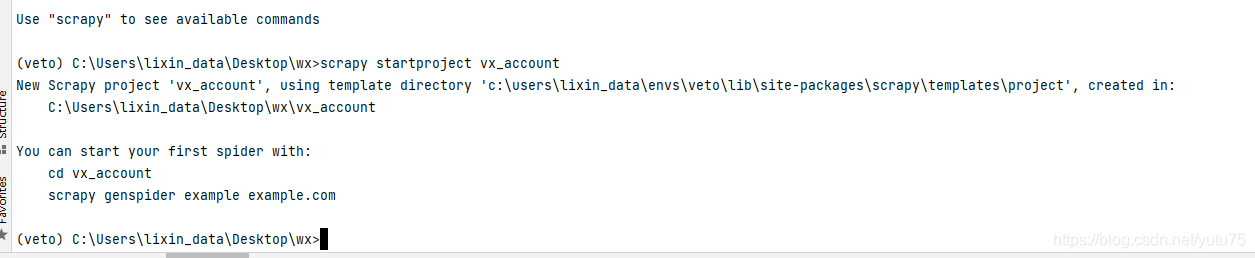
- Linux: pip install scrapy- Windows: a. pip install wheel b. 下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted - twisted插件是scrapy实现异步操作的三方组件。 c. 进入下载目录,执行 pip install Twisted‑17.1.0‑cp35‑cp35m‑win_amd64.whl d. pip install pywin32 e. pip install scrapy scrapy基本使用1.创建一个工程:scrapy startproject proName 工程的目录结构: spiders文件夹: 这里存放爬虫的主程序,这里可以写多个爬虫文件,分别执行不同的爬虫功能。 要求:必须要存储一个或者多页爬虫文件 items.py: 这个文件定义了爬虫程序中爬取的字段信息,对应着数据库中的属性信息。middlewares.py: 下载中间件,可以对爬取到的网页信息尽心特定的处理。pipelines.py: 管道,也就是将返回来的item字段信息写入到数据库,这里可以写写入数据库的代码。settings.py: 配置文件。2.创建爬虫文件 cd proNamescrapy genspider spiderName www.xxx.com3.执行工程 scrapy crawl spiderName重点关注的日志信息:ERROR类型的日志信息 settings.py:LOG_LEVEL = ‘ERROR’settings.py:不遵从robots协议settings.py:UA伪装:USER_AGENT = ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36’settings.py代码参考以及配置意思的含义: # Scrapy settings for vx_account project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # https://docs.scrapy.org/en/latest/topics/settings.html # https://docs.scrapy.org/en/latest/topics/downloader-middleware.html # https://docs.scrapy.org/en/latest/topics/spider-middleware.html # #Scrapy项目的名字,这将用来构造默认 User-Agent BOT_NAME = 'vx_account' FEED_EXPORT_ENCODING = 'utf-8' # 设置全局编码 SPIDER_MODULES = ['vx_account.spiders'] # Scrapy搜索spider的模块列表 默认: [xxx.spiders] NEWSPIDER_MODULE = 'vx_account.spiders' # 使用 genspider 命令创建新spider的模块。默认: 'xxx.spiders' # 通过在用户代理上标识您自己(和您的网站)来负责地爬行 # Crawl responsibly by identifying yourself (and your website) on the user-agent USER_AGENT = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36' # 遵守robots.txt规则 # Obey robots.txt rules ROBOTSTXT_OBEY = False # 不遵从robots协议 LOG_LEVEL = 'ERROR' # ERROR类型的日志信息 # 配置Scrapy执行的最大并发请求(默认值:16) # Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32 # 同一网站的请求配置延迟(默认值:0) # Configure a delay for requests for the same website (default: 0) # See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs # 下载延迟 #DOWNLOAD_DELAY = 3 # 下载延迟设置将仅满足以下条件之一(二选一) # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16 # 禁用cookie(默认情况下启用) # Disable cookies (enabled by default) #COOKIES_ENABLED = False # 禁用telnet控制台(默认启用) # Disable Telnet Console (enabled by default) #TELNETCONSOLE_ENABLED = False # 覆盖默认请求头 # Override the default request headers: #DEFAULT_REQUEST_HEADERS = { # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', # 'Accept-Language': 'en', #} # 启用或禁用蜘蛛中间件 # Enable or disable spider middlewares # See https://docs.scrapy.org/en/latest/topics/spider-middleware.html #SPIDER_MIDDLEWARES = { # 'vx_account.middlewares.VxAccountSpiderMiddleware': 543, #} # 启用或禁用下载器中间件 # Enable or disable downloader middlewares # See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html #DOWNLOADER_MIDDLEWARES = { # 'vx_account.middlewares.VxAccountDownloaderMiddleware': 543, #} # 启用或禁用扩展 # Enable or disable extensions # See https://docs.scrapy.org/en/latest/topics/extensions.html #EXTENSIONS = { # 'scrapy.extensions.telnet.TelnetConsole': None, #} # 管道配置项目 # Configure item pipelines # See https://docs.scrapy.org/en/latest/topics/item-pipeline.html #ITEM_PIPELINES = { # 'vx_account.pipelines.VxAccountPipeline': 300, #} # 启用和配置AutoThrottle扩展(默认情况下禁用) # Enable and configure the AutoThrottle extension (disabled by default) # See https://docs.scrapy.org/en/latest/topics/autothrottle.html #AUTOTHROTTLE_ENABLED = True # 初始下载延迟 # The initial download delay #AUTOTHROTTLE_START_DELAY = 5 # 在高延迟情况下设置的最大下载延迟 # The maximum download delay to be set in case of high latencies #AUTOTHROTTLE_MAX_DELAY = 60 # Scrapy平均请求数应与每个远程服务器并行发送 # The average number of requests Scrapy should be sending in parallel to # each remote server #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: #AUTOTHROTTLE_DEBUG = False # 启用和配置HTTP缓存(默认情况下禁用) # Enable and configure HTTP caching (disabled by default) # See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings #HTTPCACHE_ENABLED = True #HTTPCACHE_EXPIRATION_SECS = 0 #HTTPCACHE_DIR = 'httpcache' #HTTPCACHE_IGNORE_HTTP_CODES = [] #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage' 数据解析 - 数据解析 - 使用xpath进行数据解析 - 注意:使用xpath表达式解析出来的内容不是直接为字符串,而是Selector对象,想要的 字符串数据是存储在该对象中。 - extract():如果xpath返回的列表元素有多个 - extract_first():如果xpath返回的列表元素只有一个首先我们来看看 我们要爬的网页 打开spiders文件夹下爬虫文件 wechat/wechat/spiders/wechatspider.py 代码如下: # coding=utf-8 import scrapy class WechatspiderSpider(scrapy.Spider): # 爬虫文件名称:当前爬虫文件的唯一标识 name = 'wechatspider' # 允许的域名: allowed_domains = ['mp.weixin.qq.com/s/kfIAZmK5bAOMHuuHnL_ZMw'] # 起始的url列表:存储即将要发起请求的url,列表存有的url都会被框架自动进行get请求的发送 start_urls = ['http://mp.weixin.qq.com/s/kfIAZmK5bAOMHuuHnL_ZMw'] # 数据解析 # 参数response就是请求成功后对应的响应对象 def parse(self, response): all_list = [] course_list = response.xpath('//*[@id="js_content"]/section') for i in course_list: course_title = i.xpath('.//span//text()').extract_first() course_url = i.xpath('.//@href').extract_first() print(course_url) print(course_title) if course_title: dic = { 'course_title': course_title, 'course_url': course_url } all_list.append(dic) return all_list 持久化存储 - 持久化存储 - 基于终端指令的持久化存储 - 只可以将parse方法的返回值存储到制定后缀的文本文件中 - 局限性: - 1.