| 【机器学习】 | 您所在的位置:网站首页 › 全连接层参数个数计算公式 › 【机器学习】 |
【机器学习】
|
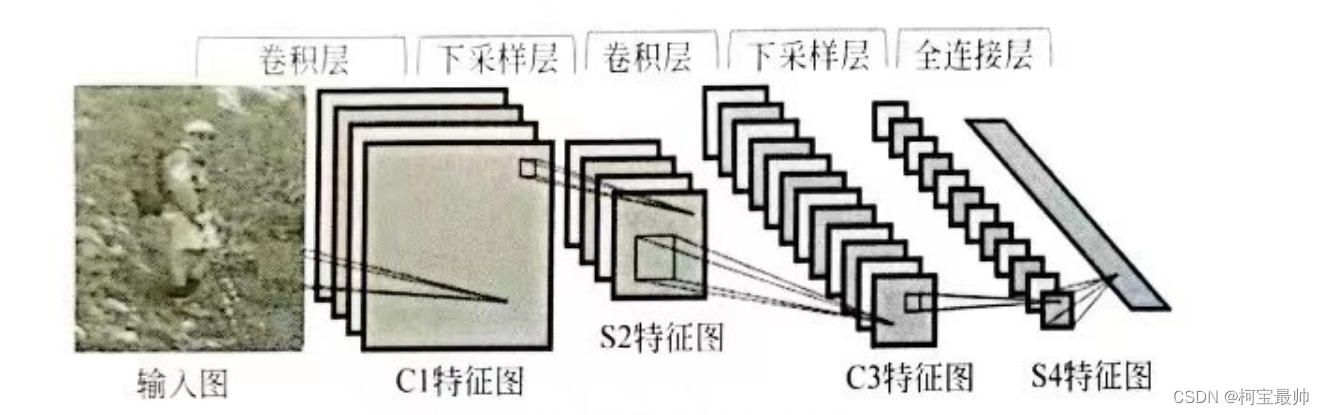
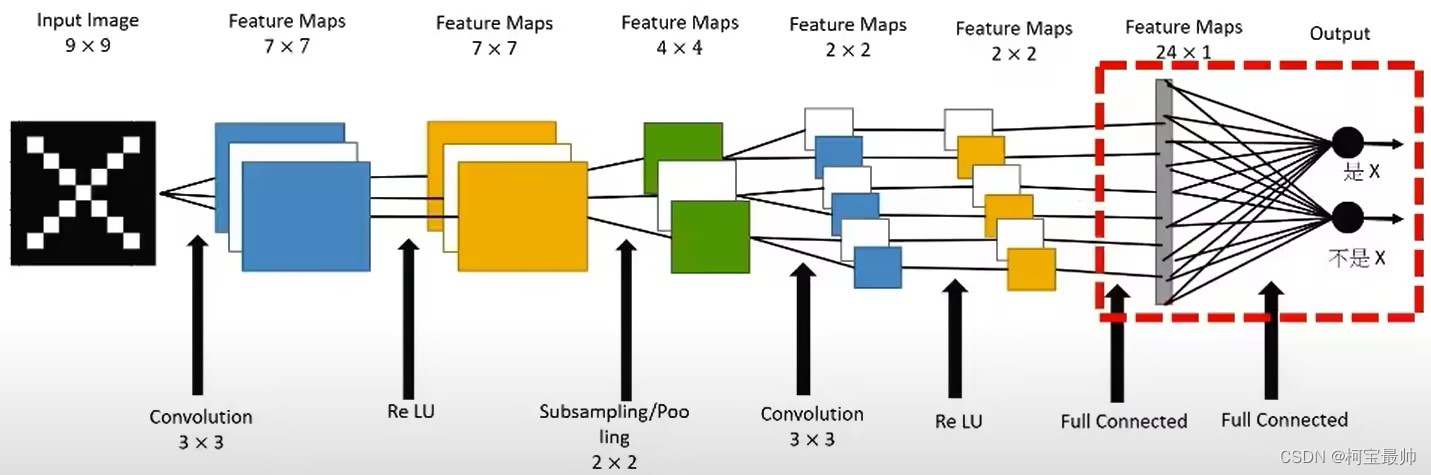
目录 引入 一、CNN基本结构 1、卷积层 2、下采样层 3、全连接层 二、CNN参数训练 总结 引入卷积神经网络(CNN)是一种有监督深度模型框架,尤其适合处理二维数据问题,如行人检测、人脸识别、信号处理等领域,是带有卷积结构的深度神经网络,也是首个真正意义上成功训练多层网络的算法。CNN与传统的神经网络的主要区别在于权值共享与非全连接。权值共享能够避免算法过拟合,通过拓补结构建立层与层间非全连接空间关系来降低训练参数的数目,这也是卷积神经网络的基本思想。 CNN经过反馈训练学习多个能够提取输入数据特征的卷积核,这些卷积核与输入数据进行逐层卷积并池化,来逐级提取隐藏在数据中拓补结构的特征。随着网络结构层层深入,提取的特征也逐渐变得抽象,最终获得输入数据的平移、旋转及缩放不变性的特征表示。相比传统神经网络,CNN将特征提取与分类过程同时进行,避免了两者在算法匹配上的难点。 一、CNN基本结构CNN主要由卷积层 例如,用于图像识别的CNN基本框架如图所示,两层卷积、两层下采样、一层全连接,然后输出分类:
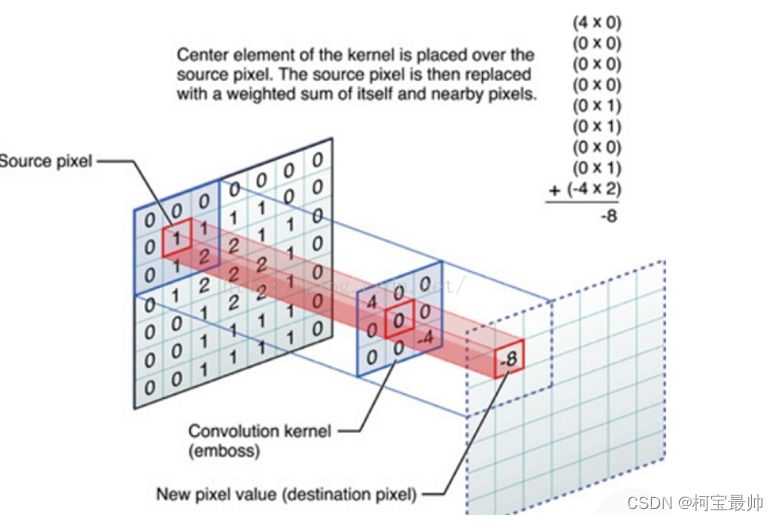
对图像和滤波矩阵做内积(逐个元素相乘再求和)即为卷积。图像即一个数据窗口,滤波矩阵可理解成权重层/卷积核,如下图:
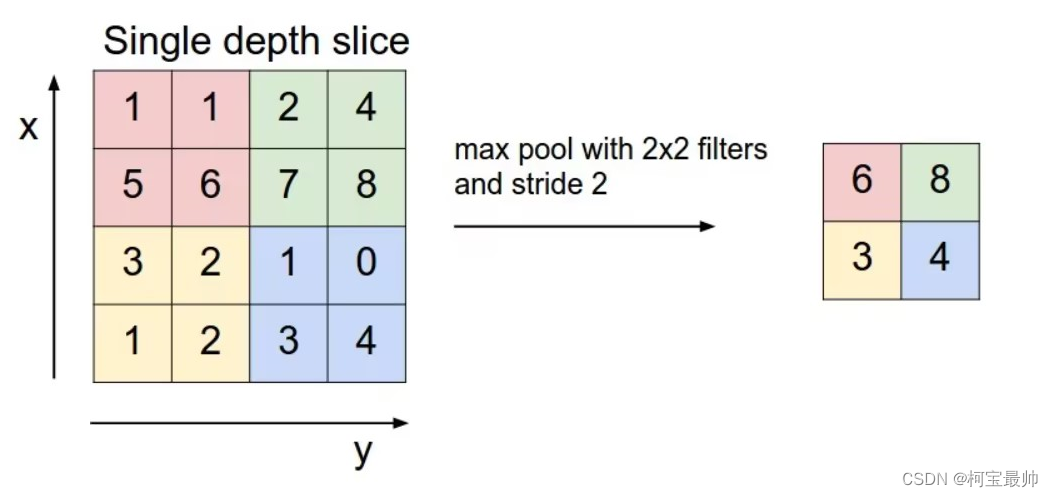
