| 爬取城市GDP排名 | 您所在的位置:网站首页 › 全球大学综合排名数据爬取网站 › 爬取城市GDP排名 |
爬取城市GDP排名
|
一、选题的背景(10分) 为什么要选择此选题?要达到的数据分析目标是什么?从社会、经济、技术、数据来源等方面进行描述。 (200 字以内) 经济的发展对一个国家具有巨大的意义。我国的GDP逐年增长,经济发展迅速。选择该主题是为了通过爬虫爬取城市GDP排名及其数据,快速地反映出城市的发展情况。数据分析的目标是通过python中的matplotlib、pandas、seaborn、wordcloud等库做出图表和云词图能让我们快速精确地知道城市目前的发展情况及以后的发展的目标,对于GDP这一重要的经济指标,探寻其影响因素对于政府正确决策,经济快速发展,社会稳定具有重要意义,也是现今相关研究的重要方向。 二、设计方案(20分) 1、主题式网络主题式网络爬虫设计方案 (1)爬虫名称:爬取城市GDP排名 (2)网络爬虫设计方案概述:实现思路:在浏览器中通过F12访问网页源代码,,分析网站源代码,找到自己所需要的数据所在的位置,提取数据,对数据进行保存数据,再对数据进行清洗和处理,数据分析与可视化处理技术难点:对库使用和库中函数的运用,爬取的内容的机构分析处理 2、主题页面的结构特征分析 主题页面的结构与特征分析:通过页面的结构分析,可以得到各个数据之间的便签都有关联的关系,城市标签分布在城市中,排名标签分布排名中,19年GDP标签分布在2019上半年GDP(亿元)中,18年GDP标签分布在2018上半年GDP(亿元)中,名义增速标签分布在名义增速中。各个值则在这种形式中。
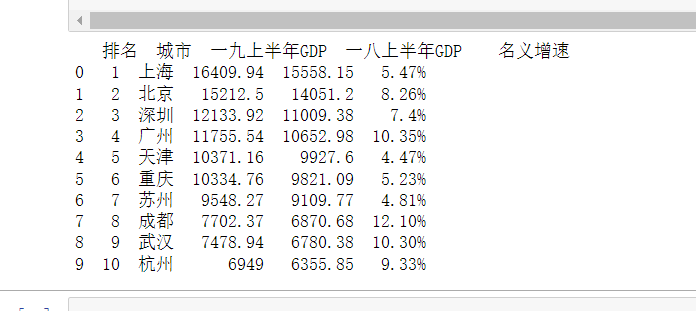
代码如下:3.网络爬虫程序设计 (1)数据爬取与采集 通过运用python中的requests、lxml、pandas库对网页进行爬取数据,然后将数据存为csv文件。 (2)数据清洗 通过运用python中的pandas、numpy库等对爬取的csv文件进行数据清洗,将空值、错误值等去除和填充。 (3)数据可视化分析 通过使用python中的padas、matplotlib、seaborn、wordcloud、jieba等库对数据进行处理,使其转化为图表和云词图,通过图表和云词图对数据进行分析。 三、实现步骤及代码(60分) 1.数据爬取与采集 通过运用python中的requests、lxml、pandas库对网页进行爬取数据,然后将数据存为csv文件。首先,我主要爬取的是该网页2018年和2019年的城市排名、城市名称、城市2018和2019年上半年的gdp和增速。具体为先伪装爬虫,然后发送一个get请求后构建一个xpath的解析对象,通过etree.html()将html的字符串转化为element对象。然后建空列表,通过for循环对其存入列表中,列表中采用append生成了一个多维数组。最后,又一次采用for循环将数据存入空列表,然后将列表中的数据存入2018和2019年上半年中国前十名城市GDP排名.scv文件中。 爬取的网站:http://www.860816.com/aricle.asp?id=1785 import requestsfrom lxml import etreeimport pandas as pd #爬取2019年上半年中国前10名城市#伪装爬虫headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'}url = "http://www.860816.com/aricle.asp?id=1785" r = requests.get(url,headers = headers)#发送get请求r.encoding=r.apparent_encoding#构建一个xpath解析对象html = etree.HTML(r.text)#利用etree.HTML()将html字符串转化为element对象,element对象是xpath语法的使用对象,element对象可由html字符串转化table = html.xpath("//table[@class='ke-zeroborder']/tbody")a=[]b=[]c=[]d=[]e=[]lt=[]for td in table: number = td.xpath(".