只可以将parse方法返回值进行持久化存储 - 2.只可以将数据存储到文件中无法写入到数据库 - 指令:scrapy crawl spiderName -o filePath - 基于管道的持久化存储 - 1.在爬虫文件中进行数据解析 - 2.在items.py文件中定义相关的属性 - 属性的个数要和解析出来的字段个数同步 - 3.将解析出来的数据存储到item类型的对象中 - 4.将item提交给管道 - 5.在管道中接收item对象且将该对象中存储的数据做任意形式的持久化存储 - 6.在配置文件中开启管道机制 基于终端指令的持久化存储 cd 项目文件下 用命令把爬取课程名和url地址存在本地 scrapy crawl wechatspider -o qwq.csv
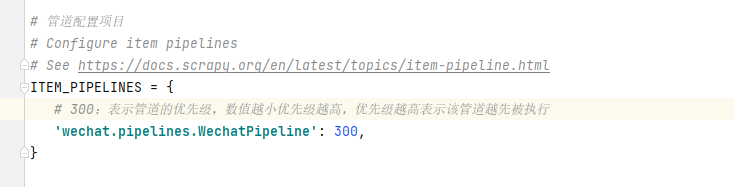
2.items.py代码 # Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class WechatItem(scrapy.Item): # define the fields for your item here like: course_url = scrapy.Field() course_title = scrapy.Field()3.去settings里开启管道配置。 - 300:表示管道的优先级,数值越小优先级越高,优先级越高表示该管道越先被执行
4.1 封装管道类,把数据储存到mysql里 ; pipelines.py代码: ,我比较懒,不喜写SQL语句,用sqlalchemy来处理的。 mysql 创建库: create database wechat charset utf8mb4; cd spiderst同级目录下 mkdir docs 新建models.py: from sqlalchemy import Column, String, DateTime, Boolean, create_engine, Integer, Text, ForeignKey from sqlalchemy.orm import sessionmaker, relationship # relationship两个表之间的外键关系 from sqlalchemy.ext.declarative import declarative_base from alembic import op # 创建对象的基类: Base = declarative_base() # 定义表对象 class Course(Base): # 定义数据库表名 __tablename__ = 'course' # 表的结构 参数参照上面表单 gid = Column(Integer(), primary_key=True, comment='主键ID') course_url = Column(String(5000), comment="课程url") course_title = Column(String(50), comment='课程标题!')执行命令: alembic init migrations
修改alembic.ini、enc.py代码 ,参考:https://blog.csdn.net/yutu75/article/details/117362459 也可以自行百度如何迁移, alembic revision --autogenerate -m “v1”
alembic upgrade head
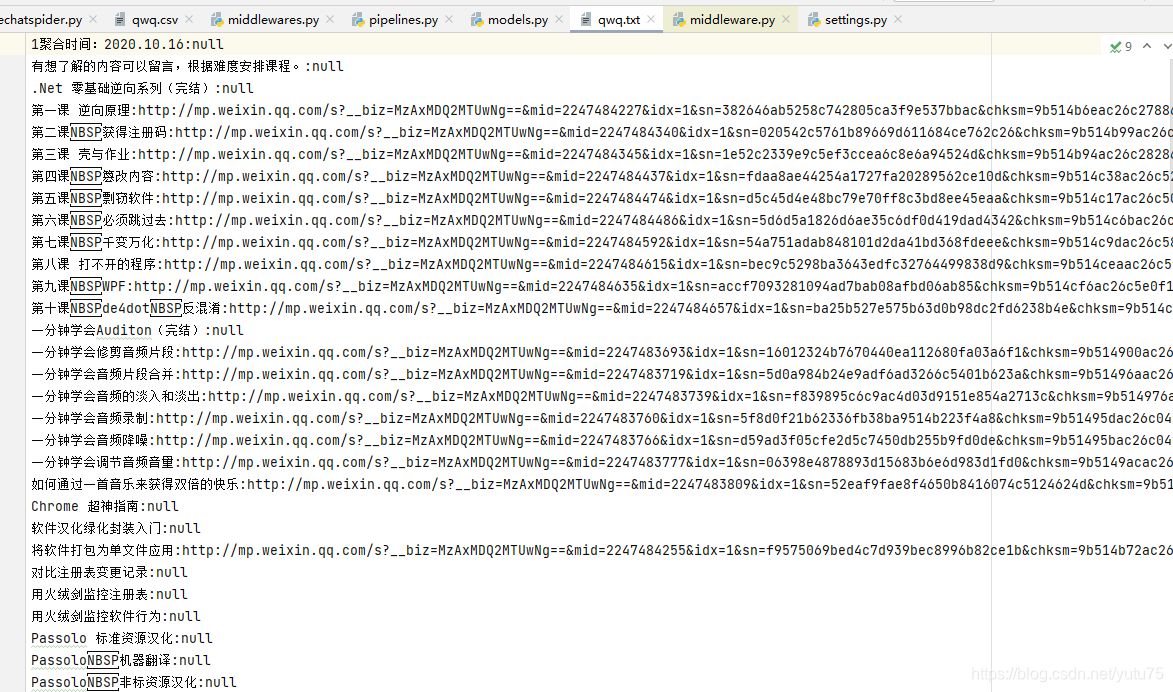
修改pipelines.py,代码: 下面封装了三个管道类: txt文件,mysql,Redis # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html from wechat.docs.models import Course from sqlalchemy import Column, String, DateTime, Boolean, create_engine, Integer, Text, ForeignKey from sqlalchemy.orm import sessionmaker, relationship import pandas as pd import pymysql import redis # useful for handling different item types with a single interface from itemadapter import ItemAdapter # 封装一个管道类,将数据存储到mysql中 class MysqlPipeline: engine = None # 链接对象 Session = None # session对象: session = None def open_spider(self, spider): self.engine = create_engine('mysql+pymysql://root:[email protected]:3306/wechat', echo=True) # 创建一个会话 self.Session = sessionmaker(bind=self.engine) # 创建session对象: print(self.engine) def process_item(self, item, spider): course_url = item['course_url'] course_title = item['course_title'] self.session = self.Session() print('qwq') try: new_page = Course(course_title=course_title, course_url=course_url) self.session.add(new_page) self.session.commit() except Exception as e: print(e) self.session.rollback() return item def close_spider(self, spider): self.session.close() class WechatPipeline: fp = None def open_spider(self, spider): # 方法只会在爬虫开始时执行一次 print('i am open_spider()') self.fp = open('./qwq.txt', 'w', encoding='utf-8') # 用来接收item对象,该方法调用的次数取决于爬虫文件像管道提交item的次数 # 参数: # - item:就是接收到的item对象 # - spider:爬虫类实例化的对象 def process_item(self, item, spider): course_url = item['course_url'] course_title = item['course_title'] if course_url is not None or course_title is not None: self.fp.write([course_title if course_title is not None else 'null'][0] + ':' + [course_url if course_url is not None else 'null'][0] + '\n') return item def