上图卷积核为3x3,所以做卷积后9个数变为1个数,每计算完一个数据窗口内的局部数据后,数据窗口不断平移滑动,直到计算完所有数据,涉及几个参数:①深度depth:神经元的个数,决定输出的depth厚度,也代表滤波器的个数;②步长stride:滑动多少步可到边缘,如3x3的卷积核一次滑移2步;③填充值zero-pading:在外围补充多少圈0,方便从初始位置以步长为单位可以刚好滑移到末尾位置——总长可以被步长整除。 滑移时数距窗口的数据一直在变化,每次滤波器(卷积核)都是对某一局部的数据窗口(一个特征图)进行卷积,这就是所谓的CNN的局部感知机制;但是权重值没变,这就是CNN的参数(权重)共享机制。 输入图像与可学习的核进行卷积操作,经过激活函数得到C1的特征图,卷积层的计算公式如下: 其中, 由上式,C1特征图由多个输入图卷积累加获得,但对于同一幅输入图其卷积核参数是一致的,这也是权值共享的意义。卷积核的初值不是随机设置,是通过无监督的预先训练或按照一定标准给定,如仿照生物视觉特征用Gabor滤波器进行预处理。此处的卷积操作是针对图像的二维离散卷积操作,步骤主要是:先将卷积核模板旋转180°,然后再将卷积核中心平移到所求像素点处,进行卷积操作(对应像素相乘并累加),得到图像上该像素点的卷积值。 2、下采样层下采样也可称为池化,池化是指特征图分别在高、长方向上缩小运算,以增强模型的鲁棒性(当输入数据发生微小偏差时,结果仍然是相同的——即下采样层通过降低网络空间分辨率来增强缩放不变性,计算公式如下: 其中, 假设一个4x4的特征图,池化窗口kenerl size为2,池化步长为2,则最大池化方法结果如下:(平均池化顾名思义,每个框取平均值)
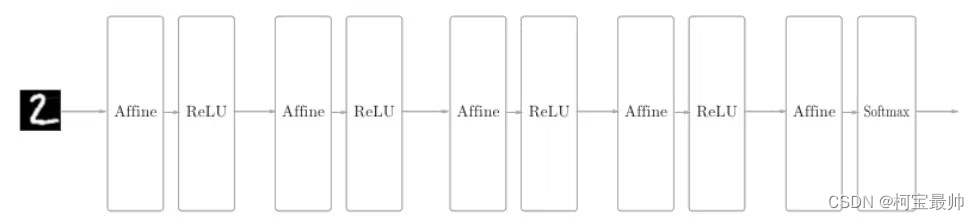
下采样的优势:①降维,减少网络要学习的参数数量;②防止过拟合,增强模型对一般情况的适应性;③增大感知野;④可以实现不变性:平移不变性、旋转不变性、尺度不变性。 劣势在于下采样过程会丢失大量的特征信息,但是这些信息可以通过一些特有手段在一定程度上弥补。 3、全连接层相邻层的所有神经元都有连接,称为全连接(fully connected),全连接层在整个CNN中起到分类器的作用。全连接层常出现在最后几层,一般用Affine层实现,该层每个神经元与前一层的所用神经元进行全连接,用来把前面提取的特征综合起来——即对前面设计的特征做加权和。由于全相连的特性,其参数也是最多的,为了提升CNN网络性能,全连接层的激活函数一般用到ReLU函数:
上图的全连接神经网络中,Affine层后跟着激活函数ReLU层(或Sigmoid层),上图堆叠了4层Affine-ReLU组合,然后第5层是Affine层,最后又Softmax层输出最终结果(一个概率)。注意这里的例子只有第5层Affine+Softmax是上面讨论的全连接输出层。前面的网络层可根据需要选择是否全连接(CNN输出层一般采用线性全连接层,目前最常用的分类方法有逻辑回归、Softmax分类方法。) 作用:全连接层主要用于线性映射,将输入数据从低维空间映射到高维空间,也可以加入非线性激活函数实现非线性映射。如果说卷积层、池化层和激活函数等操作是将原始数据映射到隐层特征空间的话,全连接层则起到了将学到的“分布式特征表示”映射到样本标记空间的作用——把前面局部特征重新通过权值矩阵组装成完整的图。 举例:如图一开始是9x9的图像经过一系列卷积、池化、激活函数操作后,即将进入到全连接层(红框):
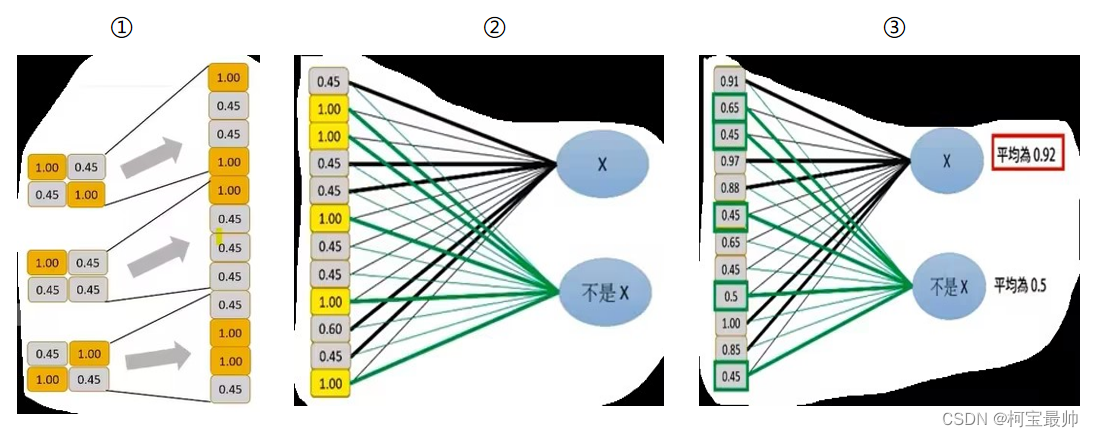
到了全连接层时,全连接层是一维数据,所以要将feature map变为一维。①假设在到达全连接层时是3个2x2的矩阵,此时这12x1向量中的每一个元素就是输入层的一个神经元;②然后得到的一维向量输入到网络中以概率(Softmax)的方式判断是X还是非X,粗线表示特征明显的数据,即是X还是非X;③根据计算得到的权重矩阵,对其进行加权求和,就得到了每个分类得分,然后根据Softmax函数进行概率计算,得到X的概率为0.92,不是X的概率为0.5:
逻辑回归和Softmax分类方法下次单独出一期博客!卷积分权值和偏置bias两部分也会进一步探讨!归一化也会进一步学习! 二、CNN参数训练CNN参数训练过程与传统的人工神经网络类似,采用BP反向传播算法,包括前向传播与反向传播两个阶段,假设共有N个训练样本,分为C类,误差函数如下: 其中, 卷积神经网络实际应用中会有很多问题,如网络参数如何预学习,收敛条件以及非全连接规则等,均需要实际应用中进一步解决与优化。这里介绍一种Boosting_like CNN算法,假设对输入样本加一个惩罚权值 其中, 误差 最后,对每个神经元运用
CNN可以看作多个特征提取器串联,每一个特征提取器,提取的特征由低级别到高级别,并且特征提取结果相互制约——一个特征提取器的分类结果不仅和前一层有关系,还受到后一层反馈的制约。假设CNN有n个阶段,则用n个不同阶段的输出训练分类器,可以得到n个弱分类器,所以使用Boosting算法在训练过程中不断调节样本权重分布,以此来给不同网络层次结构提供更好的分类情况的反馈信息,进而提高网络性能使得网络更加稳定——......具体可参考相关论文!! 总结此总结内容包括上次的神经网络与深度学习博客! 深度学习是自动学习分类所需的低层次或高层次特征算法,例如机器视觉,深度学习算法从原始图像去学习得到它的低层次表达(例如边缘),之后在低层次表达的基础上,通过线性或非线性的组合在建立高层次的表达。 深度学习能更好地表示数据特征。由于模型层次、参数很多,因此模型有能力处理大规模数据,对于图像、语音这种特征不明显的问题,能通过大规模数据训练取得很好效果。 此外,深度学习框架将特征提取和分类整合在一个框架,用数据去学习特征,减少了手工设计特征的巨大工作量,效果好还使用方便!! |
【本文地址】
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |