| 一种基于深度学习的印刷体与手写体分开文字识别方法与流程 | 您所在的位置:网站首页 › 俄语手写体和印刷体的区别和联系图片大全 › 一种基于深度学习的印刷体与手写体分开文字识别方法与流程 |
一种基于深度学习的印刷体与手写体分开文字识别方法与流程
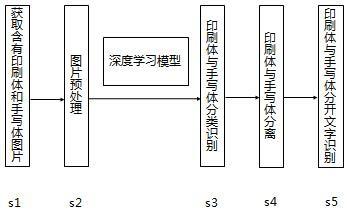 1.本发明涉及一种基于深度学习的印刷体与手写体分开文字识别方法,属于人工智能视觉领域。 背景技术: 2.对文档图片进行文字识别已经是比较成熟的技术,但是当文档图片里同时含有印刷体和手写体时,现有的文字识别技术是把二者放在一起识别,不能把印刷体和手写体分离。对同时含有印刷体和手写体的文档图片分别进行文字识别有很多重要的应用,比如银行票据的文字识别、学生试卷自动批改、诉讼文件转为电子卷宗等。要实现对印刷体与手写体分别进行文字识别,其中的一个关键技术问题是印刷体与手写体分类识别。印刷体与手写体分类问题可以定义为:对于同时含有印刷体、手写体的图片,希望对图片里的印刷体、手写体和背景实现像素级分类。传统的机器视觉方法很难对印刷体和手写体实现像素级分类识别,尤其是印刷体与手写体有交叉重叠的时候。深度学习方法中的语义分割技术可以实现像素级分类识别,可以很好的解决这个问题。语义分割技术中流行的算法包括全卷积神经网络fcn和带空洞卷积的fcn。 技术实现要素: 3.本发明为实现印刷体与手写体分开文字识别目的采用如下技术方案:一种基于深度学习的印刷体与手写体分开文字识别方法,步骤如下。4.步骤(1)制作训练样本数据集,包括如下步骤:(1.1)准备一张纸,要求纸上的印刷字体是黑色,纸的空白处是白色;(1.2)在纸上用红笔写字;(1.3)对写好字的纸张拍照得到的图片记为图a。这一步也可以用扫描仪扫描;(1.4)通过算法程序对图a进行预处理,包括边框裁剪、二值化为黑白图,得到的结果图记为图b,图b为训练模型的输入样本。图b的印刷体和手写体为黑色,背景变为白色;(1.5)通过算法程序对图a中的印刷体、手写体和背景进行像素级分类,得到的结果记为图c。算法程序的分类原理是基于不同颜色对应的像素值大小不同,红色的手写体容易与黑色印刷体和白色背景区分开。图c为训练模型的输出样本。这里把背景的像素用0表示,印刷字体的像素用1表示,手写字体的像素用2表示。从而实现手写字体、印刷字体、背景的像素级标注。5.步骤(2)建立深度学习模型,主要是图像语义分割领域的人工智能模型,该人工智能模型可以是全卷积神经网络(fully convolutional networks,fcn),空洞卷积(dilated convolutions),带空洞卷积的fcn模型,segnet网络,或者u-net网络等。6.步骤(3)模型训练就是把训练样本输入模型进行训练,包括如下步骤:(3.1)训练样本的输入把图b作为训练样本的输入,输入到人工智能模型;(3.2)训练样本的输出把图c作为训练样本的目标输出。图c包括3个类别,分别记为:印刷体记为1,手写字体记为2,背景记为0;(3.3)准备好了模型和训练样本就可以训练模型了,模型的训练可以在个人电脑上训练,也可以在cpu服务器上或者gpu服务器上训练。如果样本量很大,最好在gpu服务器上训练。训练好模型之后要保存模型。同时还需要用检测样本对模型进行检测,检测模型的分类准确率,如果分类准确率较高则可以用于实际应用。7.步骤(4)获取含有印刷体和手写体图片,包括多种方式:对含有印刷体和手写体的纸张用手机、扫描仪或者高拍仪等拍照。8.步骤(5)对图片预处理,包括图片转正、去阴影等。图片转正也可以理解为边框裁剪。去阴影也可以理解为二值化。9.步骤(6)把经过预处理的图片输入训练好的模型检测得到像素级分类结果图,包括如下步骤:(6.1)加载训练好的模型;(6.2)把经过预处理的图片分割为n个小图片,比如可以取n=4。分割为小图片是为了提高检测速度;(6.3)把每个小图片输入模型检测,可以通过多线程方法并行计算,得到分类结果。10.步骤(7)根据分类识别的结果可以分别得到印刷体图片、手写体图片,实现印刷体与手写体分离。11.步骤(8)对分离开的印刷体和手写体图片分别进行文字识别,文字识别软件可以采用百度开源程序paddleocr。附图说明12.图1为本发明流程图;图2 同时含有印刷体和手写体的原始图片;图3从原始图片中分离出印刷体;图4从原始图片中分离出手写体;图5对分离出的印刷体进行文字识别;图6对分离出的手写体进行文字识别。具体实施方式13.