//td[@class='et2'][1]/text()")[1:11] name = td.xpath(".//td[@class='et2'][2]/text()")[1:11] s2019GDP = td.xpath(".//td[@class='et2'][3]/text()")[1:11] #2019上半年GDP(亿元) s2018GDP = td.xpath(".//td[@class='et2'][4]/text()")[1:11] increase1_3 = td.xpath(".//td[@class='et2'][5]/text()")[1:3] increase2_10 = td.xpath(".//td[@class='et3']/text()")[0:8] for i in range(10): a.append(number[i].strip()) #用append生成多维数组 b.append(name[i].strip()) #.strip删除多余的空格换行 c.append(s2019GDP[i].strip()) d.append(s2018GDP[i].strip()) for i in range(2): e.append(increase1_3[i].strip()) for i in range(8): e.append(increase2_10[i].strip()) e[2],e[1] = e[1],e[2] lt=[]for i in range(10): lt.append([a[i],b[i],c[i],d[i],e[i]]) df=pd.DataFrame(lt,columns=["排名","城市","一九上半年GDP","一八上半年GDP","名义增速"])print(df)df.to_csv('2018和2019年上半年中国前十名城市GDP排名.csv',encoding = 'gbk')#保存文件,数据持久化
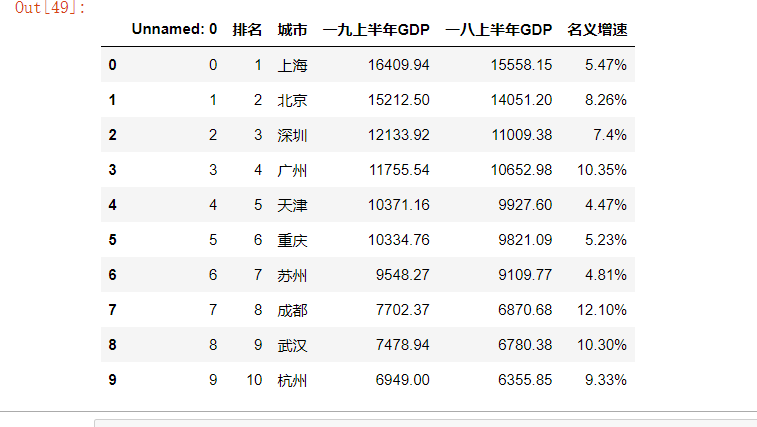
2.数据清洗 首先,先读取爬取2018和2019年上半年中国前十名城市GDP排名.csv文件。代码和结果: import pandas as pd import numpy as np import matplotlib.pyplot as plt #读取csv文件 s=pd.read_csv("2018和2019年上半年中国前十名城市GDP排名.csv") s
然后在进行重复值处理,检查是否有重复值,代码和结果如下: s.duplicated() #检查是否有重复值
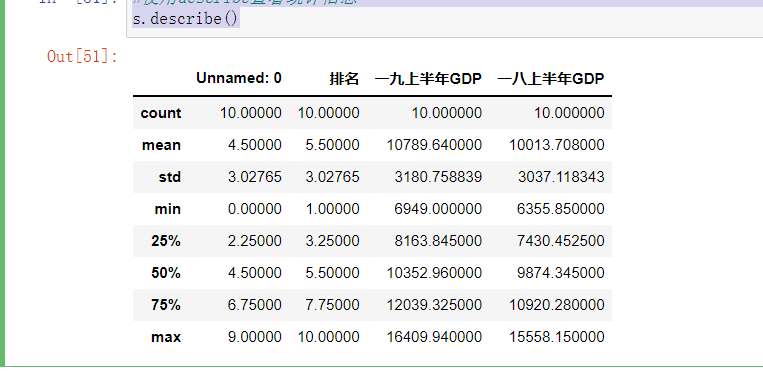
接下去对数据进行查看统计信息,代码和结果如下: #使用describe查看统计信息 s.describe()
最后对数据进行查看其数据类型,代码和结果如下: s.info() #查看各列数据类型
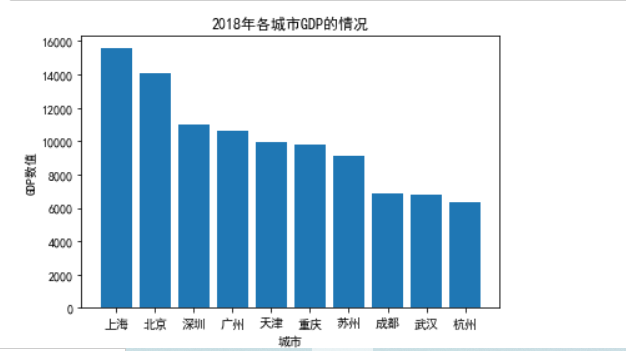
3.数据可视化分析 首先,我们先运用python的matplotlib、pandas、numpy库对18年和19年的数据进行可视化处理: 18年各城市GPD柱形图和折线图: import pandas as pd import numpy as np import matplotlib.pyplot as plt data=pd.read_csv("2018和2019年上半年中国前十名城市GDP排名.csv") plt.rcParams['font.sans-serif']=['SimHei'] #设置字体显示中文标签 plt.rcParams['axes.unicode_minus'] = False fig = plt.figure() #设置图片背景,清晰度 plt.bar(data['城市'], data['一八上半年GDP']) #画柱状图 plt.title(u'2018年各城市GDP的情况') #为图片增加标题 plt.xlabel('城市', size=10) #设置图的x轴标签 plt.ylabel(u'GDP数值) #设置图的y轴标签 plt.show() #将图片显示出来
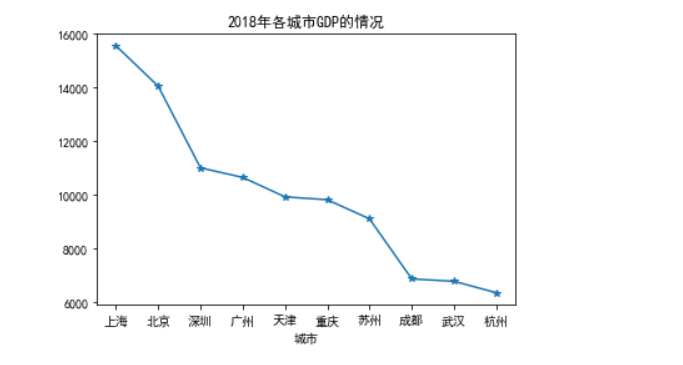