close_spider(self, spider): # 在爬虫结束时被执行一次 print('i am close_spider()') self.fp.close() # 封装一个管道类,将数据存储到redis中 class redisPipeLine: conn = None def open_spider(self,spider): self.conn = redis.Redis(host='192.168.152.128', port=6379) def process_item(self,item,spider): course_url = item['course_url'] course_title = item['course_title'] if course_url is not None or course_title is not None: self.conn.lpush('wechat', [course_title if course_title is not None else 'null'][0] + ':' + [course_url if course_url is not None else 'null'][0]) return item # 不使用orm写入mysql里 # 封装一个管道类,将数据存储到mysql中 # class MysqlPipeline: # conn = None # cursor = None # # def open_spider(self, spider): # self.conn = pymysql.Connect(host='127.0.0.1', port=3306, user='root', password='123456', db='spider', # charset='utf8') # print(self.conn) # # def process_item(self, item, spider): # author = item['author'] # content = item['content'] # self.cursor = self.conn.cursor() # sql = 'insert into new_qiubai values ("%s","%s")' % (author, content) # print(sql) # try: # self.cursor.execute(sql) # self.conn.commit() # except Exception as e: # print(e) # self.conn.rollback() # return item # # def close_spider(self, spider): # self.cursor.close() # self.conn.close()执行命令 : scrapy crwal wechatspider 储存后的mysql: 储存后txt:
|
 小知识点:
小知识点: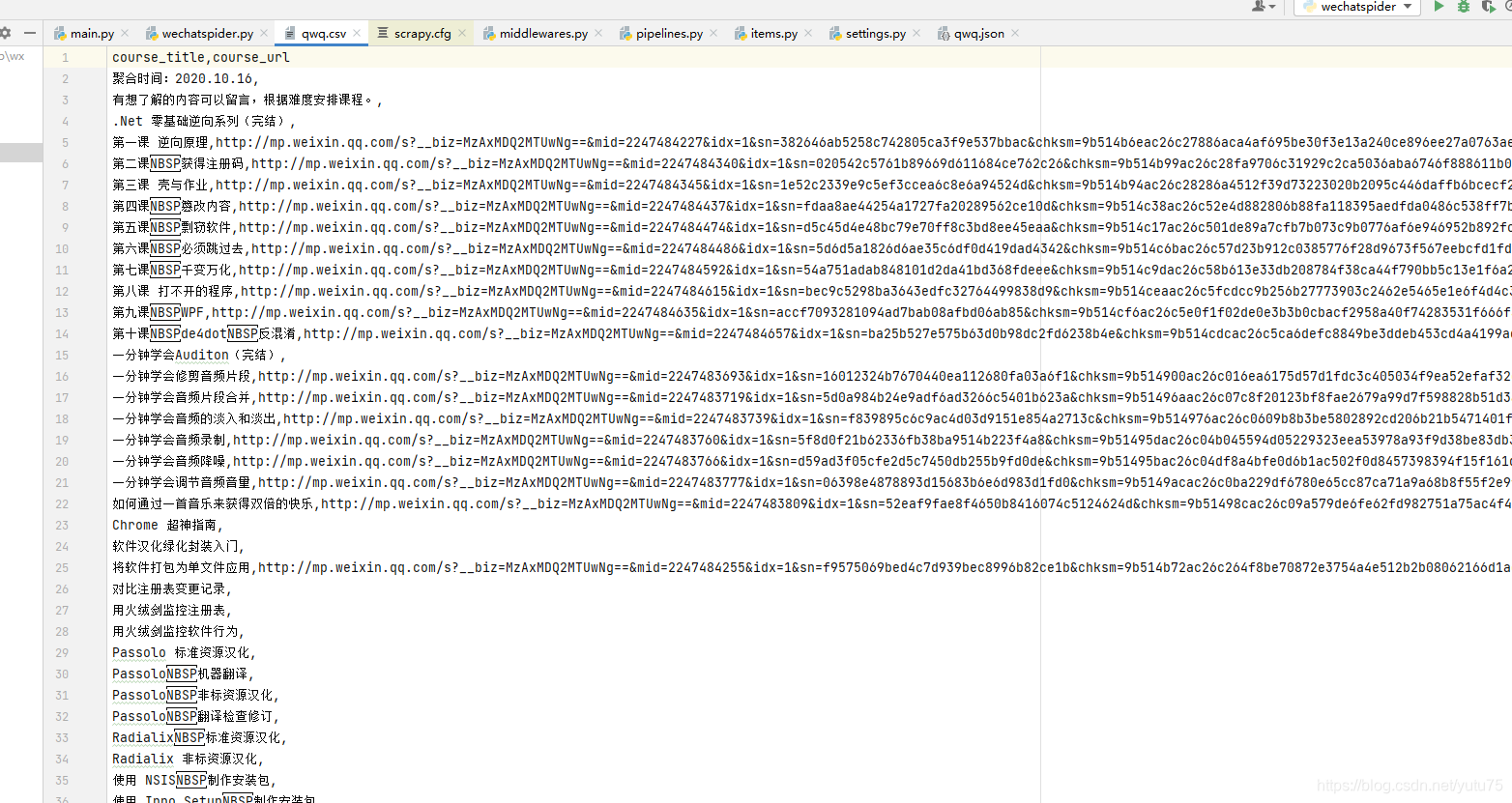
 4.1 封装管道类,把数据储存到txt文件里 ; pipelines.py代码:
4.1 封装管道类,把数据储存到txt文件里 ; pipelines.py代码:

 最后的表结构:
最后的表结构: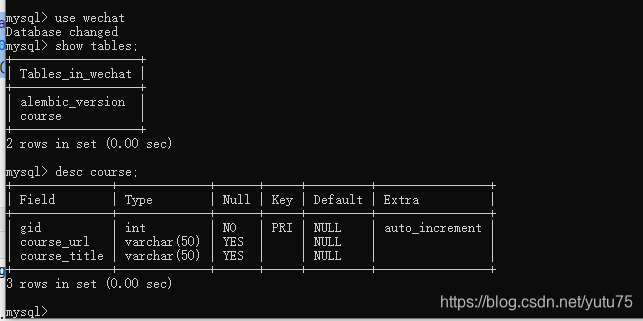 去settings添加管道:
去settings添加管道: 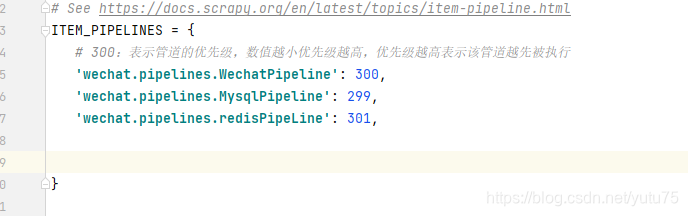
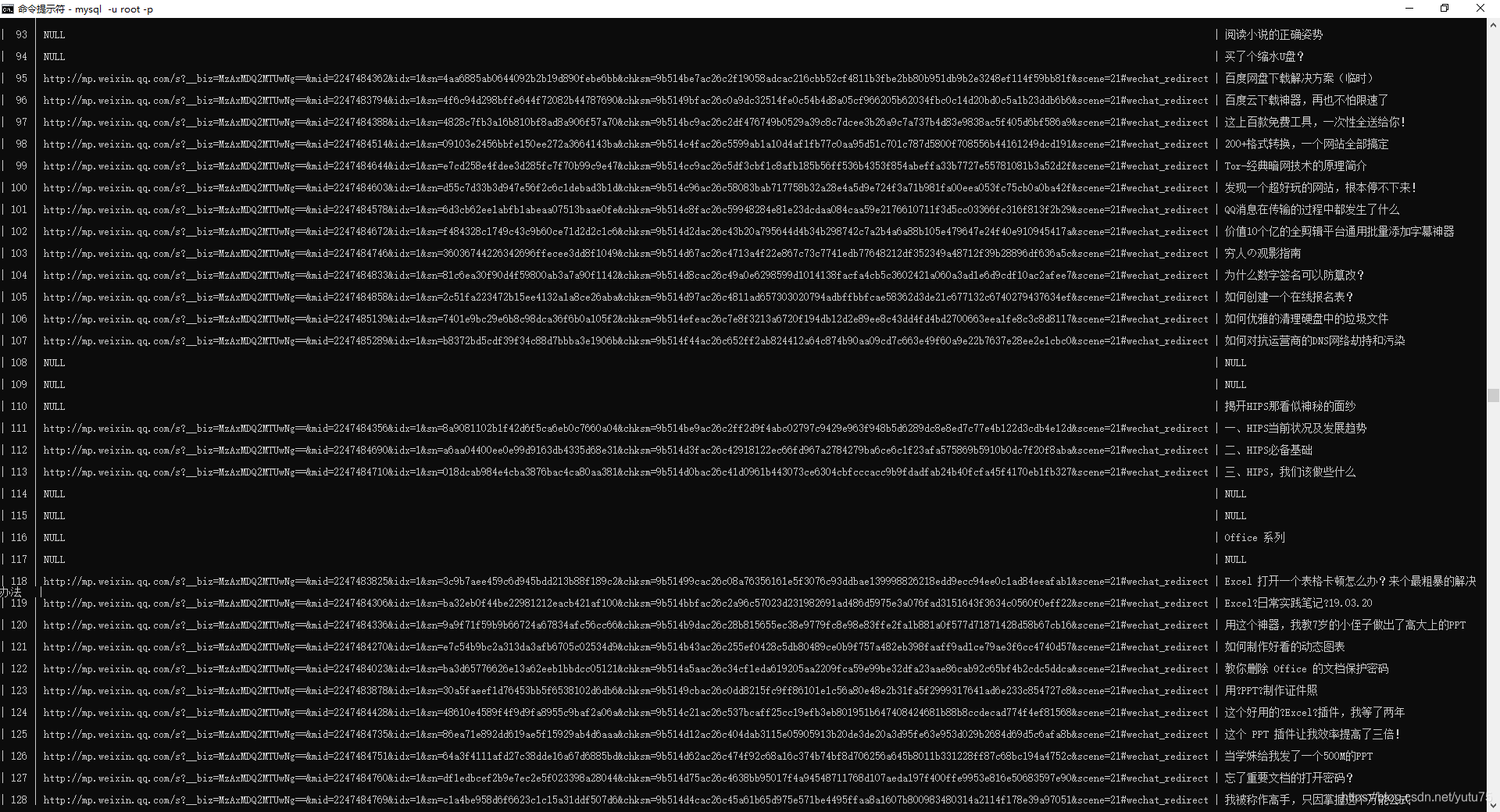 储存后的redis:
储存后的redis: 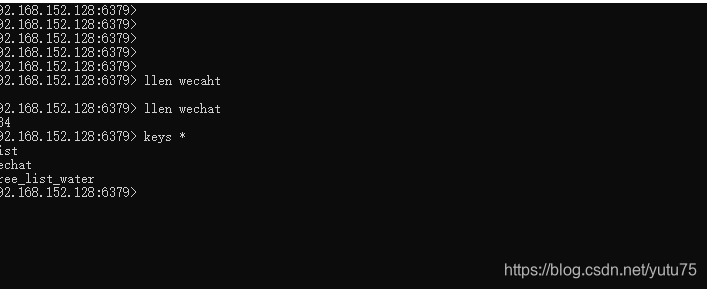
【本文地址】
公司简介
联系我们