下面结合附图对本发明的具体实施方式进行进一步的详细描述。14.图1为本发明流程图,具体步骤如下。15.步骤(1)制作训练样本数据集,包括如下步骤:(1.1)准备一张纸,要求纸上的印刷字体是黑色,纸的空白处是白色;(1.2)在纸上用红笔写字;(1.3)对写好字的纸张拍照得到的图片记为图a。这一步也可以用扫描仪扫描;(1.4)通过算法程序对图a进行预处理,包括边框裁剪、二值化为黑白图,得到的结果图记为图b,图b为训练模型的输入样本。图b的印刷体和手写体为黑色,背景变为白色;(1.5)通过算法程序对图a中的印刷体、手写体和背景进行像素级分类,得到的结果记为图c。算法程序的分类原理是基于不同颜色对应的像素值大小不同,红色的手写体容易与黑色印刷体和白色背景区分开。图c为训练模型的输出样本。这里把背景的像素用0表示,印刷字体的像素用1表示,手写字体的像素用2表示。从而实现手写字体、印刷字体、背景的像素级标注;(1.6)为了达到比较理想的效果,制作的样本数量多多益善,比如可以制作2200张,其中2000张用于训练,200张用于检测。目前制作的图片里的文字语言主要是中文和英文以及数学字符。采用同样的方法也可以对其他语言的图片制作样本。16.步骤(2)建立深度学习模型,主要是图像语义分割领域的人工智能模型,该人工智能模型可以是全卷积神经网络(fully convolutional networks,fcn),空洞卷积(dilated convolutions),带空洞卷积的fcn模型,segnet网络,或者u-net网络等。17.考虑到实际工程应用,构建的模型需要尽量简单、且分类准确率较高。太复杂的模型计算开销大且耗时。其中的一个模型例子如下:(1)模型的输入层为1024×1024的3通道图;(2)空洞卷积层,具有32个特征图,卷积核为5×5,扩张率=2;(3)dropout层,dropout概率为20%;(4)空洞卷积层,具有32个特征图,卷积核为5×5,扩张率=3;(5)池化层,采样因子为2×2;(6)空洞卷积层,具有64个特征图,卷积核为5×5,扩张率=2;(7)dropout层,dropout概率为20%;(8)空洞卷积层,具有64个特征图,卷积核为5×5,扩张率=3;(9)池化层,采样因子为2×2;(10)空洞卷积层,具有64个特征图,卷积核为5×5,扩张率=2;(11)dropout层,dropout概率为20%;(12)空洞卷积层,具有64个特征图,卷积核为5×5,扩张率=3;(13)卷积层,具有32个特征图,卷积核为1×1;(14)反卷积层,具有3个特征图,卷积核为4×4,步长为4×4。18.步骤(3)模型训练就是把训练样本输入模型进行训练,包括如下步骤:(3.1)训练样本的输入把图b作为训练样本的输入,输入到人工智能模型;(3.2)训练样本的输出把图c作为训练样本的目标输出。图c包括3个类别,分别记为:印刷体记为1,手写字体记为2,背景记为0;(3.3)准备好了模型和训练样本就可以训练模型了,模型的训练可以在个人电脑上训练,也可以在cpu服务器上或者gpu服务器上训练。如果样本量很大,最好在gpu服务器上训练。训练好模型之后要保存模型。同时还需要用检测样本对模型进行检测,检测模型的分类准确率,如果分类准确率较高则可以用于实际应用。19.步骤(4)获取含有印刷体和手写体图片,包括多种方式:对含有印刷体和手写体的纸张用手机、扫描仪或者高拍仪等拍照。如图2是拍照得到的原图截取的一部分。20.步骤(5)对图片预处理,包括图片转正、去阴影等。图片转正也可以理解为边框裁剪。去阴影也可以理解为二值化。21.步骤(6)把经过预处理的图片输入训练好的模型检测得到像素级分类结果图,包括如下步骤:(6.1)加载训练好的模型;(6.2)把经过预处理的图片分割为n个小图片,比如可以取n=4。分割为小图片是为了提高检测速度;(6.3)把每个小图片输入模型检测,可以通过多线程方法并行计算,得到分类结果。22.步骤(7)根据分类识别的结果可以分别得到印刷体图片、手写体图片,实现印刷体与手写体分离。如图3是从原始图片中分离出的印刷体,图4是从原始图片中分离出的手写体。23.步骤(8)对分离开的印刷体和手写体图片分别进行文字识别,文字识别软件可以采用百度开源程序paddleocr.如图5是对分离出的印刷体进行文字识别得到的结果,图6是对分离出的手写体进行文字识别得到的结果。从文字识别结果可以看出大部分识别正确。24.本发明说明书中未作详细描述的内容属于本领域专业技术人员的公知技术。 |
【本文地址】