#2018和2019年上半年中国前十名城市GDP排名折线图 import pandas as pd import numpy as np import matplotlib.pyplot as plt data=pd.read_csv("2018和2019年上半年中国前十名城市GDP排名.csv") plt.rcParams['font.sans-serif'] = 'simhei' plt.rcParams['axes.unicode_minus']=False data = np.array(data) plt.plot(data[:,2],data[:,4],'-*') #画折线图 plt.xlabel("城市") #设置图的x轴标签 plt.title(u'2018年各城市GDP的情况') #为图片增加标题 plt.show() #将图片显示出来
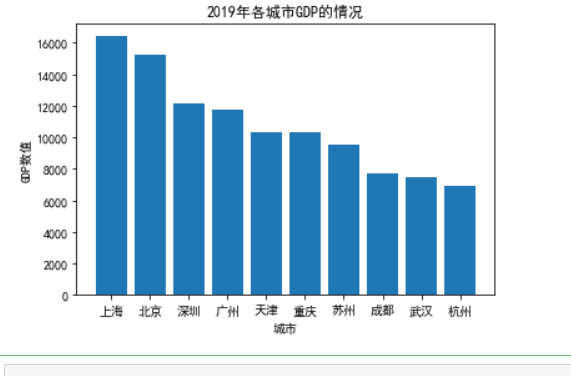
#画2018和2019年上半年中国前十名城市GDP排名柱状图 import pandas as pd import numpy as np import matplotlib.pyplot as plt data=pd.read_csv("2018和2019年上半年中国前十名城市GDP排名.csv") plt.rcParams['font.sans-serif']=['SimHei'] #设置字体显示中文标签 plt.rcParams['axes.unicode_minus'] = False fig = plt.figure() #设置图片背景,清晰度 plt.bar(data['城市'], data['一九上半年GDP']) #画柱状图 plt.title(u'2019年各城市GDP的情况') #为图片增加标题 plt.xlabel('城市', size=10) #设置图的x轴标签 plt.ylabel(u'GDP数值') #设置图的Y轴标签 plt.show() #将图片显示出来 #画2018和2019年上半年中国前十名城市GDP排名柱状图 import pandas as pd import numpy as np import matplotlib.pyplot as plt data=pd.read_csv("2018和2019年上半年中国前十名城市GDP排名.csv") plt.rcParams['font.sans-serif']=['SimHei'] #设置字体显示中文标签 plt.rcParams['axes.unicode_minus'] = False fig = plt.figure() #设置图片背景,清晰度 plt.bar(data['城市'], data['一九上半年GDP']) #画柱状图 plt.title(u'2019年各城市GDP的情况') #为图片增加标题 plt.xlabel('城市', size=10) #设置图的x轴标签 plt.ylabel(u'GDP数值') #设置图的Y轴标签 plt.show() #将图片显示出来
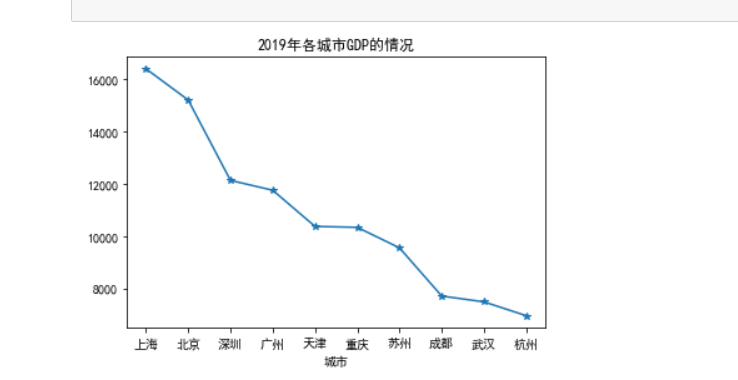
import pandas as pd import numpy as np import matplotlib.pyplot as plt data=pd.read_csv("2018和2019年上半年中国前十名城市GDP排名.csv") plt.rcParams['font.sans-serif'] = 'simhei' plt.rcParams['axes.unicode_minus']=False data = np.array(data) plt.plot(data[:,2],data[:,3],'-*') plt.title(u'2019年各城市GDP的情况') plt.xlabel("城市") plt.show() #将图片显示出来
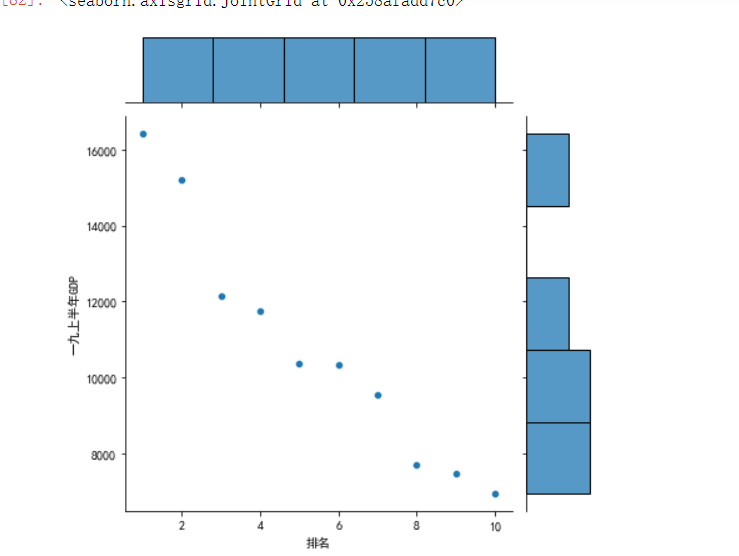
import pandas as pd import seaborn as sns import matplotlib.pyplot as plt df=pd.read_csv("2018和2019年上半年中国前十名城市GDP排名.csv") sns.jointplot(x="排名",y='一九上半年GDP',data = df)
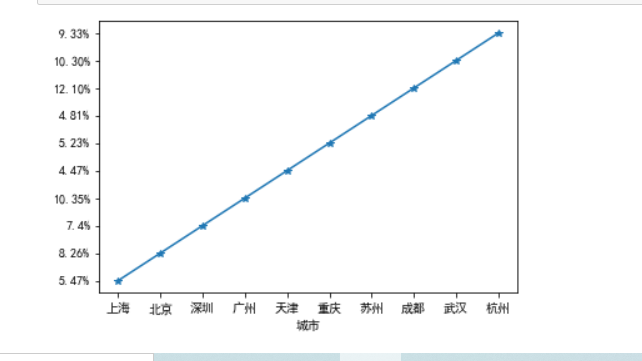
import pandas as pd import numpy as np import matplotlib.pyplot as plt data=pd.read_csv("2018和2019年上半年中国前十名城市GDP排名.csv") plt.rcParams['font.sans-serif'] = 'simhei' plt.rcParams['axes.unicode_minus']=False data = np.array(data) plt.plot(data[:,2],data[:,5],'-*') plt.xlabel("城市") plt.show() #将图片显示出来 最后,用wordcloud、pandas、jieba、matplotlib、numpy等库进行云词图制作。 做云词图采用的图片为:
代码和结果如下: 159 import jieba 160 from matplotlib import pyplot as plt 161 from wordcloud import WordCloud 162 from PIL import Image 163 import numpy as np 164 #r''单引号里面不需要转义 165 from os import path #绘制图片 166 from wordcloud import WordCloud,ImageColorGenerator 167 import jieba 168 import matplotlib.pyplot as plt 169 import matplotlib.image as mpimg 170 import numpy as np 171 img = mpimg.imread('经济.jpg') 172 print (img.shape) 173 plt.imshow(img) 174 font = r'C:\Windows\Fonts\FZSTK.TTF' 175 #电脑自带的字体 176 def tcg(texts): 177 cut = jieba.cut(texts) 178 #分词 179 string = ' '.join(cut) 180 return string 181 text = (open('2018和2019年上半年中国前十名城市GDP排名.txt','r',encoding='utf-8')).read() 182 string=tcg(text) 183 img_array = np.array(img) 184 #将图片装换为数组 185 stopword=[''] 186 #设置停止词,也就是你不想显示的词 187 wc = WordCloud( 188 background_color='white', 189 #设置背景颜色 190 width=1000, 191 #设置宽度 192 height=800, 193 #设置长度 194 mask=img_array, 195 #设置背景图片 196 font_path=font, 197 stopwords=stopword 198 ) 199 wc.generate_from_text(string)#绘制图片 200 plt.imshow(wc) 201 plt.axis('off') 202 plt.show() 203 #将图片显示出来 204 wc.to_file('2018和2019年上半年中国前十名城市GDP排名.jpg')
通过云词图的制作,我觉得在如今的疫情时代,中国不管哪个省、哪个城市GDP都已经恢复正常经济工作并持续增长,通过经济高速增长使中国数百万人摆脱了贫困,过上了幸福美满的生活。中国是如此的强大,所以我相信未来的中国必定是世界第一! 完整代码 1 import requests 2 from lxml import etree 3 import pandas as pd 4 5 #爬取2019年上半年中国前10名城市 6 #伪装爬虫 7 headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'} 8 url = "http://www.860816.com/aricle.asp?id=1785" 9 r = requests.get(url,headers = headers) 10 #发送get请求 11 r.encoding=r.apparent_encoding 12 #构建一个xpath解析对象 13 html = etree.HTML(r.text) 14 #利用etree.HTML()将html字符串转化为element对象,element对象是xpath语法的使用对象,element对象可由html字符串转化 15 table = html.xpath("//table[@class='ke-zeroborder']/tbody") 16 a=[] 17 b=[] 18 c=[] 19 d=[] 20 e=[] 21 lt=[] 22 for td in table: 23 number = td.xpath(".//td[@class='et2'][1]/text()")[1:11] 24 name = td.xpath(".//td[@class='et2'][2]/text()")[1:11] 25 s2019GDP = td.xpath(".//td[@class='et2'][3]/text()")[1:11] 26 #2019上半年GDP(亿元) 27 s2018GDP = td.xpath(".//td[@class='et2'][4]/text()")[1:11] 28 increase1_3 = td.xpath(".//td[@class='et2'][5]/text()")[1:3] 29 increase2_10 = td.xpath(".//td[@class='et3']/text()")[0:8] 30 31 for i in range(10): 32 a.append(number[i].strip()) 33 #用append生成多维数组 34 b.append(name[i].strip()) 35 #.strip删除多余的空格换行 36 c.append(s2019GDP[i].strip()) 37 d.append(s2018GDP[i].strip()) 38 for i in range(2): 39 e.append(increase1_3[i].strip()) 40 for i in range(8): 41 e.append(increase2_10[i].strip()) 42 43 e[2],e[1] = e[1],e[2] 44 45 lt=[] 46 for i in range(10): 47 lt.append([a[i],b[i],c[i],d[i],e[i]]) 48 49 50 df=pd.DataFrame(lt,columns=["排名","城市","一九上半年GDP","一八上半年GDP","名义增速"]) 51 print(df) 52 df.to_csv('2018和2019年上半年中国前十名城市GDP排名.csv',encoding = 'gbk') 53 #保存文件,数据持久化 54 import pandas as pd 55 import numpy as np 56 import matplotlib.pyplot as plt 57 #读取csv文件 58 s=pd.read_csv("2018和2019年上半年中国前十名城市GDP排名.csv") 59 s 60 61 s.duplicated() 62 #检查是否有重复值 63 64 #使用describe查看统计信息 65 s.describe() 66 67 s.info() 68 #查看各列数据类型 69 70 import pandas as pd 71 import numpy as np 72 import matplotlib.pyplot as plt 73 data=pd.read_csv("2018和2019年上半年中国前十名城市GDP排名.csv") 74 plt.rcParams['font.sans-serif']=['SimHei'] 75 #设置字体显示中文标签 76 plt.rcParams['axes.unicode_minus'] = False 77 fig = plt.figure() 78 #设置图片背景,清晰度 79 plt.bar(data['城市'], data['一八上半年GDP']) 80 #画柱状图 81 plt.title(u'2018年各城市GDP的情况') 82 #为图片增加标题 83 plt.xlabel('城市', size=10) 84 #设置图的x轴标签 85 plt.ylabel(u'GDP数值) 86 #设置图的y轴标签 87 plt.show() 88 #将图片显示出来 89 90 #2018和2019年上半年中国前十名城市GDP排名折线图 91 import pandas as pd 92 import numpy as np 93 import matplotlib.pyplot as plt 94 data=pd.read_csv("2018和2019年上半年中国前十名城市GDP排名.csv") 95 plt.rcParams['font.sans-serif'] = 'simhei' 96 plt.rcParams['axes.unicode_minus']=False 97 data = np.array(data) 98 plt.plot(data[:,2],data[:,4],'-*') 99 #画折线图 100 plt.xlabel("城市") 101 #设置图的x轴标签 102 plt.title(u'2018年各城市GDP的情况') 103 #为图片增加标题 104 plt.show() 105 #将图片显示出来 106 107 #画2018和2019年上半年中国前十名城市GDP排名柱状图 108 import pandas as pd 109 import numpy as np 110 import matplotlib.pyplot as plt 111 data=pd.read_csv("2018和2019年上半年中国前十名城市GDP排名.csv") 112 plt.rcParams['font.sans-serif']=['SimHei'] 113 #设置字体显示中文标签 114 plt.rcParams['axes.unicode_minus'] = False 115 fig = plt.figure() 116 #设置图片背景,清晰度 117 plt.bar(data['城市'], data['一九上半年GDP']) 118 #画柱状图 119 plt.title(u'2019年各城市GDP的情况') 120 #为图片增加标题 121 plt.xlabel('城市', size=10) 122 #设置图的x轴标签 123 plt.ylabel(u'GDP数值') 124 #设置图的Y轴标签 125 plt.show() 126 #将图片显示出来 127 128 import pandas as pd 129 import numpy as np 130 import matplotlib.pyplot as plt 131 data=pd.read_csv("2018和2019年上半年中国前十名城市GDP排名.csv") 132 plt.rcParams['font.sans-serif'] = 'simhei' 133 plt.rcParams['axes.unicode_minus']=False 134 data = np.array(data) 135 plt.plot(data[:,2],data[:,3],'-*') 136 plt.title(u'2019年各城市GDP的情况') 137 plt.xlabel("城市") 138 plt.show() 139 #将图片显示出来 140 141 import pandas as pd 142 import numpy as np 143 import matplotlib.pyplot as plt 144 data=pd.read_csv("2018和2019年上半年中国前十名城市GDP排名.csv") 145 plt.rcParams['font.sans-serif'] = 'simhei' 146 plt.rcParams['axes.unicode_minus']=False 147 data = np.array(data) 148 plt.plot(data[:,2],data[:,5],'-*') 149 plt.xlabel("城市") 150 plt.show() 151 #将图片显示出来 152 153 import pandas as pd 154 import seaborn as sns 155 import matplotlib.pyplot as plt 156 df=pd.read_csv("2018和2019年上半年中国前十名城市GDP排名.csv") 157 sns.jointplot(x="排名",y='一九上半年GDP',data = df) 158 159 import jieba 160 from matplotlib import pyplot as plt 161 from wordcloud import WordCloud 162 from PIL import Image 163 import numpy as np 164 #r''单引号里面不需要转义 165 from os import path #绘制图片 166 from wordcloud import WordCloud,ImageColorGenerator 167 import jieba 168 import matplotlib.pyplot as plt 169 import matplotlib.image as mpimg 170 import numpy as np 171 img = mpimg.imread('经济.jpg') 172 print (img.shape) 173 plt.imshow(img) 174 font = r'C:\Windows\Fonts\FZSTK.TTF' 175 #电脑自带的字体 176 def tcg(texts): 177 cut = jieba.cut(texts) 178 #分词 179 string = ' '.join(cut) 180 return string 181 text = (open('2018和2019年上半年中国前十名城市GDP排名.txt','r',encoding='utf-8')).read() 182 string=tcg(text) 183 img_array = np.array(img) 184 #将图片装换为数组 185 stopword=[''] 186 #设置停止词,也就是你不想显示的词 187 wc = WordCloud( 188 background_color='white', 189 #设置背景颜色 190 width=1000, 191 #设置宽度 192 height=800, 193 #设置长度 194 mask=img_array, 195 #设置背景图片 196 font_path=font, 197 stopwords=stopword 198 ) 199 wc.generate_from_text(string)#绘制图片 200 plt.imshow(wc) 201 plt.axis('off') 202 plt.show() 203 #将图片显示出来 204 wc.to_file('2018和2019年上半年中国前十名城市GDP排名.jpg')
四、总结(10分) 描述完成此项目得到哪些有益的结论?是否达到预期的目标?以及要改进的建议? 1.结论 按名义GDP的名义增速排名,一线城市——上海、北京、深圳和广州是中国最大的城市,占中国GDP总量的12.5%。中国经济高度集中在最大的城市,前十大城市合计GDP占中国GDP的23.2%。前十大城市中,四座城市——上海、北京、重庆和天津是直辖市,而另外六座城市大多是江苏、四川、湖北和浙江等资源大省的省会。广东是唯一有两座城市(深圳和广州)入选前十的省份。按以上数据可得出中国最富裕的城市主要位于中国南部和东部沿海地区。 2.目标 已经达到我预期的目标。通过对爬取的数据进行数据可视化分析,通过python中的库编写代码画出一些图表和云词图,可推断出中国经济一直朝正向增长,并说明出中国城市未来发展是光明的。 3.建议 (1)由于网页未更新出2019年后各城市GDP的情况,所以无法更精确地呈现出中国各城市经济现阶段的发展情况。 (2)对python库的使用不是特别的娴熟,绘画出的图并不是特别直观。
|


【本文地址】
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |